Colas Largas (Fat Tails)
Cuando los teoremas clásicos fallan — y por qué esto importa más de lo que crees.
“The central limit theorem has limitations… In fat-tailed domains, most of what you observe comes from the tails.” — Nassim Nicholas Taleb
El Problema Fundamental
Todo lo que vimos sobre LGN y TLC asume que la varianza es finita. Pero:
- ¿Qué pasa si la varianza es infinita?
- ¿Qué pasa si es finita pero tan grande que es prácticamente infinita?
- ¿Cómo sabemos si estamos en esa situación?
Spoiler: Muchos fenómenos del mundo real tienen colas más pesadas de lo que asumimos — y tratarlos como normales puede ser catastrófico.
Intuición: ¿Qué Son las Colas Largas?
La Prueba de Taleb: “¿Uno o Dos?”
Nassim Taleb propone una prueba intuitiva devastadoramente simple:
Si la suma de dos variables es muy grande, ¿es más probable que sea por UNA de ellas o por AMBAS?
En Mediocristán (thin tails):
- Si $X + Y = 100$ con $X, Y \sim \text{Normal}(50, 10)$
- Es más probable que ambas sean ~50
- La combinación “una muy grande, otra pequeña” es rara
En Extremistán (fat tails):
- Si $X + Y = 100$ millones (riqueza de dos personas)
- Es más probable que UNA tenga ~100M y la otra tenga poco
- Casi imposible que ambas tengan exactamente ~50M
El Principio del Máximo Dominante
En distribuciones fat-tailed:
$$\max(X_1, X_2, \ldots, X_n) \approx \sum_{i=1}^n X_i$$
Es decir: el máximo es del mismo orden que la suma total.
Ejemplo concreto:
- Las 10 personas más ricas del mundo tienen ~$1.5 trillones
- Elon Musk solo tiene ~$250 billones
- Una persona = ~17% del total de los top 10
En una distribución normal, esto sería imposible. Si 10 alturas suman 17.5 metros, ninguna persona mide 3 metros.
La Prueba del Café
Imagina que tienes datos de ingresos de 1000 personas:
Pregunta: Si elimino a la persona más rica, ¿cambia significativamente el promedio?
| Distribución | Efecto de eliminar el máximo |
|---|---|
| Normal (alturas) | Casi nada (~0.1%) |
| Lognormal (ingresos clase media) | Poco (~1-2%) |
| Pareto α=2 (riqueza) | Significativo (~10-20%) |
| Pareto α=1.5 (súper ricos) | Dramático (~30-50%) |
Si eliminar UNA observación cambia drásticamente tu estadística, estás en Extremistán.
Intuición Visual: La Forma de la Distribución
THIN TAILS (Normal): FAT TAILS (Pareto):
████ █
██████ █
█████████ ██
████████████ ███
███████████████ ██████████████████████
| | | |
media +3σ media máximo
(raro) (contribuye mucho)
En thin tails, casi todos los datos están cerca de la media. En fat tails, hay valores extremos que contribuyen desproporcionadamente.
¿Por Qué “Cola Larga”?
El nombre viene de que cuando graficas la distribución:
- La cola (la parte alejada del centro) no desaparece rápidamente
- Se extiende mucho más de lo que esperarías
Matemáticamente, una cola “larga” decae como:
- Thin tail: $P(X > x) \sim e^{-x}$ (exponencial - cae MUY rápido)
- Fat tail: $P(X > x) \sim x^{-\alpha}$ (potencia - cae LENTO)
Para $x = 10$:
- Exponencial: $e^{-10} \approx 0.00005$
- Power law α=2: $10^{-2} = 0.01$ → 200 veces más probable
Definición Formal de Fat Tails
Clasificación de Colas
Una distribución tiene colas pesadas (fat tails) si su función de distribución de cola decrece más lentamente que exponencial.
Thin-tailed (Colas ligeras): $$P(X > x) \sim e^{-\lambda x} \quad \text{(exponencial o más rápido)}$$
Ejemplos: Normal, Exponencial, Poisson
Fat-tailed (Colas pesadas): $$P(X > x) \sim x^{-\alpha} \quad \text{(ley de potencias)}$$
Ejemplos: Pareto, Cauchy, Lévy
⚠️ Advertencia sobre Student-t: Aunque a menudo se usa como “modelo fat-tailed”, la Student-t tiene colas que decaen como $t^{-\nu-1}$, no como $x^{-\alpha}$. Esto significa que subestima los eventos extremos comparado con distribuciones verdaderamente fat-tailed como Pareto. Usar Student-t para modelar riesgos puede dar una falsa sensación de seguridad.
El Exponente de Cola $\alpha$
Para una distribución Pareto-like: $$P(X > x) \propto x^{-\alpha}$$
El exponente $\alpha$ determina qué momentos existen:
| $\alpha$ | Media | Varianza | Curtosis | Comportamiento |
|---|---|---|---|---|
| $\alpha \leq 1$ | ∞ | ∞ | ∞ | Extremadamente fat-tailed |
| $1 < \alpha \leq 2$ | Finita | ∞ | ∞ | Fat-tailed severo |
| $2 < \alpha \leq 3$ | Finita | Finita | ∞ | Fat-tailed moderado |
| $3 < \alpha \leq 4$ | Finita | Finita | Finita | Semi-fat-tailed |
| $\alpha > 4$ | Finita | Finita | Finita | Casi thin-tailed |
Definición Intuitiva
Una distribución es fat-tailed si un pequeño número de observaciones extremas domina la suma total.
Tres señales de fat tails:
-
El máximo domina: $\max(X_i) / \sum X_i$ es significativo (no tiende a cero)
-
Los extremos “imposibles” ocurren: Eventos de 5-10 sigmas suceden regularmente
-
El promedio es inestable: Añadir una observación puede cambiar drásticamente la media
Ejemplo numérico:
| 1000 alturas (Normal) | 1000 riquezas (Pareto) | |
|---|---|---|
| Suma total | ~1,700 metros | ~$500 millones |
| Máximo | ~1.95 metros | ~$200 millones |
| max/sum | 0.1% | 40% |
| Efecto de quitar el máximo | Imperceptible | Catastrófico |
El Criterio de Taleb: Kappa
Nassim Taleb propone una métrica práctica para detectar fat tails:
$$\kappa = \frac{\max_{i \leq n} X_i}{\sum_{i=1}^n X_i}$$
Interpretación:
- Si $\kappa \approx 1/n$: distribución thin-tailed (cada observación contribuye igual)
- Si $\kappa \to 1$: distribución fat-tailed (una observación domina)
Ejemplo Intuitivo
Riqueza de 1000 personas:
- Si la más rica tiene $1M y el promedio es $100K → $\kappa \approx 0.01$ (thin)
- Si la más rica tiene $1B y el promedio es $1M → $\kappa \approx 0.5$ (fat)
Ejemplos del Mundo Real
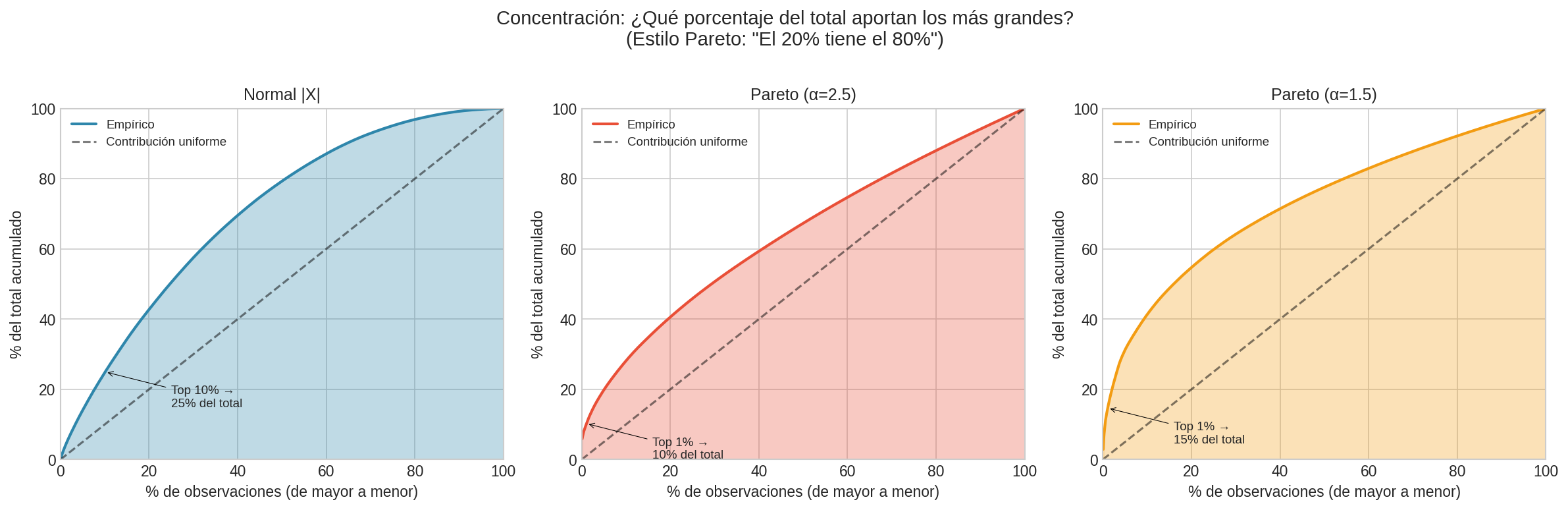
En fat tails, el top 10% puede contribuir >50% del total. En thin tails, la contribución es más uniforme.
El Mundo es “Winner Takes All”
En muchos dominios, las distribuciones son fat-tailed porque hay efectos de red y retroalimentación positiva:
- Un libro popular se recomienda más → más ventas → más popular
- Una ciudad grande atrae más empresas → más empleos → más gente
- Un video viral se comparte más → más vistas → más viral
Este efecto de “el rico se hace más rico” genera naturalmente distribuciones de ley de potencias.
1. Distribución de Riqueza
La riqueza sigue una distribución Pareto con $\alpha \approx 1.5$:
- El 1% más rico posee ~50% de la riqueza global
- Jeff Bezos solo tiene más que el PIB de muchos países
Implicación: El “promedio” de riqueza es engañoso. La mediana es mucho más representativa.
2. Tamaño de Ciudades (Ley de Zipf)
$$\text{Población de ciudad rank } r \propto r^{-1}$$
- Tokyo: ~38 millones
- Ciudad #100: ~3 millones
- Ciudad #1000: ~300 mil
3. Rendimientos Financieros
Los retornos de acciones NO son normales:
- Lunes Negro (1987): caída de 22.6% (un evento de ~20 sigmas si fuera normal)
- Flash Crash (2010): caída de 9% en minutos
- Eventos de “6 sigmas” ocurren varias veces por década
Si los mercados fueran normales:
- Un evento de 5σ ocurriría cada 14,000 años
- En realidad: ocurren cada pocos años
4. Terremotos
La magnitud de terremotos sigue ley de potencias (Gutenberg-Richter): $$\log_{10} N = a - bM$$
Un terremoto de magnitud 8 no es “un poco peor” que uno de magnitud 7 — libera ~32 veces más energía.
5. Pandemias y Eventos de Mortalidad
La distribución de muertes por pandemias es fat-tailed:
- Gripe estacional: miles de muertes
- COVID-19: millones
- Gripe Española (1918): 50-100 millones
- Peste Negra: ~200 millones
6. Éxito de Libros/Películas/Apps
- La mayoría de libros venden pocas copias
- Unos pocos venden millones
- Harry Potter vs el libro promedio: factor de ~1 millón
Aplicando la prueba de Taleb: Si un editor tiene 100 libros que vendieron 1 millón de copias en total, ¿es más probable que:
- (a) Cada libro vendió ~10,000 copias?
- (b) Un libro vendió 900,000 y los otros 99 vendieron ~1,000 cada uno?
Respuesta: (b) es mucho más probable. Por eso los editores buscan “el próximo Harry Potter”.
7. Cyberataques y Fallas de Sistemas
- La mayoría de bugs son menores
- Unos pocos causan daños de billones (Equifax, SolarWinds)
Por Qué el TLC Falla (y cuándo la LGN es lenta)
Tres Regímenes según $\alpha$
Es crucial entender qué pasa según el exponente de cola $\alpha$:
| Régimen | Media | Varianza | LGN | TLC | Ejemplo |
|---|---|---|---|---|---|
| $\alpha > 2$ | Finita | Finita | ✓ Funciona | ✓ Funciona | Pareto α=3 |
| $1 < \alpha \leq 2$ | Finita | Infinita | ✓ Funciona (lento) | ✗ Falla | Pareto α=1.5 |
| $\alpha \leq 1$ | Infinita | Infinita | ✗ Falla | ✗ Falla | Cauchy |
Caso Extremo: Cauchy (α = 1)
Sea $X_1, X_2, \ldots$ i.i.d. Cauchy estándar.
El promedio $\bar{X}_n = \frac{1}{n}\sum X_i$ es… ¡también Cauchy estándar!
No importa cuántos datos tengas, el promedio no converge porque la media no existe.
Caso Intermedio: Pareto con $1 < \alpha \leq 2$
Este es el caso más engañoso. Para Pareto con α=1.5:
- La media existe y es finita: $\mu = \frac{\alpha}{\alpha-1} = 3$
- La varianza es infinita
- La LGN sí aplica: el promedio $\bar{X}_n \to 3$ eventualmente
- PERO la convergencia es extremadamente lenta
¿Qué tan lenta?
La velocidad de convergencia ya no es $1/\sqrt{n}$ sino aproximadamente $1/n^{1-1/\alpha}$. Para α=1.5, esto significa convergencia como $1/n^{1/3}$ — necesitarías $n = 10^9$ para lograr lo que con variables normales logras con $n = 1000$.
El TLC Falla Aunque la LGN Funcione
Cuando $1 < \alpha \leq 2$:
- El promedio SÍ converge a la media verdadera (LGN)
- Pero la distribución del promedio NO es normal (TLC falla)
- La distribución límite es una distribución estable asimétrica
- Los intervalos de confianza basados en normalidad son incorrectos
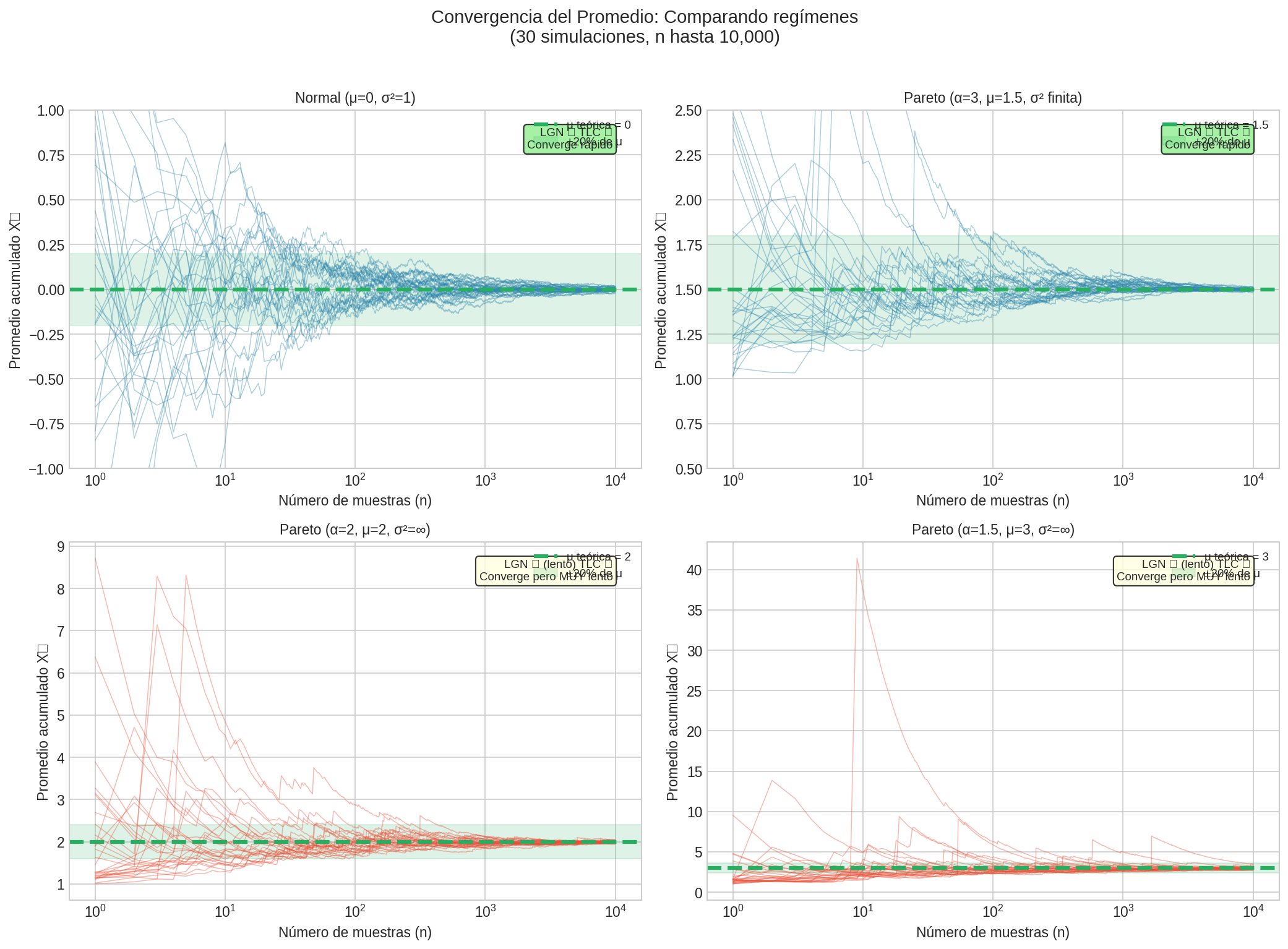
Las gráficas muestran que Pareto α=3 (varianza finita) converge rápido y limpiamente, mientras que Pareto α=1.5 y α=2 (varianza infinita) convergen eventualmente pero con mucha más volatilidad y lentitud.
El Error del Pavo de Acción de Gracias
“Consider a turkey that is fed every day. Every single feeding will firm up the bird’s belief that it is the general rule of life to be fed every day by friendly members of the human race… On the Wednesday before Thanksgiving, something unexpected will happen to the turkey.” — Taleb, The Black Swan
El problema: Usar datos históricos para estimar riesgos futuros asume que el futuro será como el pasado.
En dominios fat-tailed:
- La mayor pérdida futura será probablemente mayor que cualquier pérdida histórica
- El “peor caso” histórico subestima el verdadero peor caso
Consecuencias Prácticas
1. El Promedio es Engañoso
En distribuciones fat-tailed, el promedio muestral:
- Es muy volátil (cambia drásticamente con nuevas observaciones)
- Converge tan lentamente que es prácticamente inútil en tamaños de muestra realistas
- Puede estar dominado por una sola observación extrema
- No es representativo del “caso típico” (la mediana puede ser muy diferente)
Recomendación: Usar la mediana o cuantiles en lugar del promedio.
2. Los Intervalos de Confianza Son Inútiles
Los intervalos de confianza estándar asumen normalidad.
Con fat tails:
- El intervalo del 95% puede excluir eventos que ocurren regularmente
- La cola “fuera del intervalo” contiene la mayor parte del riesgo
3. El Tamaño de Muestra “Suficiente” Es Enorme
Para distribuciones normales: $n=30$ suele bastar para que el TLC aplique.
Para distribuciones fat-tailed con $1 < \alpha \leq 2$:
- Teóricamente el promedio converge (la media existe)
- Prácticamente necesitarías $n > 10^6$ o más para convergencia estable
- La convergencia es tan lenta que en la práctica es como si no convergiera
- Y aún con millones de datos, una nueva observación extrema puede cambiar todo
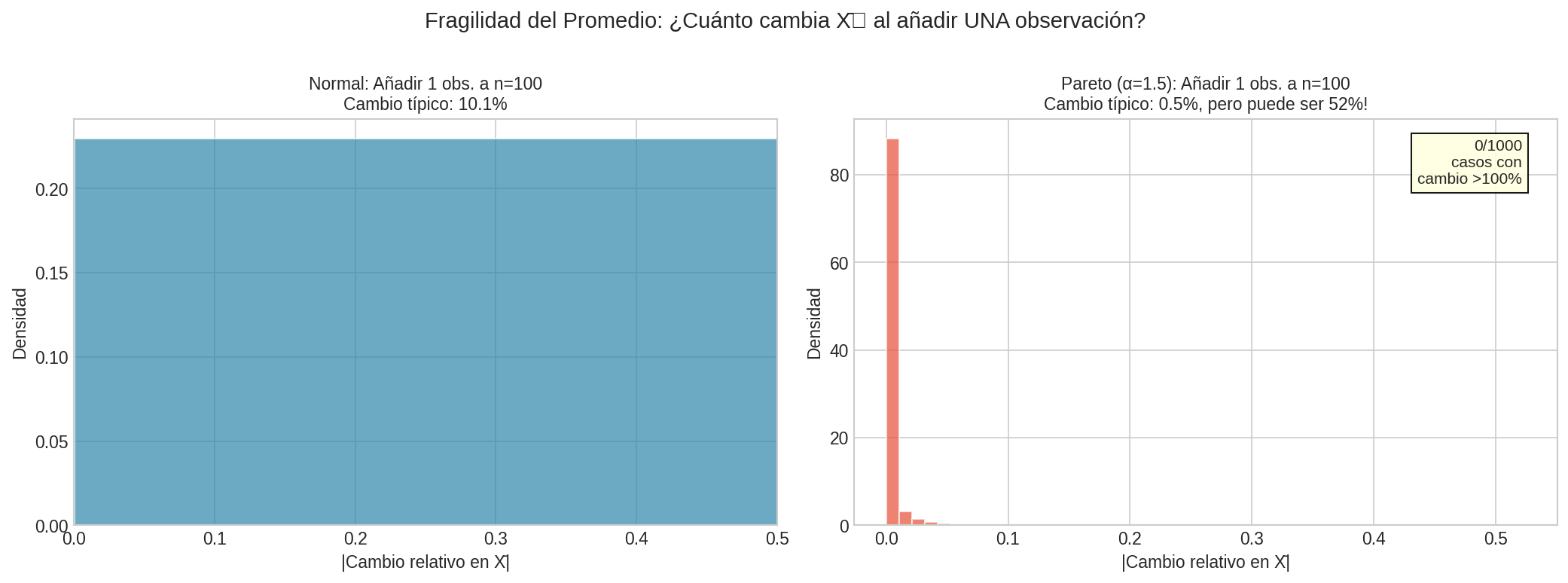
En fat tails, añadir UNA sola observación puede cambiar drásticamente el promedio. Este es el efecto de los “cisnes negros”.
4. No Puedes “Promediar” el Riesgo
En thin tails, la diversificación funciona porque el promedio de muchas variables es estable.
En fat tails, es al revés:
Imagina que inviertes en 100 startups. Con distribución thin-tailed:
- Cada una contribuye ~1% al resultado total
- Si una falla, pierdes ~1%
Con distribución fat-tailed (que es la realidad):
- Una startup exitosa puede valer más que las otras 99 juntas
- Si pierdes ESA startup, perdiste casi todo
“No puedes diversificar un cisne negro. El que te mata es el que no ves venir.” — Taleb
5. Diversificación No Funciona en las Colas
En finanzas, la diversificación asume que los riesgos son independientes.
En eventos fat-tailed:
- Los eventos extremos tienden a ocurrir juntos (correlación en las colas)
- Cuando más necesitas diversificación, menos funciona
- En 2008, TODOS los activos “diversificados” cayeron juntos
Caso de Estudio: Value at Risk (VaR) y la Crisis de 2008
¿Qué es el VaR?
El Value at Risk (Valor en Riesgo) es LA medida estándar de riesgo financiero usada por bancos, fondos de inversión y reguladores.
Definición: El VaR al nivel de confianza $\alpha$ es la pérdida máxima que no se superará con probabilidad $\alpha$.
$$\text{VaR}_\alpha = -\inf{x : P(R \leq x) \geq 1-\alpha}$$
En palabras simples:
- VaR₉₉ = “El 99% de los días, no perderemos más que esta cantidad”
- VaR₉₅ = “El 95% de los días, no perderemos más que esta cantidad”
Cómo se Calcula (Método Paramétrico)
Asumiendo que los retornos $R$ son normales:
$$R \sim \mathcal{N}(\mu, \sigma^2)$$
El VaR se calcula como:
$$\text{VaR}_\alpha = -(\mu + z_\alpha \cdot \sigma)$$
donde $z_\alpha$ es el cuantil de la normal estándar:
- Para VaR₉₉: $z_{0.01} \approx -2.33$
- Para VaR₉₅: $z_{0.05} \approx -1.65$
Ejemplo: Si $\mu = 0.05%$ diario y $\sigma = 1%$ diario: $$\text{VaR}_{99} = -(0.05% - 2.33 \times 1%) \approx 2.28%$$
“El 99% de los días, no perderemos más del 2.28%”
El Problema: La Normalidad es Falsa
El VaR paramétrico asume normalidad. Pero los retornos financieros son fat-tailed.
Consecuencias:
-
Subestima la frecuencia de pérdidas extremas
- El modelo dice: “violaciones del VaR₉₉ en 1% de los días”
- La realidad: violaciones en 2-5% de los días
-
Subestima la severidad de las pérdidas
- Cuando el VaR falla, falla catastróficamente
- El modelo dice “máximo 2.3%”, pero la pérdida real es 8%, 15%, 22%…
-
Da falsa sensación de seguridad
- Los gestores creen que tienen el riesgo “controlado”
- Hasta que llega un cisne negro
La Crisis de 2008: VaR en Acción
Antes de la crisis, los bancos reportaban:
- “Nuestro VaR₉₉ diario es $50 millones”
- “Estamos bien capitalizados”
Lo que pasó:
- Días con pérdidas de $500M, $1B, $5B…
- Eventos que según el modelo eran de “una vez cada 10,000 años”
- Ocurrieron múltiples veces en semanas
Cita de David Viniar (CFO de Goldman Sachs, agosto 2007):
“We were seeing things that were 25-standard deviation moves, several days in a row.”
Un evento de 25σ en una distribución normal tiene probabilidad $\approx 10^{-135}$. Eso es menos probable que ganar la lotería todos los días durante un año. Pero “ocurrió” varios días seguidos.
La realidad: No fueron eventos de 25σ. Los retornos simplemente no son normales.
Expected Shortfall (ES): Una Alternativa
El Expected Shortfall (también llamado CVaR o Tail VaR) responde:
“Cuando las cosas van mal, ¿qué tan mal van?”
$$\text{ES}_\alpha = E[R | R < -\text{VaR}_\alpha]$$
Es el promedio de las pérdidas en los peores $(1-\alpha)%$ de casos.
Ventajas:
- Considera la severidad, no solo la frecuencia
- Es una medida “coherente” de riesgo (tiene mejores propiedades matemáticas)
- Reguladores (Basilea III) ahora lo requieren
Desventaja: Sigue siendo sensible al modelo de distribución.
Lección para Fat Tails
En dominios fat-tailed, las medidas de riesgo basadas en normalidad son peligrosamente optimistas.
Soluciones:
- Usar distribuciones fat-tailed reales (Pareto, GPD) — no Student-t
- Usar métodos no paramétricos (simulación histórica)
- Complementar con stress testing (escenarios extremos)
- Usar Expected Shortfall en lugar de VaR
- Humildad epistemológica: aceptar que no podemos cuantificar todos los riesgos
La lección de Viniar: Si tu modelo dice que algo es “25 sigmas”, el problema no es el evento — es tu modelo.
Metodología: Detectar, Estimar y Actuar
Esta es la guía práctica paso a paso para trabajar con datos que pueden tener fat tails.
PASO 1: Detección Visual
Antes de calcular nada, haz estos gráficos:
1.1 QQ-Plot contra Normal
Compara los cuantiles de tus datos con los cuantiles normales.
- Línea recta = datos probablemente normales
- Curvatura en los extremos = colas más pesadas que Normal
import scipy.stats as stats
stats.probplot(datos, dist="norm", plot=plt)
1.2 Gráfico Log-Log de Supervivencia
Si $P(X > x) \propto x^{-\alpha}$, entonces en log-log es lineal: $$\log P(X > x) = -\alpha \log x + c$$
sorted_data = np.sort(np.abs(datos))[::-1]
survival = np.arange(1, len(sorted_data)+1) / len(sorted_data)
plt.loglog(sorted_data, survival)
Interpretación:
- Línea recta = Power law (fat tails)
- Curva hacia abajo = Decaimiento más rápido (thin tails)
1.3 Mean Excess Function
$$e(u) = E[X - u | X > u]$$
def mean_excess(data, u):
excesses = data[data > u] - u
return np.mean(excesses) if len(excesses) > 0 else np.nan
Interpretación:
- Constante = Exponencial (thin tails)
- Creciente = Fat tails
- Decreciente = Thin tails con truncamiento
PASO 2: Estimación del Índice de Cola α
El parámetro clave es $\alpha$. Determina qué momentos existen:
2.1 Estimador de Hill
El método estándar para estimar α usando las k observaciones más extremas:
$$\hat{\alpha}{Hill} = \left(\frac{1}{k}\sum^k \log\frac{X_{(n-i+1)}}{X_{(n-k)}}\right)^{-1}$$
def hill_estimator(data, k=None):
"""Estima el índice de cola α."""
sorted_data = np.sort(np.abs(data))[::-1]
if k is None:
k = int(np.sqrt(len(data)))
log_ratios = np.log(sorted_data[:k] / sorted_data[k])
return k / np.sum(log_ratios)
Reglas prácticas para k:
- $k \approx \sqrt{n}$ es un buen punto de partida
- Grafica $\hat{\alpha}$ vs $k$ — debería estabilizarse
2.2 Kappa de Taleb
$$\kappa = \frac{\max |X_i|}{\sum |X_i|}$$
def kappa_taleb(data):
return np.max(np.abs(data)) / np.sum(np.abs(data))
Interpretación:
- $\kappa < 0.01$ con n=1000 → probablemente thin tails
- $\kappa > 0.05$ con n=1000 → probablemente fat tails
- Si $\kappa$ no decrece con n → definitivamente fat tails
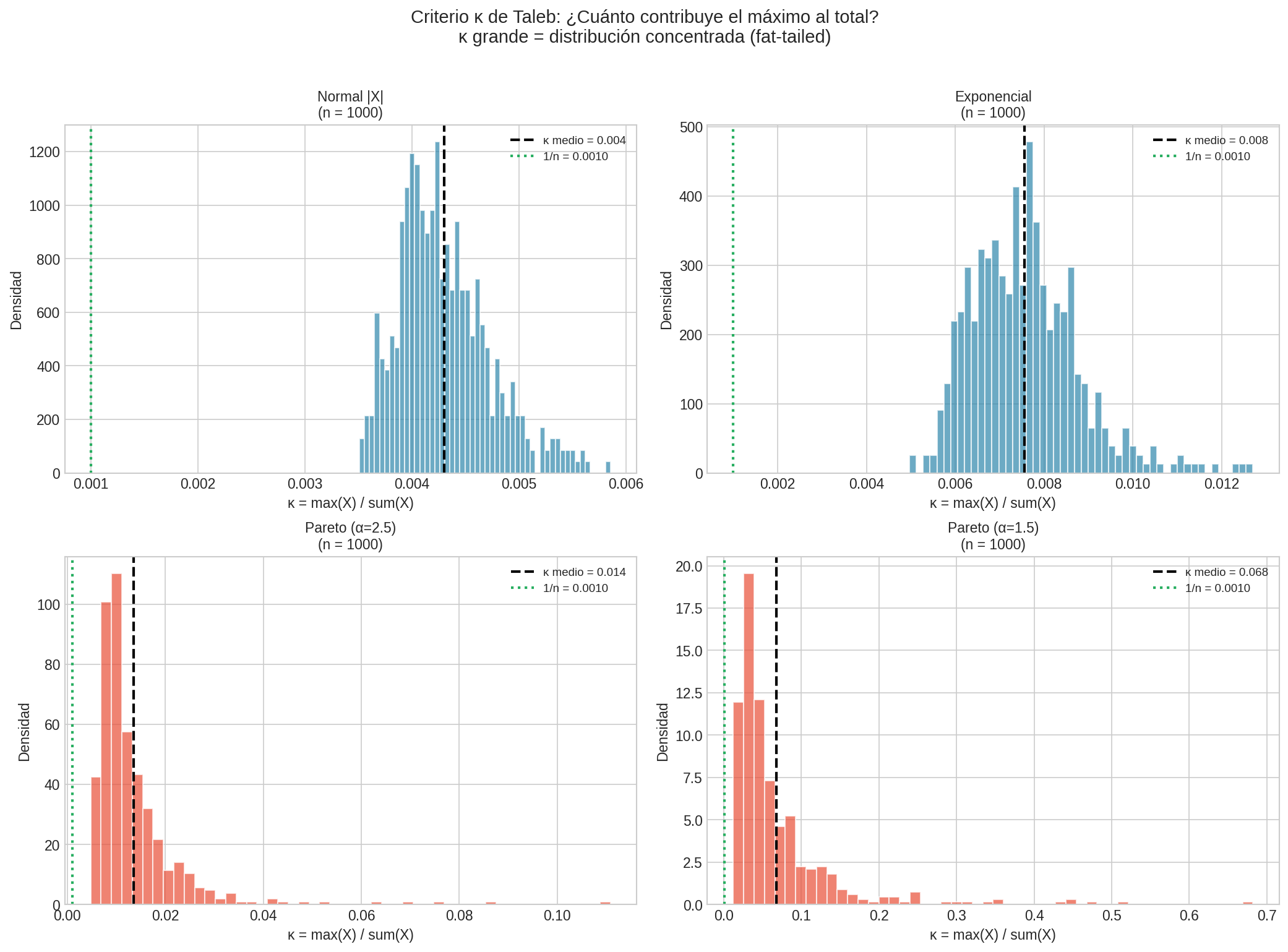
2.3 Tabla de Interpretación de α
| $\hat{\alpha}$ | Interpretación | Consecuencias |
|---|---|---|
| > 4 | Casi thin-tailed | Media, varianza, kurtosis finitas. TLC funciona. |
| 3-4 | Fat-tailed leve | Kurtosis puede ser infinita. TLC más lento. |
| 2-3 | Fat-tailed moderado | Varianza finita pero kurtosis infinita. Cuidado con intervalos de confianza. |
| 1-2 | Fat-tailed severo | Varianza infinita. TLC no funciona. Media inestable. |
| < 1 | Extremadamente fat-tailed | Media infinita. LGN no funciona. Promedio sin sentido. |
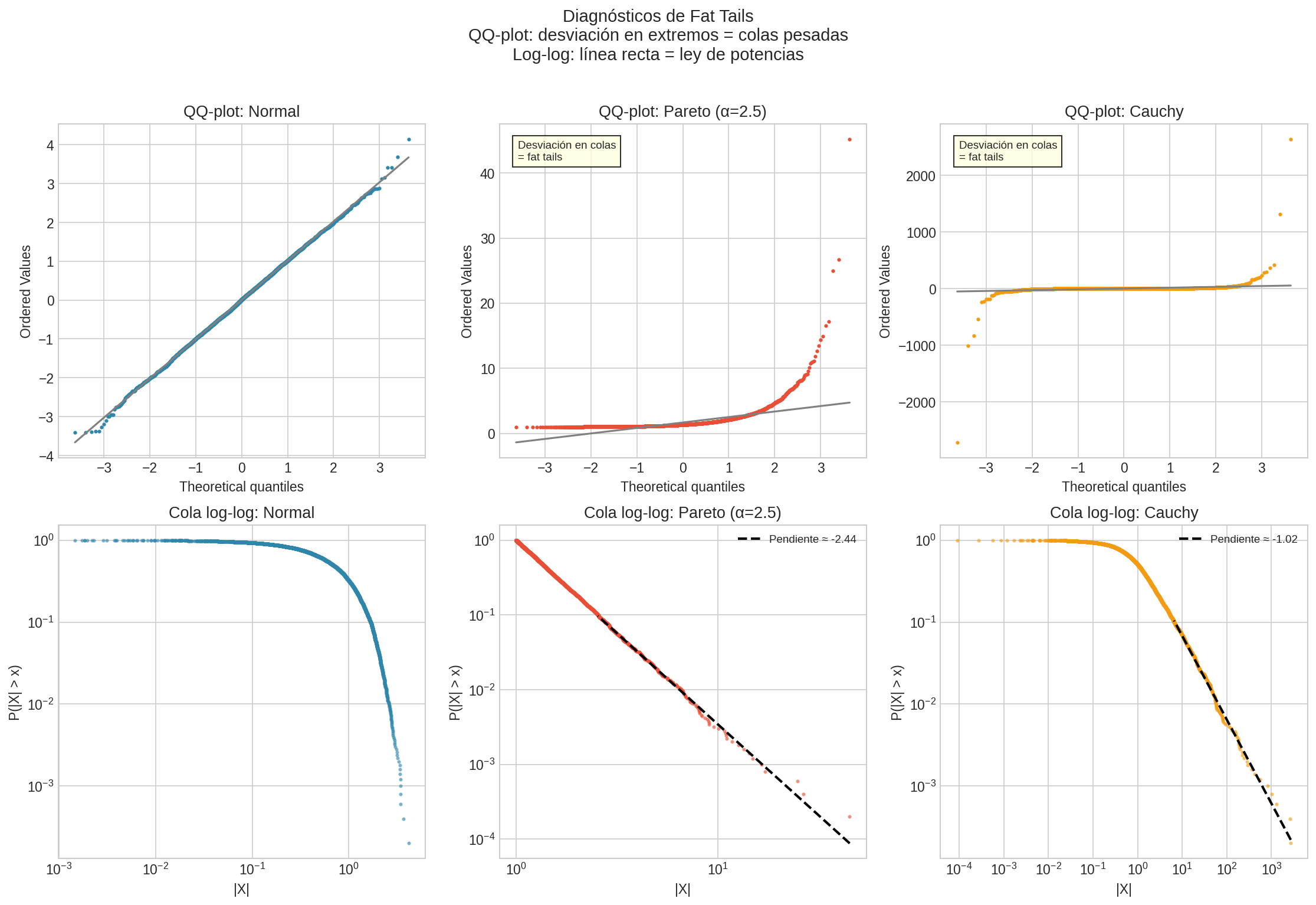
PASO 3: Tests Estadísticos
3.1 Test de Jarque-Bera
Testa normalidad usando skewness y kurtosis:
from scipy.stats import jarque_bera
stat, pvalue = jarque_bera(datos)
# Si pvalue < 0.05: rechazar normalidad
Limitación: Solo detecta desviaciones “promedio”, no colas extremas.
3.2 Contar Eventos Extremos
def contar_sigmas(data, sigma_threshold):
"""Cuenta eventos > k sigmas."""
z = (data - data.mean()) / data.std()
return (np.abs(z) > sigma_threshold).sum()
# Comparar con esperado bajo normalidad
n = len(data)
for k in [3, 4, 5, 6]:
obs = contar_sigmas(data, k)
esp = n * 2 * (1 - stats.norm.cdf(k))
print(f">{k}σ: observados={obs}, esperados={esp:.1f}, ratio={obs/esp:.1f}x")
Interpretación:
- Ratio > 2x para k ≥ 4 → fuerte evidencia de fat tails
PASO 4: ¿Qué Hacer si Hay Fat Tails?
Una vez confirmadas las fat tails, hay que adaptar el análisis:
4.1 Estimación de Tendencia Central
| En lugar de… | Usar… | Por qué |
|---|---|---|
| Media | Mediana | Robusta a extremos |
| Varianza | MAD (Median Absolute Deviation) | No asume momentos finitos |
| Promedio móvil | Mediana móvil | Más estable |
from scipy.stats import median_abs_deviation
centro = np.median(data)
dispersion = median_abs_deviation(data)
4.2 Intervalos de Confianza
NO usar intervalos normales. Opciones:
- Bootstrap: Remuestrear y calcular percentiles
- Cuantiles empíricos: Usar directamente los datos
- EVT: Extreme Value Theory para las colas
# Bootstrap IC para la mediana
from scipy.stats import bootstrap
result = bootstrap((data,), np.median, confidence_level=0.95)
4.3 Medidas de Riesgo
| Métrica Normal | Alternativa Fat-Tail |
|---|---|
| VaR paramétrico | VaR histórico o EVT |
| σ como riesgo | Expected Shortfall |
| Correlación | Correlación de colas |
4.4 Predicción y Modelado
- No extrapolar de la media muestral
- Stress testing: Simular escenarios peores que cualquier histórico
- Principio de precaución: Asumir que el peor caso será peor
PASO 5: Resumen del Flujo de Trabajo
┌─────────────────────────────────────────────────────────────┐
│ DATOS NUEVOS │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ PASO 1: Visualización │
│ - QQ-plot vs Normal │
│ - Log-log survival │
│ - Mean excess function │
└─────────────────────────────────────────────────────────────┘
│
┌────────────┴────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Parece normal │ │ Parece fat-tail │
└─────────────────┘ └─────────────────┘
│ │
▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ PASO 2: Estimación │
│ - Calcular α con Hill │
│ - Calcular κ de Taleb │
│ - Evaluar estabilidad con n │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ PASO 3: Decisión │
│ │
│ α > 4 → Métodos clásicos OK (con precaución) │
│ 2 < α ≤ 4 → Usar medianas, bootstrap, EVT │
│ α ≤ 2 → ¡ALARMA! Varianza infinita │
│ Repensar completamente el análisis │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ PASO 4: Adaptar metodología │
│ - Cambiar de media a mediana │
│ - Usar bootstrap para IC │
│ - Usar VaR histórico o EVT │
│ - Hacer stress testing │
└─────────────────────────────────────────────────────────────┘
Qué Hacer con Fat Tails
1. Reconocer el Dominio
Mediocristán (thin-tailed):
- Alturas, pesos, temperaturas
- El promedio es informativo
- Los extremos no dominan
Extremistán (fat-tailed):
- Riqueza, ventas, catástrofes
- El promedio es engañoso
- Los extremos dominan
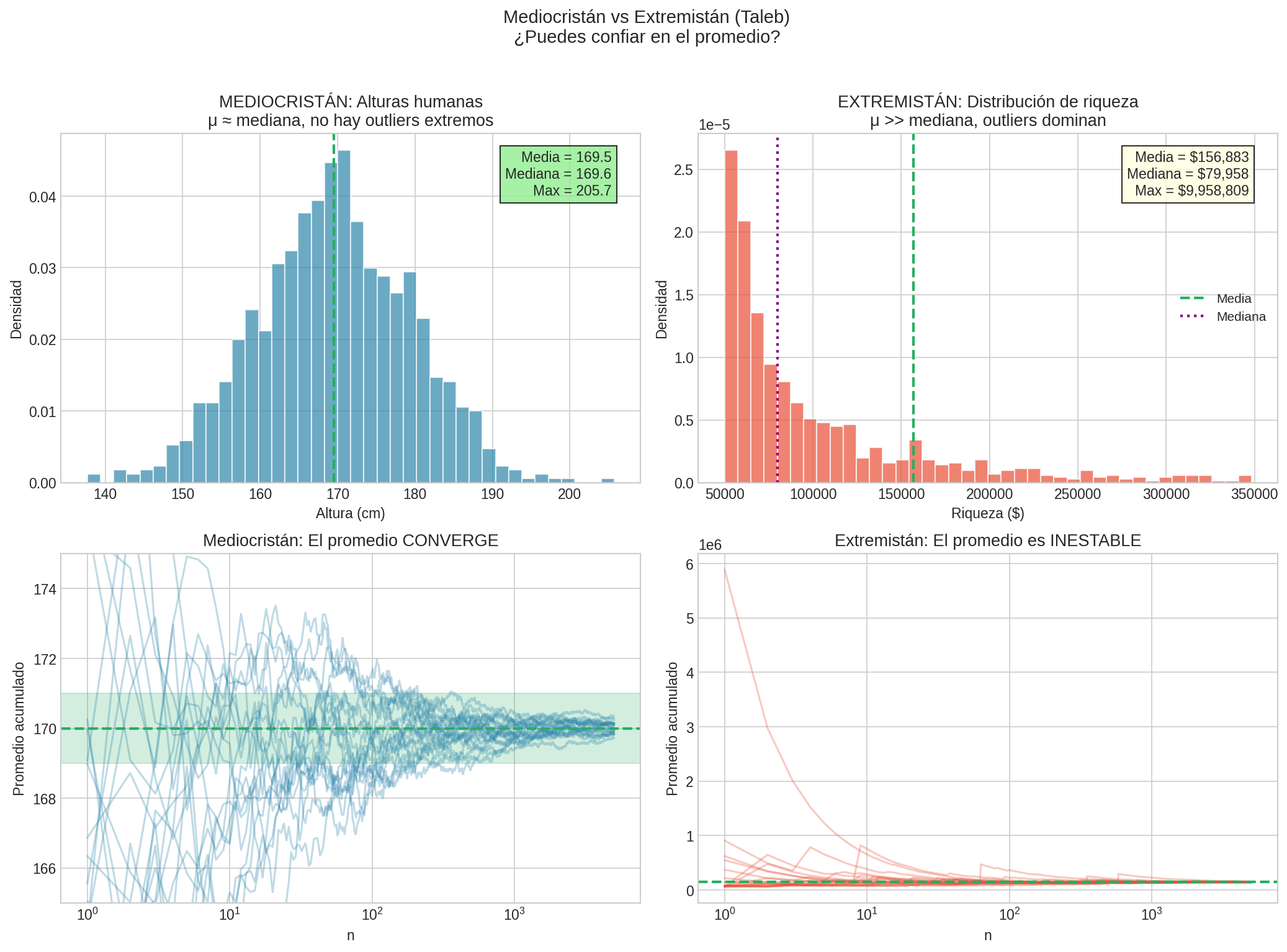
Comparación de convergencia del promedio: en Mediocristán converge, en Extremistán es inestable.
2. Usar Estadísticas Robustas
En lugar de:
- Media → usar mediana
- Varianza → usar MAD (median absolute deviation)
- Correlación → usar correlación de rangos
3. Aplicar el Principio de Precaución
En dominios fat-tailed:
- Asume que el peor caso será peor de lo observado
- Construye sistemas que sobrevivan a eventos extremos
- Evita exposición a “cola izquierda” (eventos catastróficos)
4. Entender la Asimetría
No todas las colas importan igual:
- Cola derecha positiva (ganancias): puede ser deseable (startups)
- Cola izquierda negativa (pérdidas): puede ser catastrófica (riesgos)
El Mensaje de Taleb
“In Extremistan, one single observation can disproportionately impact the aggregate.”
La Regla de Oro de Fat Tails
Pregunta clave: “Si X + Y es muy grande, ¿es más probable que sea por X, por Y, o por ambas?”
- Si la respuesta es “ambas” → estás en Mediocristán
- Si la respuesta es “una de ellas” → estás en Extremistán
Ejemplos:
| Suma grande | Mediocristán | Extremistán |
|---|---|---|
| Dos alturas suman 4m | Ambos ~2m | Imposible: uno no mide 3.5m |
| Dos fortunas suman $10B | Casi imposible | Uno tiene ~$9B |
| Dos terremotos = 10^9 joules | Imposible | Uno fue magnitud 8+ |
| Dos libros = 1M ventas | Raro | Uno vendió 900K |
La Analogía del Peso
“Si la suma de los pesos de 1000 personas es anormalmente alta, probablemente es porque hay muchas personas con sobrepeso. Si la suma de las riquezas de 1000 personas es anormalmente alta, probablemente es porque hay UN billonario.”
Las herramientas estadísticas clásicas fueron diseñadas para Mediocristán. Aplicarlas en Extremistán es como usar un mapa de Kansas para navegar los Himalayas.
La humildad epistemológica es clave:
- No sabemos lo que no sabemos
- Los eventos raros son más importantes que los frecuentes
- La incertidumbre sobre la incertidumbre (meta-incertidumbre) importa
- El próximo cisne negro será diferente a los anteriores
Laboratorio de Simulación
Para explorar estos conceptos visualmente, ejecuta el laboratorio de simulación:
python lab_probabilidad.py
Esto generará imágenes comparando:
- Convergencia de promedios: Normal vs Cauchy vs Pareto
- Distribución de sumas: thin-tailed vs fat-tailed
- Diagnósticos de fat tails
Referencias
- Taleb, N.N. Statistical Consequences of Fat Tails (Technical Incerto, 2020)
- Taleb, N.N. The Black Swan (2007)
- Mandelbrot, B. The Misbehavior of Markets (2004)
- Clauset, Shalizi, Newman “Power-law distributions in empirical data” (2009)
Resumen
| Concepto | Thin-Tailed | Fat-Tailed |
|---|---|---|
| Colas | Decaen exponencialmente | Decaen como potencia |
| Varianza | Finita | Puede ser infinita |
| TLC | Aplica | No aplica o converge muy lento |
| Promedio | Estable | Volátil |
| Eventos extremos | Raros | Frecuentes |
| max/sum | → 0 | Permanece alto |
| “Suma grande por…” | …muchos valores | …UN valor extremo |
| Ejemplo | Alturas | Riqueza |
Checklist: ¿Estoy en Extremistán?
Responde SÍ/NO:
- ☐ ¿Puede el valor más grande ser 1000x el promedio?
- ☐ ¿Eliminar una observación cambiaría significativamente la media?
- ☐ ¿Los “outliers” ocurren más frecuentemente de lo que Normal predice?
- ☐ ¿Hay efectos de red o “winner takes all”?
- ☐ ¿El éxito/fracaso se concentra en pocos casos?
Si respondiste SÍ a ≥2 preguntas, probablemente estás en Extremistán.
Mensaje final: Antes de aplicar cualquier técnica estadística, pregúntate: ¿Estoy en Mediocristán o Extremistán? Si es lo segundo, tus intervalos de confianza, tus promedios, y tus modelos de riesgo probablemente están peligrosamente equivocados.
Siguiente: Laboratorio de Simulación | ← Volver al índice