Códigos y compresión: pagar menos por lo frecuente
Ya tenemos una medida de “incertidumbre” en bits: $H(X\mid I)$.
Ahora viene una pregunta natural:
Si $H$ es “bits esperados”, ¿eso se puede convertir en un método concreto para codificar mensajes?
Sí. Y este puente es una de las razones por las que teoría de la información es tan central.
Problema: enviar símbolos con un alfabeto binario
Supón que una fuente emite símbolos (por ejemplo, palabras o tipos de eventos) con distribución $p(x\mid I)$.
Queremos asignar a cada símbolo $x$ un código binario $c(x)$ (una cadena de 0/1) para transmitirlo.
Restricción esencial: decodificación sin ambigüedad
Una restricción práctica muy usada es código prefijo:
Ningún código es prefijo de otro.
Eso permite decodificar leyendo bits de izquierda a derecha sin separadores.
El principio: lo frecuente debe ser corto
Si un símbolo aparece mucho, conviene darle un código corto.
Esto no es solo “intuición”: si no lo haces, tu longitud promedio se dispara.
Definimos la longitud del código:
$$ \ell(x) = |c(x)| $$
Y la longitud promedio:
$$ L = \mathbb{E}[\ell(X)] = \sum_x p(x\mid I),\ell(x) $$
La pregunta es: ¿cuál es el menor $L$ que puedo lograr?
La conexión con entropía (idea central)
Sin entrar en una prueba completa, el resultado (Shannon) dice:
Para una fuente discreta, la longitud promedio óptima está acotada por la entropía:
$$ H(X\mid I) \le L < H(X\mid I) + 1 $$
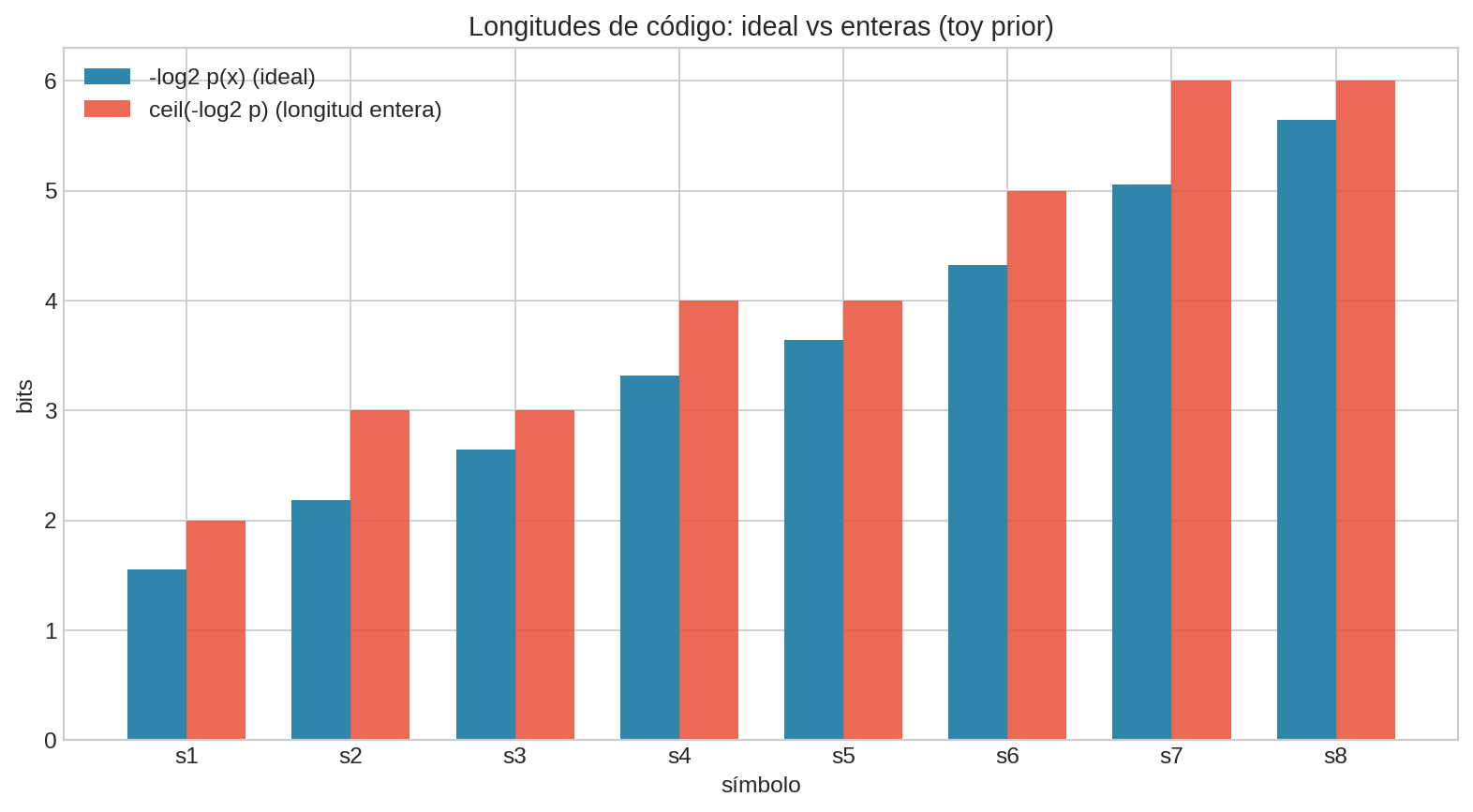
Visualización concreta de la idea: longitudes ideales se parecen a $-\log_2 p(x)$, pero los códigos reales suelen usar longitudes enteras. Aun así, el costo promedio puede acercarse al límite impuesto por $H(X\mid I)$.
Lectura:
- No puedes comprimir, en promedio, por debajo de $H$ bits por símbolo (sin perder información).
- Puedes acercarte a $H$ con códigos bien diseñados (por ejemplo, Huffman).
Esto hace que $H$ sea más que una “fórmula bonita”: es un límite de compresión.
Códigos prefijo como árboles (la idea mecánica)
Un código prefijo binario se puede ver como un árbol binario:
- Cada símbolo $x$ es una hoja.
- Ir a la izquierda agrega un bit (por ejemplo,
0). - Ir a la derecha agrega un bit (por ejemplo,
1). - El código $c(x)$ es el camino desde la raíz a la hoja.
Esto explica por qué “prefijo” importa:
Si ningún símbolo es prefijo de otro, entonces ninguna hoja es ancestro de otra hoja.
Eso hace que decodificar sea “leer bits hasta caer en una hoja”.
Una consecuencia útil (solo como intuición; no la probaremos aquí) es la desigualdad de Kraft: si un conjunto de longitudes ${\ell(x)}$ viene de un código prefijo, entonces
$$ \sum_x 2^{-\ell(x)} \le 1 $$
Esto te recuerda que “no puedes darle códigos cortísimos a todos”: hay un presupuesto de longitudes.
Mini-ejemplo visual: del árbol al código (sin Huffman todavía)
Imagina este árbol (izquierda=0, derecha=1):
(raíz)
/ \
0/ \1
/ \
(*) (*)
/ \ / \
00 01 10 11
a b c d
Entonces los códigos son literalmente los caminos:
- $c(a)=00$, $c(b)=01$, $c©=10$, $c(d)=11$
Y se ve el punto del “prefijo”: ninguno de esos strings es prefijo de otro, porque todas las hojas están al mismo nivel.
¿Cómo se construye el mejor código? Huffman (paso a paso)
Huffman es un algoritmo greedy para construir un código prefijo que minimiza la longitud promedio:
$$ L=\sum_x p(x),\ell(x) $$
Intuición antes del algoritmo
Si dos símbolos son muy raros, “no pasa mucho” si terminan con códigos largos.
La idea de Huffman es:
Junta los dos símbolos menos probables para que compartan un prefijo largo, y repite.
Pseudocódigo (versión clara)
Entrada: símbolos S = {x1,...,xk} con pesos w(x) (probabilidades o frecuencias)
Salida: árbol binario (y por tanto un código prefijo)
1) Crea un nodo-hoja para cada símbolo x con peso w(x).
2) Mete todos los nodos en una cola de prioridad (min-heap) por peso.
3) Mientras haya más de un nodo en el heap:
a) u = extrae_min(heap) # el peso más chico
b) v = extrae_min(heap) # segundo más chico
c) crea un nodo padre p con hijos (u, v) y peso w(p)=w(u)+w(v)
d) inserta p al heap
4) El nodo que queda es la raíz del árbol.
5) Asigna bits a las ramas (por ejemplo: izquierda=0, derecha=1).
6) El código de un símbolo es el camino raíz→hoja.
Detalles prácticos:
- Si usas frecuencias en un dataset, puedes dividir entre el total y obtienes probabilidades; el árbol de Huffman es el mismo (solo escala).
- Si hay empates, puedes romperlos arbitrariamente: pueden cambiar los bits exactos, pero la longitud promedio óptima no empeora.
¿Qué es exactamente el “heap” aquí? (sin magia)
En Huffman necesitas repetir muchas veces: “dame los dos pesos más chicos”.
La estructura estándar para eso es una cola de prioridad implementada con un min-heap.
La idea de cola de prioridad
Piensa en un contenedor de elementos con clave peso que soporta:
insertar(elemento)extrae_min()(sacar el elemento con menor peso)
La idea de heap (min-heap)
Un min-heap es un árbol binario “casi completo” (se llena por niveles) con la regla:
El peso en cada nodo es $\le$ que el peso de sus hijos.
Por eso el mínimo siempre está en la raíz.
En implementación real suele guardarse en un arreglo (sin punteros) y mantener la regla con dos operaciones:
- sift-up (al insertar): sube el elemento mientras sea más pequeño que su padre.
- sift-down (al extraer mínimo): bajas el elemento que pusiste en la raíz mientras sea más grande que alguno de sus hijos.
Cada sift recorre como mucho la altura del árbol, que es $O(\log k)$.
Nota pedagógica
En el ejemplo, para entender, voy a escribir el heap como una lista ordenada por peso.
Eso NO es el layout interno del heap (que no está ordenado globalmente), pero sí refleja correctamente qué elementos podrían salir por extrae_min().
Ejemplo completo de Huffman (con números y cálculo de $L$)
Supón una fuente con 6 símbolos:
| símbolo | $p(x)$ |
|---|---|
| $a$ | 0.30 |
| $b$ | 0.25 |
| $c$ | 0.20 |
| $d$ | 0.15 |
| $e$ | 0.06 |
| $f$ | 0.04 |
Paso 0: iniciar con hojas
Cada símbolo es una hoja con su peso.
Heap inicial (visto como lista ordenada por peso):
$$ [(f,0.04),(e,0.06),(d,0.15),(c,0.20),(b,0.25),(a,0.30)] $$
Paso 1: juntar los dos más raros
Los dos más chicos son $f(0.04)$ y $e(0.06)$:
- Merge: $(f,e)\rightarrow n_1$ con peso $0.10$
Ahora los “nodos” son: $a(0.30)$, $b(0.25)$, $c(0.20)$, $d(0.15)$, $n_1(0.10)$.
Heap después del merge:
$$ [(n_1,0.10),(d,0.15),(c,0.20),(b,0.25),(a,0.30)] $$
Paso 2: repetir
Los dos más chicos ahora son $n_1(0.10)$ y $d(0.15)$:
- Merge: $(n_1,d)\rightarrow n_2$ con peso $0.25$
Ahora tienes: $a(0.30)$, $b(0.25)$, $c(0.20)$, $n_2(0.25)$.
Heap después del merge:
$$ [(c,0.20),(b,0.25),(n_2,0.25),(a,0.30)] $$
Paso 3: repetir
Los dos más chicos: $c(0.20)$ y uno de los $0.25$ (por ejemplo $b(0.25)$):
- Merge: $(c,b)\rightarrow n_3$ con peso $0.45$
Quedan: $a(0.30)$, $n_2(0.25)$, $n_3(0.45)$.
Heap después del merge:
$$ [(n_2,0.25),(a,0.30),(n_3,0.45)] $$
Paso 4: repetir
Los dos más chicos: $n_2(0.25)$ y $a(0.30)$:
- Merge: $(n_2,a)\rightarrow n_4$ con peso $0.55$
Quedan: $n_3(0.45)$, $n_4(0.55)$.
Heap después del merge:
$$ [(n_3,0.45),(n_4,0.55)] $$
Paso 5: merge final (raíz)
- Merge: $(n_3,n_4)\rightarrow \text{root}$ con peso $1.00$
Construir el árbol (lo que realmente produjo el algoritmo)
Si expandes “quién se juntó con quién”, el árbol conceptual queda así:
root(1.00)
/ \
n3(0.45) n4(0.55)
/ \ / \
c(.20) b(.25) n2(.25) a(.30)
/ \
n1(.10) d(.15)
/ \
f(.04) e(.06)
Esto es literalmente Huffman: cada merge crea un padre cuyo peso es la suma de sus hijos.
Asignar bits y leer códigos (no solo longitudes)
Asigna (por ejemplo) 0 a la rama izquierda y 1 a la derecha.
Con esa convención, un conjunto posible de códigos es:
- $c©=00$
- $c(b)=01$
- $c(a)=11$
- $c(d)=101$
- $c(f)=1000$
- $c(e)=1001$
Dos cosas a checar:
- Prefijo: ninguno de esos códigos es prefijo de otro.
- Longitudes: las longitudes quedan:
- $a$: longitud 2
- $b$: longitud 2
- $c$: longitud 2
- $d$: longitud 3
- $e$: longitud 4
- $f$: longitud 4
Nota: si rompes empates distinto o cambias “izquierda/derecha”, cambian los bits exactos, pero el costo promedio óptimo (y estas longitudes) no empeoran.
Calcular el costo promedio $L$
$$ \begin{aligned} L &= 0.30\cdot 2 + 0.25\cdot 2 + 0.20\cdot 2 + 0.15\cdot 3 + 0.06\cdot 4 + 0.04\cdot 4 \ &= 2.35 \text{ bits/símbolo} \end{aligned} $$
Comparar con la entropía $H(X)$
$$ H(X)= -\sum_x p(x)\log_2 p(x) \approx 2.325 \text{ bits} $$
Aquí se ve el mensaje de Shannon en acción:
- $H(X)\approx 2.325$ es el “límite ideal”.
- Huffman paga $L=2.35$, o sea una redundancia de $L-H \approx 0.025$ bits por símbolo.
¿Por qué Huffman “tiene sentido”? (intuición sin prueba dura)
Dos ideas que explican por qué el greedy funciona:
- En un árbol prefijo, los símbolos con códigos más largos viven “más profundo”.
- En un óptimo, los dos símbolos menos probables deben terminar como “hermanos” al fondo (comparten el prefijo más largo).
Si no fuera así, podrías intercambiar hojas y bajar el costo promedio.
Huffman formaliza esa intuición juntándolos primero, y repitiendo el mismo argumento recursivamente.
Complejidad (qué tan caro es construirlo y usarlo)
Sea $k$ el número de símbolos distintos.
- Construcción con min-heap:
- Haces $k-1$ merges; cada merge hace 2 extracciones y 1 inserción en el heap.
$$ O((k-1)\log k)=O(k\log k) $$
- Codificar mensajes: una vez construido el diccionario $x\mapsto c(x)$, codificar es $O(1)$ por símbolo (lookup).
- Decodificar: es $O(\text{número de bits})$ recorriendo el árbol hasta hojas.
Comentario honesto: Huffman es óptimo para “códigos de símbolos” con longitudes enteras. Si quieres acercarte aún más a $H$ (como “longitudes fraccionarias”), existen técnicas como codificación aritmética; la idea conceptual es la misma: pagar $\approx -\log_2 p(x)$.
Analogía (útil pero incompleta): “precio por palabra”
Analogía:
Cada bit cuesta dinero/tiempo. Si algo ocurre mucho, quieres pagarlo barato.
- Qué captura bien: el criterio de optimalidad promedio.
- Qué es incompleto: no dice nada sobre cómo construir el árbol, ni sobre errores, ni sobre canales con ruido.
El examen cubre las primeras tres clases del curso:
- Clase 1: Introducción e Historia de la IA
- Clase 2: Agents y Environments
- Clase 3: Lógica
El examen incluirá todo lo que hemos visto sobre cómo evalúo, los temas de historia de la IA, agentes y ambientes, y lógica proposicional. Tienes símbolos ${a,b,c,d,e,f}$ con:
- $p(a)=0.30$, $p(b)=0.25$, $p©=0.20$, $p(d)=0.15$, $p(e)=0.06$, $p(f)=0.04$
- Ejecuta Huffman “a mano”: en cada paso junta los dos pesos más chicos y anota el nuevo peso.
- Dibuja el árbol (aunque sea en ASCII) o al menos deduce las longitudes $\ell(x)$.
- Calcula $L=\sum_x p(x)\ell(x)$.
- Calcula $H(X)=-\sum_x p(x)\log_2 p(x)$.
- Reporta la redundancia $L-H$ (en bits/símbolo) e interpreta qué significa.
Siguiente: Cross-entropy y KL →
Volver: ← Índice