Paisaje de optimización
Imagina la función objetivo como un terreno montañoso. Optimizar es buscar el punto más bajo (minimización) o más alto (maximización) de ese terreno. La “forma” de ese terreno determina qué tan fácil o difícil es encontrar la solución.
Mínimos y máximos
Un punto $x^{∗}$ es un mínimo local si $f(x^{∗}) \leq f(x)$ para todo $x$ en una vecindad de $x^{∗}$.
Un punto $x^{∗}$ es un mínimo global si $f(x^{∗}) \leq f(x)$ para todo $x$ en el dominio.
Condición necesaria (para funciones diferenciables): en un mínimo o máximo, el gradiente se anula:
$$\nabla f(x^{∗}) = 0$$
Pero cuidado: $\nabla f = 0$ es necesario, no suficiente. Puede ser un mínimo, un máximo, o un punto silla.
Local vs global
La diferencia entre mínimos locales y globales es crucial en la práctica:
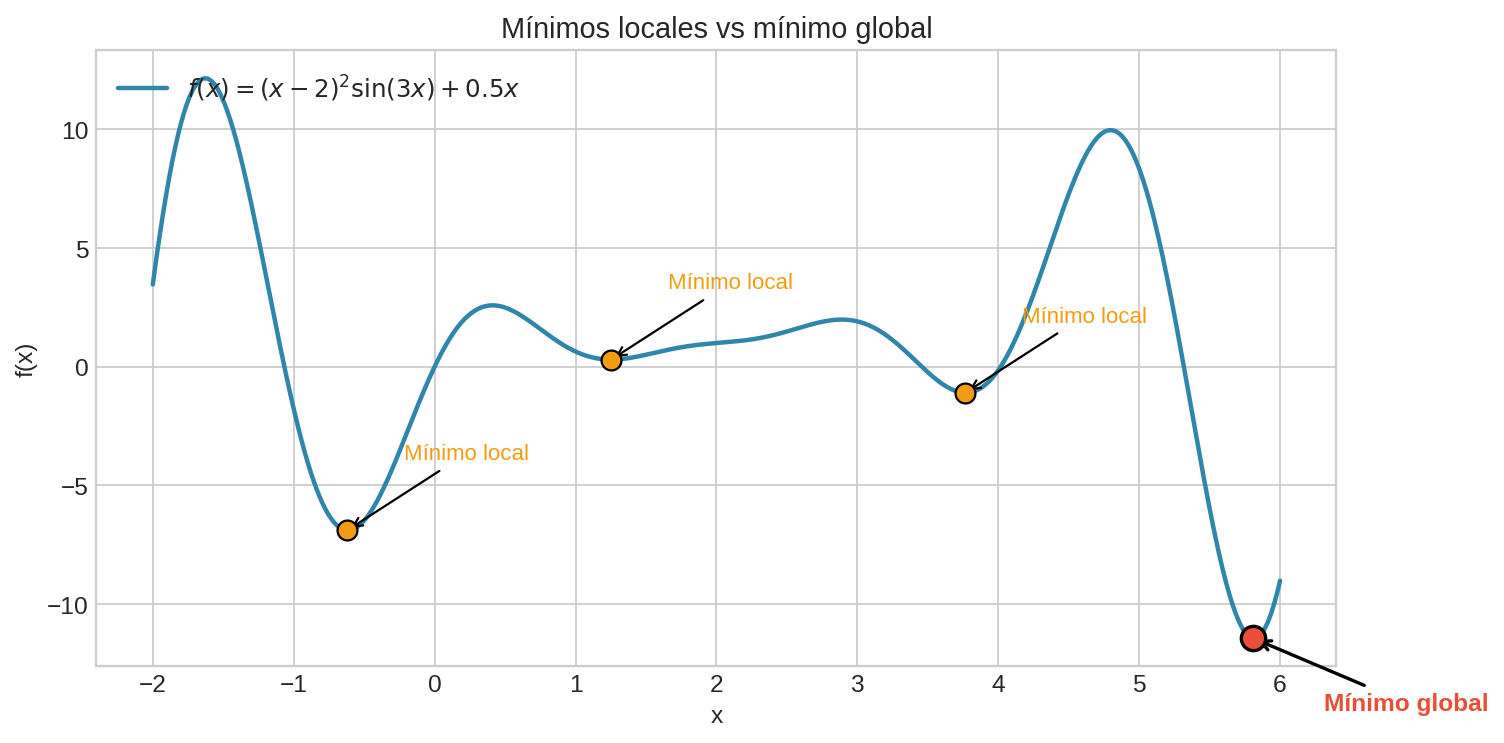
Un algoritmo como descenso de gradiente puede quedarse atrapado en un mínimo local sin encontrar el global. Esta es una de las dificultades fundamentales de la optimización no convexa.
Notebook — Abre NB1: Paisajes 1D
- Ejecuta las celdas del bloque Paisajes 1D para ver una función con múltiples mínimos.
- Cambia
f_customalambda x: x**4 - 8*x**2. ¿Cuántos mínimos locales tiene?- Prueba
lambda x: np.abs(x - 2)— ¿es diferenciable en el mínimo?
Puntos silla
Un punto silla es un punto crítico ($\nabla f = 0$) que no es ni mínimo ni máximo: es mínimo en una dirección y máximo en otra.
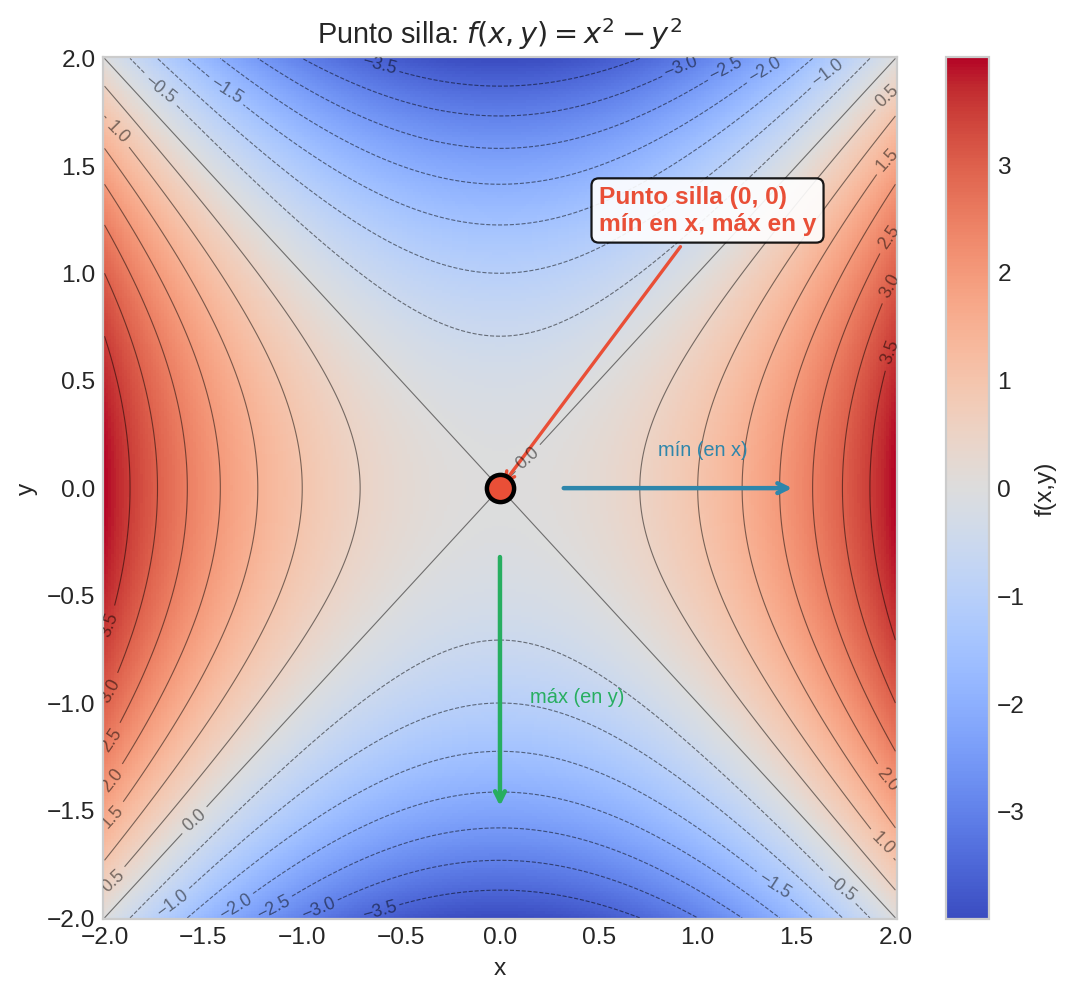
El ejemplo clásico es $f(x,y) = x^2 - y^2$: en $(0,0)$ el gradiente es cero, pero es un mínimo a lo largo de $x$ y un máximo a lo largo de $y$.
¿Por qué importa? En dimensiones altas (como el entrenamiento de redes neuronales con millones de parámetros), los puntos silla son mucho más comunes que los mínimos locales. Intuitivamente: para que un punto crítico sea un mínimo local, todas las direcciones deben curvar hacia arriba. En alta dimensión, es muy probable que al menos una dirección curve hacia abajo.
Notebook — Abre NB1: Superficies 2D
- Compara los contornos del punto silla ($x^2 - y^2$) con el bowl ($x^2 + y^2$).
- Cambia
f_custom_2dalambda x, y: x**2*y**2 - x**2 - y**2. ¿Tiene puntos silla?- Prueba
lambda x, y: np.sin(x) + np.sin(y)— ¿cuántos mínimos locales ves?
Convexidad
Una función $f$ es convexa si para cualesquiera dos puntos $x, y$ y cualquier $\lambda \in [0, 1]$:
$$f(\lambda x + (1-\lambda) y) \leq \lambda f(x) + (1-\lambda) f(y)$$
Geométricamente: la cuerda entre dos puntos de la curva siempre queda por arriba de la curva.
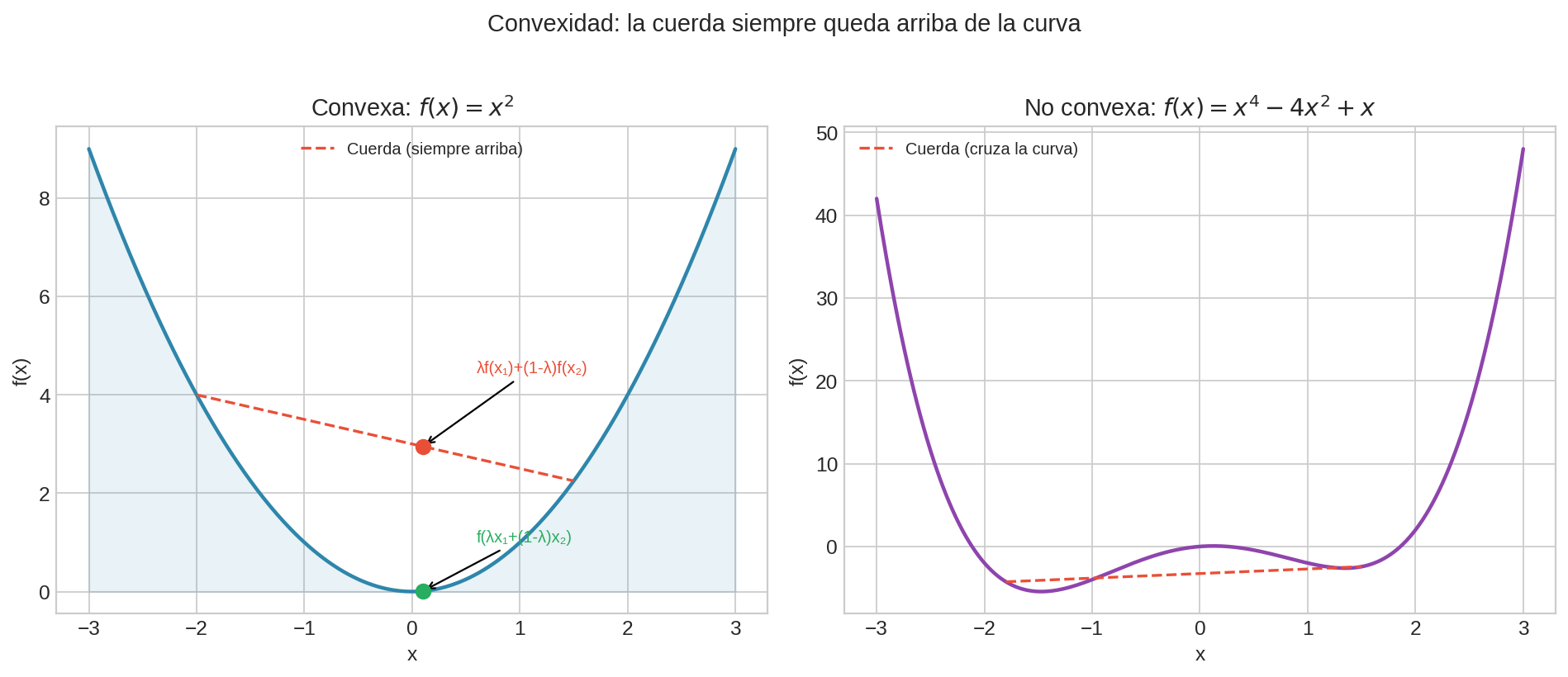
¿Por qué convexidad es tan importante?
En una función convexa, todo mínimo local es global.
Esto significa que si un algoritmo encuentra un punto donde $\nabla f = 0$, puedes estar seguro de que es la solución óptima. No hay trampas de mínimos locales.
Ejemplos de funciones convexas:
- $f(x) = x^2$ (y cualquier forma cuadrática positiva definida)
- $f(x) = |x|$
- $f(x) = e^x$
- $f(x) = \max(0, x)$ (ReLU)
Ejemplos de funciones no convexas:
- $f(x) = \sin(x)$
- $f(x) = x^4 - 4x^2$ (tiene dos mínimos locales)
- Cualquier red neuronal con más de una capa
Notebook — Abre NB1, Secciones 5-6: Convexidad
- Ejecuta las pruebas de cuerdas para $x^2$, $\sin(x)$, $e^x$, $\cos(x)$.
- Clasifica cada función como convexa o no convexa.
- Inventa una función propia y verifica visualmente si es convexa.
- ¿Qué operaciones preservan convexidad? Prueba $f(x) = x^2 + |x|$ y $f(x) = \max(x^2, 2x+1)$.
Taxonomía de problemas
| Tipo | Objetivo | Restricciones | Ejemplo | ¿Convexo? |
|---|---|---|---|---|
| Programación lineal (LP) | Lineal | Lineales | Asignación de recursos | Sí |
| Programación cuadrática (QP) | Cuadrática | Lineales | SVM, portafolio | Sí (si $Q \succeq 0$) |
| Optimización convexa | Convexa | Convexas | Regresión logística | Sí |
| Optimización no convexa | Cualquiera | Cualquiera | Redes neuronales | No |
| Programación entera (IP/MIP) | Lineal/Cuadrática | Variables enteras | Knapsack, scheduling | No (NP-hard en general) |
A medida que bajas en la tabla, los problemas se vuelven más difíciles pero también más expresivos.
La buena noticia: muchos problemas de ML son convexos (regresión lineal, logística, SVM) o “casi convexos” (en la práctica, los mínimos locales de redes neuronales suelen tener valores similares).
Optimización entera y discreta
Cuando las variables de decisión deben ser enteras (¿cuántos camiones enviar?, ¿qué proyectos financiar?), el problema cambia fundamentalmente. No puedes simplemente resolver la versión continua y redondear — el resultado redondeado puede ser infactible o muy lejos del óptimo.
¿Por qué es más difícil? La región factible ya no es continua — son puntos aislados. No hay gradientes, y no puedes “caminar” suavemente hacia la solución.
Variables binarias vs enteras generales
- Binarias ($x_i \in {0, 1}$): decisiones sí/no. ¿Incluir este objeto? ¿Abrir esta planta?
- Enteras generales ($x_i \in \mathbb{Z}_{\geq 0}$): ¿cuántas unidades producir? ¿cuántos turnos asignar?
- Mixtas (MIP): algunas variables enteras, otras continuas. Lo más común en la práctica.
Branch-and-Bound: cómo se resuelven
El algoritmo estándar para programación entera es branch-and-bound:
- Relaja: resuelve la versión continua (LP relaxation). Esto da una cota inferior (para minimización) del óptimo entero — el óptimo continuo siempre es al menos tan bueno.
- Ramifica: elige una variable fraccionaria (e.g., $x_1 = 2.7$) y crea dos subproblemas: uno con $x_1 \leq 2$ y otro con $x_1 \geq 3$.
- Acota: resuelve la relajación LP de cada subproblema. Si la cota inferior de un subproblema es peor que la mejor solución entera conocida, poda esa rama (no la explores más).
- Repite hasta que todas las ramas estén podadas o resueltas.
La clave es que las relajaciones LP son baratas de resolver y dan cotas que permiten eliminar ramas enteras del árbol de búsqueda.
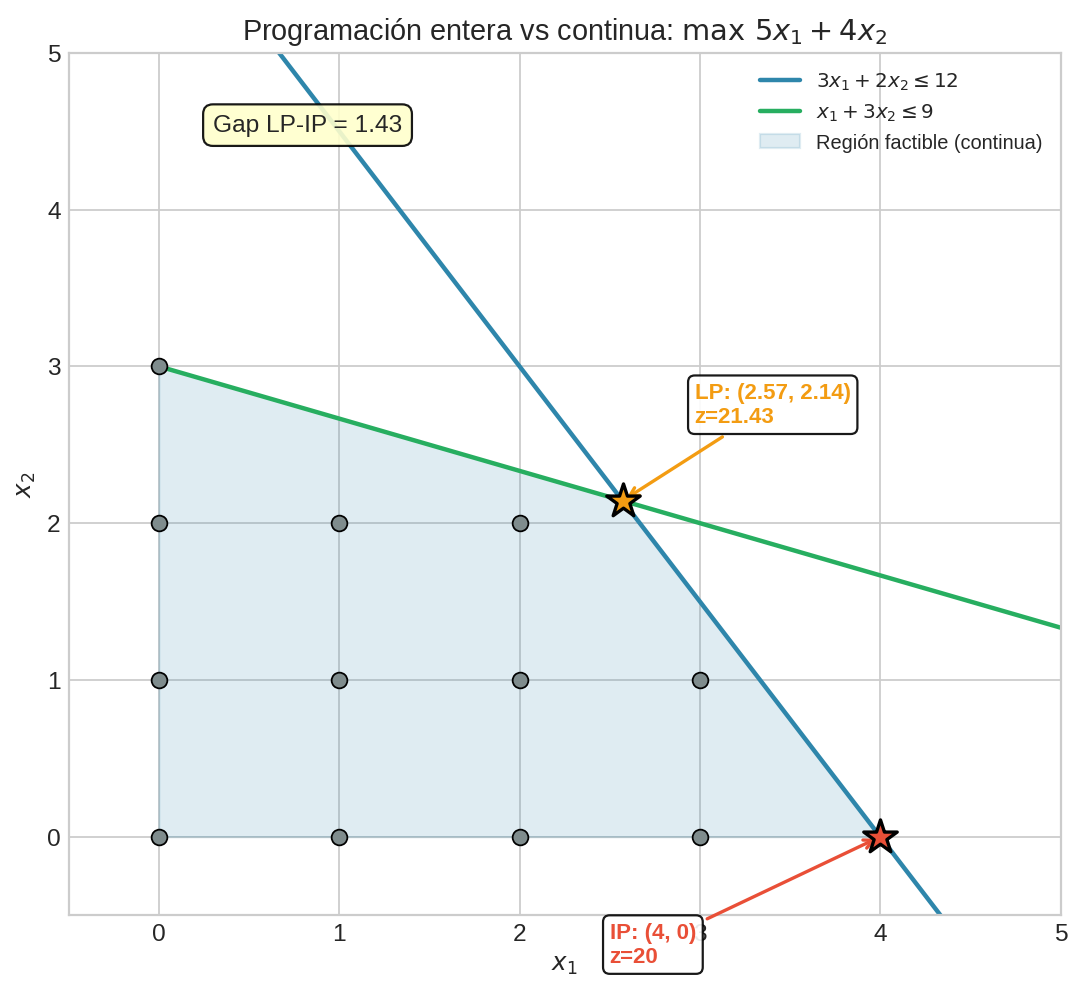
Tienes una mochila con capacidad $W = 15$ kg y 6 objetos:
| Objeto | Peso ($w_i$) | Valor ($v_i$) | Valor/Peso |
|---|---|---|---|
| A | 5 | 10 | 2.00 |
| B | 4 | 8 | 2.00 |
| C | 6 | 11 | 1.83 |
| D | 3 | 7 | 2.33 |
| E | 7 | 14 | 2.00 |
| F | 2 | 3 | 1.50 |
$$\max \sum_i v_i x_i \quad \text{s.t.} \quad \sum_i w_i x_i \leq 15, \quad x_i \in {0, 1}$$
Relajación LP (permite $x_i \in [0,1]$): ordena por valor/peso y llena la mochila. Resultado: A, D, B completos + 0.5 de E → valor = 35.0. Pero no puedes llevar medio objeto.
Redondeo de la LP: quitas E (el fraccionario) → A + D + B = peso 12, valor 25. ¿Es óptimo? No.
Solución MIP óptima: A + D + E = peso 15, valor 31. El redondeo dio 25 — un 19% peor.
Supuestos y características
| Ventajas | Desventajas |
|---|---|
| Solución exacta (óptimo entero garantizado) | NP-hard en general (exponencial en peor caso) |
| La relajación LP da cotas para poda eficiente | Mucho más difícil que LP continua |
| Solvers modernos (HiGHS, CPLEX, Gurobi) resuelven problemas grandes | Sensible a la formulación del problema |
Dónde se usa
- Knapsack: selección de proyectos, asignación de presupuesto
- Scheduling: asignación de turnos, horarios de exámenes
- Facility location: ¿dónde abrir almacenes o plantas?
- Network design: diseño de redes de telecomunicaciones
En Python, scipy.optimize.milp resuelve problemas MIP. Para problemas más serios, bibliotecas como PuLP o Google OR-Tools son el estándar industrial.
Para cada problema, indica si es LP, QP, convexo (no lineal), o no convexo:
- $\min_{x} \quad 3x_1 + 2x_2$ sujeto a $x_1 + x_2 \leq 10$, $x_1, x_2 \geq 0$
- $\min_{x} \quad x_1^2 + x_2^2$ sujeto a $x_1 + x_2 = 1$
- $\min_{x} \quad \sin(x_1) + x_2^2$
- $\min_{w} \quad \sum_i \log(1 + e^{-y_i w^T x_i})$ (log-loss)
Ver Solución
- LP — Objetivo lineal, restricciones lineales.
- QP — Objetivo cuadrático (con $Q = I$, positiva definida → convexo), restricción lineal de igualdad.
- No convexo — $\sin(x_1)$ no es convexa.
- Convexo — La función log-loss es convexa (composición de funciones convexas). Este es el problema de regresión logística.
Siguiente: Algoritmos →