Teorema del Límite Central y Ley de los Grandes Números
Dos de los resultados más importantes de la probabilidad — explican por qué la estadística funciona… cuando funciona.
La Gran Pregunta
¿Por qué podemos inferir propiedades de poblaciones enormes (millones de personas) a partir de muestras pequeñas (miles)?
La respuesta está en dos teoremas fundamentales:
- Ley de los Grandes Números (LGN): El promedio converge al valor esperado
- Teorema del Límite Central (TLC): La distribución del promedio se vuelve normal
Ley de los Grandes Números (LGN)
Intuición
“Si repites un experimento muchas veces, el promedio observado se acerca al promedio teórico.”
Esta es la justificación formal de por qué las frecuencias relativas convergen a probabilidades.
Versión Débil (Convergencia en Probabilidad)
Sea $X_1, X_2, \ldots$ una secuencia de variables aleatorias i.i.d. con $E[X_i] = \mu$ y $\text{Var}(X_i) = \sigma^2 < \infty$.
$$\bar{X}n = \frac{1}{n}\sum^n X_i \xrightarrow{P} \mu$$
Es decir: para todo $\epsilon > 0$, $$P(|\bar{X}_n - \mu| > \epsilon) \to 0 \quad \text{cuando } n \to \infty$$
Versión Fuerte (Convergencia Casi Segura)
$$P\left(\lim_{n \to \infty} \bar{X}_n = \mu\right) = 1$$
Con probabilidad 1, el promedio converge al valor esperado.
Demostración Intuitiva (usando Chebyshev)
Por la desigualdad de Chebyshev: $$P(|\bar{X}_n - \mu| \geq \epsilon) \leq \frac{\text{Var}(\bar{X}_n)}{\epsilon^2} = \frac{\sigma^2}{n\epsilon^2}$$
Como $\sigma^2/n \to 0$, la probabilidad de desviarse de $\mu$ tiende a cero.
Ejemplo: Lanzamiento de Moneda
Si lanzas una moneda justa muchas veces:
- Con $n = 10$: la proporción de caras puede variar mucho (0.3 a 0.7)
- Con $n = 100$: típicamente entre 0.4 y 0.6
- Con $n = 10,000$: muy cerca de 0.5
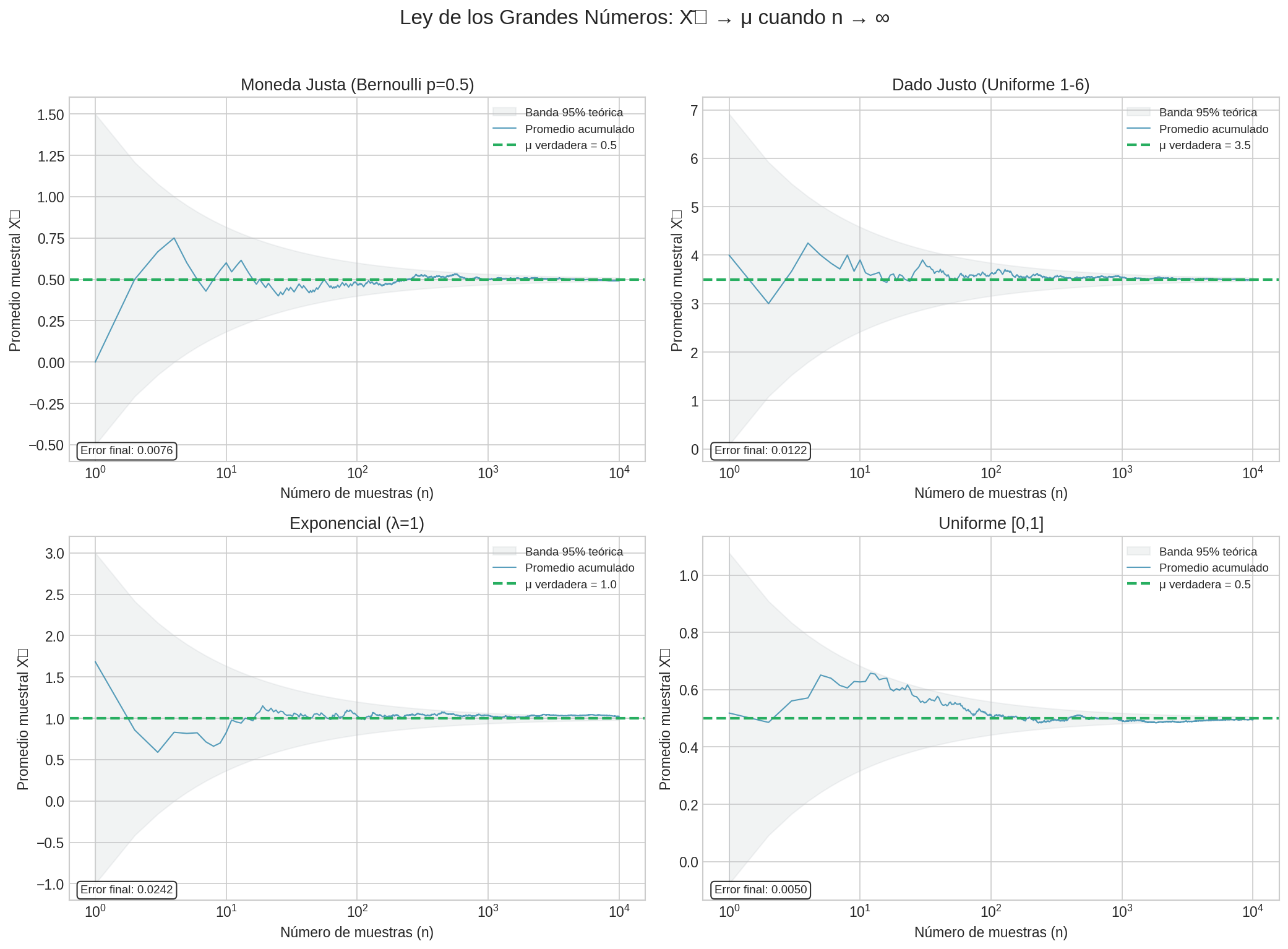
Nota: Esta imagen se genera automáticamente al ejecutar lab_probabilidad.py
Teorema del Límite Central (TLC)
Intuición
“No importa cómo se distribuyan los datos individuales — el promedio de muchos datos se distribuye normalmente.”
Este es probablemente el resultado más sorprendente y útil de toda la probabilidad.
Enunciado Formal
Sea $X_1, X_2, \ldots$ una secuencia de variables aleatorias i.i.d. con:
- $E[X_i] = \mu$
- $\text{Var}(X_i) = \sigma^2 < \infty$
Entonces: $$\frac{\bar{X}_n - \mu}{\sigma/\sqrt{n}} \xrightarrow{d} \mathcal{N}(0, 1)$$
Equivalentemente: $$\bar{X}_n \xrightarrow{d} \mathcal{N}\left(\mu, \frac{\sigma^2}{n}\right)$$
O para la suma: $$S_n = \sum_{i=1}^n X_i \xrightarrow{d} \mathcal{N}(n\mu, n\sigma^2)$$
Lo Que Dice el TLC
- La forma de la distribución original no importa (puede ser uniforme, exponencial, cualquier cosa)
- El promedio estandarizado converge a normal estándar
- La velocidad de convergencia es $1/\sqrt{n}$
Visualización
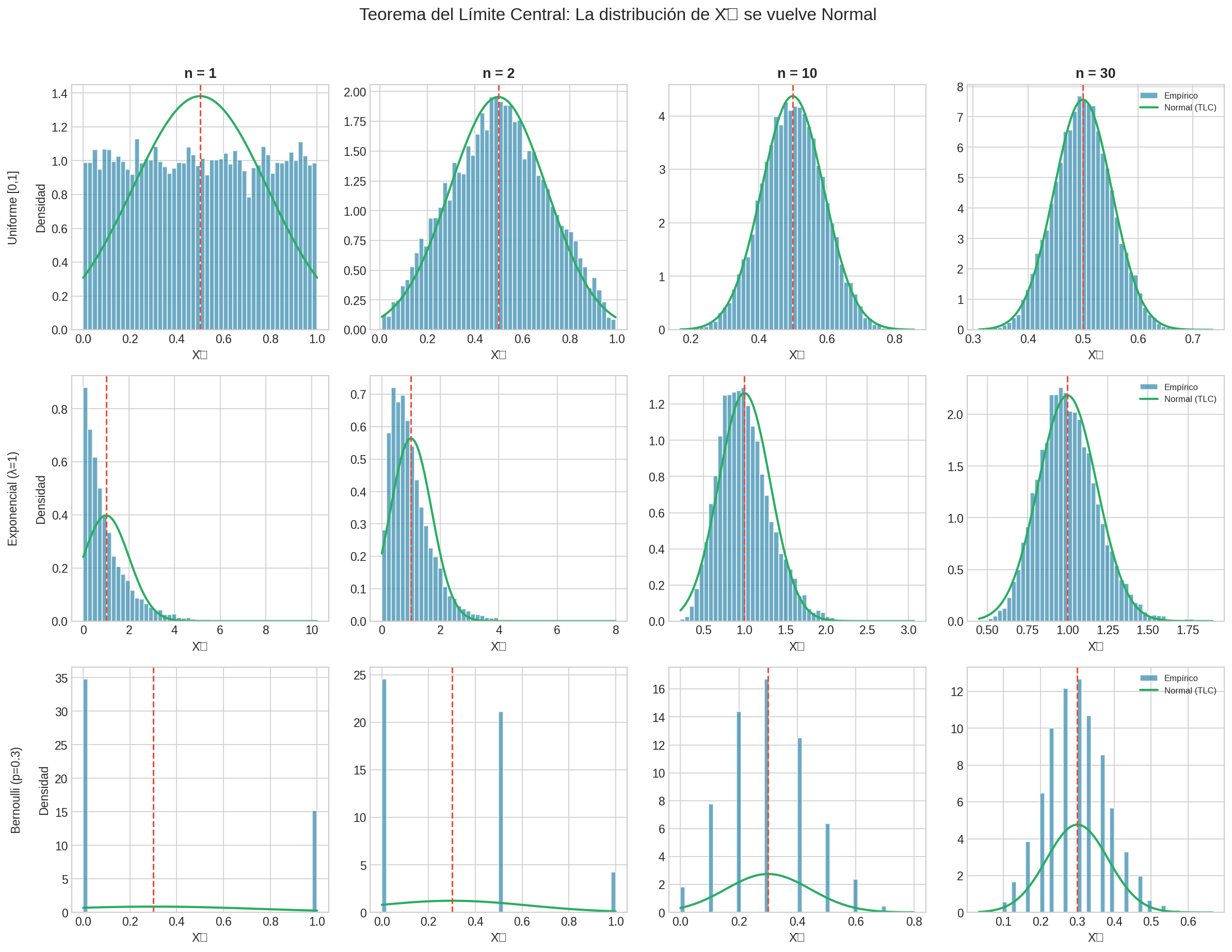
Nota: Esta imagen se genera automáticamente al ejecutar lab_probabilidad.py
Ejemplo: Dados
Lanza un dado (distribución uniforme discreta):
- $E[X] = 3.5$
- $\text{Var}(X) = 35/12 \approx 2.92$
El promedio de $n$ dados:
- Con $n = 1$: distribución uniforme en ${1,2,3,4,5,6}$
- Con $n = 2$: distribución triangular
- Con $n = 10$: casi normal
- Con $n = 30$: prácticamente normal
Condiciones Necesarias
Para la LGN
Condición crítica: $E[|X|] < \infty$ (media finita)
- ✓ Normal, Exponencial, Poisson, Binomial
- ✗ Cauchy (media no existe)
- ⚠ Pareto con $\alpha \leq 1$ (media infinita)
Para el TLC
Condición crítica: $\text{Var}(X) < \infty$ (varianza finita)
- ✓ Normal, Exponencial, Poisson, Binomial
- ✗ Cauchy (varianza infinita)
- ✗ Pareto con $\alpha \leq 2$ (varianza infinita)
Velocidad de Convergencia
Regla de $\sqrt{n}$
El error estándar del promedio decrece como $1/\sqrt{n}$:
$$\text{SE}(\bar{X}_n) = \frac{\sigma}{\sqrt{n}}$$
| $n$ | Error relativo |
|---|---|
| 1 | $\sigma$ |
| 4 | $\sigma/2$ |
| 100 | $\sigma/10$ |
| 10,000 | $\sigma/100$ |
Para reducir el error a la mitad, necesitas 4 veces más datos.
Convergencia en la Práctica
¿Cuántos datos necesitamos para que el TLC “funcione”?
- Distribución simétrica: $n \geq 10$ suele bastar
- Distribución asimétrica: $n \geq 30$ es la regla tradicional
- Distribución muy sesgada: puede necesitar $n \geq 100$
- Colas pesadas: puede necesitar mucho más (o nunca converger)
Aplicaciones
1. Intervalos de Confianza
Por el TLC, aproximadamente: $$\bar{X}_n \sim \mathcal{N}\left(\mu, \frac{\sigma^2}{n}\right)$$
Entonces un intervalo de confianza del 95% es: $$\bar{X}_n \pm 1.96 \cdot \frac{s}{\sqrt{n}}$$
2. Pruebas de Hipótesis
Para contrastar $H_0: \mu = \mu_0$: $$Z = \frac{\bar{X}_n - \mu_0}{s/\sqrt{n}} \approx \mathcal{N}(0, 1)$$
3. Diseño de Encuestas
Para estimar una proporción $p$ con margen de error $\epsilon$: $$n \geq \frac{p(1-p)}{\epsilon^2} \cdot z_{\alpha/2}^2$$
Con $p=0.5$ y margen del 3%: $$n \geq \frac{0.25}{0.03^2} \cdot 1.96^2 \approx 1067$$
Advertencias Importantes
1. Las Condiciones Son Esenciales
Si $E[X] = \infty$ o $\text{Var}(X) = \infty$, los teoremas no aplican.
Esto no es un tecnicismo — hay fenómenos reales donde las distribuciones tienen varianza infinita.
2. “Asintótico” No Es “Para Todo $n$”
Los teoremas dicen qué pasa cuando $n \to \infty$. Para $n$ finito, la aproximación puede ser mala si:
- La distribución original es muy asimétrica
- Hay colas pesadas
- $n$ es pequeño
3. La Convergencia Puede Ser Lenta
Para distribuciones con colas pesadas, la convergencia a la normal puede ser tan lenta que es prácticamente inútil.
El Lado Oscuro: Cuando Fallan
En la siguiente sección veremos colas largas (fat tails): distribuciones donde:
- El promedio converge muy lentamente (o no converge)
- La varianza es infinita
- El TLC no aplica
- ¡Y son más comunes de lo que crees en el mundo real!
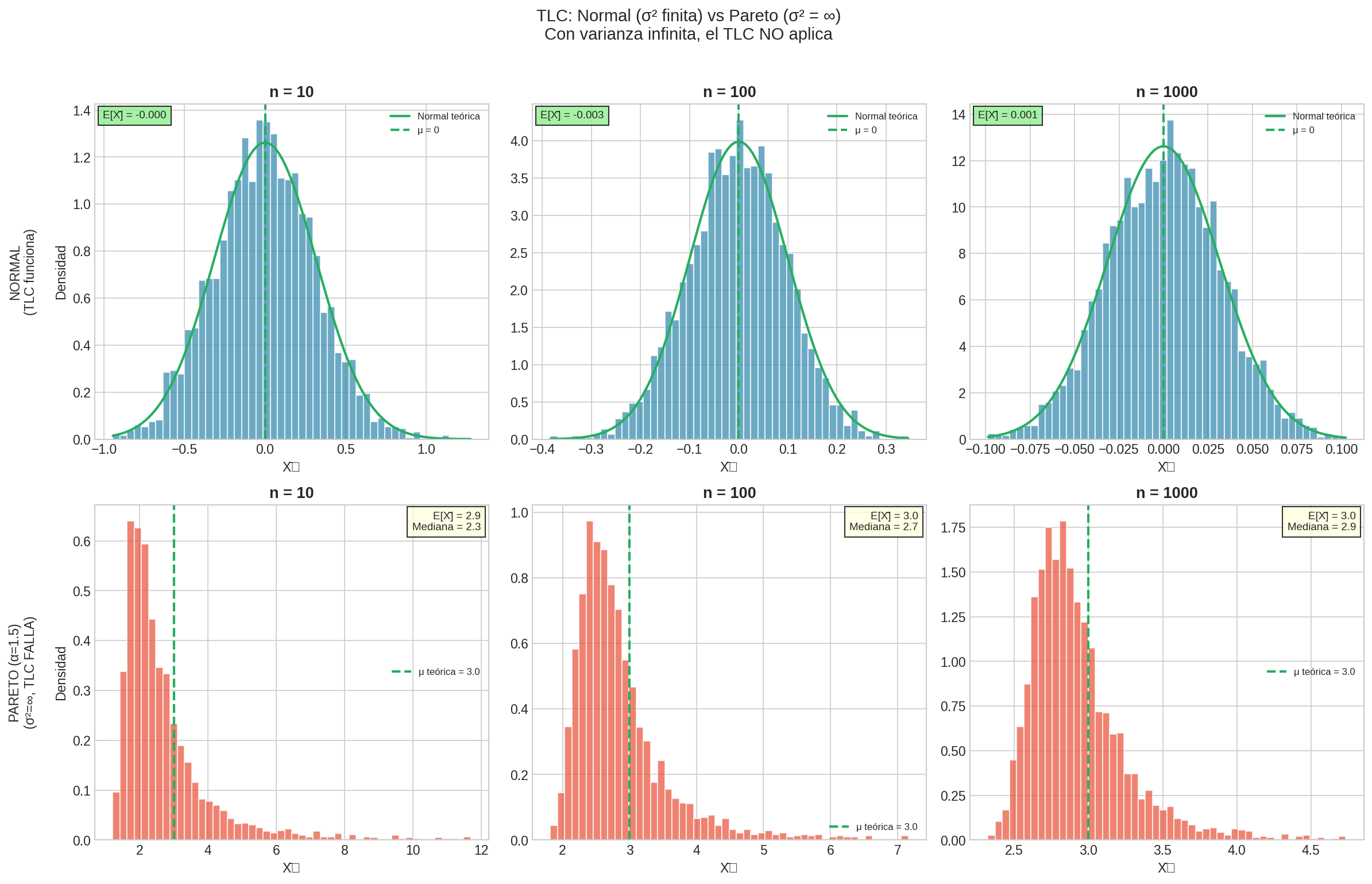
Nota: Esta imagen se genera automáticamente al ejecutar lab_probabilidad.py
Resumen
| Teorema | Qué dice | Condición |
|---|---|---|
| LGN | $\bar{X}_n \to \mu$ | $E[X] < \infty$ |
| TLC | $\bar{X}_n \approx \mathcal{N}(\mu, \sigma^2/n)$ | $\text{Var}(X) < \infty$ |
Mensaje clave: Estos teoremas son la base de la estadística clásica, pero tienen condiciones. Cuando esas condiciones no se cumplen, necesitamos herramientas diferentes.
Siguiente: Colas Largas (Fat Tails) →