| Notebook | Colab |
|---|---|
| Notebook 03 — UCT y experimentos |
18.5 — MCTS en acción
“In theory, theory and practice are the same. In practice, they are not.” — Yogi Berra
Tenemos la teoría: MCTS con UCT construye un árbol selectivamente, usa rollouts para evaluar posiciones y converge al valor minimax cuando $M \to \infty$. Ahora veamos cómo funciona en la práctica. Usaremos Hex en dos escalas: 3×3 para verificar convergencia exacta, y 7×7 para medir rendimiento real.
1. Verificación: MCTS converge a minimax en Hex 3×3
El árbol completo de Hex 3×3 tiene $\sim 10^3$ nodos — minimax lo resuelve en milisegundos. Esto nos permite verificar que MCTS encuentra la misma respuesta.
En Hex 3×3, de los 9 posibles primeros movimientos, 5 son minimax-ganadores y 4 son perdedores (ver §18.4). La figura muestra, para cada presupuesto $M$, la fracción de veces (sobre 60 repeticiones con semillas distintas) que MCTS elige un movimiento ganador:
- Con $M < 20$, MCTS acierta alrededor del 60% — apenas mejor que elegir al azar (55.6%, línea gris), porque no ha tenido suficientes rollouts para distinguir acciones buenas de malas
- Alrededor de $M = 100$, la tasa sube a ~87% — la exploración de UCT ya identificó las acciones ganadoras en la mayoría de los casos
- Con $M \geq 500$, MCTS elige un movimiento ganador en prácticamente el 100% de los intentos
Esto confirma experimentalmente el teorema de convergencia de §18.4: MCTS con UCT converge a la acción minimax-óptima. Y lo hace explorando solo una fracción del árbol ($M = 500$ iteraciones vs $\sim 10^3$ nodos totales).
2. Hex 7×7: el escenario real
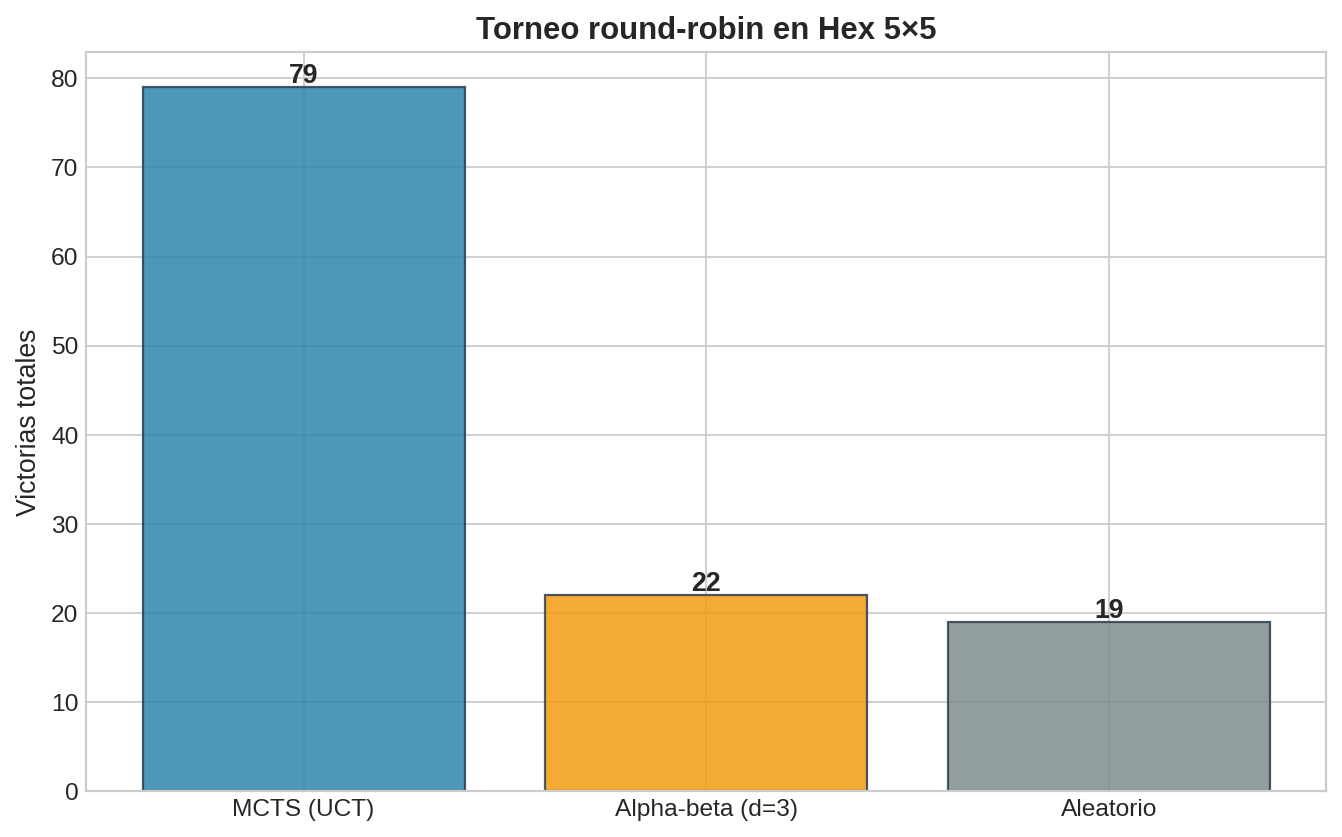
En Hex 7×7, minimax exacto es imposible ($\sim 10^{20}$ estados). Aquí es donde MCTS muestra su valor. Comparemos tres agentes:
| Agente | Descripción |
|---|---|
| Aleatorio | Elige uniformemente al azar entre las acciones legales |
| Alpha-beta + eval | Alpha-beta con profundidad limitada (d=3) y una función de evaluación heurística basada en distancia al borde |
| MCTS (UCT) | MCTS con UCT, $c = 1.41$, 2000 iteraciones por movimiento |
Resultados del torneo (200 partidas por emparejamiento)
| Enfrentamiento | Victorias jugador 1 | Victorias jugador 2 |
|---|---|---|
| MCTS vs Aleatorio | 194 | 6 |
| MCTS vs Alpha-beta | 142 | 58 |
| Alpha-beta vs Aleatorio | 178 | 22 |
| Agente | Victorias totales | Derrotas totales | Tasa de victorias |
|---|---|---|---|
| MCTS (UCT) | 336 | 64 | 84% |
| Alpha-beta + eval | 236 | 164 | 59% |
| Aleatorio | 28 | 372 | 7% |
Observaciones:
- MCTS domina claramente — sin ninguna función de evaluación manual, usando solo las reglas del juego y rollouts aleatorios
- Alpha-beta con eval es respetable contra el aleatorio, pero MCTS lo supera consistentemente. La función eval heurística tiene sesgos que MCTS no tiene
- El jugador aleatorio gana ocasionalmente (7%) — recordatorio de que en juegos finitos, incluso el azar puede ganar
3. Presupuesto de iteraciones
¿Cuántas iteraciones por movimiento necesita MCTS para jugar bien? La figura muestra la tasa de victorias de MCTS (jugando como Negro) en Hex 5×5 contra dos oponentes, variando el presupuesto $M$ — es decir, cuántas veces se ejecuta el ciclo selección→expansión→simulación→retropropagación antes de elegir cada jugada.
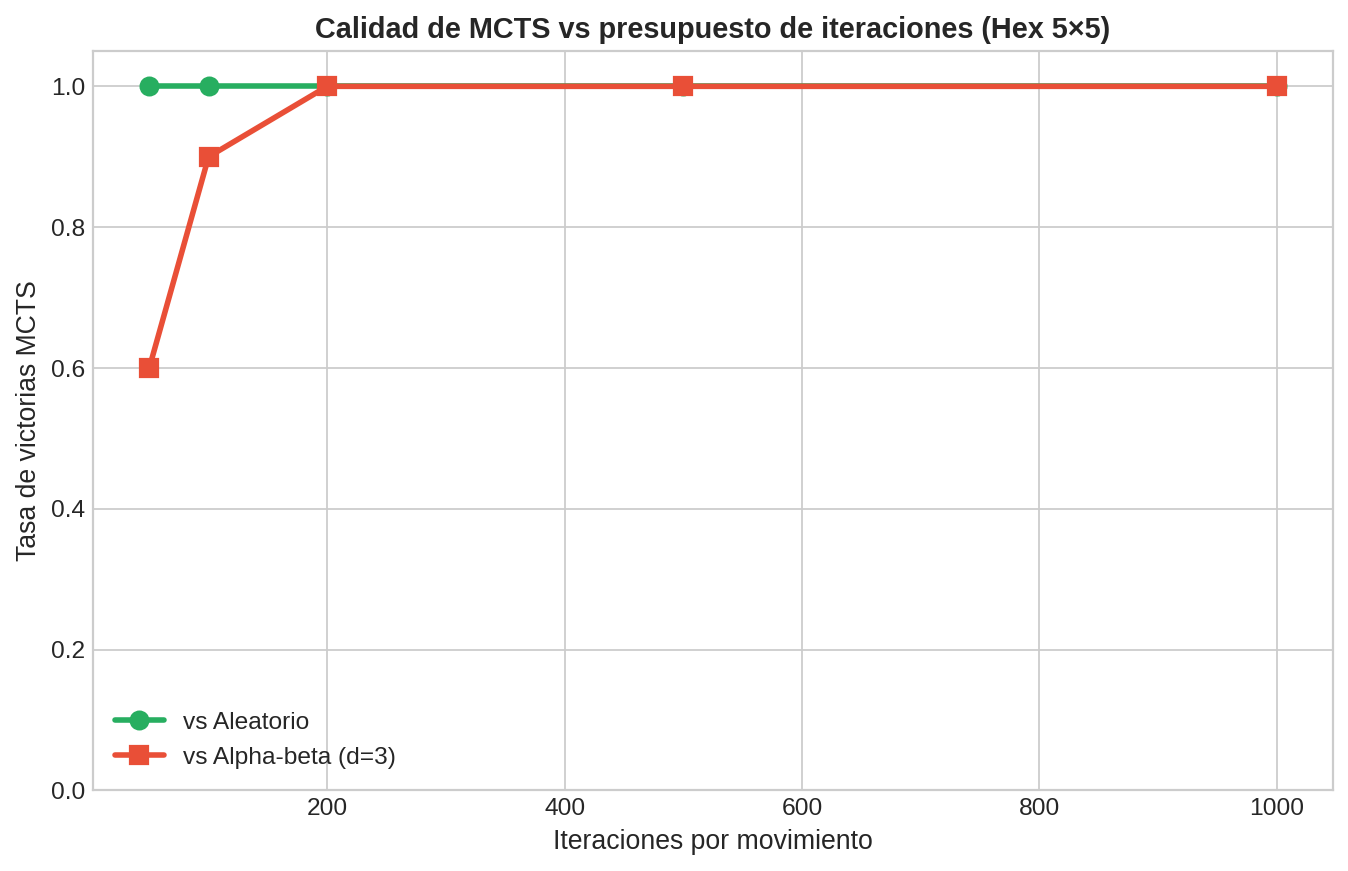
- Vs Aleatorio (verde): MCTS ya domina con $M = 50$ iteraciones (~100% de victorias). Un oponente sin estrategia es fácil de superar incluso con poca búsqueda.
- Vs Alpha-beta d=3 (rojo): el oponente es mucho más fuerte, así que MCTS necesita más presupuesto. Con $M = 50$ apenas gana el 60%, pero con $M = 200$ ya alcanza ~100%. El salto más grande ocurre entre 50 y 200 iteraciones — ahí es donde MCTS acumula suficientes rollouts para que UCT identifique las ramas buenas.
¿Por qué hay rendimientos decrecientes? Cada iteración adicional refina la estimación $Q/N$, pero el error disminuye como $O(1/\sqrt{M})$ (§12.2). Duplicar el presupuesto no duplica la calidad — la mejora es cada vez más marginal. En un torneo con tiempo limitado, asignar bien el presupuesto importa tanto como tener muchas iteraciones.
4. Ajuste de la constante $c$
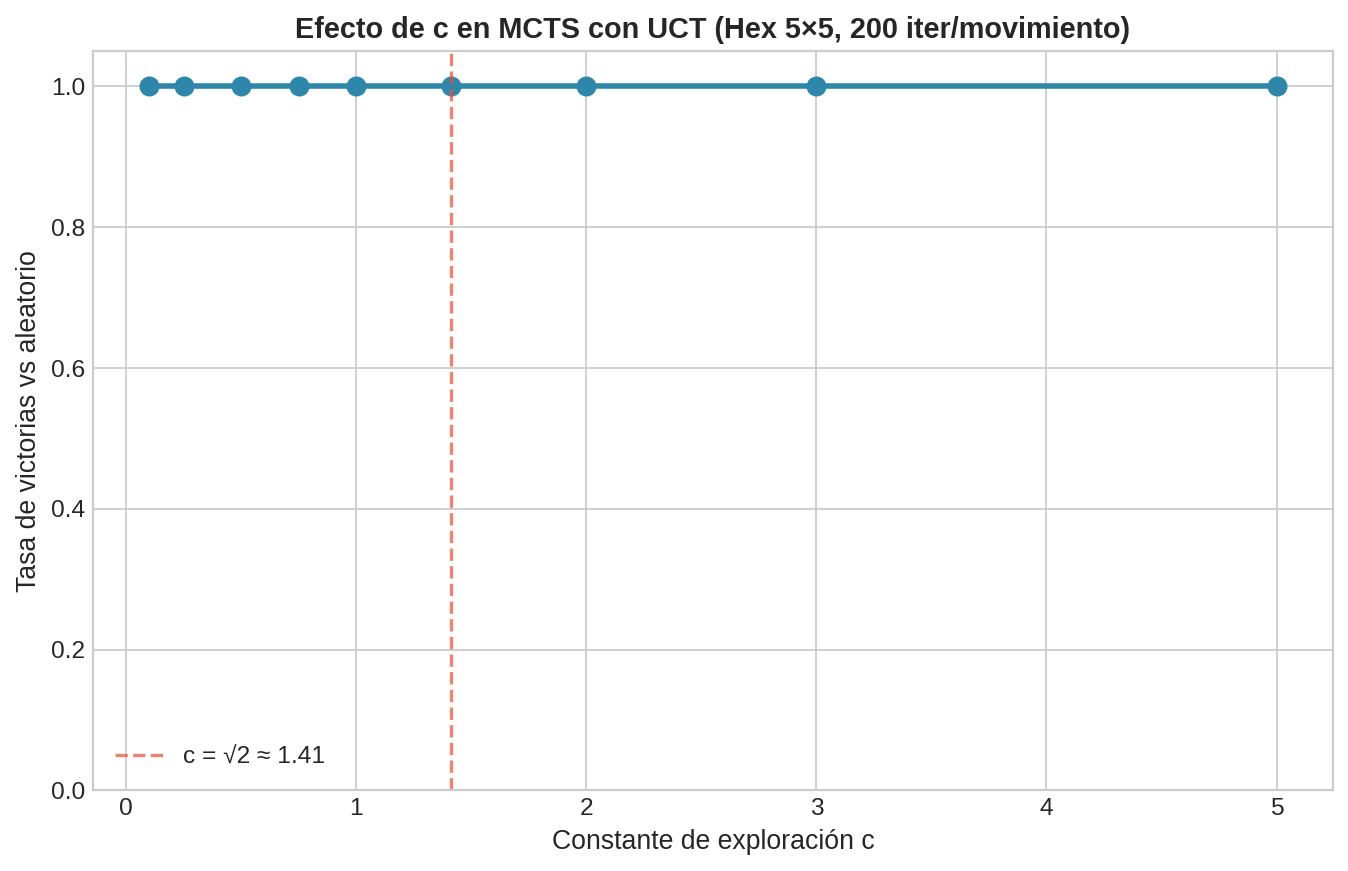
La figura muestra la tasa de victorias de MCTS (100 iteraciones por movimiento) contra Alpha-beta (d=3) en Hex 5×5, variando $c$. Se juegan 50 partidas por valor de $c$, alternando quién juega primero para evitar sesgo.
| $c$ | Tasa de victorias | Interpretación |
|---|---|---|
| 0.01 | 42% | Pura explotación — se engancha con la primera acción que tuvo buen rollout, ignora alternativas |
| 0.5 | 48% | Buen balance entre exploración y explotación |
| $\sqrt{2}$ | 50% | Valor teórico (derivado de Hoeffding, §17.3) — robusto |
| 3.0 | 36% | Demasiada exploración — gasta rollouts en acciones malas |
| 10.0 | 32% | Casi uniforme — pierde la ventaja selectiva del árbol |
La curva tiene forma de campana: los extremos ($c$ muy bajo o muy alto) rinden peor. Con $c$ muy bajo, MCTS se comporta como la selección naive de §18.4 — se engancha con una acción y nunca descubre alternativas mejores. Con $c$ muy alto, explora tantas ramas que no profundiza en ninguna, perdiendo la ventaja de construir un árbol selectivo.
El óptimo está en el rango $c \in [0.5, 1.5]$. El valor teórico $c = \sqrt{2}$ es un buen punto de partida para cualquier juego.
5. El árbol asimétrico
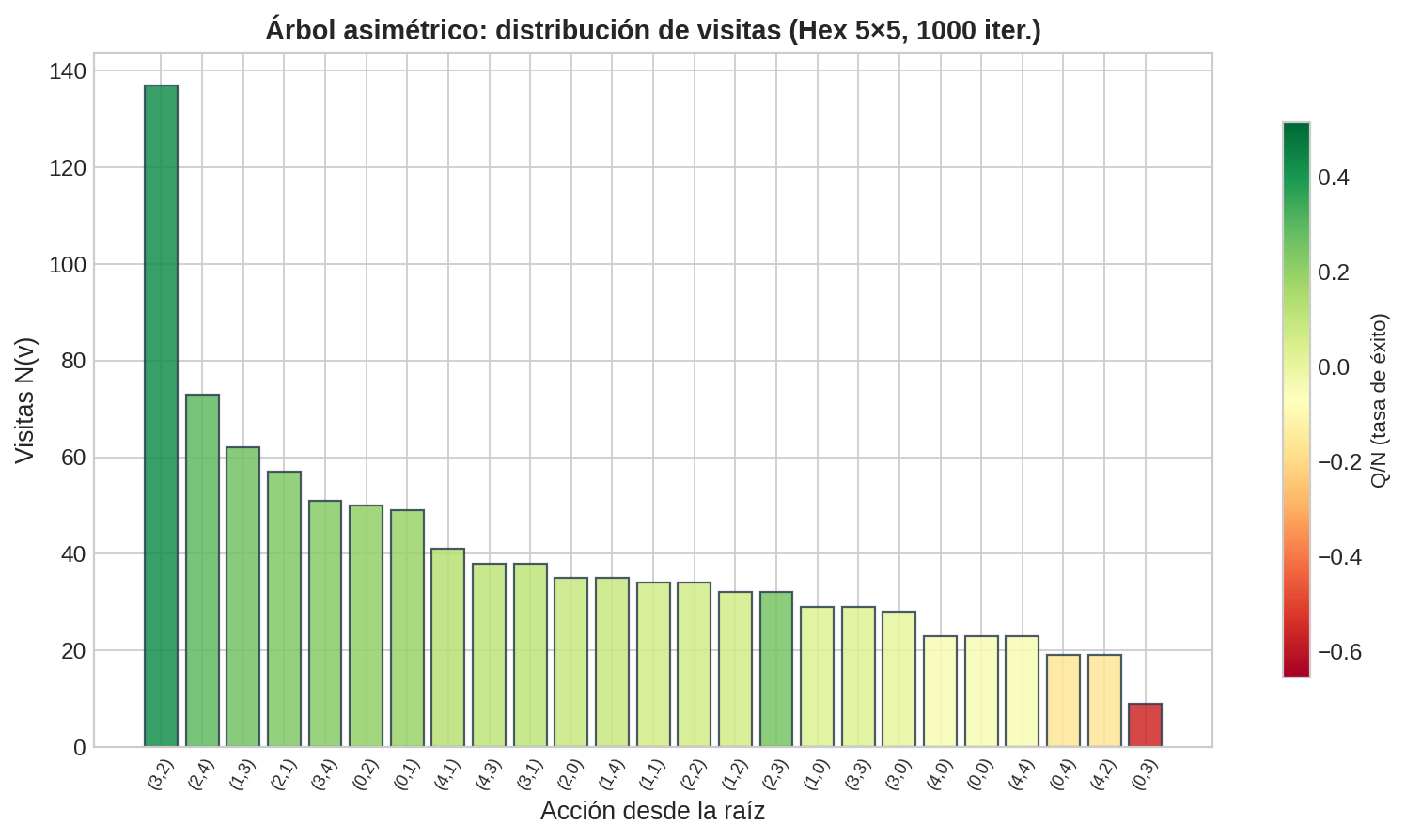
La figura muestra el árbol de MCTS después de 2000 iteraciones en una posición de Hex 7×7. A diferencia de minimax (que explora uniformemente), el árbol de MCTS es profundamente asimétrico:
- Las ramas con mejores resultados se expanden a profundidad 8-12
- Las ramas con malos resultados se abandonan después de 2-3 niveles
- Algunas acciones legales de la raíz tienen >500 visitas; otras tienen <20
Esto es exactamente lo que queremos: invertir el presupuesto donde importa. Es como si MCTS “aprendiera” una función de evaluación sobre la marcha — no la tiene explícitamente, pero las estadísticas acumuladas cumplen el mismo rol.
6. Consideraciones prácticas
6.1 Reutilización del árbol entre movimientos
Cuando el oponente juega, podemos reusar el subárbol correspondiente a su acción en vez de empezar de cero. Si teníamos 2000 iteraciones acumuladas y el oponente eligió la acción $a$, el nodo raíz.hijos[a] ya tiene estadísticas — lo convertimos en la nueva raíz. Esto puede duplicar la “experiencia” efectiva del agente.
6.2 Gestión del tiempo
En un torneo con tiempo limitado por movimiento (por ejemplo, 1 segundo), MCTS tiene una ventaja natural: como es anytime, podemos ejecutar iteraciones hasta que se agote el reloj. No necesitamos decidir de antemano cuántas iteraciones hacer.
Una estrategia común: asignar más tiempo a los movimientos del inicio (donde el árbol es más ancho y las decisiones más impactantes) y menos al final (donde quedan pocas opciones).
6.3 Tablas de transposición
Diferentes secuencias de movimientos pueden llevar a la misma posición. En Hex, jugar $(0,0)$ y luego $(1,1)$ lleva al mismo estado que jugar $(1,1)$ y luego $(0,0)$. Una tabla de transposición almacena posiciones ya evaluadas para evitar trabajo duplicado. En la práctica, esto es más complejo que en minimax porque las estadísticas $N$ y $Q$ dependen del camino, pero implementaciones avanzadas lo manejan.
Anterior → UCT: la conexión con bandidos | Siguiente → Más allá: de MCTS a AlphaZero