Estadística y Estimadores
Pasamos de la teoría a la práctica: ¿cómo aprendemos sobre distribuciones desconocidas a partir de datos?
El Problema Central de la Estadística
Probabilidad: Dado un modelo (distribución), ¿qué datos esperamos ver? $$\text{Modelo} \to \text{Datos}$$
Estadística: Dados los datos, ¿qué modelo los generó? $$\text{Datos} \to \text{Modelo}$$
La estadística es el problema inverso de la probabilidad.
Población vs Muestra
| Concepto | Símbolo | Descripción |
|---|---|---|
| Población | — | Todos los elementos de interés (usualmente desconocida/infinita) |
| Muestra | $X_1, X_2, \ldots, X_n$ | Subconjunto observado de la población |
| Parámetro | $\theta$ | Valor verdadero (desconocido) que describe la población |
| Estadístico | $\hat{\theta}$ | Función de la muestra que estima el parámetro |
Ejemplo:
- Población: Alturas de todos los mexicanos
- Parámetro: Media poblacional $\mu$
- Muestra: Alturas de 100 personas medidas
- Estadístico: Promedio muestral $\bar{X} = \frac{1}{n}\sum X_i$
Estadísticos (Funciones de la Muestra)
Un estadístico es cualquier función de los datos que no depende de parámetros desconocidos.
Estadísticos Comunes
Media muestral: $$\bar{X} = \frac{1}{n}\sum_{i=1}^n X_i$$
Varianza muestral: $$S^2 = \frac{1}{n-1}\sum_{i=1}^n (X_i - \bar{X})^2$$
(El $n-1$ es la corrección de Bessel para obtener un estimador insesgado)
Mediana muestral: $$\tilde{X} = \text{valor central de los datos ordenados}$$
Moda muestral: $$\text{Valor más frecuente}$$
Estimación Puntual
Un estimador puntual da un único valor como “mejor conjetura” del parámetro.
Propiedades Deseables de Estimadores
1. Insesgado (Unbiased): $$E[\hat{\theta}] = \theta$$
El estimador acierta “en promedio”.
2. Consistente: $$\hat{\theta}_n \xrightarrow{P} \theta \quad \text{cuando } n \to \infty$$
Con más datos, el estimador converge al valor verdadero.
3. Eficiente: $$\text{Var}(\hat{\theta}) \text{ es mínima entre los estimadores insesgados}$$
4. Suficiente:
El estadístico captura toda la información relevante sobre $\theta$ contenida en los datos.
Ejemplo: Estimando la Media
Sea $X_1, \ldots, X_n \sim \mathcal{N}(\mu, \sigma^2)$ con $\mu$ desconocido.
El estimador $\hat{\mu} = \bar{X}$ es:
- ✓ Insesgado: $E[\bar{X}] = \mu$
- ✓ Consistente: $\bar{X} \to \mu$ por LGN
- ✓ Eficiente: tiene varianza mínima $\sigma^2/n$
- ✓ Suficiente: contiene toda la información sobre $\mu$
Máxima Verosimilitud (Maximum Likelihood)
El método más importante y general para encontrar estimadores.
Intuición
“¿Qué valor del parámetro hace que los datos observados sean más probables?”
Definición Formal
Sea $X_1, \ldots, X_n$ una muestra i.i.d. con densidad $f(x|\theta)$.
Función de verosimilitud: $$L(\theta) = \prod_{i=1}^n f(X_i | \theta)$$
Log-verosimilitud (más conveniente): $$\ell(\theta) = \sum_{i=1}^n \log f(X_i | \theta)$$
Estimador de Máxima Verosimilitud (MLE): $$\hat{\theta}_{MLE} = \arg\max_\theta L(\theta) = \arg\max_\theta \ell(\theta)$$
Ejemplo 1: MLE para Bernoulli
Datos: $X_1, \ldots, X_n \sim \text{Bernoulli}(p)$, observamos $k$ éxitos.
Verosimilitud: $$L(p) = p^k (1-p)^{n-k}$$
Log-verosimilitud: $$\ell(p) = k \log p + (n-k) \log(1-p)$$
Derivada: $$\frac{d\ell}{dp} = \frac{k}{p} - \frac{n-k}{1-p} = 0$$
Solución: $$\hat{p}_{MLE} = \frac{k}{n}$$
¡El MLE es simplemente la proporción muestral de éxitos!
Ejemplo 2: MLE para Normal
Datos: $X_1, \ldots, X_n \sim \mathcal{N}(\mu, \sigma^2)$
Log-verosimilitud: $$\ell(\mu, \sigma^2) = -\frac{n}{2}\log(2\pi) - \frac{n}{2}\log(\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^n(X_i - \mu)^2$$
MLEs: $$\hat{\mu}{MLE} = \bar{X} = \frac{1}{n}\sum X_i$$ $$\hat{\sigma}^2 = \frac{1}{n}\sum (X_i - \bar{X})^2$$
Nota: El MLE de la varianza usa $n$, no $n-1$, así que es ligeramente sesgado.
Ejemplo 3: MLE para Exponencial
Datos: $X_1, \ldots, X_n \sim \text{Exp}(\lambda)$
Log-verosimilitud: $$\ell(\lambda) = n\log\lambda - \lambda\sum X_i$$
Derivada: $$\frac{d\ell}{d\lambda} = \frac{n}{\lambda} - \sum X_i = 0$$
MLE: $$\hat{\lambda}_{MLE} = \frac{n}{\sum X_i} = \frac{1}{\bar{X}}$$
Propiedades del MLE
El MLE tiene propiedades muy buenas asintóticamente (cuando $n \to \infty$):
-
Consistente: $\hat{\theta}_{MLE} \to \theta$
-
Asintóticamente Normal: $$\sqrt{n}(\hat{\theta}_{MLE} - \theta) \xrightarrow{d} \mathcal{N}(0, I(\theta)^{-1})$$
donde $I(\theta)$ es la información de Fisher.
-
Asintóticamente Eficiente: alcanza la cota de Cramér-Rao.
-
Invariante: si $\hat{\theta}$ es MLE de $\theta$, entonces $g(\hat{\theta})$ es MLE de $g(\theta)$.
Método de Momentos
Un método más simple (pero menos eficiente).
Idea
Igualar los momentos muestrales con los momentos teóricos.
Procedimiento
-
Calcular los primeros $k$ momentos teóricos como función de parámetros:
- $\mu_1 = E[X] = g_1(\theta)$
- $\mu_2 = E[X^2] = g_2(\theta)$
- …
-
Calcular los momentos muestrales:
- $\hat{\mu}_1 = \bar{X}$
- $\hat{\mu}_2 = \frac{1}{n}\sum X_i^2$
-
Resolver el sistema de ecuaciones.
Ejemplo: Método de Momentos para Gamma
$X \sim \text{Gamma}(\alpha, \beta)$ con $E[X] = \alpha/\beta$ y $E[X^2] = \alpha(\alpha+1)/\beta^2$.
Resolviendo: $$\hat{\alpha} = \frac{\bar{X}^2}{\overline{X^2} - \bar{X}^2}, \quad \hat{\beta} = \frac{\bar{X}}{\overline{X^2} - \bar{X}^2}$$
MLE vs Método de Momentos
| Aspecto | MLE | Método de Momentos |
|---|---|---|
| Eficiencia | Óptima asintóticamente | Subóptima |
| Cálculo | Puede requerir optimización | Sistema de ecuaciones |
| Propiedades | Bien entendidas | Menos garantías |
| Robustez | Sensible a modelo | Más robusto |
Visualización: Verosimilitud
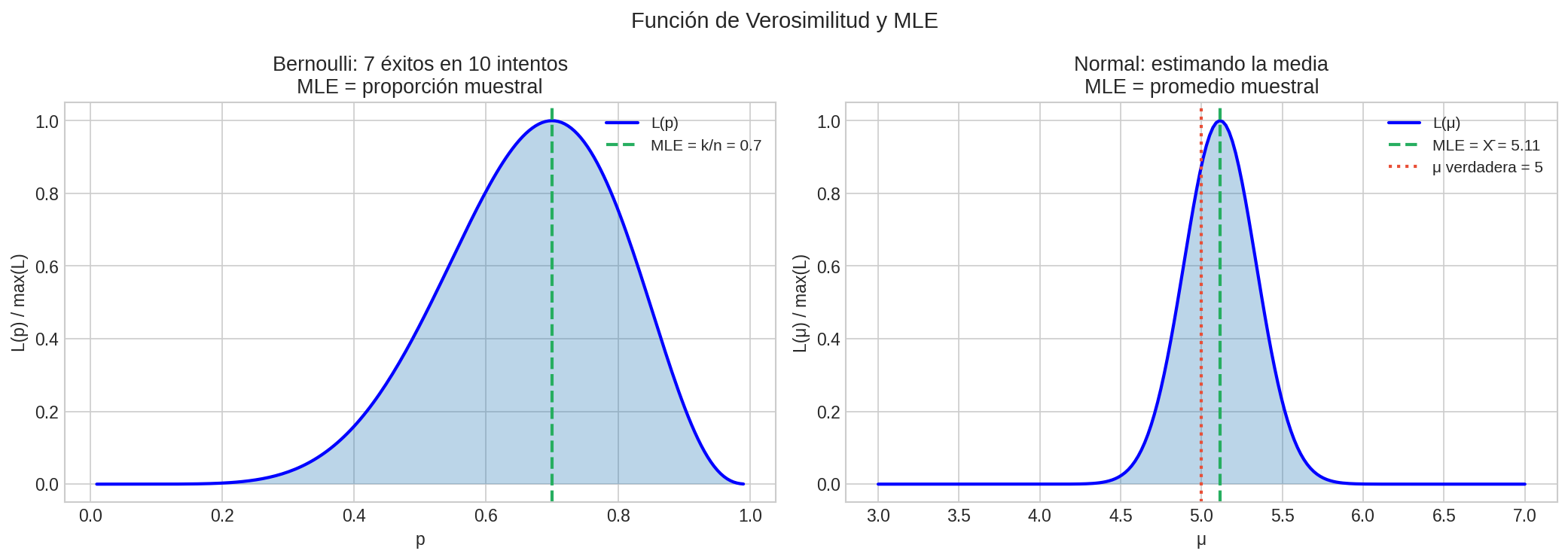
Nota: Esta imagen se genera automáticamente al ejecutar lab_probabilidad.py
Conexión con Bayes
El MLE es un caso especial del enfoque Bayesiano:
$$\text{Posterior} \propto \text{Likelihood} \times \text{Prior}$$
Con un prior uniforme (no informativo): $$\text{Posterior} \propto \text{Likelihood}$$
El modo del posterior = MLE.
Así, MLE puede verse como la estimación Bayesiana con máxima ignorancia previa.
Resumen
| Concepto | Qué es | Para qué sirve |
|---|---|---|
| Estadístico | Función de datos | Resumir información |
| Estimador | Estadístico para estimar $\theta$ | Inferir parámetros |
| MLE | Maximiza verosimilitud | Estimación óptima |
| Método de Momentos | Iguala momentos | Estimación simple |
Siguiente: Teorema del Límite Central y Ley de los Grandes Números →