18.6 — Más allá: de MCTS a AlphaZero
“The game of Go has long been viewed as the most challenging of classic games for artificial intelligence.” — David Silver et al. (2016)
MCTS con UCT y rollouts aleatorios es sorprendentemente fuerte — pero tiene un límite: los rollouts aleatorios son ruidosos. En posiciones complejas, miles de partidas al azar pueden no capturar la sutileza de una posición. Esta sección presenta las mejoras que transformaron MCTS de un algoritmo prometedor en la herramienta que derrotó a los campeones mundiales.
1. RAVE: compartir información entre nodos
Rapid Action Value Estimation (RAVE), también conocido como AMAF (All Moves As First), aborda un problema práctico: al inicio, los nodos tienen muy pocas visitas y las estadísticas son poco confiables.
El problema
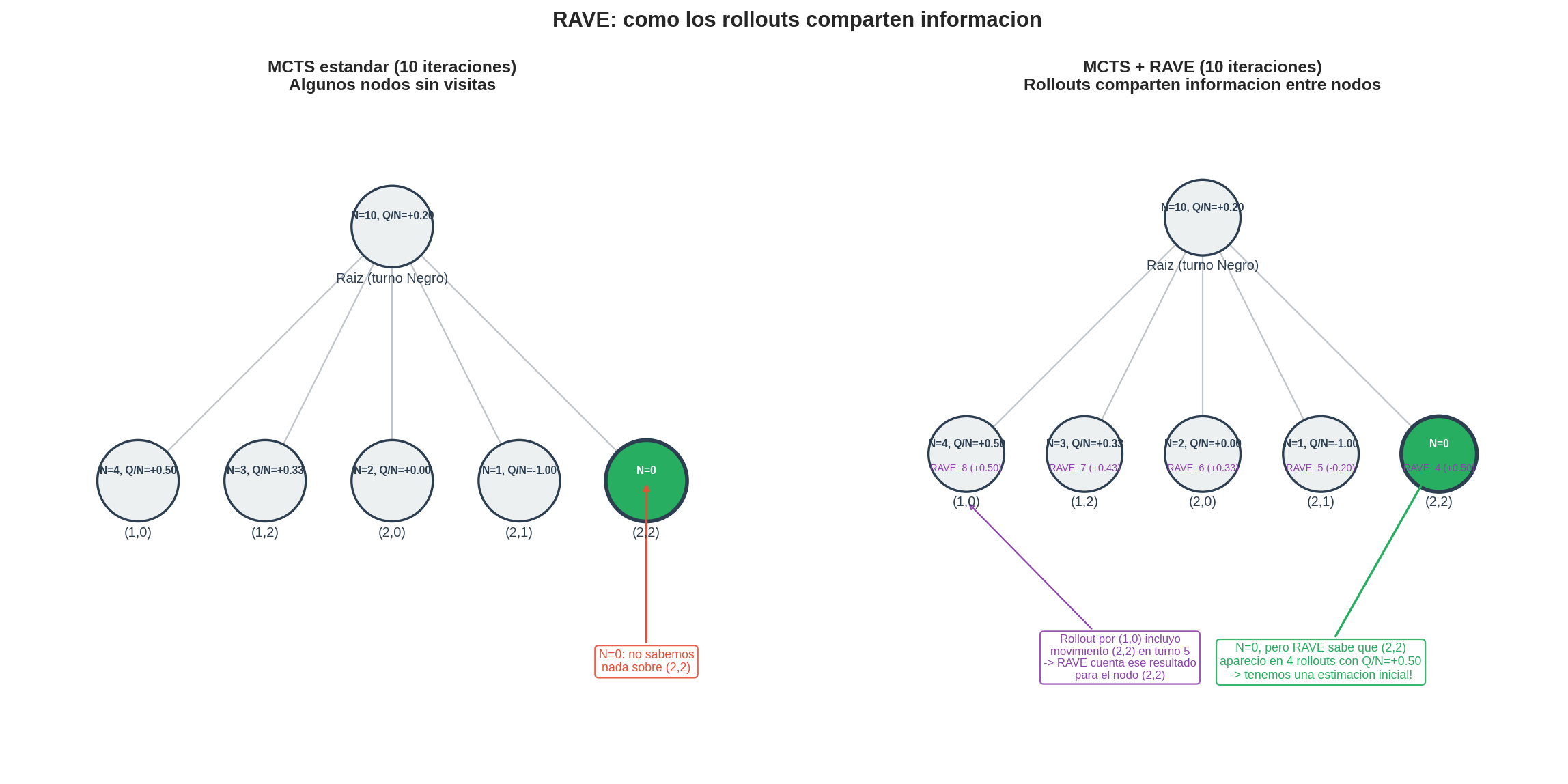
Imagina un árbol de MCTS después de 10 iteraciones en Hex 3×3. La raíz tiene 5 hijos (acciones legales). De esas 10 iteraciones, 4 fueron por el primer hijo, 3 por el segundo, 2 por el tercero, 1 por el cuarto — y 0 por el quinto. No sabemos nada sobre la celda $(2,2)$: $N = 0$, $Q = 0$.
Pero espera — en los 10 rollouts que hicimos a través de otros nodos, es probable que la celda $(2,2)$ haya aparecido como movimiento en alguno de esos rollouts. Si en 4 de los 10 rollouts se jugó $(2,2)$ (en el turno 5, o el 7, o el 3 — no importa cuándo), y el resultado fue $+1$ en 3 de esos 4, tenemos información útil sobre $(2,2)$ aunque nunca la hayamos seleccionado como primer movimiento.
La idea
RAVE recolecta esa información. Además de las estadísticas normales $Q(v)$ y $N(v)$, mantiene contadores $Q_{\text{RAVE}}(v)$ y $N_{\text{RAVE}}(v)$ que acumulan resultados de todos los rollouts donde la acción correspondiente a $v$ apareció en algún momento — sin importar si fue el primer movimiento o el décimo.
Ejemplo concreto
Supongamos que estamos en la raíz y hacemos un rollout a través del hijo $(1,0)$. La secuencia de movimientos del rollout es:
$$(1,0) \to (0,1) \to (2,2) \to (0,0) \to (2,0) \to \ldots \to \text{Negro gana} ;(+1)$$
En MCTS estándar, solo se actualiza el nodo $(1,0)$: $Q(1,0) \mathrel{+}= 1$, $N(1,0) \mathrel{+}= 1$.
En MCTS + RAVE, también se actualiza $Q_{\text{RAVE}}$ para $(2,2)$, $(2,0)$, y cualquier otro movimiento de Negro que haya aparecido en ese rollout:
| Nodo | Actualización estándar | Actualización RAVE |
|---|---|---|
| $(1,0)$ | $Q \mathrel{+}= 1$, $N \mathrel{+}= 1$ | $Q_R \mathrel{+}= 1$, $N_R \mathrel{+}= 1$ |
| $(2,2)$ | — (no fue seleccionado) | $Q_R \mathrel{+}= 1$, $N_R \mathrel{+}= 1$ |
| $(2,0)$ | — (no fue seleccionado) | $Q_R \mathrel{+}= 1$, $N_R \mathrel{+}= 1$ |
Después de 10 rollouts (a través de varios nodos), el nodo $(2,2)$ podría tener $N = 0$ pero $N_{\text{RAVE}} = 4$, $Q_{\text{RAVE}} = 3$ — una estimación inicial de $Q_R/N_R = 0.75$.
La fórmula de selección
RAVE combina la estimación propia del nodo con la estimación RAVE usando un peso $\beta$ que decrece con las visitas:
$$\text{valor}(v) = (1 - \beta) \cdot \frac{Q(v)}{N(v)} + \beta \cdot \frac{Q_{\text{RAVE}}(v)}{N_{\text{RAVE}}(v)} + c\sqrt{\frac{\ln N(\text{padre})}{N(v)}}$$
- Cuando $N(v)$ es bajo: $\beta \approx 1$, RAVE domina. La información compartida llena el vacío hasta que el nodo tenga suficientes visitas propias
- Cuando $N(v)$ es alto: $\beta \approx 0$, las estadísticas propias del nodo dominan. RAVE es una aproximación (el orden de los movimientos sí importa), así que conviene confiar en los datos directos cuando los hay
Una fórmula común para $\beta$:
$$\beta = \frac{k}{k + 3N(v)}$$
donde $k$ es un parámetro (típicamente $k \approx 1000$). Con $k = 1000$: si $N(v) = 0$, $\beta = 1$ (puro RAVE); si $N(v) = 100$, $\beta = 0.77$; si $N(v) = 1000$, $\beta = 0.25$.
¿Por qué funciona?
La suposición clave de RAVE es que el valor de un movimiento no depende mucho de cuándo se juega. En Go y Hex, jugar en la celda $(3,4)$ tiende a ser bueno o malo independientemente de si es el primer movimiento o el quinto. Esta suposición es aproximada (el contexto importa), pero es suficientemente buena para dar una estimación inicial razonable cuando no tenemos nada mejor.
Efecto práctico: RAVE acelera la convergencia de MCTS significativamente en las primeras iteraciones — especialmente en juegos con alto factor de ramificación como Go ($b \approx 250$), donde sin RAVE muchos nodos tardarían cientos de iteraciones en recibir su primera visita directa.
2. De rollouts aleatorios a evaluación neuronal
El siguiente salto es reemplazar los rollouts aleatorios [M3] por algo más informado.
2.1 El problema con los rollouts aleatorios
Los rollouts aleatorios son un estimador Monte Carlo sin sesgo (§12.2), pero tienen alta varianza. Imagina una posición de Go donde Negro tiene una ventaja sutil — un grupo débil de Blanco que se puede atacar. En un rollout aleatorio, Negro necesitaría jugar una secuencia precisa de 5-6 movimientos para capturar ese grupo. La probabilidad de que eso ocurra por azar es minúscula. Así que los rollouts “no ven” esa ventaja, y la evaluación es ruidosa.
Recordemos del módulo 12 que el error del estimador Monte Carlo es $O(\sigma / \sqrt{n})$, donde $\sigma$ es la desviación estándar. Si la varianza de los rollouts es alta ($\sigma$ grande), necesitamos muchos más rollouts para la misma precisión:
| Varianza del evaluador | Rollouts para error < 0.05 | Tiempo (a 10μs/rollout) |
|---|---|---|
| $\sigma = 1.0$ (aleatorio) | ~400 | 4 ms |
| $\sigma = 0.5$ (patrones) | ~100 | 1 ms |
| $\sigma = 0.1$ (red neuronal) | ~4 | 40 μs |
| $\sigma = 0$ (perfecto) | 1 | 10 μs |
2.2 Rollouts con política aprendida
En vez de elegir movimientos uniformemente al azar durante el rollout, usar una política de rollout entrenada: una función rápida que elige movimientos “razonables” en lugar de aleatorios.
Ejemplo concreto para Hex: en vez de elegir entre las $\sim$30 celdas vacías con probabilidad uniforme, la política podría asignar más probabilidad a celdas adyacentes a piedras existentes (donde es más probable que los movimientos sean relevantes). Los primeros programas fuertes de Go (como MoGo, 2006) usaban patrones locales aprendidos de partidas de expertos.
Esto reduce la varianza sin eliminar los rollouts — los rollouts son más “realistas” aunque siguen siendo rápidos.
2.3 Red de valor: eliminar los rollouts
La idea más radical: no hacer rollouts. En su lugar, evaluar la posición directamente con una red neuronal $v_\theta(s)$ entrenada para predecir el resultado del juego desde cualquier posición:
| Rollouts aleatorios | Rollouts con política | Red de valor | |
|---|---|---|---|
| Conocimiento | Ninguno | Patrones locales | Posición completa |
| Velocidad | ~$\mu$s por rollout | ~$\mu$s por rollout | ~ms por evaluación |
| Calidad | Ruidosa ($\sigma \approx 1$) | Mejor ($\sigma \approx 0.5$) | Mucho mejor ($\sigma \approx 0.1$) |
| Entrenamiento | No necesita | Datos de expertos | Datos + auto-juego |
| Rollouts por nodo | Cientos–miles | Decenas–cientos | Uno (la red) |
La red de valor es más lenta por evaluación individual, pero como cada evaluación es mucho más precisa, se necesitan muchas menos iteraciones de MCTS para tomar buenas decisiones. El tradeoff es favorable: una evaluación de red a 1ms que vale tanto como 100 rollouts de 10μs.
3. AlphaGo (2016): MCTS + redes neuronales
AlphaGo, desarrollado por DeepMind, combinó MCTS con dos redes neuronales:
Red de política $p_\sigma(a \mid s)$: predice qué movimientos jugaría un experto humano. Entrenada con millones de partidas de Go profesional. Se usa para:
- Guiar la fase de selección
[M1]— como prior sobre qué hijos explorar primero - Mejorar los rollouts
[M3]— política de rollout en lugar de aleatoria
Red de valor $v_\theta(s)$: predice quién va a ganar desde la posición $s$. Entrenada primero con partidas humanas, luego refinada con auto-juego. Se usa para:
- Evaluar nodos hoja sin necesidad de rollout completo
- En la práctica, AlphaGo combinaba ambas: $V(s) = (1-\lambda) \cdot v_\theta(s) + \lambda \cdot \text{rollout}(s)$
La fórmula PUCT: UCT con prior
AlphaGo no usa UCT directamente — usa PUCT (Predictor + UCT), que incorpora el prior de la red de política en el término de exploración:
$$\text{PUCT}(v) = \frac{Q(v)}{N(v)} + c \cdot P(v) \cdot \frac{\sqrt{N(\text{padre})}}{1 + N(v)}$$
Comparemos con UCT:
| UCT (§18.4) | PUCT (AlphaGo) | |
|---|---|---|
| Exploración | $c \sqrt{\frac{\ln N(\text{padre})}{N(v)}}$ | $c \cdot P(v) \cdot \frac{\sqrt{N(\text{padre})}}{1 + N(v)}$ |
| Prior | Uniforme (todos los hijos iguales) | $P(v)$ de la red de política |
| Efecto | Explora todos por igual | Explora primero donde la red dice |
La diferencia clave es $P(v)$: la probabilidad que la red de política asigna a la acción $v$. Si la red cree que una acción es buena ($P = 0.50$), recibe un bonus de exploración 5 veces mayor que una acción con $P = 0.10$.
Ejemplo concreto: PUCT vs UCT
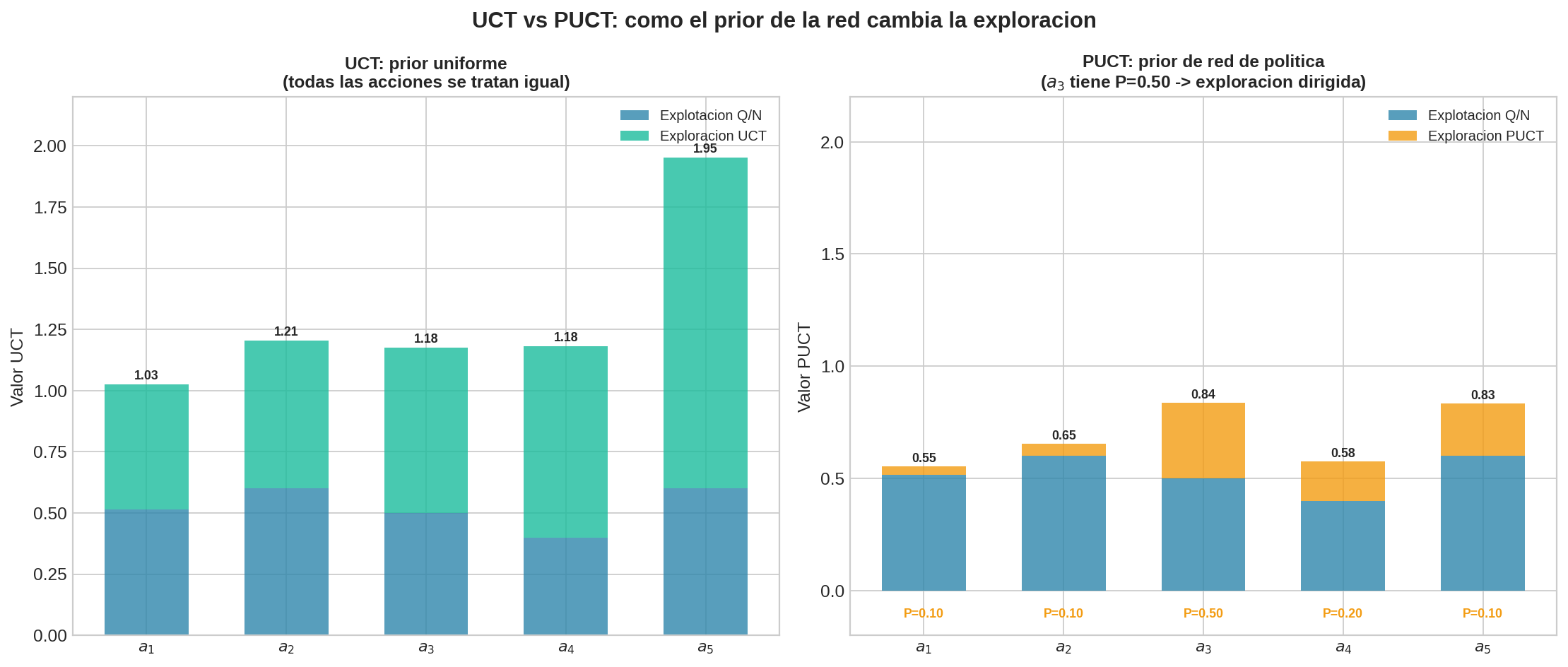
Supongamos 5 acciones con $N(\text{padre}) = 100$ y la red de política asigna $P(a_3) = 0.50$ (cree que $a_3$ es el mejor movimiento):
| Acción | $N$ | $Q/N$ | Exploración UCT | Exploración PUCT ($P$) | UCT total | PUCT total |
|---|---|---|---|---|---|---|
| $a_1$ | 35 | 0.51 | 0.50 | $0.10 \times 0.28 = 0.03$ | 1.01 | 0.54 |
| $a_2$ | 25 | 0.60 | 0.57 | $0.10 \times 0.38 = 0.04$ | 1.17 | 0.64 |
| $a_3$ | 20 | 0.50 | 0.64 | $0.50 \times 0.48 = 0.24$ | 1.14 | 0.74 |
| $a_4$ | 15 | 0.40 | 0.72 | $0.20 \times 0.63 = 0.13$ | 1.12 | 0.53 |
| $a_5$ | 5 | 0.60 | 1.31 | $0.10 \times 1.67 = 0.17$ | 1.91 | 0.77 |
- UCT elige $a_5$ (5 visitas → bonus enorme), luego $a_2$. Trata todas las acciones por igual — $a_5$ gana solo porque tiene pocas visitas.
- PUCT elige $a_5$ también (pocas visitas ayudan), pero $a_3$ queda en segundo lugar gracias a su prior alto ($P = 0.50$). La red “le dice” a MCTS dónde buscar primero.
El efecto acumulativo: con PUCT, MCTS dedica más iteraciones a las acciones que la red considera prometedoras, y menos a las que la red descarta. Esto es como tener un “experto” que te orienta antes de que empieces a buscar — no reemplaza la búsqueda, pero la guía enormemente.
Resultado: en marzo de 2016, AlphaGo derrotó a Lee Sedol (campeón mundial de Go) 4-1 en un match de 5 partidas. Fue la primera vez que un programa venció a un jugador profesional de Go en un tablero completo (19×19).
4. AlphaZero (2018): auto-juego puro
AlphaZero simplificó radicalmente la arquitectura de AlphaGo:
| Aspecto | AlphaGo (2016) | AlphaZero (2018) |
|---|---|---|
| Redes | Dos separadas (política + valor) | Una sola red con dos cabezas |
| Datos de entrenamiento | Millones de partidas humanas | Ninguno — solo auto-juego |
| Rollouts | Sí (combinados con red de valor) | No — solo red de valor |
| Conocimiento humano | Partidas de expertos + features manuales | Solo las reglas del juego |
| Juegos | Solo Go | Go, ajedrez y shogi |
La red dual: política + valor en una sola red
AlphaZero usa una sola red neuronal $f_\theta(s) = (p, v)$ que recibe el estado del juego y produce dos salidas simultáneamente:
- $p$ (política): un vector de probabilidades sobre todas las acciones legales. Ejemplo en Hex 7×7: un vector de 49 componentes donde $p_i$ indica la probabilidad de jugar en la celda $i$
- $v$ (valor): un escalar en $[-1, +1]$ que predice quién va a ganar desde esa posición
Esto reemplaza los dos componentes que antes eran separados: la política de rollout/selección y la función de evaluación.
El ciclo de auto-juego
AlphaZero aprende desde cero con un ciclo de tres pasos que se repite miles de veces:
Paso 1 — Jugar: la red actual $f_\theta$ juega partidas contra sí misma. En cada turno, usa MCTS con PUCT (la red proporciona $p$ para la selección y $v$ para la evaluación de hojas). Después de $M$ iteraciones de MCTS, elige la acción proporcional a las visitas $N(v)$. Almacena cada posición $s_t$, la distribución de visitas $\pi_t$, y el resultado final $z$ de la partida.
Paso 2 — Aprender: usa las tripletas $(s_t, \pi_t, z)$ como datos de entrenamiento. La red aprende a:
- Predecir $\pi_t$ (la distribución de búsqueda de MCTS) con su cabeza de política $p$
- Predecir $z$ (el resultado final) con su cabeza de valor $v$
La función de pérdida combina ambos objetivos:
$$\mathcal{L} = (z - v)^2 - \pi^T \ln p + \lambda |\theta|^2$$
El primer término es error cuadrático en el valor; el segundo es entropía cruzada en la política; el tercero es regularización.
Paso 3 — Repetir: la red actualizada juega nuevas partidas contra sí misma. Como la red es mejor, las partidas son de mayor calidad → los datos de entrenamiento son mejores → la siguiente red es aún más fuerte. Cada ciclo produce una red más fuerte que la anterior.
¿Por qué funciona el auto-juego?
La clave es que MCTS es más fuerte que la red sola. Incluso con una red mediocre, MCTS + PUCT con 800 iteraciones juega mejor que la red evaluando posiciones directamente (sin búsqueda). Esto significa que las distribuciones $\pi_t$ generadas por MCTS son mejores que lo que la red predice actualmente — son un “profesor” ligeramente más fuerte que el “alumno”. Al entrenar la red para imitar a MCTS, la red mejora. Y con una red mejor, MCTS es aún más fuerte → el ciclo se refuerza.
Es como un estudiante que resuelve problemas con ayuda (MCTS = búsqueda) y luego estudia sus propias soluciones para internalizar los patrones (entrenamiento de la red). Cada ronda de estudio lo hace más capaz, así que los problemas que resuelve después son más sofisticados.
Después de ~4 horas de auto-juego en ajedrez (usando 5000 TPUs), AlphaZero derrotó a Stockfish — el motor de ajedrez más fuerte del mundo, resultado de décadas de ingeniería humana.
5. La evolución completa

| Sistema | Año | Búsqueda | Evaluación | Datos | Resultado |
|---|---|---|---|---|---|
| Deep Blue | 1997 | Alpha-beta | Manual (~8000 features) | Ninguno | Derrotó a Kasparov |
| Stockfish | 2023 | Alpha-beta | NNUE (red neuronal) | Partidas + auto-juego | Motor más fuerte (código abierto) |
| AlphaGo | 2016 | MCTS + PUCT | Redes (política + valor) | Partidas humanas + auto-juego | Derrotó a Lee Sedol (Go) |
| AlphaZero | 2018 | MCTS + PUCT | Red dual (pol. + val.) | Solo auto-juego | Derrotó a Stockfish y AlphaGo |
El patrón es el mismo en todos los casos: árbol de búsqueda + evaluación de posiciones. Lo que evolucionó fue:
- La búsqueda: de alpha-beta (exhaustiva) a MCTS (selectiva)
- La evaluación: de manual a aprendida
- Los datos: de conocimiento humano a auto-juego
6. Tabla comparativa final
| Minimax (§15.3) | Alpha-beta (§15.4) | MCTS + UCT (§18.3-4) | AlphaZero | |
|---|---|---|---|---|
| Búsqueda | Exhaustiva | Exhaustiva con poda | Selectiva (asimétrica) | Selectiva + prior |
| Evaluación | Exacta (hojas) | Heurística eval(s) |
Rollouts aleatorios | Red neuronal |
| Conocimiento | Reglas | Reglas + expertise | Solo reglas | Solo reglas |
| Óptimo | Sí | Sí | Asintóticamente | Asintóticamente |
| Anytime | No | No | Sí | Sí |
| Complejidad | $O(b^m)$ | $O(b^{m/2})$ | $O(M \cdot m)$ | $O(M \cdot m)$ |
| Go | Imposible | Imposible | Fuerte | Superhuman |
| Ajedrez | Imposible | Muy fuerte | Moderado | Superhuman |
| Hex 7×7 | Imposible | Con eval | Fuerte | — |
7. Hacia adelante: el torneo de Hex
Los módulos 15–18 construyen una progresión:
| Módulo | Herramienta | Limitación |
|---|---|---|
| 15 | Minimax, alpha-beta | Requieren árbol completo o eval manual |
| 17 | UCB1, Thompson Sampling | Un solo nivel de decisiones |
| 18 | MCTS + UCT | Árboles grandes, sin eval, anytime |
Todo esto converge en una pregunta práctica: ¿qué tan buen agente de Hex puedes construir?
En un proyecto futuro, cada estudiante implementará un agente de Hex que compita en un torneo round-robin. El formato: Hex 7×7, cada agente tiene 1 segundo por movimiento, todos contra todos. El agente recibe el estado del juego y debe retornar una acción dentro del tiempo límite — la interfaz es una función elegir_accion(estado, tiempo_limite). El ranking final se basa en victorias totales, como una liga de fútbol.
Las herramientas están sobre la mesa: MCTS con UCT es la base, pero hay mucho espacio para innovar — ajustar $c$, implementar RAVE, mejorar la política de rollout, reutilizar el árbol entre movimientos, o incluso entrenar una red de valor simple. La teoría de los módulos 12, 15 y 17 es el fundamento; la creatividad del estudiante determina el resultado.
Resumen del módulo
| Sección | Tema | Idea central |
|---|---|---|
| 18.1 | Más allá de minimax | Los rollouts aleatorios evalúan posiciones sin dominio — son el estimador MC del módulo 12 |
| 18.2 | Hex: el juego | Reglas simples, sin empates, sin eval conocido — el juego ideal para MCTS |
| 18.3 | MCTS | Cuatro fases: selección, expansión, simulación, retropropagación |
| 18.4 | UCT | UCB1 (módulo 17) aplicado a la selección → exploración eficiente del árbol |
| 18.5 | MCTS en acción | Convergencia en 3×3, dominio sobre alpha-beta en 7×7, efecto de $c$ e iteraciones |
| 18.6 | Más allá | De rollouts a redes neuronales: RAVE, PUCT, AlphaGo → AlphaZero |
Las tres ideas fundamentales del módulo:
- Simulación como evaluación: no necesitas saber qué es una buena posición — solo necesitas las reglas del juego y la capacidad de simular partidas aleatorias
- Búsqueda selectiva: MCTS invierte su presupuesto donde importa, a diferencia de minimax que explora uniformemente. El árbol asimétrico es una señal de inteligencia
- La conexión UCB1 → UCT: el balance exploración-explotación del módulo 17 es exactamente lo que hace funcionar la selección de MCTS. Los bandidos multibrazo no son un tema aislado — son la pieza clave del algoritmo que derrotó al campeón mundial de Go