| Notebook | Colab |
|---|---|
| Notebook 03 — UCT y experimentos |
18.4 — UCT: la conexión con bandidos
“The crucial idea is to treat each node of the search tree as an independent bandit problem.” — Levente Kocsis & Csaba Szepesvári (2006)
En §18.3 usamos una política de selección simple: elegir el hijo con mayor $Q/N$. Eso es pura explotación — repite lo que ya funcionó, sin explorar alternativas. En el módulo 17 aprendimos que eso es un error: un brazo con pocos jalones puede tener una media real superior a la estimada. La solución fue UCB1: añadir un bonus de exploración a los brazos poco visitados.
UCT (Upper Confidence bounds applied to Trees) aplica exactamente la misma idea a los nodos del árbol de MCTS. Propuesto por Kocsis y Szepesvári en 2006, fue un ingrediente clave en la revolución de AlphaGo.
1. Cada nodo es un bandido
La observación central es que cada nodo interno del árbol de MCTS es un problema de bandidos independiente:
| Concepto bandidos (§17) | Concepto en MCTS |
|---|---|
| Brazos $i = 1, \ldots, K$ | Acciones legales desde el nodo |
| Jalar el brazo $i$ | Elegir la acción $i$ y expandir/simular |
| Recompensa $r_t$ | Resultado del rollout ($+1$ o $-1$) |
| Jalones $N_i(t)$ | Visitas al hijo $N(v_i)$ |
| Media estimada $\hat\mu_i$ | Tasa de éxito $Q(v_i)/N(v_i)$ |
| Regret | Rollouts invertidos en acciones subóptimas |
En el módulo 17, UCB1 resolvió este problema con la fórmula:
$$A_t = \arg\max_i \left[ \hat\mu_i(t) + \sqrt{\frac{2 \ln t}{N_i(t)}} \right]$$
UCT usa la misma estructura para elegir qué hijo visitar.
2. La fórmula UCT
2.1. Recordatorio: $N$, $Q$ y qué es una “visita”
Antes de ver la fórmula, aclaremos la terminología. Cada nodo $v$ del árbol almacena dos contadores:
- $N(v)$: el número de visitas — cuántas veces un rollout ha pasado a través de este nodo (es decir, cuántas veces este nodo estuvo en el camino selección → expansión → simulación → retropropagación)
- $Q(v)$: la suma de recompensas acumuladas por esos rollouts (cada rollout aporta $+1$ si ganó o $-1$ si perdió)
Una visita no es solo “mirar” un nodo — es un ciclo completo [M1]→[M2]→[M3]→[M4] que pasó por ese nodo. Cuando decimos “el nodo tiene $N = 40$”, significa que 40 iteraciones completas de MCTS incluyeron ese nodo en su camino de selección.
La tasa de éxito de un nodo es $Q(v)/N(v)$: la fracción de rollouts que resultaron en victoria. Si $N = 40$ y $Q = 28$, entonces $Q/N = 0.70$ — el 70% de los rollouts que pasaron por ese nodo terminaron ganando.
2.2. La fórmula
En cada nodo durante la fase de selección [M1], elegimos el hijo $v$ que maximiza:
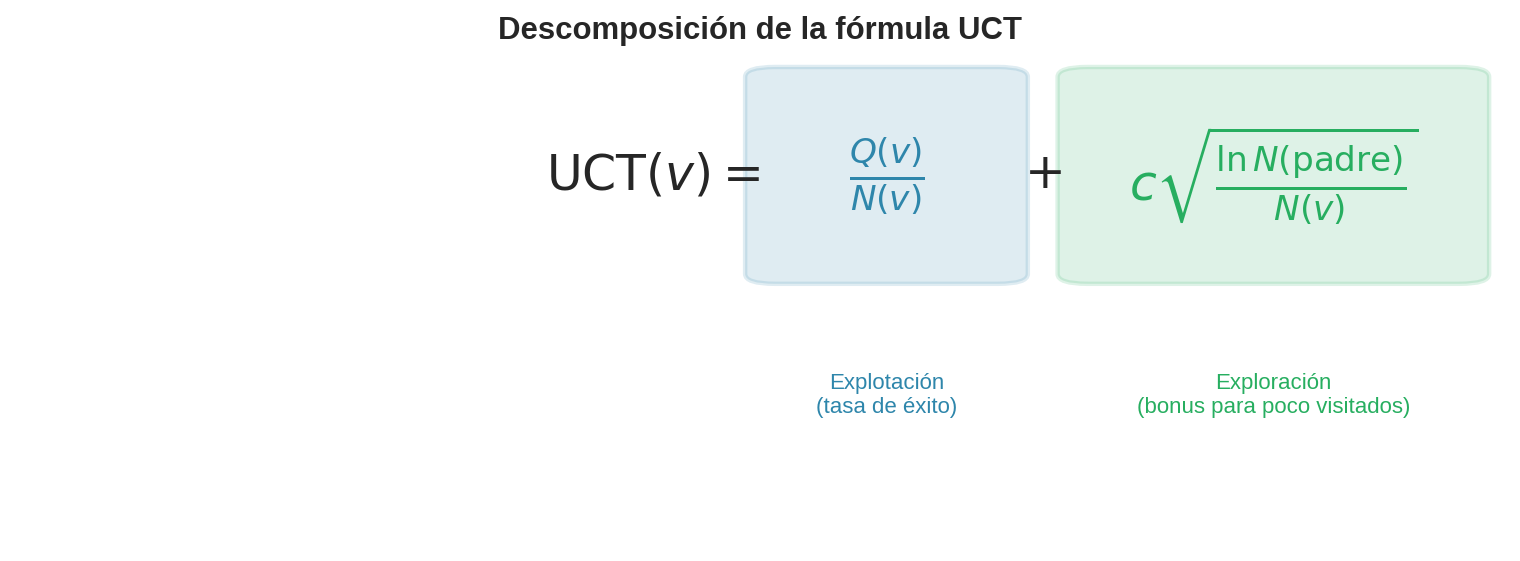
$$\text{UCT}(v) = \frac{Q(v)}{N(v)} + c \sqrt{\frac{\ln N(\text{padre})}{N(v)}}$$
donde el primer término es la explotación y el segundo es la exploración.
2.3. Término por término
Término de explotación $Q(v)/N(v)$: la tasa de éxito promedio del nodo. Favorece nodos con buenos resultados — los que han ganado más rollouts.
Término de exploración $c\sqrt{\ln N(\text{padre}) / N(v)}$: este término es un bonus que hace más atractivos a los nodos poco visitados. Tiene dos partes que vale la pena descomponer:
- El denominador $N(v)$ (visitas al hijo): cuanto menos visitado sea un nodo, mayor es el bonus. Si un hijo tiene 2 visitas y otro tiene 200, el primero recibe un bonus mucho más grande — forzando al algoritmo a no ignorarlo sin evidencia suficiente.
- El numerador $\ln N(\text{padre})$ (log de visitas totales al padre): crece con el tiempo, pero logarítmicamente. Esto significa que el bonus de exploración nunca desaparece del todo — siempre hay un incentivo para revisitar nodos olvidados — pero crece tan lento que eventualmente la explotación domina. Después de 100 visitas al padre, $\ln(100) \approx 4.6$; después de 10,000 visitas, $\ln(10{,}000) \approx 9.2$. Se duplicó el bonus, pero las visitas se multiplicaron por 100.
- El cociente $\ln N(\text{padre}) / N(v)$: compara cuánto se ha jugado en total desde este nodo padre versus cuánto se ha invertido en este hijo en particular. Si el padre tiene 1000 visitas y un hijo solo tiene 3, el cociente es grande → ese hijo merece más atención. Es la misma lógica que en UCB1 (§17.3): un brazo poco jalado tiene alta incertidumbre y merece el beneficio de la duda.
La constante $c$: controla el balance entre explotación y exploración. Es exactamente el mismo rol que $\varepsilon$ jugaba en $\varepsilon$-greedy (§17.2) — pero de forma más elegante:
| Valor de $c$ | Efecto |
|---|---|
| $c \to 0$ | Pura explotación (como $\varepsilon = 0$): siempre elige el mejor $Q/N$ |
| $c = \sqrt{2}$ | Valor teórico óptimo (derivado de Hoeffding, §17.3) |
| $c$ grande | Exceso de exploración: visita todos los nodos casi por igual |
En la práctica, $c$ se ajusta empíricamente. Para recompensas en $[0, 1]$, valores de $c$ entre 0.5 y 1.5 suelen funcionar bien.
2.4. Una iteración completa, paso a paso
Para entender cómo funciona UCT en la práctica, tracemos la iteración 101 de MCTS con $c = 1.41$ en un árbol que ya tiene 100 iteraciones acumuladas. Esta traza cubre las cuatro fases — selección, expansión, simulación y retropropagación — en un solo ciclo completo.
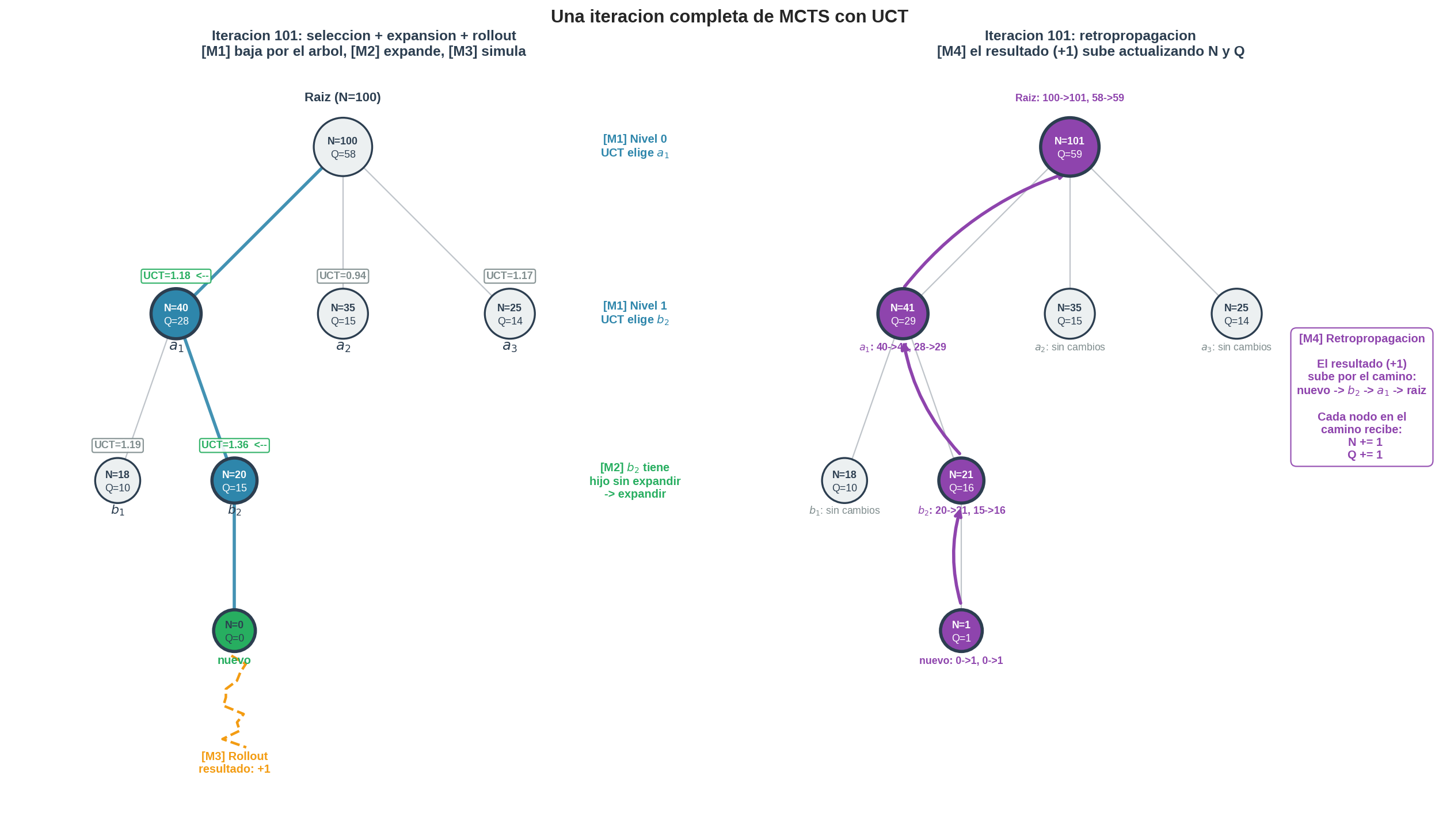
El estado del árbol antes de la iteración 101 es:
Raíz (N=100, Q=58)
/ | \
a₁(40,28) a₂(35,15) a₃(25,14)
/ \
b₁(18,10) b₂(20,15)
Cada par $(N, Q)$ representa las visitas y victorias acumuladas en 100 iteraciones previas. Veamos qué pasa en la iteración 101.
Paso 1 — [M1] Selección, nivel 0: la raíz
La selección empieza en la raíz. Todos sus hijos están expandidos, así que calculamos UCT para cada uno usando $N(\text{padre}) = N(\text{raíz}) = 100$:
| Hijo | $N(v)$ | $Q(v)$ | $\frac{Q}{N}$ | $1.41\sqrt{\frac{\ln(100)}{N}}$ | UCT |
|---|---|---|---|---|---|
| $a_1$ | 40 | 28 | 0.70 | $1.41 \times \sqrt{4.60/40} = 0.48$ | 1.18 |
| $a_2$ | 35 | 15 | 0.43 | $1.41 \times \sqrt{4.60/35} = 0.51$ | 0.94 |
| $a_3$ | 25 | 14 | 0.56 | $1.41 \times \sqrt{4.60/25} = 0.60$ | 1.16 |
$a_1$ gana con UCT $= 1.18$. Tiene la mejor tasa de éxito (70%) y visitas suficientes para que su estimación sea confiable. La selección baja a $a_1$.
Observa que $a_3$ tiene un bonus de exploración mayor que $a_1$ (0.60 vs 0.48) porque tiene menos visitas (25 vs 40), pero no le alcanza para compensar la diferencia en explotación. Si $a_3$ tuviera, digamos, solo 5 visitas, su bonus sería $\approx 1.35$ y ganaría por lejos — UCT obligaría a explorarlo antes de descartarlo.
Paso 2 — [M1] Selección, nivel 1: dentro de $a_1$
Ahora estamos en $a_1$. La selección se repite con un nuevo $N(\text{padre})$: esta vez es $N(a_1) = 40$, no el $N$ de la raíz. Los hijos de $a_1$ son $b_1$ y $b_2$:
| Nieto | $N(v)$ | $Q(v)$ | $\frac{Q}{N}$ | $1.41\sqrt{\frac{\ln(40)}{N}}$ | UCT |
|---|---|---|---|---|---|
| $b_1$ | 18 | 10 | 0.56 | $1.41 \times \sqrt{3.69/18} = 0.64$ | 1.19 |
| $b_2$ | 20 | 15 | 0.75 | $1.41 \times \sqrt{3.69/20} = 0.61$ | 1.36 |
$b_2$ gana con UCT $= 1.36$. Tiene mejor tasa de éxito (75% vs 56%) y un bonus de exploración similar. La selección baja a $b_2$.
Lo crucial: en cada nivel, $N(\text{padre})$ cambia. En la raíz usamos $N = 100$; en $a_1$ usamos $N = 40$. Cada nodo es un bandido independiente con su propio “reloj”.
Paso 3 — [M2] Expansión: $b_2$ tiene un hijo sin expandir
La selección llega a $b_2$ y encuentra que tiene una acción legal que aún no tiene nodo en el árbol. Aquí la selección se detiene y pasamos a la fase de expansión: creamos un nuevo nodo como hijo de $b_2$, con $N = 0$ y $Q = 0$.
b₂(20,15)
|
nuevo(0,0) <-- nodo recién creado
Paso 4 — [M3] Simulación (rollout)
Desde el estado del nodo recién creado, ejecutamos un rollout: jugamos movimientos aleatorios hasta que la partida termine. En este ejemplo, el rollout termina con victoria para nuestro jugador → resultado $= +1$.
Paso 5 — [M4] Retropropagación
El resultado del rollout ($+1$) sube por el camino que recorrimos: nuevo → $b_2$ → $a_1$ → raíz. Cada nodo en el camino recibe:
- $N \mathrel{+}= 1$ (una visita más)
- $Q \mathrel{+}= 1$ (una victoria más, porque el rollout dio $+1$)
Los nodos que no están en el camino ($a_2$, $a_3$, $b_1$) no se modifican.
| Nodo | Antes | Después | Cambio |
|---|---|---|---|
| Raíz | $(100, 58)$ | $(101, 59)$ | $N{+}1, Q{+}1$ |
| $a_1$ | $(40, 28)$ | $(41, 29)$ | $N{+}1, Q{+}1$ |
| $b_2$ | $(20, 15)$ | $(21, 16)$ | $N{+}1, Q{+}1$ |
| nuevo | $(0, 0)$ | $(1, 1)$ | $N{+}1, Q{+}1$ |
| $a_2$ | $(35, 15)$ | $(35, 15)$ | sin cambios |
| $a_3$ | $(25, 14)$ | $(25, 14)$ | sin cambios |
| $b_1$ | $(18, 10)$ | $(18, 10)$ | sin cambios |
Si el rollout hubiera dado $-1$ (derrota), los nodos en el camino recibirían $N \mathrel{+}= 1$ pero $Q \mathrel{-}= 1$: la visita se cuenta, pero la recompensa es negativa.
Esto es una iteración. MCTS repite este ciclo $M$ veces (típicamente 500–2000), y cada iteración actualiza una rama distinta del árbol, acumulando evidencia sobre qué acciones son buenas.
2.5. Caso borde — $N(v) = 0$
¿Qué pasa si un hijo nunca ha sido visitado? El denominador $N(v) = 0$ haría la fracción indefinida. La convención es:
$$N(v) = 0 \implies \text{UCT}(v) = +\infty$$
Los nodos no visitados tienen prioridad absoluta. Si un nodo padre tiene 3 hijos expandidos y uno con $N = 0$, ese hijo se elige sin calcular nada más. Esto tiene una consecuencia práctica: cada vez que [M2] crea un nodo nuevo, la siguiente iteración que pase por su padre lo visitará inmediatamente (porque tiene $\text{UCT} = \infty$).
En la traza anterior, el nodo “nuevo” quedó con $N = 1$ después de la retropropagación. En la iteración 102, si la selección vuelve a $b_2$ y $b_2$ tiene otro hijo sin expandir, ese hijo tendría $N = 0$ y se elegiría automáticamente — sin importar que el nodo “nuevo” tenga $Q/N = 1.0$.
2.6. La constante $c$ y el balance exploración-explotación
Para cerrar, veamos cómo $c$ afecta la selección en el mismo árbol de nuestro ejemplo:
| $c$ | UCT($a_1$) | UCT($a_2$) | UCT($a_3$) | Elegido | Comportamiento |
|---|---|---|---|---|---|
| 0 | 0.70 | 0.43 | 0.56 | $a_1$ | Pura explotación: siempre el mejor $Q/N$ |
| 0.5 | 0.87 | 0.61 | 0.77 | $a_1$ | Explotación domina, pero con algo de corrección |
| 1.41 | 1.18 | 0.94 | 1.16 | $a_1$ | Balance — $a_3$ está cerca, será explorado pronto |
| 5.0 | 2.40 | 2.24 | 2.71 | $a_3$ | Exploración domina: el menos visitado gana |
Con $c = 0$, MCTS siempre elige $a_1$ (mejor $Q/N$) y nunca descubre si $a_2$ o $a_3$ son mejores — es el problema de pura explotación del módulo 17. Con $c = 5$, siempre elige el menos visitado, gastando rollouts en acciones malas. El valor $c = \sqrt{2} \approx 1.41$ mantiene las diferencias entre nodos mientras da oportunidades proporcionales a la incertidumbre.
3. Comparación con UCB1
Pongamos las fórmulas lado a lado para ver que son la misma idea:
| UCB1 (§17.3) | UCT (§18.4) | |
|---|---|---|
| Fórmula | $\hat\mu_i + \sqrt{\frac{2 \ln t}{N_i(t)}}$ | $\frac{Q(v)}{N(v)} + c\sqrt{\frac{\ln N(\text{padre})}{N(v)}}$ |
| Media estimada | $\hat\mu_i = \frac{1}{N_i}\sum r$ | $\frac{Q(v)}{N(v)}$ |
| Exploración | $\sqrt{\frac{2 \ln t}{N_i(t)}}$ | $c\sqrt{\frac{\ln N(\text{padre})}{N(v)}}$ |
| $t$ (tiempo total) | Rondas totales | $N(\text{padre})$ = visitas al nodo padre |
| $N_i$ (visitas) | Jalones del brazo $i$ | Visitas al hijo $v$ |
La única diferencia es que en bandidos hay un solo nivel ($t$ rondas, $K$ brazos), mientras que en MCTS hay muchos niveles — cada nodo es su propio bandido, con su propio “reloj” $N(\text{padre})$.
En §17.3 demostramos que UCB1 alcanza regret $O(\sqrt{K \ln T})$. Esto es exactamente por qué UCT explora eficientemente: en cada nodo, el regret de la selección crece solo logarítmicamente.
4. Pseudocódigo: solo cambia [M1]
El cambio de MCTS vanilla a MCTS con UCT es mínimo — solo la función MEJOR_HIJO:
# ── MEJOR_HIJO_UCT ───────────────────────────────────────────────────────────
# Reemplaza MEJOR_HIJO de §18.3.
# La ÚNICA diferencia con MCTS vanilla. [U1]
función MEJOR_HIJO_UCT(v, c):
retornar argmax sobre hijo en v.hijos.valores() de:
hijo.Q / hijo.N + c × √(ln(v.N) / hijo.N) # [U1] UCB1
El resto del algoritmo — expansión [M2], simulación [M3], retropropagación [M4] — es idéntico al de §18.3. Solo cambia la línea marcada [U1].
# ── MCTS con UCT ─────────────────────────────────────────────────────────────
# Idéntico a MCTS de §18.3, excepto por [U1].
función MCTS_UCT(juego, estado, M, c = √2):
raíz ← crear_nodo(estado)
para i = 1, …, M:
# ── [M1] Selección (MODIFICADA) ──────────────────────────────────
v ← raíz
mientras v.no_expandidos está vacío y v.hijos no está vacío:
v ← MEJOR_HIJO_UCT(v, c) # [U1] UCT en lugar de Q/N
# ── [M2] Expansión (sin cambios) ────────────────────────────────
si v.no_expandidos no está vacío:
a ← sacar_uno(v.no_expandidos)
hijo ← crear_nodo(juego.resultado(v.estado, a))
hijo.padre ← v
v.hijos[a] ← hijo
v ← hijo
# ── [M3] Simulación (sin cambios) ───────────────────────────────
resultado ← ROLLOUT(juego, v.estado, juego.turno(raíz.estado))
# ── [M4] Retropropagación (sin cambios) ─────────────────────────
mientras v ≠ None:
v.N ← v.N + 1
v.Q ← v.Q + resultado_para(v, resultado)
v ← v.padre
retornar acción en raíz.hijos con mayor raíz.hijos[acción].N
5. Implementación en Python
import math, random, copy
class MCTSNode:
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = {}
self.N = 0
self.Q = 0.0
self.unexpanded = list(state.actions())
def uct_value(child, parent_visits, c):
"""Fórmula UCT: explotación + exploración."""
if child.N == 0:
return float('inf') # nodo no visitado → prioridad máxima
return child.Q / child.N + c * math.sqrt(math.log(parent_visits) / child.N)
def mcts_uct(game_state, iterations, player, c=1.41):
root = MCTSNode(game_state)
for _ in range(iterations):
node = root
# [M1] Selección con UCT [U1]
while not node.unexpanded and node.children:
node = max(node.children.values(),
key=lambda ch: uct_value(ch, node.N, c))
# [M2] Expansión
if node.unexpanded:
action = node.unexpanded.pop()
child_state = node.state.result(action)
child = MCTSNode(child_state, parent=node)
node.children[action] = child
node = child
# [M3] Simulación
sim = copy.deepcopy(node.state)
while not sim.is_terminal():
sim = sim.result(random.choice(sim.actions()))
reward = sim.utility(player)
# [M4] Retropropagación
while node is not None:
node.N += 1
node.Q += reward
node = node.parent
return max(root.children, key=lambda a: root.children[a].N)
La única diferencia con la versión de §18.3 es la función uct_value en [U1]. Tres líneas de código cambian el rendimiento radicalmente.
6. UCT vs selección naive
Para hacer la comparación concreta, usamos Hex 3×3 — lo suficientemente pequeño para conocer la respuesta exacta por minimax. De las 9 celdas, 5 son primer movimiento ganador (minimax $= +1$, en verde) y 4 son perdedoras (minimax $= -1$, en rojo). Ambos algoritmos reciben el mismo presupuesto: 500 iteraciones.
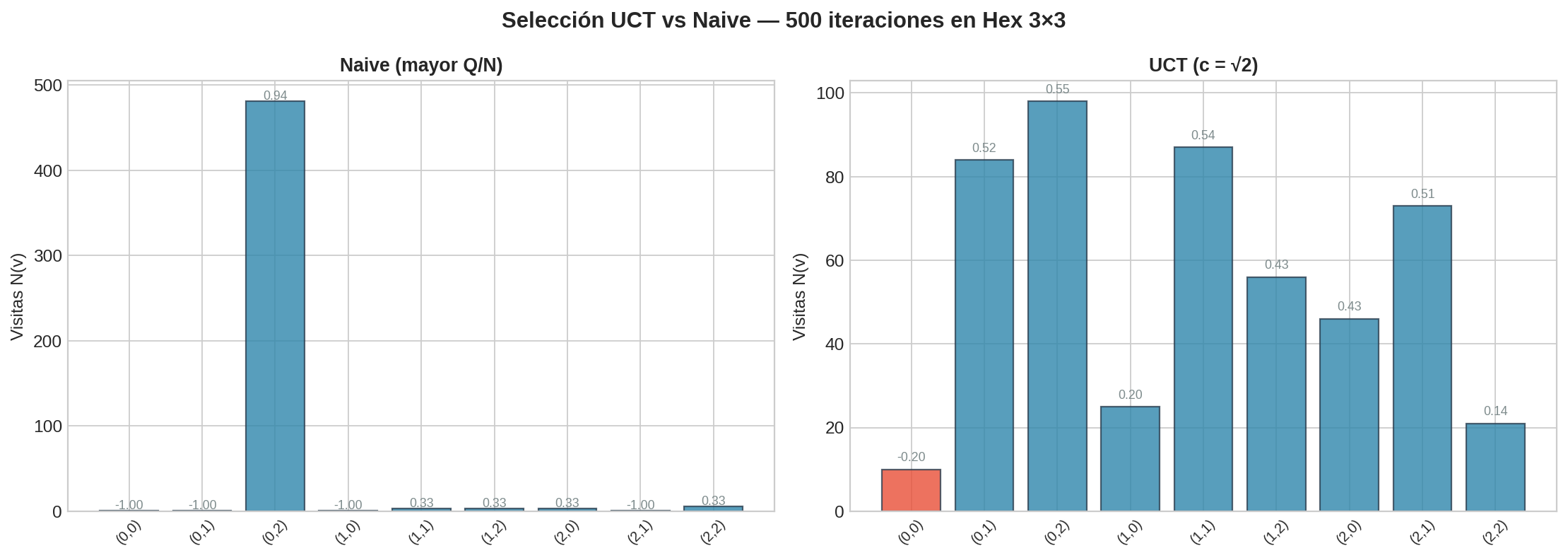
Naive (mayor $Q/N$): la selección se engancha con el primer nodo que tuvo un buen rollout — en este caso $(0,2)$ — y le dedica 481 de 500 visitas (96% del presupuesto). Las otras 8 acciones reciben entre 1 y 6 visitas cada una. Varias acciones ganadoras como $(1,0)$, $(1,1)$ y $(1,2)$ solo tienen 1–3 visitas, así que el algoritmo no sabe que también son ganadoras. Peor aún: con tan pocas visitas, sus estimaciones $Q/N$ son ruidosas y poco confiables ($\pm 1.00$ o $\pm 0.33$). Naive acertó aquí por suerte — si el primer rollout de $(0,2)$ hubiera dado $-1$, se habría enganchado con otra celda y posiblemente con una perdedora.
UCT ($c = \sqrt{2}$): las visitas se distribuyen de forma más inteligente. Las acciones ganadoras (verde) tienden a acumular más visitas — $(0,2)$ tiene 98, $(1,1)$ tiene 87, $(2,0)$ tiene 46 — mientras que las perdedoras (rojo) reciben menos — $(0,0)$ solo 10, $(2,2)$ solo 21. UCT no sabe cuáles son ganadoras a priori, pero el bonus de exploración le obligó a probar todas al menos ~10 veces, y después la explotación concentró el esfuerzo en las que mostraron mejores resultados. Observa que las estimaciones $Q/N$ de UCT son más moderadas (entre $-0.20$ y $+0.55$) porque reflejan la probabilidad de ganar con juego aleatorio, no con juego óptimo — pero el ranking es informativo.
El contraste clave: naive sabe mucho sobre una acción y casi nada sobre las demás. UCT sabe algo sobre todas y más sobre las mejores. Esto es exactamente el balance exploración-explotación de UCB1 (§17.3) aplicado al árbol.
7. El efecto de $c$
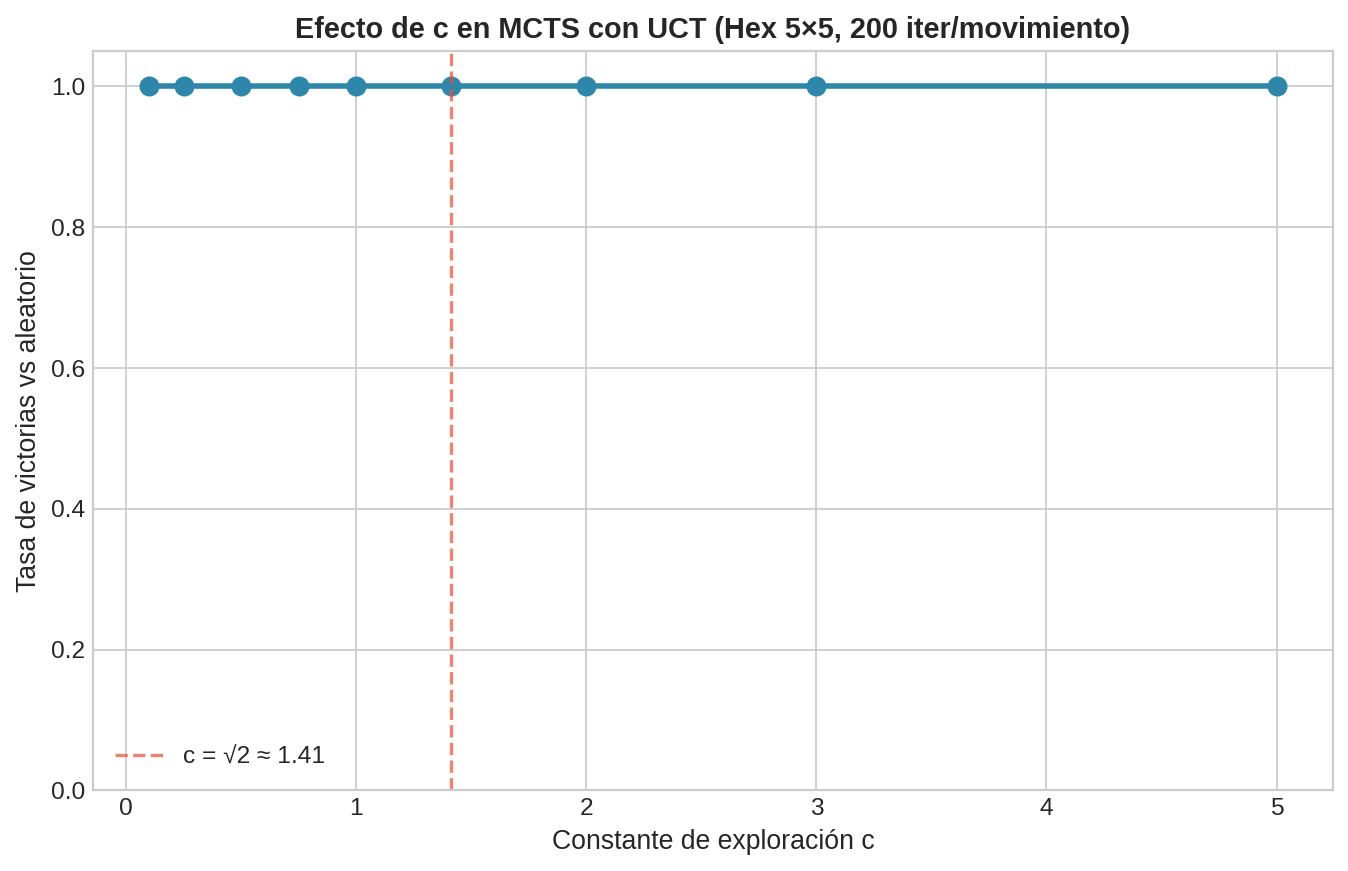
La figura muestra la tasa de victorias de MCTS con UCT contra un jugador aleatorio en Hex 7×7, variando $c$:
- $c$ muy bajo ($< 0.1$): pura explotación. MCTS se aferra a la primera acción que parece buena y pierde acciones superiores → mala tasa de victorias
- $c$ óptimo ($\approx 0.5$–$1.5$): buen balance. Explora lo suficiente para encontrar buenas acciones, explota lo suficiente para invertir rollouts donde importa
- $c$ muy alto ($> 5$): demasiada exploración. MCTS visita todos los nodos casi por igual, como si hiciera rollouts puros → pierde la ventaja del árbol
En la práctica, $c = \sqrt{2} \approx 1.41$ es un buen punto de partida. Para juegos específicos, se puede ajustar experimentalmente.
8. Convergencia: UCT → Minimax
Teorema (Kocsis & Szepesvári, 2006). Cuando el número de iteraciones $M \to \infty$, la acción elegida por MCTS con UCT converge a la acción óptima de minimax.
No demostraremos el teorema formalmente, pero la intuición es clara:
- UCB1 garantiza que cada brazo se jala infinitas veces cuando $t \to \infty$ (§17.3). Por lo tanto, en cada nodo, cada hijo es visitado infinitamente
- Si cada hijo es visitado infinitamente, los rollouts desde cada posición convergen al valor verdadero (por LLN, §12.2)
- Si los valores de los hijos convergen a los valores verdaderos, la propagación hacia arriba reproduce minimax
El resultado práctico: MCTS con UCT es asintóticamente óptimo — con suficientes iteraciones, encuentra la misma respuesta que minimax. Pero a diferencia de minimax, es anytime: con pocas iteraciones ya da una respuesta razonable.
9. Resumen: la cadena completa
El módulo 18 une tres ideas de módulos anteriores:
| Módulo | Idea | Rol en MCTS |
|---|---|---|
| 12 — Monte Carlo | $\hat\mu_n = \frac{1}{n}\sum f(X_i)$ converge a $\mu$ | Los rollouts [M3] son el estimador |
| 15 — Búsqueda adversarial | Árbol de juego + propagación de valores | La estructura del árbol [M2] + [M4] |
| 17 — Bandidos multibrazo | UCB1: $\hat\mu + c\sqrt{\ln t / N}$ | La selección [M1] con UCT [U1] |
MCTS con UCT no es un algoritmo nuevo desconectado de lo anterior — es la síntesis natural de tres herramientas que ya teníamos.
Anterior → MCTS: las cuatro fases | Siguiente → MCTS en acción