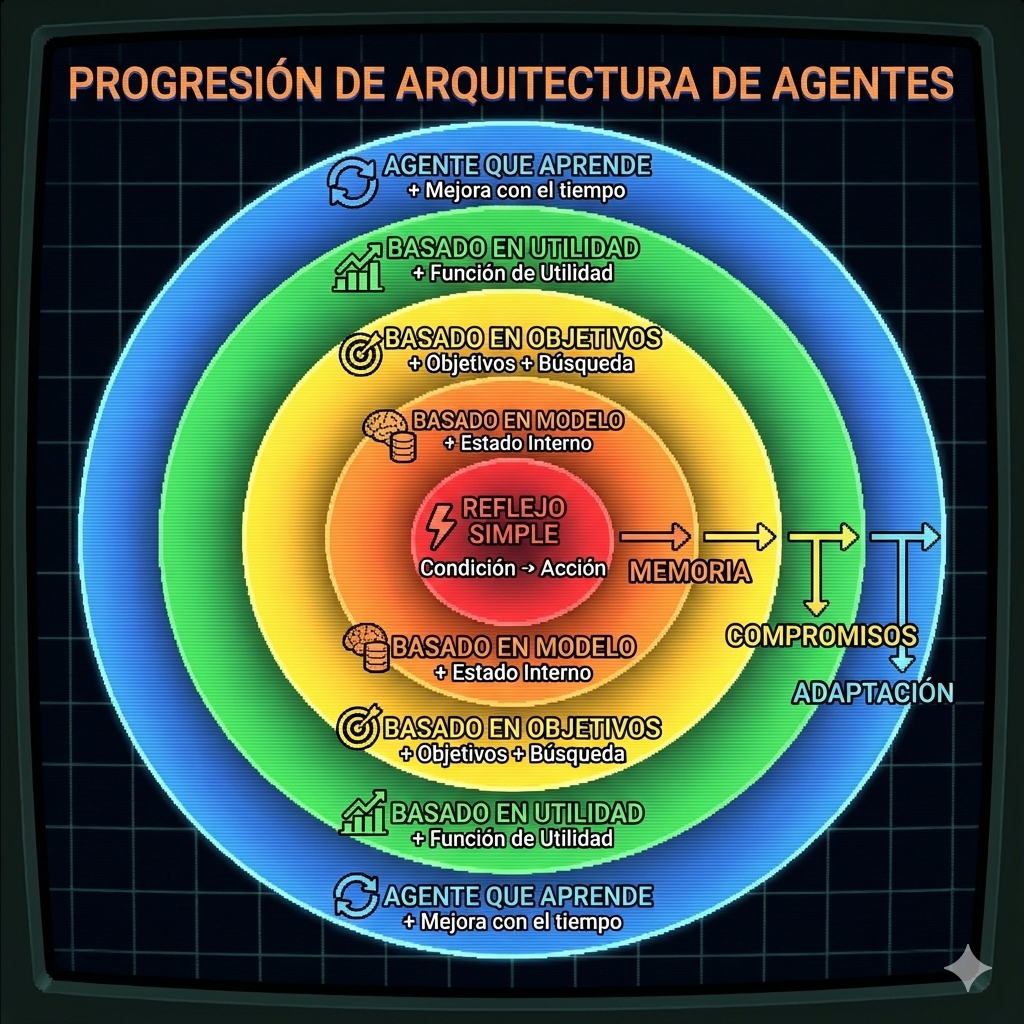
Arquitecturas de Agentes
¿Cómo está organizado internamente un agente? Hay 4 arquitecturas básicas, cada una más capaz que la anterior.
1. Simple Reflex Agent
El agente más básico: actúa solo basándose en el percept actual.
graph TD
E[Environment] -->|Percept| S[Sensors]
S --> R[Condition-Action Rules]
R --> A[Actuators]
A -->|Action| E
Implementación
function SIMPLE-REFLEX-AGENT(percept):
rules ← a set of condition-action rules
state ← INTERPRET-INPUT(percept)
rule ← RULE-MATCH(state, rules)
action ← rule.ACTION
return action
Ejemplo: Vacuum World
if status = Dirty then return Suck
else if location = A then return Right
else if location = B then return Left
Limitaciones
- ❌ No funciona bien en environments partially observable
- ❌ No tiene memoria
- ❌ No puede planear
2. Model-Based Reflex Agent
Mantiene un estado interno que representa partes del mundo que no puede ver.
graph TD
E[Environment] -->|Percept| S[Sensors]
S --> U[Update State]
ST[Internal State] --> U
M[Model: How world evolves] --> U
U --> ST
ST --> R[Condition-Action Rules]
R --> A[Actuators]
A -->|Action| E
Dos tipos de conocimiento
| Tipo | Descripción |
|---|---|
| Transition Model | ¿Cómo evoluciona el mundo independiente del agente? |
| Sensor Model | ¿Cómo mis percepts reflejan el estado del mundo? |
Ventajas
- ✅ Puede manejar partial observability
- ✅ Tiene “memoria” del pasado
- ❌ Todavía usa reglas fijas
3. Goal-Based Agent
Tiene goals explícitos y considera el futuro.
graph TD
E[Environment] -->|Percept| S[Sensors]
S --> U[Update State]
ST[Internal State] --> U
U --> ST
ST --> P{What if I do action A?}
G[Goals] --> P
P --> D[Will it achieve goal?]
D --> A[Actuators]
A -->|Action| E
Diferencia clave
- Reflex:
if condition then action - Goal-based:
if action leads to goal then action
Requiere
- Search para encontrar secuencia de acciones
- Planning para construir planes complejos
Ventajas
- ✅ Flexible ante cambios de goals
- ✅ Puede “razonar” sobre acciones
- ❌ Goals binarios (logrado/no logrado)
4. Utility-Based Agent
Tiene una función de utilidad que mide “qué tan bueno” es cada estado.
graph TD
E[Environment] -->|Percept| S[Sensors]
S --> U[Update State]
ST[Internal State] --> U
U --> ST
ST --> EU[Expected Utility Calculation]
UF[Utility Function] --> EU
P[Probability of Outcomes] --> EU
EU --> MAX[Maximize Expected Utility]
MAX --> A[Actuators]
A -->|Action| E
¿Por qué utilidad?
- Goals conflictivos: ¿Rápido o seguro? Utilidad permite trade-offs
- Incertidumbre: Maximizar utilidad esperada
- Múltiples formas de éxito: No solo “logré el goal”, sino “qué tan bien”
La ecuación fundamental
$$\text{Acción óptima} = \arg\max_a \sum_{s’} P(s’|s,a) \cdot U(s’)$$
Elegir la acción que maximiza la utilidad esperada.
5. Learning Agent
Puede mejorar su comportamiento con experiencia.
graph TD
E[Environment] -->|Percept| S[Sensors]
S --> PE[Performance Element]
PE --> A[Actuators]
A -->|Action| E
S --> C[Critic]
F[Feedback] --> C
C --> LE[Learning Element]
LE --> PE
LE --> PG[Problem Generator]
PG -->|Suggest exploratory actions| PE
Componentes
| Componente | Función |
|---|---|
| Performance Element | Selecciona acciones (los 4 anteriores) |
| Critic | Evalúa qué tan bien lo hace el agente |
| Learning Element | Modifica performance element para mejorar |
| Problem Generator | Sugiere acciones exploratorias |
El trade-off fundamental
Exploration vs Exploitation
- Explotar lo que sabes → Reward inmediato
- Explorar lo desconocido → Mejor información futura
Resumen Comparativo
| Arquitectura | Memoria | Goals | Utilidad | Aprende |
|---|---|---|---|---|
| Simple Reflex | ❌ | ❌ | ❌ | ❌ |
| Model-Based | ✅ | ❌ | ❌ | ❌ |
| Goal-Based | ✅ | ✅ | ❌ | ❌ |
| Utility-Based | ✅ | ✅ | ✅ | ❌ |
| Learning | ✅ | ✅ | ✅ | ✅ |
¿Qué arquitectura usa cada agente?
- Un termostato que enciende la calefacción cuando la temperatura baja de 20°C
- Un GPS que recalcula la ruta cuando te sales del camino
- Un robot que mantiene un mapa de la casa mientras limpia
- Un jugador de ajedrez que evalúa posiciones numéricamente
- Un chatbot que mejora con feedback de usuarios
- Un semáforo con tiempos fijos
- Un carro autónomo de Waymo
Para cada problema, diseña un agente especificando:
- Arquitectura elegida y por qué
- Qué información mantiene en su estado interno
- Cómo decide qué acción tomar
Problemas:
-
Robot mesero en un restaurante
- Debe llevar órdenes a mesas
- Evitar obstáculos y personas
- Optimizar tiempo de espera
-
Sistema de precios dinámicos (como Uber)
- Debe fijar precios
- Balancear oferta y demanda
- Maximizar ganancias sin perder clientes
-
Tutor personalizado de matemáticas
- Debe seleccionar ejercicios
- Adaptarse al nivel del estudiante
- Maximizar aprendizaje
Estoy diseñando un agente para: [DESCRIBE TU PROBLEMA]
Ya hice el análisis PEAS y las propiedades del environment son: [LISTA LAS PROPIEDADES]
Ayúdame a elegir la arquitectura correcta:
-
Para cada arquitectura (simple reflex, model-based, goal-based, utility-based, learning):
- ¿Funcionaría para este problema? ¿Por qué?
- ¿Qué limitaciones tendría?
-
¿Cuál es la arquitectura mínima que funcionaría?
-
¿Cuál es la arquitectura ideal y qué agregaría?
-
¿Qué componentes específicos necesitaría implementar?
Conexión con el Resto del Curso
| Arquitectura | Temas relacionados |
|---|---|
| Model-Based | Probability, Bayesian Inference, HMMs |
| Goal-Based | Search, Planning, Logic |
| Utility-Based | Decision Theory, Game Theory, MDPs |
| Learning | Learning Theory, Neural Networks, RL |
Cada tema del curso te da herramientas para implementar una parte de estas arquitecturas.
Puntos Clave
- Hay 4+1 arquitecturas de complejidad creciente
- Cada una añade capacidades sobre la anterior
- La elección depende de las propiedades del environment
- Los learning agents pueden mejorar cualquiera de las otras
- El resto del curso enseña técnicas para implementar cada componente