Entropía: sorpresa promedio (Shannon) e información faltante (Jaynes)
Ya tenemos una forma de medir la sorpresa de un resultado específico:
$$ I(x) = -\log_2 p(x\mid I) $$
Ahora queremos medir algo diferente:
Antes de ver el resultado, ¿cuánta sorpresa espero, en promedio?
Eso es entropía.
Definición (caso discreto)
Sea $X$ una variable aleatoria discreta con distribución $p(x\mid I)$.
La entropía de $X$ (en bits) es:
$$ H(X\mid I) ;=; \mathbb{E}[I(X)] ;=; \sum_x p(x\mid I),(-\log_2 p(x\mid I)) $$
Lectura:
Entropía = sorpresa promedio de los resultados, bajo tu modelo $p(\cdot\mid I)$.
Una aclaración crucial: “antes” vs “después” de observar
Esto evita otra confusión típica:
- Después de observar el resultado $X=x$, ya no hay incertidumbre sobre $X$: sabes qué ocurrió.
- La entropía $H(X\mid I)$ es una medida ex ante: describe cuánta incertidumbre/sorpresa esperas antes de mirar, cuando solo tienes $I$.
Por eso $H(X\mid I)$ se interpreta como:
- el número esperado (idealizado) de “preguntas binarias” necesarias para identificar $X$, o
- el costo promedio mínimo (en bits) para codificar los resultados de la fuente,
conectando directamente con Bits y preguntas y con Códigos y compresión.
Nota (por qué escribimos $H(X\mid I)$)
En el espíritu de Jaynes, la entropía no es una propiedad “mística” del universo: es una propiedad de tu distribución condicionada a lo que sabes $I$.
Ejemplo acumulativo (no-uniforme, con interpretación)
Retomemos el prior de 5 palabras:
- $p(w_1)=0.60$
- $p(w_2)=0.20$
- $p(w_3)=0.10$
- $p(w_4)=0.05$
- $p(w_5)=0.05$
Calculemos $H$ (aprox):
$$ H \approx 0.60\log_2\frac{1}{0.60} + 0.20\log_2\frac{1}{0.20} + 0.10\log_2\frac{1}{0.10} + 0.05\log_2\frac{1}{0.05} + 0.05\log_2\frac{1}{0.05} $$
No importa que el número salga “feo”: lo importante es la lectura:
- Si una opción domina (0.60), la entropía baja.
- Si las probabilidades se distribuyen más uniforme, la entropía sube.
Propiedad clave 1: máximo en la uniforme
Si $X$ tiene $N$ valores posibles y es uniforme:
$$ p(x)=\frac{1}{N} \quad\Rightarrow\quad H(X)=\log_2 N $$
Interpretación:
Si todo es igual de plausible, necesitas $\log_2 N$ bits en promedio para identificar el resultado.
Esto conecta perfectamente con “bits como preguntas” de la sección 2.
Caso más simple: dos resultados (entropía binaria)
Si solo hay dos resultados posibles (por ejemplo $X\in{0,1}$), basta un parámetro:
- $p = P(X=1)$
- $1-p = P(X=0)$
La entropía se vuelve una función de una sola variable:
$$ H(p) = -p\log_2(p) - (1-p)\log_2(1-p) $$
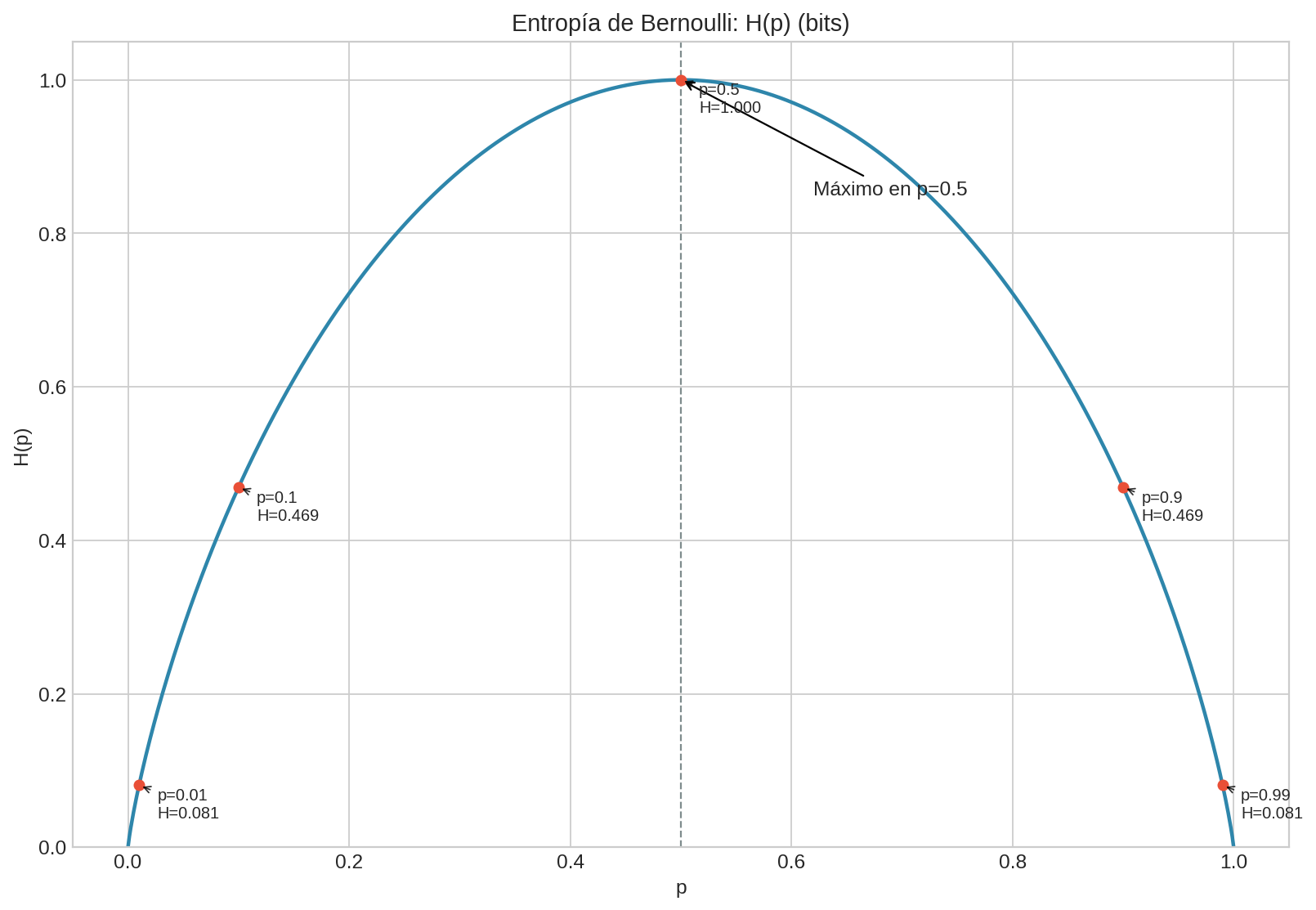
Lectura (esta gráfica vale oro para intuición):
- Cuando $p=0.5$, hay máxima incertidumbre (dos resultados igual de plausibles) y $H(p)=1$ bit.
- Cuando $p\to 0$ o $p\to 1$, casi “ya sabes” lo que va a pasar y $H(p)\to 0$.
- Los puntos anotados (p=0.9, 0.99, etc.) son “escenarios”: cuantifican cuánta incertidumbre queda con un prior muy sesgado.
Propiedad clave 2: concentración reduce entropía
Si tu distribución se vuelve más “picuda” (más masa en pocas opciones), la entropía baja.
Esto no es una metáfora: es una afirmación matemática sobre la forma de la suma $\sum p\log(1/p)$.
Lectura operacional:
Menos entropía = menos bits esperados para descubrir el valor (si haces buenas preguntas/estrategias).
¿De dónde sale la gráfica? (qué distribución se está variando)
Para que la gráfica signifique algo, hay que decir qué familia de distribuciones estamos moviendo.
Usamos una familia muy controlada y explícita: una mezcla entre
- una distribución uniforme $u$ sobre $N$ símbolos, y
- una distribución determinista (“one-hot”) que pone toda la masa en un solo símbolo.
Definimos, para $a\in[0,1]$:
$$ p(a) \,=\, (1-a)\,u \,+\, a\,\text{onehot} $$
Es decir: cuando $a=0$ tienes máxima incertidumbre (uniforme), y cuando $a\to 1$ casi todo el peso cae en una sola opción.
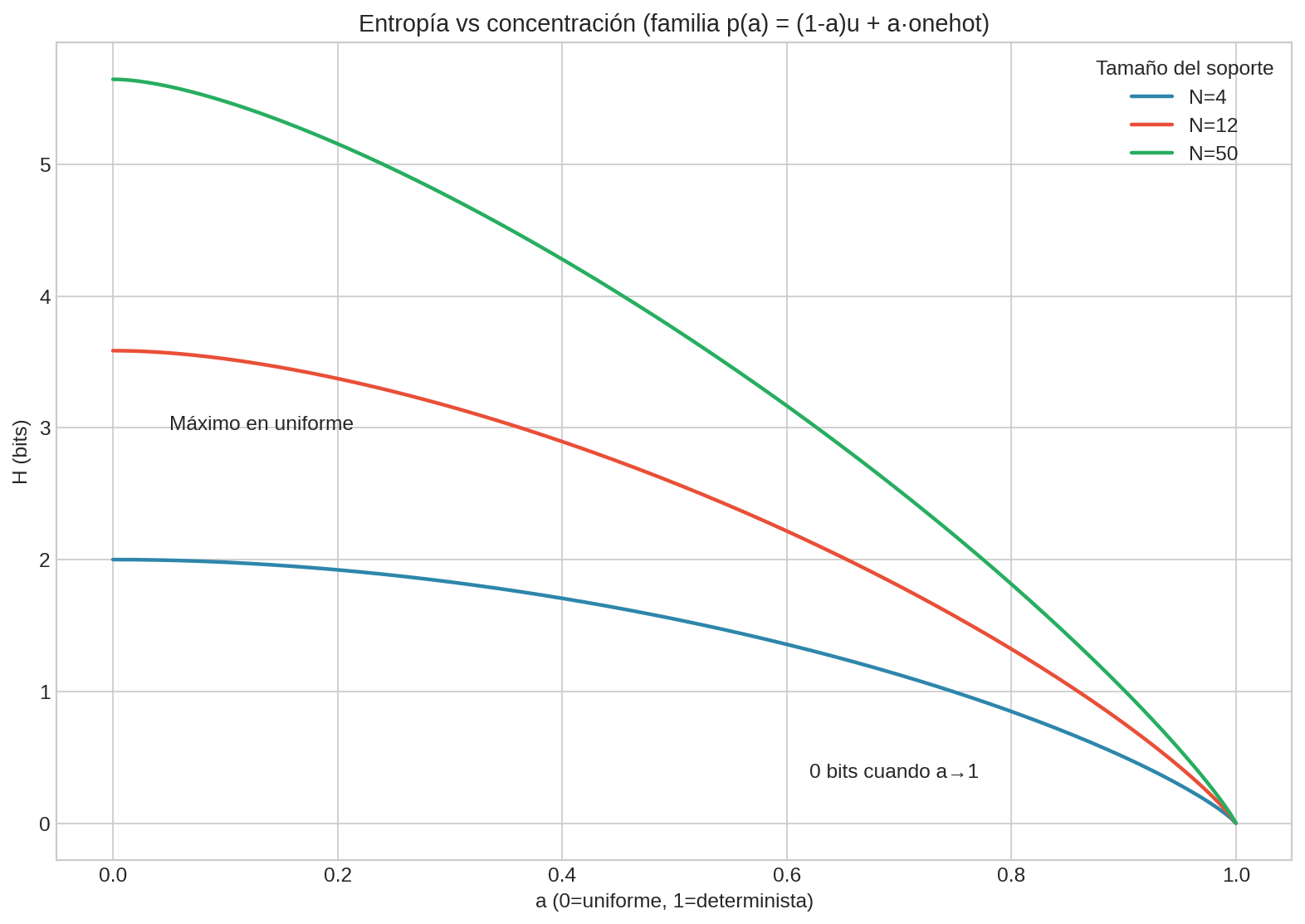
En todos los casos se ve lo mismo: al concentrar el prior, la entropía cae. La escala cambia con $N$ porque el máximo posible en uniforme es $H(u)=\log_2 N$.
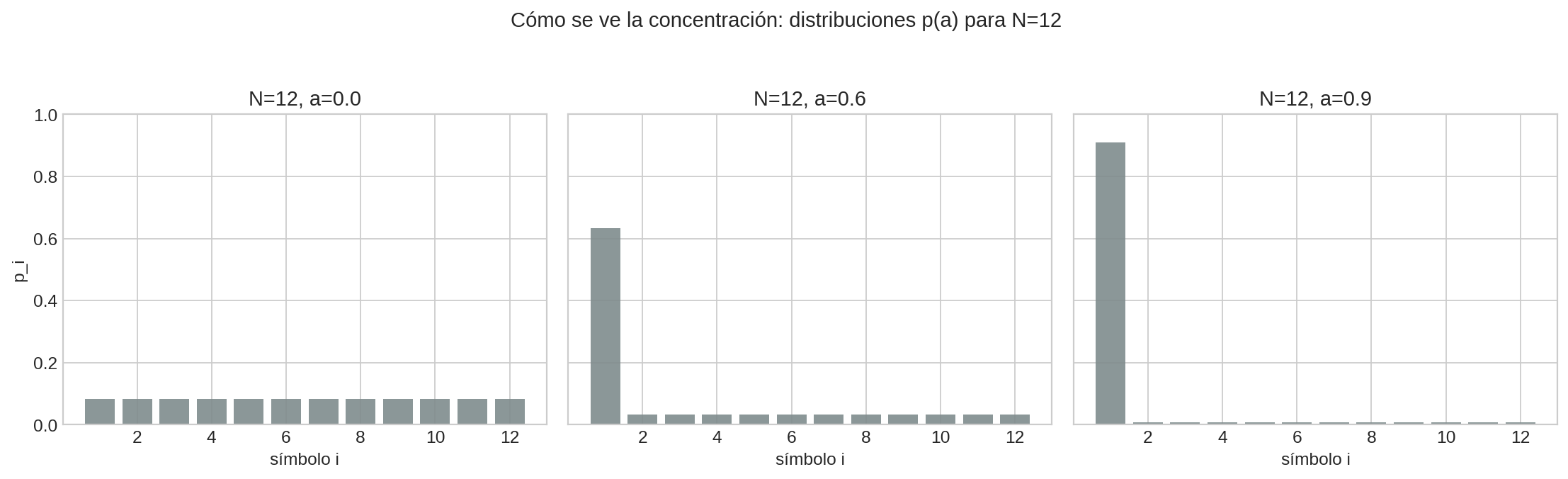
Estas barras muestran literalmente qué significa “concentrar”: para $a$ grande, una barra domina y las demás son pequeñas.
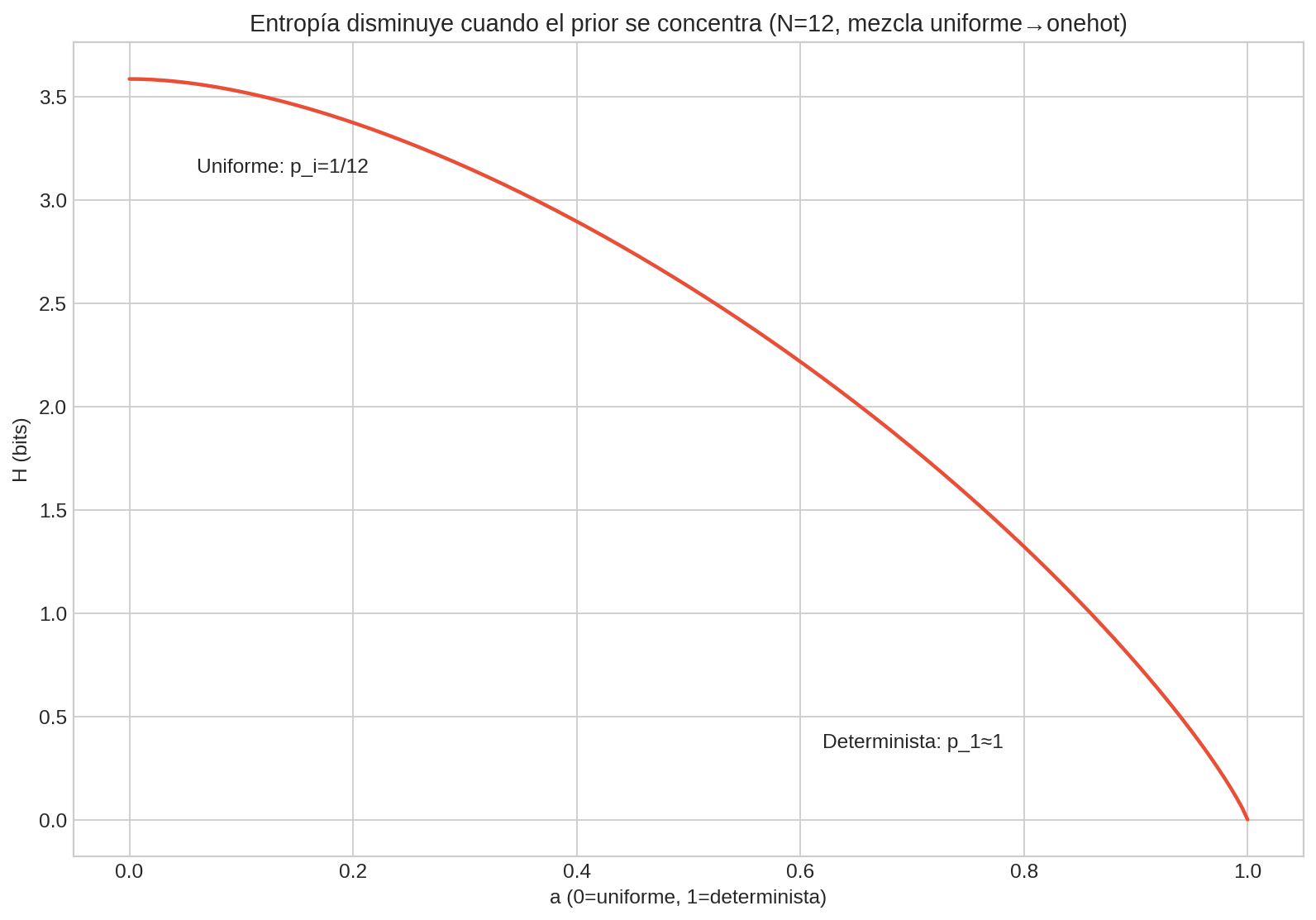
La lectura “operativa” para Wordle/password: si tu prior está concentrado, en promedio necesitas menos bits/preguntas para identificar la respuesta; si es casi uniforme, necesitas más.
La perspectiva de Jaynes: “entropía = información faltante”
En el enfoque de E.T. Jaynes (máxima entropía), la entropía se interpreta como:
cuánta información te falta para especificar el estado, dado lo que ya sabes.
Esto es útil pedagógicamente porque te obliga a decir:
- ¿Cuál es el espacio de posibilidades?
- ¿Qué restricciones (información) ya tienes?
- ¿Qué distribución estás justificando?
Entropía de Jaynes (en el caso discreto)
En este módulo, cuando digamos “entropía de Jaynes” nos referiremos a:
- Entropía escrita condicionada al contexto $I$: $H(X\mid I)$.
- (Más adelante) la idea de elegir $p$ maximizando $H$ sujeto a restricciones — “no inventar información”.
Hoy solo necesitamos (1) para el capstone; (2) lo mencionaremos como “lo que sigue”.
(Lo que sigue) Máxima entropía en una frase
Jaynes propone un principio para elegir $p(x\mid I)$ cuando solo conoces ciertas restricciones:
Elige la distribución que maximiza $H(X\mid I)$ sujeta a las restricciones, para no introducir suposiciones extra.
En este módulo no vamos a desarrollar todo el método general, pero sí vamos a usar su filosofía (y ver un ejemplo): siempre declarar qué sabes y qué estás asumiendo.
Ejemplo práctico (paso a paso): derivar máxima entropía con una restricción
La frase “maximiza entropía sujeto a restricciones” suena abstracta… hasta que haces uno.
El problema (bien planteado)
Imagina que $X$ solo puede tomar tres valores:
$$ X \in {0,1,2} $$
Piensa en esto como “bajo / medio / alto”, o “0 errores / 1 error / 2 errores”, etc.
Tú no sabes cuál ocurrirá, pero sí sabes algo agregado:
- Restricción 1 (normalización): $p_0 + p_1 + p_2 = 1$
- Restricción 2 (promedio conocido): $\mathbb{E}[X]=\mu$, es decir
$$ 0\cdot p_0 + 1\cdot p_1 + 2\cdot p_2 = \mu $$
La pregunta “Jaynes” es:
Entre todas las distribuciones $(p_0,p_1,p_2)$ que cumplen esas dos restricciones, ¿cuál tiene máxima entropía?
Paso 1: escribir qué maximizas (entropía)
En bits:
$$ H(p) = -\sum_{i=0}^2 p_i \log_2 p_i $$
Truco técnico: es más cómodo derivar con log natural. Como $\log_2 p = \frac{\ln p}{\ln 2}$, maximizar $H$ en bits es equivalente a maximizar
$$ -\sum_{i=0}^2 p_i \ln p_i $$
(solo cambia por el factor constante $1/\ln 2$).
Paso 2: armar el Lagrangiano con las restricciones
$$ \mathcal{L}(p,\alpha,\beta)
-\sum_{i=0}^2 p_i \ln p_i
- \alpha\left(\sum_{i=0}^2 p_i - 1\right)
- \beta\left(\sum_{i=0}^2 i,p_i - \mu\right) $$
donde $\alpha$ y $\beta$ son multiplicadores de Lagrange.
Paso 3: derivar y resolver la forma de $p_i$
Derivamos respecto a cada $p_i$ y lo igualamos a cero:
$$ \frac{\partial \mathcal{L}}{\partial p_i}
-(\ln p_i + 1) + \alpha + \beta i =0 $$
Reacomodamos:
$$ \ln p_i = (\alpha-1) + \beta i $$
Exponentiamos:
$$ p_i = \exp(\alpha-1),\exp(\beta i) $$
Esto ya te deja una idea importante:
Con restricción de “promedio”, la máxima entropía cae en una familia exponencial.
Para que se vea como “decaimiento”, define $\lambda=-\beta$ y una constante de normalización $Z$:
$$ p_i = \frac{e^{-\lambda i}}{Z} \quad\text{con}\quad Z=\sum_{j=0}^2 e^{-\lambda j}= 1 + e^{-\lambda} + e^{-2\lambda} $$
En concreto:
$$ p_0=\frac{1}{Z},\quad p_1=\frac{e^{-\lambda}}{Z},\quad p_2=\frac{e^{-2\lambda}}{Z} $$
Paso 4: usar el promedio para fijar $\lambda$
La restricción $\mathbb{E}[X]=\mu$ se vuelve una ecuación de 1 variable:
$$ \mu = 0\cdot p_0 + 1\cdot p_1 + 2\cdot p_2 = \frac{e^{-\lambda} + 2e^{-2\lambda}}{1+e^{-\lambda}+e^{-2\lambda}} $$
Esa ecuación determina $\lambda$.
Caso base (sin sesgo extra): $\mu=1$
Si $\mu=1$, la solución es $\lambda=0$. Entonces $e^{-\lambda}=1$ y
$$ p_0=p_1=p_2=\frac{1}{3} $$
Tiene sentido: con solo “el promedio es 1” y un soporte simétrico ${0,1,2}$, lo menos comprometido es la uniforme.
Leve modificación: cambia el promedio a $\mu=1.2$
Ahora aprendes un poquito más: el promedio no es 1 sino $\mu=1.2$.
Sin re-derivar nada, la forma sigue siendo $p_i \propto e^{-\lambda i}$; solo cambia $\lambda$ para cumplir el nuevo promedio. En este caso:
- $\lambda \approx -0.305$
- $(p_0,p_1,p_2)\approx(0.238,;0.323,;0.438)$
Lectura: como $\mu$ sube, la distribución de máxima entropía “se inclina” hacia $2$, pero de la forma más suave posible compatible con lo que sabes.
Analogías comunes (y por qué son incompletas)
“Entropía = desorden”
Esto puede ayudar como intuición en física, pero aquí puede confundir.
- Qué captura bien: cuando hay muchas configuraciones plausibles, “hay más entropía”.
- Qué NO captura bien: en información, entropía no es “caos” sino incertidumbre cuantificada bajo un modelo.
“Entropía = aleatoriedad”
También es peligroso si se toma literal.
- Un proceso puede ser determinista para el mundo, pero si tú no lo conoces, tu $p(\cdot\mid I)$ puede tener alta entropía.
- Por eso Jaynes insiste en separar “estado del mundo” vs “estado de conocimiento”.
Entropía y Wordle: la idea de “ganancia esperada”
Antes de jugar un guess $g$, tienes una distribución sobre posibles palabras $p(x\mid I)$.
Después del feedback $F$, tu distribución cambia a $p(x\mid F,I)$.
La cantidad de incertidumbre restante (en bits) después de ver $F$ es:
$$ H(X\mid F, I) $$
Como $F$ es aleatorio (depende del secreto), la incertidumbre restante esperada es:
$$ \mathbb{E}_{F}[H(X\mid F,I)] $$
Entonces la ganancia esperada de información del guess $g$ es:
$$ \text{IG}(g) ;=; H(X\mid I) - \mathbb{E}_{F}[H(X\mid F,I)] $$
Esta fórmula será el corazón del solver del capstone.
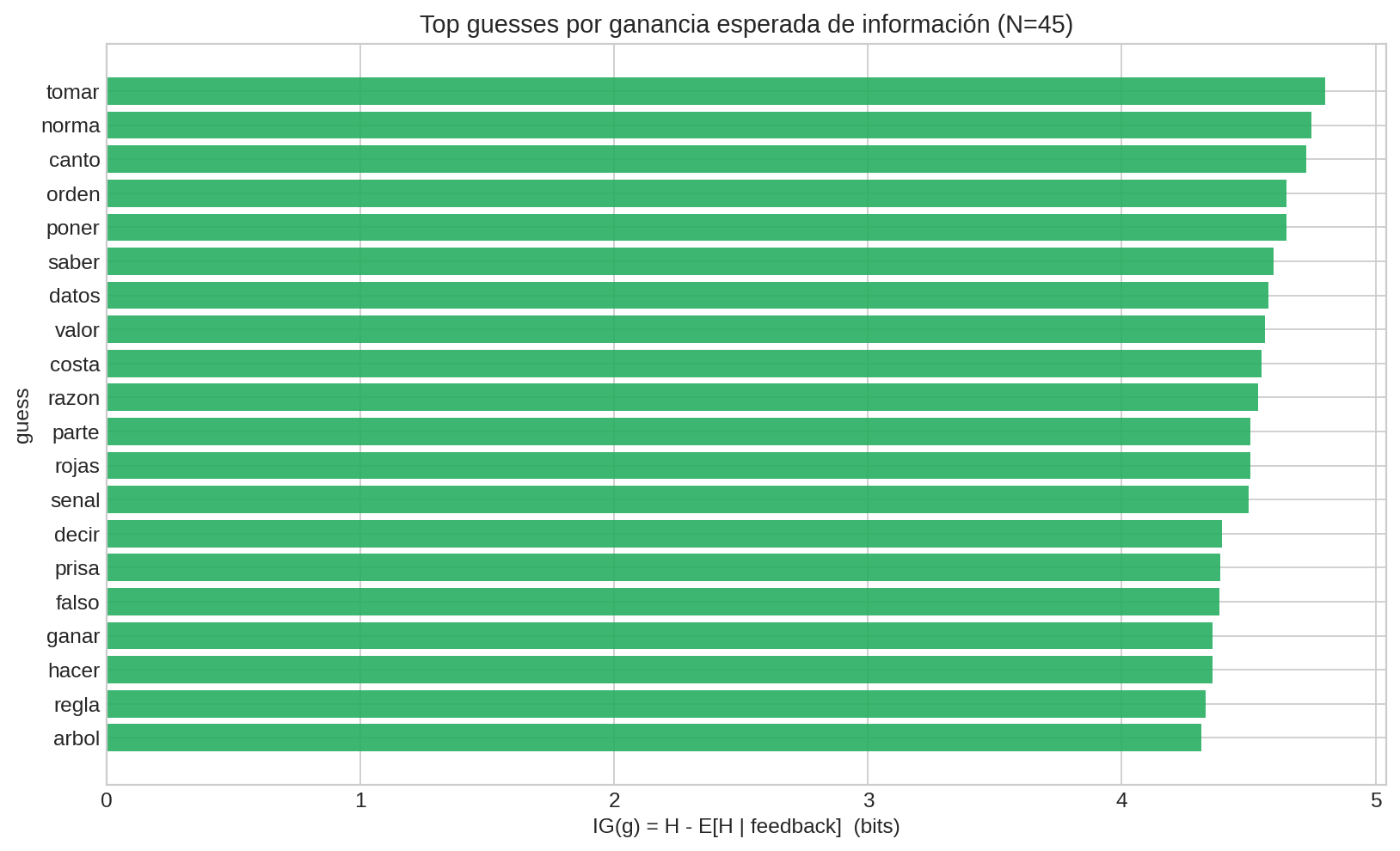
Ejemplo (a escala pequeña): guesses que “parten” mejor el espacio de candidatas maximizando $\text{IG}(g)$. La lista exacta depende del lexicón y del prior.
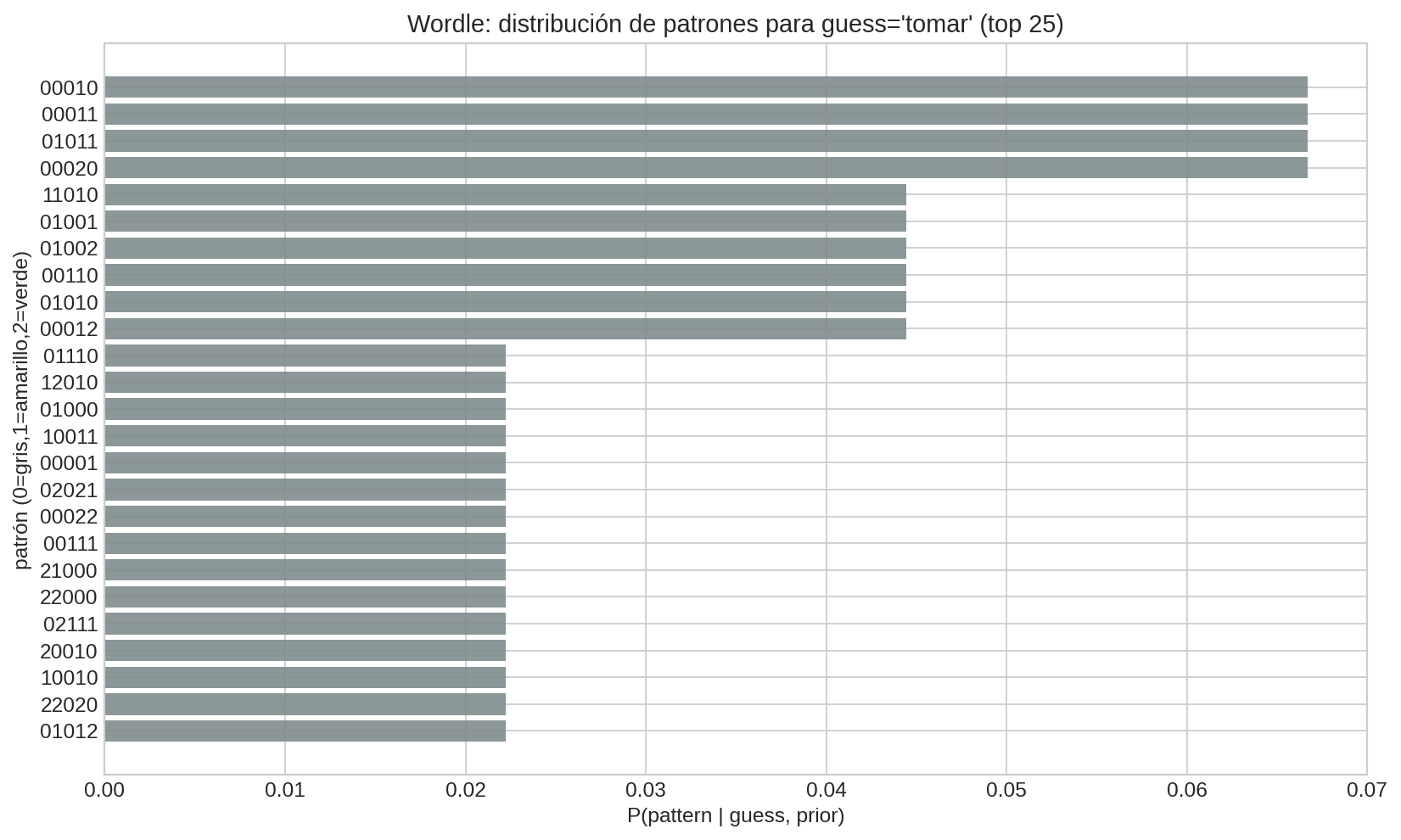
Otra vista complementaria: un buen guess induce muchos patrones posibles con masas no demasiado concentradas. Si casi toda la masa cae en 1–2 patrones, el guess “dice poco” en promedio.
Considera dos priors sobre 4 palabras:
- Prior A: $[0.25, 0.25, 0.25, 0.25]$
- Prior B: $[0.70, 0.10, 0.10, 0.10]$
- Calcula $H_A$ y $H_B$.
- Interpreta: ¿en cuál caso te conviene más “apostar” por la palabra más probable sin preguntar nada?
- Relación con passwords: ¿qué prior se parece más a la realidad humana al escoger contraseñas?
Siguiente: Códigos y compresión →
Volver: ← Índice