Cross-entropy y KL: el costo de apostar mal (puente a ML)
Hasta ahora usamos $p(x\mid I)$ como “la distribución” de una fuente.
En ML suele pasar algo distinto:
- El mundo “sigue” alguna distribución $p$ (desconocida).
- Tu modelo produce otra distribución $q$ (tu apuesta).
La pregunta práctica es:
Si el mundo genera resultados según $p$, ¿cuánto “pagas” en promedio si apuestas con $q$?
Ese pago promedio es cross-entropy.
De $-\log$ a log-loss
Si el mundo revela un resultado $x$, y tu modelo asigna probabilidad $q(x)$, un costo natural es:
$$ \text{loss}(x) = -\log_2 q(x) $$
Lectura:
- Si $q(x)$ es grande, pagas poco.
- Si $q(x)$ es pequeño, pagas mucho.
- Si $q(x)=0$, tu costo es infinito (tu modelo declaró “imposible” algo que ocurrió).
En clasificación, esto es exactamente log-loss (con log natural normalmente).
Cross-entropy: costo promedio bajo $p$
La cross-entropy de $p$ respecto a $q$ es:
$$ H(p,q) ;=; \mathbb{E}_{x\sim p}\left[-\log_2 q(x)\right] ;=; \sum_x p(x),(-\log_2 q(x)) $$
Interpretación:
Si la realidad sigue $p$, la cross-entropy mide cuántos bits en promedio necesitas si codificas usando un código “diseñado” para $q$.
Esto conecta con la sección de compresión:
- diseñar un código óptimo para $q$ es como asignar longitudes $\ell(x)\approx -\log_2 q(x)$,
- y el costo promedio real depende de cómo $p$ pesa los símbolos.
KL divergence: “penalización extra” por modelo equivocado
La divergencia de Kullback–Leibler (KL) es:
$$ D_{KL}(p|q) ;=; \mathbb{E}_{x\sim p}\left[\log_2\frac{p(x)}{q(x)}\right] ;=; \sum_x p(x),\log_2\frac{p(x)}{q(x)} $$
Propiedad importante:
$$ D_{KL}(p|q) \ge 0 \quad\text{y}\quad D_{KL}(p|q)=0 \iff p=q $$
Relación clave
Hay una identidad fundamental:
$$ H(p,q) = H(p) + D_{KL}(p|q) $$
Lectura:
- $H(p)$: bits inevitables (si supieras la distribución real).
- $D_{KL}(p|q)$: bits extra por usar el modelo equivocado.
Esto es una de las mejores frases-UX de todo el tema:
La KL es el “regret” de información por apostar con $q$ cuando el mundo es $p$.
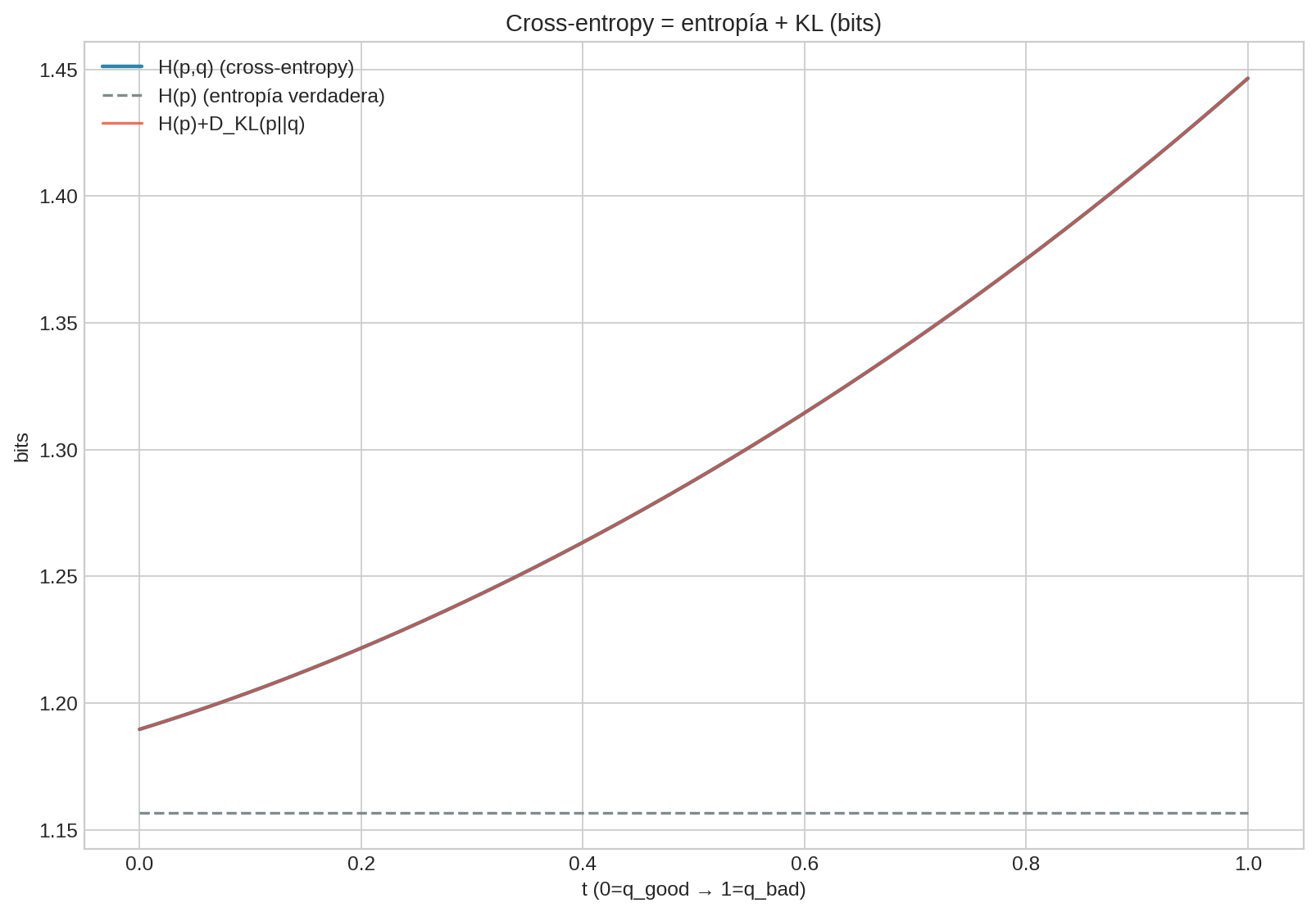
La gráfica ilustra la identidad $H(p,q)=H(p)+D_{KL}(p|q)$: cuando $q$ se aleja de $p$, crece la penalización KL y, con ella, la cross-entropy.
Ejemplo pequeño (2–3 clases, con números)
Supón un problema con 3 clases ${A,B,C}$.
La realidad (o dataset) tiene:
$$ p = (0.70, 0.20, 0.10) $$
Modelo 1 (mejor):
$$ q_1 = (0.60, 0.25, 0.15) $$
Modelo 2 (peor):
$$ q_2 = (0.40, 0.30, 0.30) $$
La cross-entropy es:
$$ H(p,q)=0.70(-\log_2 q(A)) + 0.20(-\log_2 q(B)) + 0.10(-\log_2 q©) $$
Y será menor para $q_1$ que para $q_2$.
En el laboratorio vamos a graficar estas cantidades para ver cómo crece el costo cuando el modelo se equivoca.
Conexión directa con nuestro hilo conductor (wordle/password)
Password guessing (sin feedback)
Si el mundo elige contraseñas con $p$ y tú las intentas en orden de $q$ (tu prior), entonces:
- tu desempeño depende de qué tan cerca está $q$ de $p$,
- y “estar cerca” se puede medir con KL / cross-entropy.
Wordle (con feedback)
Aquí $q$ no es solo una “apuesta”: después de cada feedback, actualizas tu distribución. Eso reduce entropía y, por tanto, reduce el “espacio de búsqueda”.
En el capstone vamos a usar:
- $H(X\mid I)$ para medir incertidumbre actual,
- $\text{IG}(g)$ para elegir el guess con mayor reducción esperada.
Tienes $p=(0.5,0.3,0.2)$ y dos modelos:
- $q_1=(0.5,0.3,0.2)$
- $q_2=(0.8,0.1,0.1)$
- Calcula $H(p)$.
- Calcula $H(p,q_1)$ y $H(p,q_2)$.
- Calcula $D_{KL}(p|q_2)$.
- Verifica la identidad $H(p,q)=H(p)+D_{KL}(p|q)$ en el caso $q_2$.
Siguiente: Información mutua y ML →
Volver: ← Índice