Bits y preguntas: distinguir posibilidades
Vamos a formalizar la intuición de la sección anterior:
Aprender (en el sentido más básico) es reducir el conjunto de posibilidades.
Y queremos medir “cuánto” reducimos.
Caso 1: todas las posibilidades son igual de plausibles
Supón que la palabra secreta está en una lista de $N$ palabras y, por simplicidad, al inicio todas son igual de plausibles.
Preguntas sí/no
Si puedes hacer preguntas tipo sí/no (preguntas binarias), una estrategia natural es:
- en cada pregunta, dividir el conjunto en dos mitades lo más iguales posible.
En el mejor caso, cada respuesta reduce $N$ a aproximadamente $N/2$.
Después de $k$ respuestas, tienes aproximadamente:
$$ N \rightarrow \frac{N}{2^k} $$
Quieres que quede 1 opción:
$$ \frac{N}{2^k} \approx 1 \quad\Rightarrow\quad 2^k \approx N \quad\Rightarrow\quad k \approx \log_2 N $$
Interpretación (la idea de “bit”)
$\log_2 N$ es el número de respuestas sí/no necesarias (en el mejor caso) para identificar una opción entre $N$.
Por eso el bit aparece como la unidad natural cuando tu “motor” de información son decisiones binarias.
Ejemplo acumulativo (uniforme)
Si al inicio tienes $N=4096$ palabras posibles:
$$ \log_2(4096)=12 $$
Interpretación:
En el mejor caso, 12 respuestas sí/no bien elegidas bastan para identificar la palabra.
Esto ya suena como “cantidad de información”: 12 bits para distinguir una palabra de entre 4096 opciones equiprobables.
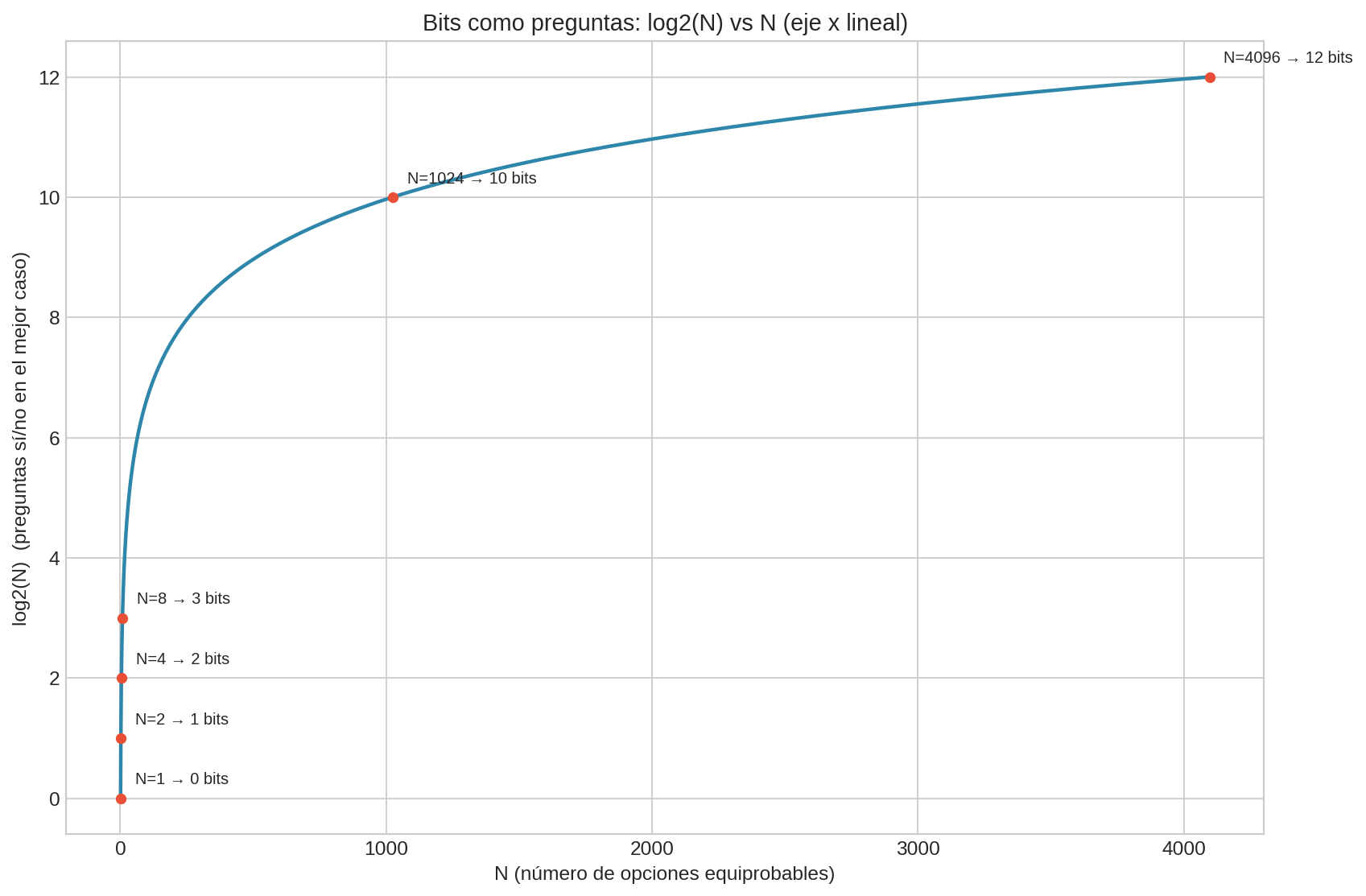
En eje x lineal se ve la idea correcta: $\log_2(N)$ no crece linealmente con $N$; crece lento. (Si graficas $N$ en eje log, la curva se ve casi recta; eso es un efecto de la escala, no de la función.)
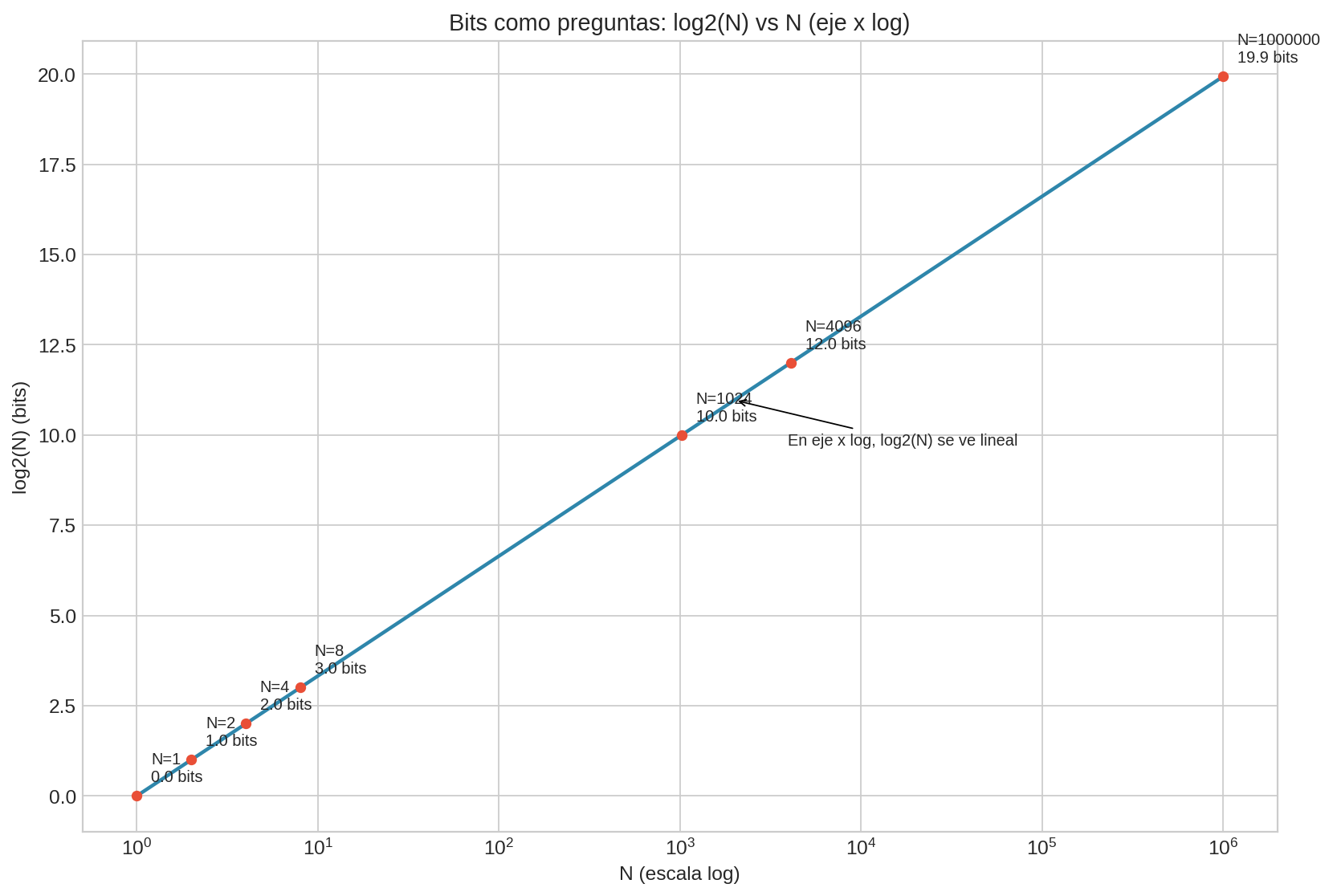
Esta segunda versión existe solo para mostrar un punto de visualización: en eje log, $\log_2(N)$ se ve lineal porque $\log_2(N)$ es proporcional a $\log_{10}(N)$.
Caso 2: no todo es igual de plausible (priors)
En español, no todas las palabras de 5 letras son igual de comunes.
Ejemplo informal:
- “canto” es más plausible que “xqzjk” (si esa existiera),
- y en passwords, “12345” es más plausible que “r7K!mQ”.
Aquí aparece una idea clave del módulo: la información depende del contexto.
- El contexto $I$ incluye cosas como: “estamos en español”, “son 5 letras”, “la gente elige passwords humanos”, etc.
- En notación estilo Jaynes, hablaríamos de $p(\text{palabra}\mid I)$.
¿Qué cambia exactamente cuando hay probabilidades?
Cuando todo era uniforme, “progreso” era casi lo mismo que contar cuántas opciones quedan.
Con priors ya no: ahora lo correcto es pensar en masa de probabilidad.
Intuición:
- Si eliminas 1000 opciones rarísimas, quizá no avanzaste mucho.
- Si eliminas 10 opciones pero eran las más plausibles, avanzaste muchísimo.
Dicho de otra forma:
Con priors, una buena pregunta no es la que parte el conjunto en dos mitades por tamaño, sino la que parte la distribución en dos mitades por probabilidad.
Esto es el puente entre “preguntas” y “probabilidad”.
Mini-ejemplo
Supón 8 candidatas. Una de ellas es muy plausible y las otras 7 son raras:
- $p(w_1)=0.50$
- $p(w_2)=\cdots=p(w_8)=0.50/7\approx 0.0714$
Compararemos dos preguntas:
- Pregunta A (por tamaño): “¿Está en ${w_1,w_2,w_3,w_4}$?”
(4 vs 4) - Pregunta B (por probabilidad): “¿Es $w_1$?”
(probabilidad 0.5 vs 0.5)
En promedio, la pregunta B es más “justa” en el sentido correcto porque está partiendo la masa de probabilidad en dos mitades iguales (0.5 y 0.5):
- si la respuesta es “sí”, ya terminaste;
- si la respuesta es “no”, eliminaste la opción más plausible.
La A parte por cantidad, pero no necesariamente por incertidumbre.
Este es exactamente el tipo de fenómeno que queremos medir con una fórmula.
“Ok, pero ¿cómo se decide la partición? ¿hay un algoritmo?”
Sí. Y es importante decirlo explícitamente para que el módulo sea coherente:
- Con priors, lo que estás construyendo es un árbol de preguntas (como “20 preguntas”), donde cada hoja es una candidata.
- Un objetivo natural es minimizar el número esperado de preguntas para identificar la respuesta.
Dos ideas (una local y una global):
-
Idea local (una pregunta a la vez)
Piensa en una pregunta binaria que divide las candidatas en dos grupos: “sí” y “no”.
El truco con priors es que ya no quieres 50/50 en cantidad, sino 50/50 en probabilidad: $$ P(\text{sí}\mid I)\approx P(\text{no}\mid I)\approx 0.5 $$ Intuición: si una respuesta casi siempre ocurre, la pregunta “no sorprende” (bajo el prior) y su ganancia esperada es pequeña.
(Lo hacemos formal en Entropía: una partición ~50/50 maximiza la ganancia esperada de información). -
Idea global (toda la secuencia)
Una secuencia de preguntas forma un árbol: cada respuesta te mueve a una rama y, al final, llegas a una hoja (la palabra).
Si quieres minimizar el número esperado de preguntas, las hojas más probables deberían quedar más cerca de la raíz (camino corto).
Esa es exactamente la misma lógica que en compresión: en un código prefijo, símbolos frecuentes deben tener códigos cortos.
En Códigos y compresión conectamos esto con dos hechos clave:- longitudes “ideales” se parecen a $\ell(x)\approx -\log p(x)$, y
- el costo promedio inevitable se resume en la entropía $H(X\mid I)$.
Pregunta crucial
Si hay priors, ya no basta contar opciones. Queremos algo como:
“¿Cuánta información me da observar un evento de probabilidad $p$?”
Esa pregunta nos llevará directamente a $-\log_2 p$.
¿Por qué el logaritmo (sin magia)?
Queremos una función $I(p)$ (“información de un evento con probabilidad $p$”) con dos propiedades razonables:
-
Eventos más raros deberían dar más información
Si $p$ baja, $I(p)$ debería subir. -
Independencia debería sumar
Si dos eventos independientes ocurren, la información total debería ser la suma: $$ I(pq)=I(p)+I(q) $$
La familia de funciones que cumple esto (bajo condiciones suaves) es:
$$ I(p)=k\cdot(-\log p) $$
Si elegimos base 2 y $k=1$, medimos en bits:
$$ I(p)=-\log_2 p $$
No es un “truco”: el log aparece porque convierte productos (probabilidades de independientes) en sumas (información acumulada).
Unidades: bits, nats, hartleys (base 10) y trits (base 3)
Hasta ahora elegimos $\log_2$ porque veníamos de preguntas sí/no (binarias). Pero matemáticamente puedes usar cualquier base $b>1$:
$$ I_b(p) = -\log_b p $$
Cambiar la base no cambia el concepto, solo cambia la unidad (es un factor constante):
$$ \log_b p = \frac{\log_a p}{\log_a b} \quad\Rightarrow\quad I_b(p)=\frac{I_a(p)}{\log_a b} $$
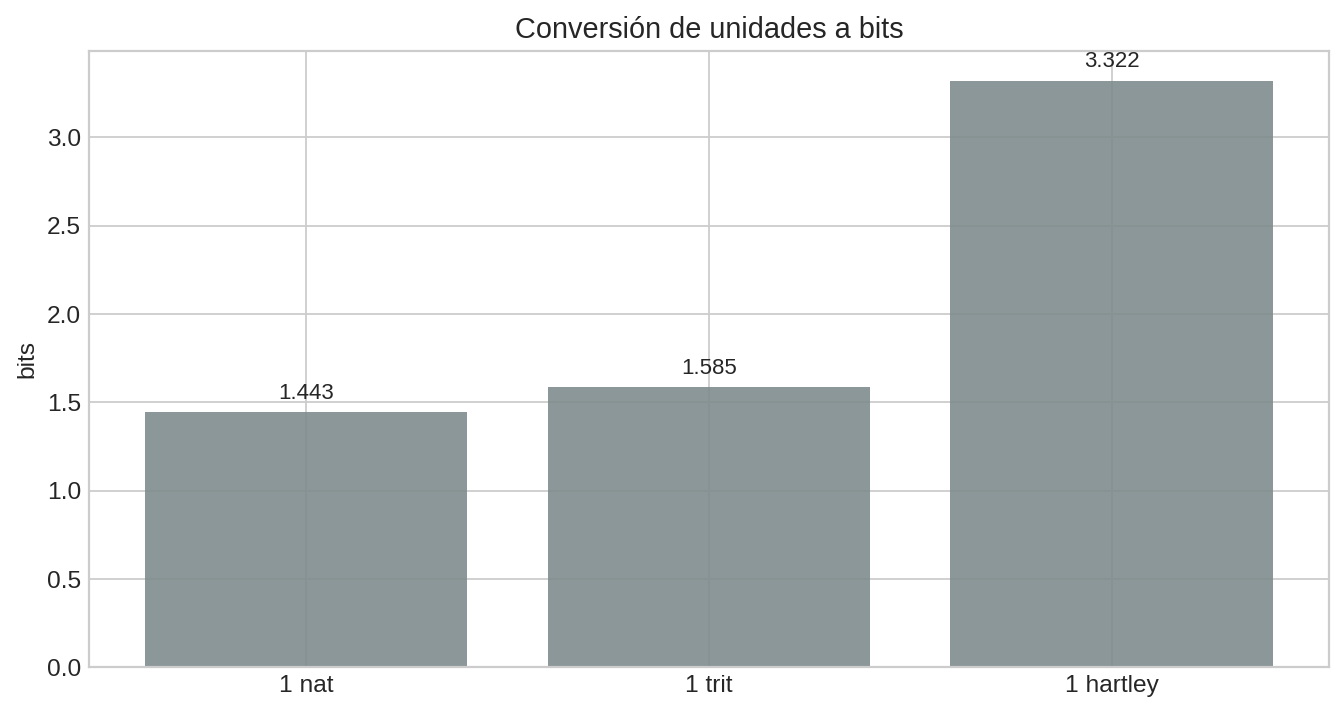
Una forma rápida de fijar la intuición: “nat”, “trit” y “hartley” son solo otras reglas para medir la misma sorpresa. Todo se puede convertir a bits multiplicando por una constante.
Base 2: bits
- Unidad: bit
- Interpretación operacional: “número de respuestas sí/no” (en promedio / idealmente).
Base $e$: nats
- Unidad: nat
- ¿Por qué aparece en ML? Porque el cálculo (derivadas) suele usar $\log$ natural, y entonces la pérdida típica es $-\log q$ en nats.
- Conversión: $1\ \text{nat} = \log_2(e) \approx 1.4427\ \text{bits}$.
Base 10: hartleys / bans / dits
- Unidad: hartley (también “ban” o “dit”, depende del texto)
- Interpretación: “dígitos decimales de sorpresa” (qué tan raro es en escala base 10).
- Conversión: $1\ \text{hartley} = \log_2(10) \approx 3.3219\ \text{bits}$.
Base 3: trits
- Unidad: trit
- Interpretación operacional: si tus preguntas fueran de 3 opciones (por ejemplo: “A/B/C”), la unidad natural sería $\log_3$.
- Conversión: $1\ \text{trit} = \log_2(3) \approx 1.5850\ \text{bits}$.
Casos límite (solo intuición): base $1$ y base $\infty$
Estos casos no se usan en práctica, pero ayudan a entender qué es “la unidad”.
Base $1$ (límite $b\to 1^+$)
La base del log debe ser $b>1$. En $b=1$ el logaritmo no está definido.
Pero el límite dice algo intuitivo:
- cuando $b\to 1^+$, $\ln b \to 0$
- y como $\log_b p = \frac{\ln p}{\ln b}$, el denominador se hace muy pequeño,
- entonces $I_b(p)=-\log_b p$ se vuelve enorme para cualquier evento no trivial ($p<1$).
Lectura:
Usar una base casi 1 define una “unidad” absurdamente pequeña, así que necesitas muchísimas unidades para expresar cualquier sorpresa.
Base $\infty$ (límite $b\to \infty$)
Si $b\to\infty$, entonces $\ln b\to\infty$ y:
$$ I_b(p) = -\log_b p = -\frac{\ln p}{\ln b} \to 0 \quad (p\in(0,1)) $$
Lectura:
Usar una base enorme define una “unidad” gigantesca (muchos bits por unidad), así que casi todo termina siendo “cerca de 0” en esas unidades.
La moral es: la base es solo una escala (como elegir metros vs kilómetros). Lo real es el contenido, y eso no cambia.
Ejemplo corto (misma idea, distintas unidades)
Si un evento tiene $p=1/8$:
- $I_2(p)= -\log_2(1/8)=3$ bits
- $I_e(p)= -\ln(1/8)=\ln(8)\approx 2.08$ nats
- $I_{10}(p)= -\log_{10}(1/8)\approx 0.903$ hartleys
Es la misma sorpresa, solo con “reglas” distintas.
¿Qué significa “un bit con 1 estado”?
Aquí hay una aclaración importante, porque el lenguaje puede confundir:
- Un bit no es “algo con 1 estado”.
- Un bit es una unidad de información asociada a una elección entre ~2 posibilidades.
Si una variable tiene 1 solo estado posible (determinista), entonces:
$$ \log_2(1)=0 $$
Eso significa:
Si no hay alternativas, no hay nada que aprender: 0 bits de información.
En nuestro juego:
- Si tu lista de candidatas tiene tamaño $N=1$, ya sabes la palabra.
- La entropía y la “cantidad de preguntas necesarias” colapsan a 0.
- Si una lista tiene $N=1024$ opciones equiprobables, ¿cuántos bits necesitas para identificar una opción?
- Ahora imagina que hay 1024 opciones, pero una de ellas tiene probabilidad 0.5 y las otras 1023 comparten el 0.5 restante.
- Intuitivamente: ¿es igual de “difícil” adivinar la opción en promedio?
- ¿Qué te dice esto sobre por qué “contar opciones” no basta?
Siguiente: Sorpresa y auto-información →
Volver: ← Índice