Introducción: ¿Qué es “información” y por qué importa?
La palabra información se usa para todo:
- “Te paso información del proyecto.”
- “Esa noticia tiene mucha información.”
- “Mi modelo aprende información de los datos.”
En teoría de la información vamos a darle un significado operativo: algo medible que conecta con preguntas, códigos, compresión, predicción y (más adelante) con aprendizaje.
Pero antes de fórmulas, hay que resolver una confusión real: “información” en español coloquial no significa lo mismo que “información” en teoría de la información.
Antes de empezar: tres sentidos de “información” (y por qué aquí usamos uno técnico)
Cuando decimos “eso me dio mucha información”, podemos estar hablando de al menos tres cosas distintas:
1) Información (coloquial): “lo que me sirve para actuar”
Ejemplos:
- “Si el semáforo está en rojo, eso es toda la información que necesito: freno.”
- “Si el test salió positivo, tomo una decisión.”
Aquí “información” se refiere a utilidad para una tarea. Puede ser 1 bit, 0.01 bits, o 100 bits: lo coloquial no mide eso.
2) Información (epistémica): “qué alternativas descarto”
Aquí ya se parece al lenguaje técnico:
“Antes no sabía cuál de muchas posibilidades era cierta; después, ya descarté varias.”
3) Información (técnica, teoría de la información): “costo de especificar lo que pasó, dado lo que ya esperaba”
Este es el punto clave del módulo:
En teoría de la información, “información” se mide como cuántos bits (mínimos) necesitas para identificar o describir el resultado, relativo a un modelo/prior de qué tan probable era cada resultado.
Por eso aparecen expresiones como $-\log p$ y entropía: no es por gusto; es porque queremos una medida que sea:
- consistente,
- aditiva para eventos independientes,
- y conectada con compresión/decodificación.
Un ejemplo que rompe la intuición coloquial (y por eso es importante)
Supón que hoy decides si llevar paraguas.
Tu pronóstico (tu prior) es:
- $p(\text{llueve}\mid I)=0.01$
- $p(\text{no llueve}\mid I)=0.99$
Ahora pasa “no llueve”.
Coloquialmente
Eso puede ser toda la información que necesitabas para irte sin paraguas.
Técnicamente (sorpresa / costo de especificación)
Que no llueva era lo esperado. Entonces su “sorpresa” es muy pequeña:
$$ I(\text{no llueve})=-\log_2(0.99)\approx 0.014\ \text{bits} $$
Mientras que si llueve (evento raro), la sorpresa es grande:
$$ I(\text{llueve})=-\log_2(0.01)\approx 6.64\ \text{bits} $$
Ambas cosas pueden ser verdad a la vez:
- un evento puede ser muy útil para una tarea,
- y tener poca sorpresa bajo tu modelo.
En este módulo, cuando midamos “información”, casi siempre estaremos midiendo sorpresa/costo de especificación relativo al prior.
Por qué hablamos así (y por qué aparece $-\log p$)
Se habla así porque la teoría no intenta capturar el uso coloquial de “información”. Intenta construir una cantidad que cumpla requisitos matemáticos y operativos muy concretos.
La confusión típica es esta:
- En lenguaje cotidiano, “información” suele significar “algo útil para mi objetivo”.
- Aquí, “información” significa “cuánto tuve que especificar para identificar lo que pasó, dado lo que ya esperaba”.
1) ¿Qué problema está resolviendo la definición $I(x)=-\log_2 p(x\mid I)$?
Si el mundo elige un resultado $x$ según un prior $p(\cdot\mid I)$, queremos una medida razonable del “contenido” de observar $x$.
Pedimos que esa medida:
- Sea mayor para eventos raros: si casi nunca pasa, cuando pasa “dice más” (tiene más sorpresa).
- Sea aditiva para eventos independientes: si pasan dos cosas independientes, el contenido total debería sumarse.
- Tenga interpretación operacional (no solo filosofía): conecte con preguntas/códigos.
La condición clave es la aditividad:
$$ I(x,y)=I(x)+I(y)\quad \text{si } p(x,y\mid I)=p(x\mid I)p(y\mid I) $$
Eso “fuerza” (bajo supuestos suaves) que la forma sea un logaritmo. El signo “-” aparece porque $p\in(0,1]$ y queremos una cantidad no negativa.
2) ¿Por qué “respecto al prior”? ¿qué es lo aprendido?
Porque sin un prior no existe una noción de “sorpresa” o “novedad”.
El prior $p(\cdot\mid I)$ representa lo que ya creías (tu contexto $I$). Entonces “aprender” aquí significa:
cuánto cambió tu estado de conocimiento al ver $x$, medido como cuántas alternativas plausibles descartaste según tu propio modelo.
Si $p(x\mid I)=0.99$, observar $x$ no reestructura mucho tu panorama: ya estabas prácticamente convencido.
Si $p(x\mid I)=0.01$, observar $x$ sí cambia tu historia mental: pasó algo que casi descartabas.
Esto es muy Jaynes: las probabilidades (y por lo tanto entropía/información) son condicionadas a $I$, o sea al conocimiento disponible.
3) La justificación más concreta: codificación/decodificación
Aquí deja de ser una elección de palabras y se vuelve ingeniería:
- Imagina que quieres transmitir el resultado $x$ a alguien.
- Si $x$ es muy probable bajo el prior, puedes usar un código corto.
- Si $x$ es raro, necesitas un código largo para evitar ambigüedad.
El resultado profundo (que veremos en Códigos y compresión) es que una longitud ideal se comporta como:
$$ \ell(x)\approx -\log_2 p(x\mid I) $$
y el costo promedio mínimo se resume en la entropía $H(X\mid I)$ (ver Entropía).
Entonces “información” = “bits necesarios” no es metáfora: es literalmente el costo mínimo de describir/identificar lo ocurrido bajo el prior.
4) ¿Se refiere a preguntar o a decodificar?
Sí: es la misma idea vista desde dos ángulos.
- Preguntar (20 preguntas): eliges preguntas para identificar $x$ con pocas respuestas esperadas.
- Codificar (compresión): asignas longitudes de código para identificar $x$ con pocos bits esperados.
Ambos problemas llevan al mismo objeto matemático: $-\log p(x)$ para resultados individuales y $H(X)$ en promedio.
Si en algún punto una frase como “tiene poca información” suena rara, léela como:
- “tiene poca sorpresa (surprisal) relativa al prior”, o
- “requiere pocos bits para especificarse bajo el modelo”.
Entonces, ¿qué es la teoría de la información?
Es una teoría que unifica (con el mismo lenguaje matemático) preguntas como:
- Compresión: ¿cuántos bits necesito en promedio para codificar mensajes de una fuente?
- Comunicación: ¿cuántos bits puedo transmitir de forma confiable por un canal (con ruido)?
- Predicción / ML: ¿qué costo pago si mi modelo asigna probabilidad baja a lo que ocurre?
- Búsqueda / preguntas: ¿cómo elijo preguntas (o intentos) para identificar un estado oculto con pocos pasos esperados?
Lo que une estos problemas es que todos se pueden ver como:
“Hay un conjunto de posibilidades con probabilidades. Quiero identificar / describir / transmitir cuál ocurrió, con el menor costo promedio posible.”
Un problema real que vamos a reutilizar (Wordle / hacking)
Ahora sí, nuestra historia guía:
Hay una palabra secreta de 5 letras en español (sin acentos).
Tú quieres descubrirla haciendo intentos.
A veces recibes feedback (tipo Wordle). A veces no (tipo password guessing).
Dos versiones del mismo problema
- Con feedback (Wordle / “Fallout hacking”)
- Propones una palabra.
- El sistema te regresa una pista (verde/amarillo/gris).
- Sin feedback (password guessing)
- Propones una contraseña.
- Solo sabes si fue correcta o no.
La diferencia no es “de tema”: es cuánta información técnica recibes por intento.
Primera analogía útil (con advertencia): “información = pista”
Analogía:
Una pista buena es la que elimina muchas opciones plausibles.
- Qué captura bien: información como “reducir alternativas”.
- Qué es incompleto: no te dice “cuánto” ni cómo sumar pistas; para eso necesitamos probabilidades y números.
“Information is physical” (versión ligera y fascinante)
Hasta ahora suena como una teoría abstracta: bits, logs, entropía.
Pero hay un hecho sorprendente:
La información no es solo “un concepto”: cuando la manipulas en un dispositivo físico, hay costos físicos.
El principio de Landauer (la idea central)
En términos muy simples:
Borrar información (hacer una operación lógicamente irreversible, como forzar un bit a 0 sin importar si era 0 o 1) tiene un costo mínimo de energía disipada como calor.
Ese límite mínimo es:
$$ E_{\min} \approx kT\ln 2 $$
donde $k$ es la constante de Boltzmann y $T$ es la temperatura.
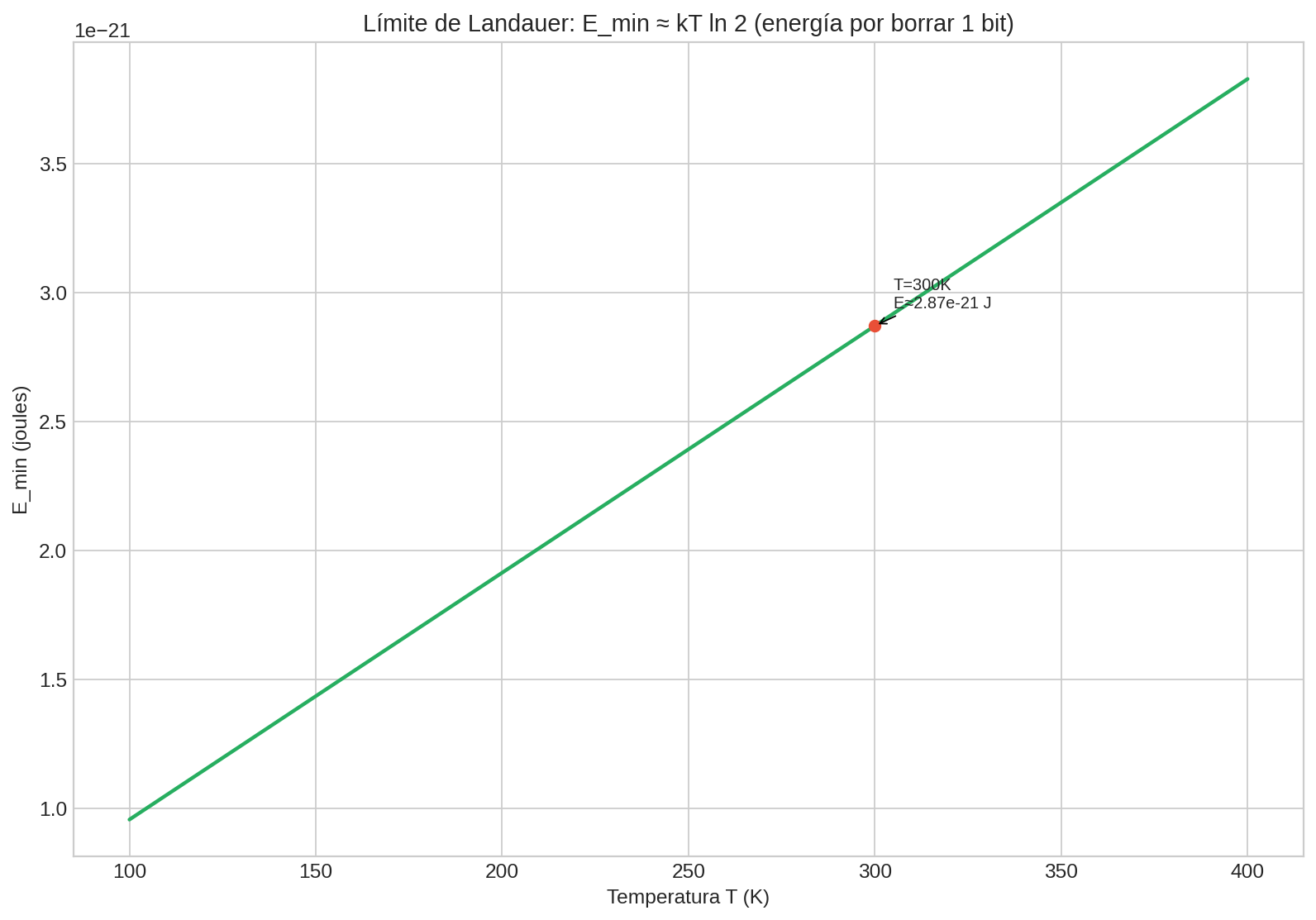
La gráfica muestra el orden de magnitud del límite a distintas temperaturas (y marca $T\approx 300K$). La idea no es memorizar el número: es internalizar que “borrar distinciones” tiene un costo físico mínimo.
Interpretación (sin meternos a física estadística)
- No significa que “guardar un bit cuesta $kT\ln 2$” siempre.
- Significa que borrar irreversiblemente (perder distinción entre estados) está ligado a disipación mínima.
Esto conecta profundamente el lenguaje de “bits” con el lenguaje de “entropía” en física: al final, ambos tratan con distinciones entre estados y con lo que cuesta perderlas.
¿Por qué esto es relevante en general?
Porque muchos problemas se pueden ver como:
- adivinar el estado del mundo (¿qué pasa?) a partir de señales ruidosas,
- comunicar (enviar una señal) usando pocos recursos,
- aprender (ajustar un modelo) para que haga buenas predicciones.
La teoría de la información es un lenguaje que aparece en:
- compresión (ZIP, imágenes, audio),
- transmisión (códigos correctores),
- estadística (log-likelihood),
- machine learning (cross-entropy loss),
- IA (selección de preguntas/acciones que maximizan información).
¿Por qué importa en IA y ML?
Un modelo de ML típico hace algo así:
- Recibe $x$ (features, tokens, pixeles).
- Produce una distribución $q(y\mid x)$ sobre respuestas posibles.
- Se entrena para que $q$ ponga probabilidad alta donde el mundo pone probabilidad alta.
Sin decirlo, lo que se optimiza muchas veces es:
- “qué tan sorprendido estaría el modelo” cuando ve la respuesta correcta,
- y ese “costo de sorpresa” se expresa con $-\log q(\cdot)$.
Ese puente lo haremos formal más adelante. Aquí solo queremos que suene razonable:
Si tu modelo asigna 0.001 a lo que ocurre, tu modelo va a “sufrir” cuando ocurra.
Lo que NO haremos (por ahora)
Para ir lento y bien:
- Todavía no definimos “entropía”.
- Todavía no asumimos que todo es “aleatorio”.
- Todavía no hablamos de canal, ruido, capacidad.
Primero: bits y preguntas.
Piensa en el juego de la palabra secreta (5 letras).
- Si solo supieras que la palabra está en una lista de 4096 palabras, ¿cuántas opciones hay al inicio?
- Si después de una pista reduces la lista a 512 palabras, ¿dirías que esa pista fue “buena”? ¿por qué?
- Si tuvieras que comparar dos pistas:
- Pista A reduce de 4096 a 2048
- Pista B reduce de 4096 a 256
¿cuál “aportó más información” y cómo lo justificarías sin fórmulas?
Siguiente: Bits y preguntas →
Volver: ← Índice