¿Qué es un Agente?
Definición
Un agente es cualquier cosa que puede verse como:
- Percibiendo su entorno a través de sensores
- Actuando sobre ese entorno a través de actuadores
graph LR
subgraph Environment
W[World State]
end
subgraph Agent
S[Sensors]
B[Brain]
A[Actuators]
end
W -->|Percepts| S
S --> B
B --> A
A -->|Actions| W
style W fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style B fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style A fill:#f472b6,stroke:#db2777,color:#831843
Ejemplos de Agentes
| Agente | Sensores | Actuadores |
|---|---|---|
| Humano | Ojos, oídos, piel | Manos, piernas, voz |
| Robot | Cámaras, LIDAR, touch | Motores, grippers |
| Software | Archivos, network, input | Display, network, files |
| Termostato | Termómetro | Switch on/off |

Clasificación de Agentes: Russell & Norvig (AIMA)
La clasificación más utilizada en IA proviene de Russell y Norvig en “Artificial Intelligence: A Modern Approach”. Clasifica agentes por su arquitectura interna — cómo procesan información para decidir qué hacer.
Visión General
graph LR
A[Simple Reflex] --> B[Model-Based Reflex]
B --> C[Goal-Based]
C --> D[Utility-Based]
D --> E[Learning]
style A fill:#94a3b8,stroke:#475569,color:#1e293b
style B fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style C fill:#5eead4,stroke:#14b8a6,color:#134e4a
style D fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style E fill:#f472b6,stroke:#db2777,color:#831843
Cada tipo añade capacidades al anterior:
| Tipo | Usa percept actual | Tiene estado interno | Tiene goals | Tiene utilidad | Aprende |
|---|---|---|---|---|---|
| Simple Reflex | ✓ | ✗ | ✗ | ✗ | ✗ |
| Model-Based | ✓ | ✓ | ✗ | ✗ | ✗ |
| Goal-Based | ✓ | ✓ | ✓ | ✗ | ✗ |
| Utility-Based | ✓ | ✓ | ✓ | ✓ | ✗ |
| Learning | ✓ | ✓ | ✓ | ✓ | ✓ |
1. Simple Reflex Agents
El agente más básico. Selecciona acciones basándose únicamente en el percept actual, ignorando toda la historia.
graph LR
E[Environment] -->|percept| S[Sensors]
S --> R{Condition-Action Rules}
R -->|action| A[Actuators]
A --> E
style E fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style R fill:#94a3b8,stroke:#475569,color:#1e293b
style A fill:#f472b6,stroke:#db2777,color:#831843
Mecanismo: Reglas if-then (condición-acción)
function SIMPLE-REFLEX-AGENT(percept):
rules ← conjunto de reglas condición-acción
state ← INTERPRET-INPUT(percept)
rule ← RULE-MATCH(state, rules)
action ← rule.ACTION
return action
Ejemplo: Termostato
| Percept (Temperatura) | Acción |
|---|---|
| T < 18°C | Encender calefacción |
| T > 22°C | Encender AC |
| 18°C ≤ T ≤ 22°C | No hacer nada |
Ejemplo: Vacuum World Simple
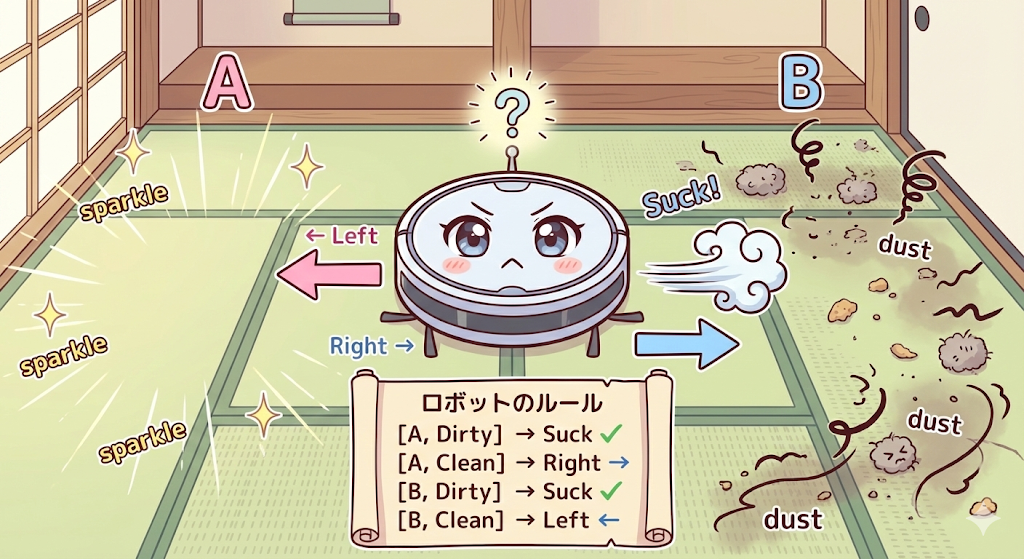
| Percept | Acción |
|---|---|
| [A, Dirty] | Suck |
| [A, Clean] | Right |
| [B, Dirty] | Suck |
| [B, Clean] | Left |
Ventajas:
- Muy simples de implementar
- Respuesta inmediata (tiempo constante)
- No requieren memoria
Limitaciones:
- Solo funcionan en entornos fully observable
- No pueden manejar estados ocultos
- Pueden caer en loops infinitos
En Vacuum World, si el agente está en A (limpio) y va a Right, luego en B (limpio) va a Left, ¡repite infinitamente!
Solución: Necesita memoria (→ Model-Based)
2. Model-Based Reflex Agents
Mantiene un estado interno que representa aspectos del mundo que no puede ver directamente.
graph TD
E[Environment] -->|percept| S[Sensors]
S --> U[Update State]
M[Internal Model] --> U
U --> M
M --> R{Condition-Action Rules}
R -->|action| A[Actuators]
A --> E
subgraph "Conocimiento del Agente"
T1["Cómo evoluciona el mundo"]
T2["Cómo mis acciones afectan el mundo"]
end
T1 --> U
T2 --> U
style E fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style U fill:#5eead4,stroke:#14b8a6,color:#134e4a
style M fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style R fill:#94a3b8,stroke:#475569,color:#1e293b
style A fill:#f472b6,stroke:#db2777,color:#831843
style T1 fill:#334155,stroke:#64748b,color:#e2e8f0
style T2 fill:#334155,stroke:#64748b,color:#e2e8f0
Mecanismo: Estado interno + reglas
function MODEL-BASED-REFLEX-AGENT(percept):
state ← UPDATE-STATE(state, action, percept, model)
rule ← RULE-MATCH(state, rules)
action ← rule.ACTION
return action
El agente necesita dos tipos de conocimiento:
- Modelo de transición: Cómo evoluciona el mundo independientemente del agente
- Modelo del sensor: Cómo el estado del mundo se refleja en los percepts
Ejemplo: Conductor que no ve un carro
Un conductor en una autopista sabe que había un carro en su punto ciego hace 2 segundos. Aunque ahora no lo ve, mantiene en su estado interno que probablemente sigue ahí.
Ejemplo: Vacuum World con Memoria
El agente recuerda qué cuartos ya limpió:
| Estado Interno | Percept | Acción |
|---|---|---|
| [A, Dirty] | Suck, update A:clean | |
| [A, Clean] | Right | |
| [B, Dirty] | Suck, update B:clean | |
| [B, Clean] | Stop (¡ya terminó!) |
Ventajas:
- Funciona en entornos partially observable
- Puede evitar loops
- Puede razonar sobre objetos que no ve actualmente
Limitaciones:
- El modelo puede ser incorrecto o incompleto
- Aún no tiene objetivos explícitos
- No puede planificar a futuro
3. Goal-Based Agents
Además del estado actual, tiene objetivos explícitos que quiere alcanzar. Esto le permite planificar y buscar secuencias de acciones.
graph TD
E[Environment] -->|percept| S[Sensors]
S --> U[Update State]
M[Internal Model] --> U
U --> M
M --> P[Planning/Search]
G[Goals] --> P
P -->|action| A[Actuators]
A --> E
style E fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style U fill:#5eead4,stroke:#14b8a6,color:#134e4a
style M fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style P fill:#5eead4,stroke:#14b8a6,color:#134e4a
style G fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style A fill:#f472b6,stroke:#db2777,color:#831843
Mecanismo: Búsqueda + Planificación
function GOAL-BASED-AGENT(percept):
state ← UPDATE-STATE(state, action, percept, model)
if goal-achieved(state, goals):
return NoOp
plan ← SEARCH(state, goals, model)
action ← first(plan)
return action
Ejemplo: GPS / Navegación
- Estado: Posición actual, mapa
- Goal: Llegar a destino D
- Proceso: Buscar ruta óptima de A → D
- Acción: Seguir la ruta paso a paso
Ejemplo: Robot que entrega paquetes
Estado: en(robot, oficina), tiene(robot, paquete)
Goal: en(paquete, almacén)
Plan:
1. ir(oficina, pasillo)
2. ir(pasillo, almacén)
3. soltar(paquete)
Diferencia clave con Reflex:
| Situación | Reflex Agent | Goal-Based Agent |
|---|---|---|
| Obstáculo en el camino | Gira a la derecha (regla fija) | Recalcula ruta óptima al goal |
| Múltiples caminos | Siempre elige el mismo | Evalúa cuál llega al goal |
| Goal cambia | No puede adaptarse | Replanifica automáticamente |
Ventajas:
- Comportamiento flexible — el goal puede cambiar
- Puede manejar situaciones nuevas
- Razonamiento sobre consecuencias de acciones
Limitaciones:
- No distingue entre goals igualmente alcanzables
- ¿Qué pasa si hay múltiples goals conflictivos?
- ¿Cómo elegir entre rutas igual de válidas?
4. Utility-Based Agents
Tiene una función de utilidad $U: S \to \mathbb{R}$ que mide qué tan “feliz” está el agente en cada estado. Maximiza la utilidad esperada.
graph TD
E[Environment] -->|percept| S[Sensors]
S --> U[Update State]
M[Internal Model] --> U
U --> M
M --> EU[Compute Expected Utility]
UF[Utility Function] --> EU
EU -->|action that maximizes EU| A[Actuators]
A --> E
style E fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style U fill:#5eead4,stroke:#14b8a6,color:#134e4a
style M fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style EU fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style UF fill:#fbbf24,stroke:#d97706,color:#78350f
style A fill:#f472b6,stroke:#db2777,color:#831843
Mecanismo: Maximización de utilidad esperada
$$a^* = \arg\max_a \sum_{s’} P(s’|s,a) \cdot U(s’)$$
¿Por qué utilidad y no solo goals?
Los goals son binarios (logrado/no logrado). La utilidad permite:
- Trade-offs entre objetivos conflictivos
- Preferencias sobre cómo lograr el objetivo
- Manejo de incertidumbre probabilística
Ejemplo: Taxi Autónomo
| Factor | Goal-Based | Utility-Based |
|---|---|---|
| Objetivo | Llegar al destino | $U = f(seguridad, tiempo, costo, comfort)$ |
| Ruta rápida pero peligrosa | ¿Válida? | $U = 0.3 \cdot rapido - 0.7 \cdot peligro$ → rechazada |
| Ruta lenta pero segura | ¿Válida? | $U = 0.3 \cdot lento + 0.7 \cdot seguro$ → aceptada |
| Cliente con prisa | Misma decisión | Ajustar pesos: $w_{tiempo} \uparrow$ |
Ejemplo: Decisión bajo incertidumbre
Tienes dos rutas:
- Ruta A: 30 min seguro
- Ruta B: 20 min con 50% de probabilidad, 60 min con 50% (por tráfico)
| Tipo de Agente | Decisión |
|---|---|
| Goal-Based | Ambas llegan → ¿cuál elegir? 🤷 |
| Utility-Based | $E[U_A] = U(30) = 0.7$, $E[U_B] = 0.5 \cdot U(20) + 0.5 \cdot U(60) = 0.55$ → Elige A |
Ventajas:
- Maneja múltiples objetivos con trade-offs
- Toma decisiones óptimas bajo incertidumbre
- Comportamiento racional formalmente definido
Limitaciones:
- Definir $U$ correctamente es difícil
- Computar la acción óptima puede ser costoso
- El agente no mejora con la experiencia
5. Learning Agents
Puede mejorar su comportamiento a través de la experiencia. Tiene componentes adicionales para aprender.
graph TD
E[Environment] -->|percept| S[Sensors]
S --> PE[Performance Element]
PE -->|action| A[Actuators]
A --> E
E -->|feedback| C[Critic]
C -->|learning goals| LE[Learning Element]
LE -->|changes| PE
LE -->|experiments| PG[Problem Generator]
PG -->|exploratory actions| A
style E fill:#1e293b,stroke:#94a3b8,color:#e2e8f0
style S fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style PE fill:#5eead4,stroke:#14b8a6,color:#134e4a
style A fill:#f472b6,stroke:#db2777,color:#831843
style C fill:#fbbf24,stroke:#d97706,color:#78350f
style LE fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style PG fill:#fb7185,stroke:#e11d48,color:#881337
Componentes:
| Componente | Función | Ejemplo |
|---|---|---|
| Performance Element | Selecciona acciones (como los agentes anteriores) | El “cerebro” actual |
| Critic | Evalúa qué tan bien lo está haciendo | Compara con estándar de performance |
| Learning Element | Modifica el Performance Element | Actualiza reglas, modelo, utilidad |
| Problem Generator | Sugiere acciones exploratorias | “¿Qué pasa si pruebo esto?” |
Tipos de Aprendizaje:
| Qué aprende | Ejemplo |
|---|---|
| Reglas condición-acción | Aprender que “cielo oscuro → llevar paraguas” |
| Modelo del mundo | Aprender cómo el tráfico afecta tiempos de viaje |
| Función de utilidad | Aprender preferencias del usuario |
| Goals | Descubrir qué objetivos son importantes |
Ejemplo: Sistema de Recomendación
Día 1: Recomienda películas aleatorias
Usuario da ratings
Critic: "Le gustaron las de acción, no le gustaron las románticas"
Learning Element: Actualiza modelo de preferencias
Día 30: Recomienda películas de acción con alta precisión
Problem Generator: "¿Y si pruebo una comedia de acción?"
→ Descubre nuevo gusto del usuario
Ejemplo: AlphaGo
- Performance Element: Red neuronal que evalúa posiciones + MCTS
- Critic: ¿Ganó o perdió la partida?
- Learning Element: Backpropagation, actualiza pesos de la red
- Problem Generator: Self-play genera nuevas situaciones
Ventajas:
- Puede operar en entornos desconocidos
- Mejora con el tiempo
- Puede descubrir estrategias no anticipadas por el diseñador
Limitaciones:
- Necesita mucha experiencia para aprender bien
- Puede aprender comportamientos no deseados
- El diseño del sistema de aprendizaje es complejo
Resumen: Progresión de Arquitecturas
graph TB
subgraph "Capacidad Creciente"
SR[Simple Reflex] -->|+estado interno| MB[Model-Based]
MB -->|+goals| GB[Goal-Based]
GB -->|+utilidad| UB[Utility-Based]
UB -->|+aprendizaje| LA[Learning Agent]
end
SR ---|Ejemplo| T1[Termostato]
MB ---|Ejemplo| T2[Conductor humano]
GB ---|Ejemplo| T3[GPS navegador]
UB ---|Ejemplo| T4[Taxi autónomo]
LA ---|Ejemplo| T5[AlphaGo]
style SR fill:#94a3b8,stroke:#475569,color:#1e293b
style MB fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style GB fill:#5eead4,stroke:#14b8a6,color:#134e4a
style UB fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style LA fill:#f472b6,stroke:#db2777,color:#831843
style T1 fill:#334155,stroke:#64748b,color:#e2e8f0
style T2 fill:#334155,stroke:#64748b,color:#e2e8f0
style T3 fill:#334155,stroke:#64748b,color:#e2e8f0
style T4 fill:#334155,stroke:#64748b,color:#e2e8f0
style T5 fill:#334155,stroke:#64748b,color:#e2e8f0
| Pregunta | Simple Reflex | Model-Based | Goal-Based | Utility-Based | Learning |
|---|---|---|---|---|---|
| ¿Qué hay ahora? | ✓ | ✓ | ✓ | ✓ | ✓ |
| ¿Qué pasará si hago X? | ✗ | ✓ | ✓ | ✓ | ✓ |
| ¿Qué quiero lograr? | ✗ | ✗ | ✓ | ✓ | ✓ |
| ¿Qué tan bueno es? | ✗ | ✗ | ✗ | ✓ | ✓ |
| ¿Cómo puedo mejorar? | ✗ | ✗ | ✗ | ✗ | ✓ |
Clasificación Alternativa: Weiss (1999)
Gerhard Weiss en “Multiagent Systems” ofrece una perspectiva complementaria, clasificando agentes por propiedades observables y arquitectura cognitiva.
Propiedades Fundamentales de un Agente
Para Weiss, un agente “verdadero” debe tener estas propiedades:
| Propiedad | Descripción | Ejemplo |
|---|---|---|
| Autonomía | Opera sin intervención directa | Un robot que decide cuándo recargar batería |
| Reactividad | Responde a cambios del entorno oportunamente | Un carro que frena ante un obstáculo |
| Pro-actividad | Toma iniciativa, no solo reacciona | Un asistente que sugiere tareas sin que le preguntes |
| Habilidad Social | Interactúa con otros agentes | Un bot de trading que negocia con otros bots |
Tipos de Agentes según Weiss
graph LR
subgraph Reactivos["🔴 Agentes Reactivos"]
R1[Sin modelo del mundo]
R2[Respuesta estímulo-acción]
R3[Rápidos pero limitados]
end
subgraph Deliberativos["🔵 Agentes Deliberativos"]
D1[Modelo simbólico del mundo]
D2[Razonamiento y planificación]
D3[Arquitectura BDI]
end
subgraph Hibridos["🟢 Agentes Híbridos"]
H1[Capas reactivas]
H2[Capas deliberativas]
H3[Lo mejor de ambos]
end
style R1 fill:#fb7185,stroke:#e11d48,color:#881337
style R2 fill:#fb7185,stroke:#e11d48,color:#881337
style R3 fill:#fb7185,stroke:#e11d48,color:#881337
style D1 fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style D2 fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style D3 fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style H1 fill:#5eead4,stroke:#14b8a6,color:#134e4a
style H2 fill:#5eead4,stroke:#14b8a6,color:#134e4a
style H3 fill:#5eead4,stroke:#14b8a6,color:#134e4a
1. Agentes Reactivos
- No tienen modelo interno del mundo
- Mapeo directo percepción → acción
- Inspirados en comportamiento de insectos
- Ejemplo: Arquitectura de subsunción de Brooks
2. Agentes Deliberativos
- Mantienen un modelo simbólico del mundo
- Razonan sobre ese modelo para decidir
- Arquitectura BDI (Beliefs-Desires-Intentions):
- Beliefs: Lo que el agente cree sobre el mundo
- Desires: Los estados que quiere alcanzar
- Intentions: Los planes que se ha comprometido a ejecutar
3. Agentes Híbridos
- Combinan capas reactivas (respuesta rápida) con deliberativas (planificación)
- La capa reactiva maneja emergencias
- La capa deliberativa planifica a largo plazo
- Ejemplo: Arquitectura InteRRaP, TouringMachines
Comparación: Russell & Norvig vs Weiss
| Aspecto | Weiss | Russell & Norvig |
|---|---|---|
| Pregunta central | “¿Qué propiedades tiene?” | “¿Cómo decide qué hacer?” |
| Enfoque | Comportamiento observable | Mecanismo interno |
| Contexto | Sistemas multiagente | Agente individual |
| Categorías | 3 tipos (reactivo, deliberativo, híbrido) | 5 tipos progresivos |
Mapeo entre Clasificaciones
graph TD
subgraph Weiss["Weiss"]
W1[Reactivo]
W2[Deliberativo]
W3[Híbrido]
end
subgraph RN["Russell & Norvig"]
RN1[Simple Reflex]
RN2[Model-Based]
RN3[Goal-Based]
RN4[Utility-Based]
RN5[Learning]
end
W1 -.->|corresponde a| RN1
W1 -.->|corresponde a| RN2
W2 -.->|corresponde a| RN3
W2 -.->|corresponde a| RN4
W3 -.->|combina| RN2
W3 -.->|combina| RN3
RN5 -.->|puede agregarse a| W1
RN5 -.->|puede agregarse a| W2
RN5 -.->|puede agregarse a| W3
style W1 fill:#fb7185,stroke:#e11d48,color:#881337
style W2 fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style W3 fill:#5eead4,stroke:#14b8a6,color:#134e4a
style RN1 fill:#94a3b8,stroke:#475569,color:#1e293b
style RN2 fill:#7dd3fc,stroke:#0284c7,color:#0c4a6e
style RN3 fill:#5eead4,stroke:#14b8a6,color:#134e4a
style RN4 fill:#a78bfa,stroke:#7c3aed,color:#4c1d95
style RN5 fill:#f472b6,stroke:#db2777,color:#831843
Diferencias Clave
| Criterio | Weiss | Russell & Norvig |
|---|---|---|
| Modelo interno | Reactivo=no, Deliberativo=sí | Reflex=no, Model-based+=sí |
| Planificación | Solo deliberativos | Goal-based y Utility-based |
| Aprendizaje | No es categoría separada | Es un tipo adicional |
| Interacción social | Propiedad fundamental | No es central |
| BDI | Arquitectura específica para deliberativos | No se menciona explícitamente |
¿Cuál usamos en este curso?
Seguimos la clasificación de Russell & Norvig porque:
- Progresión clara de capacidades
- Conecta directamente con las técnicas del curso
- Es el estándar en cursos introductorios
Pero la perspectiva de Weiss aporta:
- El concepto de autonomía como propiedad fundamental
- La arquitectura BDI para agentes deliberativos
- La importancia de la habilidad social en sistemas reales
- El diseño de agentes híbridos con capas
Para cada agente, clasifícalo según ambas taxonomías:
-
Roomba básica (aspiradora robot simple)
- Weiss: ¿Reactivo, Deliberativo, o Híbrido?
- R&N: ¿Simple Reflex, Model-Based, Goal-Based, Utility-Based?
-
GPS de carro (calcula rutas)
- Weiss: ?
- R&N: ?
-
Carro autónomo Waymo
- Weiss: ?
- R&N: ?
-
AlphaGo (juega Go)
- Weiss: ?
- R&N: ?
-
ChatGPT
- Weiss: ?
- R&N: ?
Justifica cada clasificación.
Ver Respuestas
1. Roomba básica
| Taxonomía | Clasificación | Justificación |
|---|---|---|
| Weiss | Reactivo | Responde directamente a sensores: ¿sucio? aspirar. ¿obstáculo? girar. No planea ni mantiene modelo complejo. |
| R&N | Simple Reflex (básica) o Model-Based (avanzada) | Las Roombas básicas usan reglas condición-acción. Las nuevas construyen mapas → Model-Based. |
2. GPS de carro
| Taxonomía | Clasificación | Justificación |
|---|---|---|
| Weiss | Deliberativo | Razona sobre un modelo del mundo (mapa), planifica rutas, no solo reacciona. |
| R&N | Goal-Based (o Utility-Based) | Tiene objetivo explícito (destino), usa búsqueda/planificación. Si optimiza tiempo/distancia/tráfico → Utility-Based. |
3. Carro autónomo Waymo
| Taxonomía | Clasificación | Justificación |
|---|---|---|
| Weiss | Híbrido | Combina capas reactivas (frenado de emergencia) con deliberativas (planificación de ruta, predicción de otros vehículos). |
| R&N | Utility-Based + Learning | Maximiza utilidad (seguridad × velocidad × comodidad × legalidad), aprende de datos, mantiene modelo del mundo. |
4. AlphaGo
| Taxonomía | Clasificación | Justificación |
|---|---|---|
| Weiss | Híbrido | Tiene componentes reactivos (red de policy aprendida) y deliberativos (MCTS para planificación). |
| R&N | Learning + Utility-Based | Aprendió de self-play, usa función de valor (utilidad), planifica con MCTS. |
5. ChatGPT
| Taxonomía | Clasificación | Justificación |
|---|---|---|
| Weiss | Reactivo (principalmente) | No mantiene memoria entre sesiones, responde al input actual. Aunque tiene patrones complejos aprendidos. |
| R&N | Learning (entrenamiento) → desplegado como Model-Based Reflex sofisticado | Fue entrenado (learning), pero en uso no tiene goals explícitos ni optimiza utilidad en el sentido clásico. Es un caso límite interesante. |
Nota sobre ChatGPT
Los LLMs no encajan perfectamente en las taxonomías clásicas de agentes:
- No tienen estado persistente (no son model-based en el sentido tradicional)
- No tienen objetivos explícitos (no son goal-based)
- No optimizan una utilidad definida en cada interacción
- Pero sí aprendieron patrones complejos del mundo
Esto es un tema de discusión activo en AI: ¿Son los LLMs agentes? ¿Qué tipo? La respuesta depende de cómo los integremos en sistemas más amplios.
Agent Function vs Agent Program
Dos conceptos relacionados pero distintos:
| Concepto | Descripción | Naturaleza |
|---|---|---|
| Agent Function | Mapeo de percept sequences a actions | Abstracta, matemática |
| Agent Program | Implementación concreta | Código ejecutable |
$$f: \mathcal{P}^* \rightarrow \mathcal{A}$$
Donde $\mathcal{P}^*$ es el conjunto de todas las secuencias posibles de percepts y $\mathcal{A}$ es el conjunto de acciones.
El Problema de la Tabla
Si intentáramos implementar un agente con una tabla de lookup:
Percept Sequence → Action
[A, Clean] → Right
[A, Dirty] → Suck
[B, Clean] → Left
[B, Dirty] → Suck
[A, Clean], [A, Clean] → Right
...
Para un taxi autónomo con cámara HD a 30fps por 1 hora:
- Entradas posibles: $> 10^{600,000,000,000}$
- Átomos en el universo observable: $< 10^{80}$
¿De dónde sale ese número astronómico?
Calculemos paso a paso:
-
Un frame de video HD:
- Resolución: $1920 \times 1080 = 2,073,600$ píxeles
- Cada píxel tiene 3 canales (RGB)
- Cada canal tiene 256 valores posibles (8 bits)
- Bits por frame: $1920 \times 1080 \times 3 \times 8 \approx 50 \times 10^6$ bits
-
Una hora de video a 30fps:
- Frames totales: $30 \times 60 \times 60 = 108,000$ frames
- Bits totales: $50 \times 10^6 \times 108,000 \approx 5.4 \times 10^{12}$ bits
-
Número de posibles secuencias de percepts:
- Cada secuencia de $n$ bits puede tomar $2^n$ valores
- Posibles historias: $2^{5.4 \times 10^{12}}$
-
Convertir a base 10:
- $2^n = 10^{n \cdot \log_{10}(2)} = 10^{n \cdot 0.301}$
- $2^{5.4 \times 10^{12}} = 10^{5.4 \times 10^{12} \times 0.301} \approx 10^{1.6 \times 10^{12}}$
Eso es $10^{1,600,000,000,000}$ — ¡diez elevado a 1.6 trillones!
El número $10^{600,000,000,000}$ en el texto es una estimación conservadora (asumiendo menos bits por frame o compresión). El punto es el mismo: es incomprensiblemente más grande que cualquier cosa física.
Perspectiva: Si cada átomo en el universo fuera una computadora, y cada computadora pudiera almacenar un estado por cada nanosegundo desde el Big Bang… no alcanzarías ni a rozar $10^{600,000,000,000}$.
Conclusión: Necesitamos programas compactos, no tablas.
Visualización: Espectro de Agentes
Para cada sistema, identifica:
- ¿Es un agente? ¿Por qué?
- Si sí, ¿cuáles son sus sensores y actuadores?
Sistemas:
- a) Un reloj de pared
- b) Un termostato programable
- c) Una puerta automática
- d) Google Search
- e) Un virus biológico
- f) Una empresa (como organización)
Considera el mundo de la aspiradora con dos cuartos (A y B):
┌───┬───┐
│ A │ B │
└───┴───┘
Cada cuarto puede estar limpio o sucio. La aspiradora puede:
- Moverse a la izquierda (Left)
- Moverse a la derecha (Right)
- Aspirar (Suck)
- ¿Cuántos estados posibles tiene el environment?
- ¿Cuántas percept sequences de longitud 3 existen?
- Diseña una agent function simple (tabla pequeña) que limpie ambos cuartos.
Quiero entender mejor el concepto de agente en IA.
Dado el siguiente sistema: [DESCRIBE TU SISTEMA]
- ¿Puede modelarse como un agente? Justifica.
- Si sí, ¿cuáles serían sus:
- Sensores (¿qué percibe?)
- Actuadores (¿qué acciones puede tomar?)
- Environment (¿en qué mundo opera?)
- ¿Qué tan complejo es su “agent function”?
- ¿Qué desafíos tendría implementar este agente?
Dame ejemplos concretos y específicos.
Puntos Clave
- Agente = Percepción + Acción en un environment
- La agent function es el mapeo ideal; el agent program es la implementación
- Las tablas de lookup son imposibles para problemas reales
- El reto de AI es encontrar programas compactos que aproximen buenas agent functions