scipy.optimize — referencia rápida
Esta sección es tu cheat sheet de scipy.optimize. Cada patrón muestra el snippet mínimo para resolver un tipo de problema. Los notebooks tienen versiones interactivas con visualización.
Patrón 1: Minimización 1D — minimize_scalar
import numpy as np
from scipy.optimize import minimize_scalar
f = lambda x: (x - 3)**2 + 2 * np.sin(5 * x)
result = minimize_scalar(f, bounds=(0, 6), method="bounded")
# result.x → mínimo, result.fun → f(mínimo)
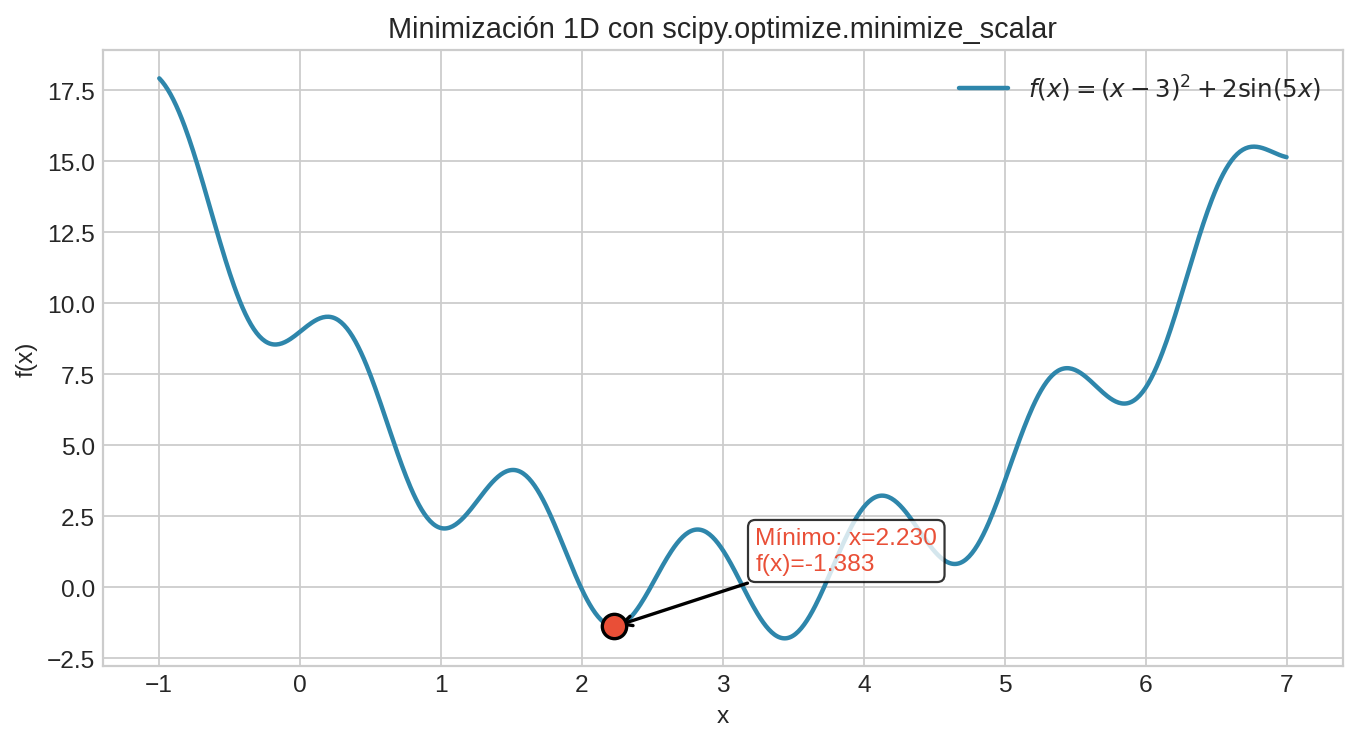
method="bounded" busca en un intervalo. Puede encontrar un mínimo local — prueba diferentes intervalos.
Patrón 2: Minimización multidimensional — minimize
from scipy.optimize import minimize
rosenbrock = lambda x: (1 - x[0])**2 + 100 * (x[1] - x[0]**2)**2
result = minimize(rosenbrock, x0=[-1.5, 2.0], method="L-BFGS-B")
# result.x → solución, result.nfev → evaluaciones de f
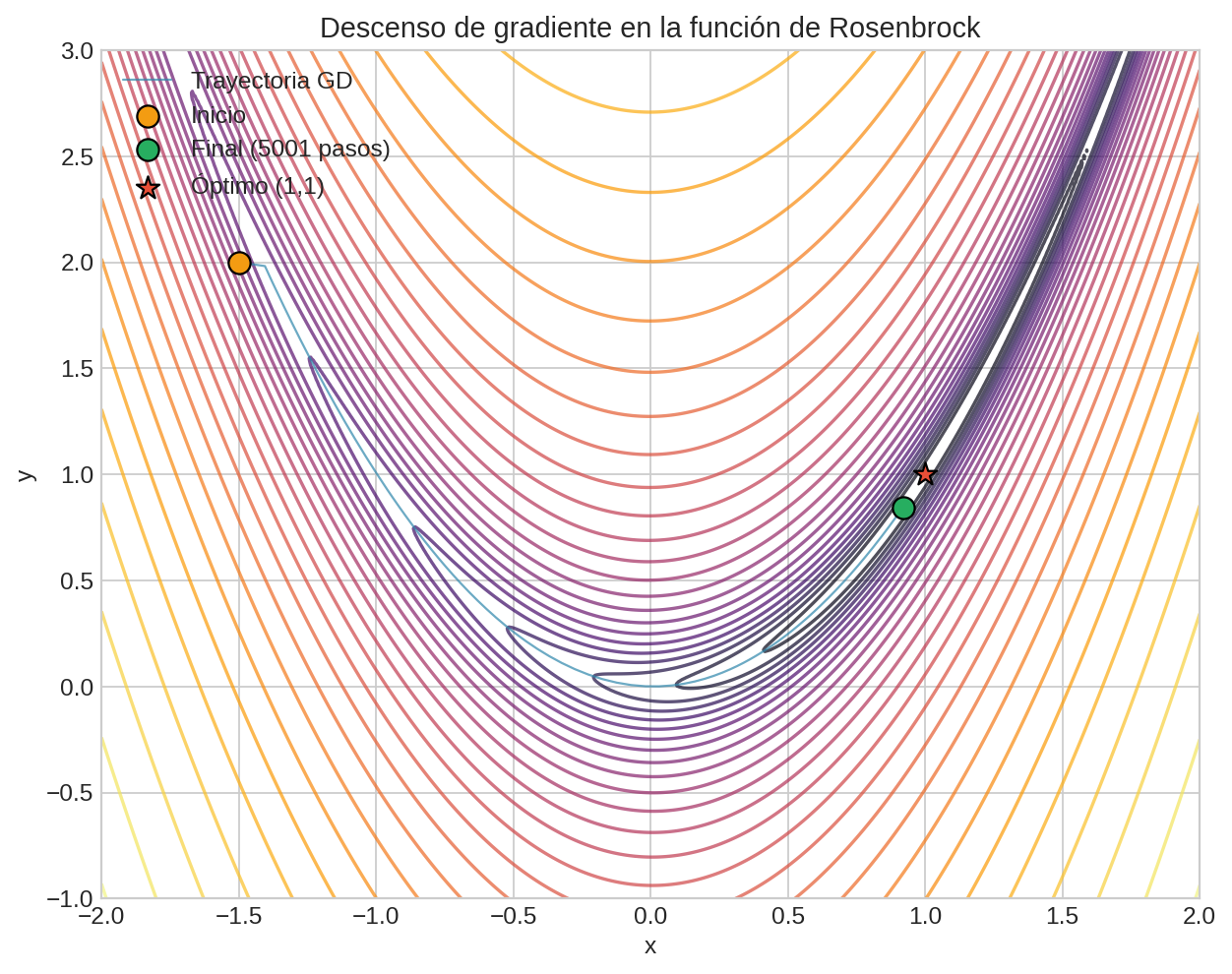
L-BFGS-B es el default para problemas sin restricciones — usa curvatura aproximada (ver métodos de segundo orden).
Patrón 3: Restricciones de igualdad
f = lambda x: x[0]**2 + x[1]**2
constraint = {"type": "eq", "fun": lambda x: x[0] + x[1] - 1}
result = minimize(f, x0=[0.0, 0.0], constraints=constraint)
# result.x → (0.5, 0.5) — coincide con Lagrange analítico
Patrón 4: Restricciones de desigualdad + cotas
f = lambda x: 2*x[0]**2 + 3*x[1]**2 + x[0]*x[1]
constraints = [{"type": "ineq", "fun": lambda x: x[0] + x[1] - 10}] # x1+x2 >= 10
bounds = [(0, None), (0, None)] # x1, x2 >= 0
result = minimize(f, x0=[5.0, 5.0], constraints=constraints, bounds=bounds)
Nota: "ineq" en scipy significa $\text{fun}(x) \geq 0$.
Patrón 5: Programación lineal — linprog
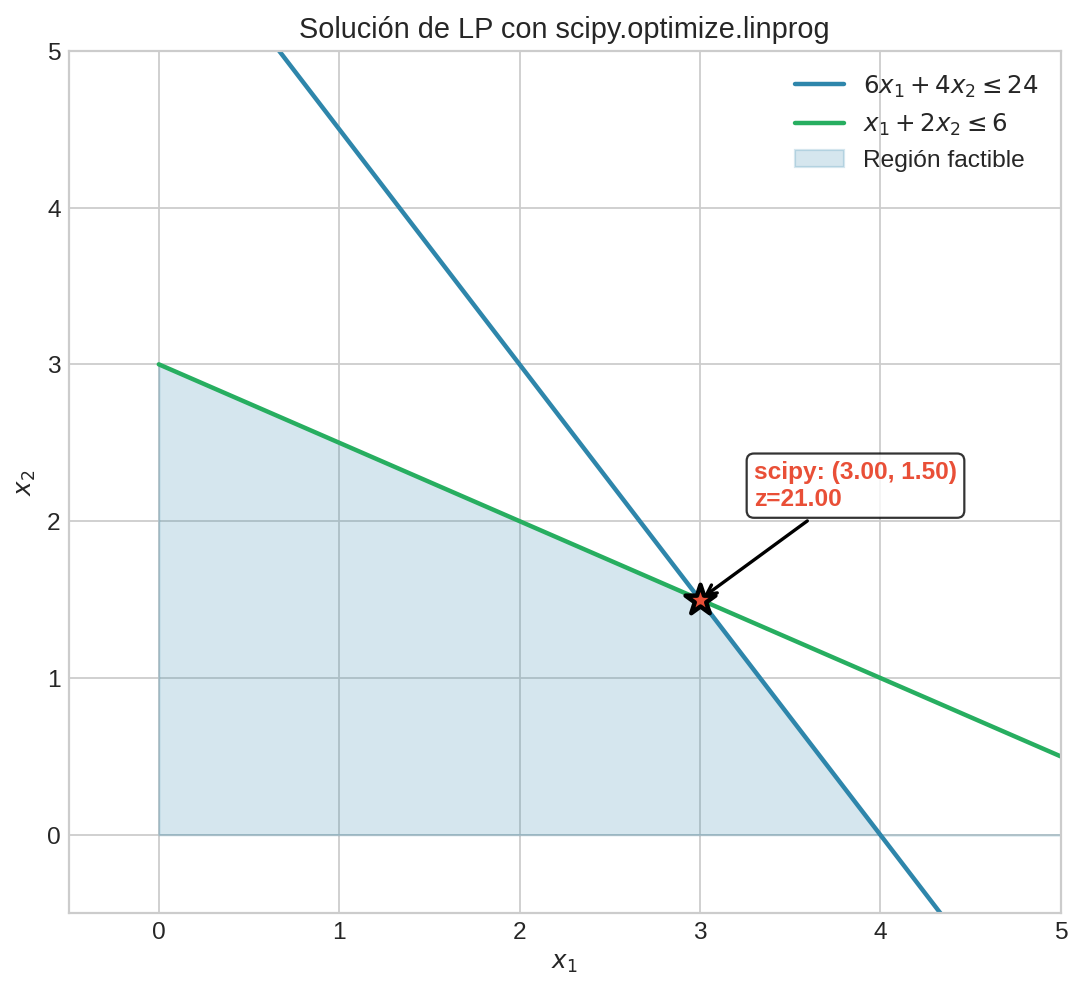
from scipy.optimize import linprog
c = [-5, -4] # min -c^T x (linprog solo minimiza)
A_ub = [[6, 4], [1, 2]] # Ax <= b
b_ub = [24, 6]
bounds = [(0, None), (0, None)]
result = linprog(c, A_ub=A_ub, b_ub=b_ub, bounds=bounds, method="highs")
# -result.fun → ganancia máxima
Patrón 6: Programación entera mixta — milp
from scipy.optimize import milp, LinearConstraint, Bounds
# Knapsack: max 10x1 + 6x2 + 12x3 s.t. 2x1 + x2 + 3x3 <= 5, x_i ∈ {0,1}
c = [-10, -6, -12] # milp minimiza → negamos
constraints = LinearConstraint([[2, 1, 3]], ub=5)
integrality = [1, 1, 1] # 1 = variable entera
bounds = Bounds(lb=0, ub=1) # binarias
result = milp(c, constraints=constraints, integrality=integrality, bounds=bounds)
# result.x → [1, 1, 0], -result.fun → 16
Supuestos: Objetivo y restricciones lineales (o cuadráticos), variables enteras acotadas. Ventaja: Solución exacta — no aproximada. Desventaja: NP-hard, puede ser lento para problemas grandes. Dónde se usa: Knapsack, scheduling, facility location, selección de features (wrapper method).
Patrón 7: Simulated Annealing — dual_annealing
from scipy.optimize import dual_annealing
import numpy as np
rastrigin = lambda x: 10*len(x) + sum(xi**2 - 10*np.cos(2*np.pi*xi) for xi in x)
result = dual_annealing(rastrigin, [(-5.12, 5.12)]*2, seed=42)
# result.x → ~[0, 0], result.fun → ~0
Supuestos: Solo necesita evaluar $f(x)$ — caja negra. No requiere gradiente. Ventaja: Combina SA clásico con búsqueda local; encuentra mínimos globales con alta probabilidad. Desventaja: Más lento que métodos de gradiente; no hay certificado de optimalidad. Dónde se usa: Calibración de simulaciones, diseño de circuitos, hiperparámetros de modelos.
Patrón 8: Evolución diferencial — differential_evolution
from scipy.optimize import differential_evolution
result = differential_evolution(rastrigin, [(-5.12, 5.12)]*2, seed=42)
# result.x → ~[0, 0], result.fun → ~0
Supuestos: Caja negra, dominio acotado. Mantiene una población de soluciones. Ventaja: Robusta, paralelizable, buena para funciones ruidosas o multimodales. Desventaja: Muchas evaluaciones de $f$; lenta para funciones suaves donde el gradiente está disponible. Dónde se usa: Hiperparámetro tuning, diseño de antenas, optimización de portafolios con restricciones no lineales.
Diferenciación automática (autodiff)
En las notas y notebooks anteriores calculamos gradientes a mano. Eso funciona para funciones simples, pero no escala a modelos con millones de parámetros.
Tres formas de obtener gradientes
| Método | Exacto | Costo | Escala |
|---|---|---|---|
| A mano (derivadas analíticas) | Sí | Esfuerzo humano | No |
| Diferencias finitas: $\frac{f(x+h) - f(x)}{h}$ | Aprox. | $O(n)$ evaluaciones | Mal |
| Autodiff (backpropagation) | Sí | ~1 evaluación de $f$ | Millones de params |
Ejemplo: Rosenbrock con PyTorch
import torch
def rosenbrock_torch(xy):
x, y = xy[0], xy[1]
return (1 - x)**2 + 100 * (y - x**2)**2
xy = torch.tensor([-1.5, 2.0], requires_grad=True)
loss = rosenbrock_torch(xy)
loss.backward() # <-- aquí ocurre la magia
print(xy.grad) # gradiente exacto, calculado automáticamente
Esto es exactamente lo que hace loss.backward() en cada iteración de entrenamiento de una red neuronal. Autodiff hace que GD sea práctico para modelos reales.
Notebook — Abre NB2, Sección autodiff
- Ejecuta el ejemplo de autodiff con PyTorch en Rosenbrock.
- Compara el gradiente de
.backward()con el gradiente analítico que calculamos a mano.- ¿Coinciden? Esa es la magia de autodiff: exacto sin esfuerzo.
Conexión con Machine Learning
Cada vez que entrenas un modelo de ML, estás resolviendo un problema de optimización:
| Modelo | Función objetivo | Variables | Restricciones | Algoritmo |
|---|---|---|---|---|
| Regresión lineal | $\sum(y_i - w^T x_i)^2$ | $w$ | Ninguna | Solución cerrada |
| Ridge (L2) | $\sum(y_i - w^T x_i)^2 + \lambda|w|^2$ | $w$ | Equiv. $|w|^2 \leq t$ | Solución cerrada |
| Lasso (L1) | $\sum(y_i - w^T x_i)^2 + \lambda|w|_1$ | $w$ | Equiv. $|w|_1 \leq t$ | Coord. descent |
| Regresión logística | $\sum \log(1 + e^{-y_i w^T x_i})$ | $w$ | Ninguna | L-BFGS / SGD |
| SVM | $\frac{1}{2}|w|^2$ | $w, b$ | $y_i(w^T x_i + b) \geq 1$ | QP (SMO) |
| Red neuronal | $\mathcal{L}(\theta; X, Y)$ | $\theta$ (millones) | Ninguna (típicamente) | SGD / Adam |
| Hyperparameter tuning | Validation loss | Hyperparámetros | Rangos acotados | dual_annealing / DE |
| Feature selection | Precisión del modelo | $x_i \in {0,1}$ | Max features | GA / IP (milp) |
Cuando llamas model.fit() en scikit-learn o loss.backward() en PyTorch, estás ejecutando un algoritmo de optimización.
Una empresa quiere minimizar el costo de transporte $f(x_1, x_2) = 2x_1^2 + 3x_2^2 + x_1 x_2$ sujeto a que la producción total sea al menos 10: $x_1 + x_2 \geq 10$, con $x_1, x_2 \geq 0$.
- Reformula la restricción en forma estándar ($g(x) \leq 0$).
- Resuelve con Lagrange (asumiendo que la restricción está activa, es decir, $x_1 + x_2 = 10$).
- Verifica con scipy usando
minimizecon la restricción.
Ver Solución
1. Reformulación: $x_1 + x_2 \geq 10 \Rightarrow -(x_1 + x_2) + 10 \leq 0$, es decir, $g(x) = -x_1 - x_2 + 10 \leq 0$.
2. Lagrange (asumiendo restricción activa $x_1 + x_2 = 10$):
$\mathcal{L} = 2x_1^2 + 3x_2^2 + x_1 x_2 + \lambda(x_1 + x_2 - 10)$
$$ \begin{aligned} \frac{\partial \mathcal{L}}{\partial x_1} &= 4x_1 + x_2 + \lambda = 0 \ \frac{\partial \mathcal{L}}{\partial x_2} &= 6x_2 + x_1 + \lambda = 0 \ x_1 + x_2 &= 10 \end{aligned} $$
De las dos primeras: $4x_1 + x_2 = 6x_2 + x_1 \Rightarrow 3x_1 = 5x_2 \Rightarrow x_1 = \frac{5}{3}x_2$.
Sustituyendo: $\frac{5}{3}x_2 + x_2 = 10 \Rightarrow \frac{8}{3}x_2 = 10 \Rightarrow x_2 = \frac{30}{8} = 3.75$, $x_1 = 6.25$.
3. Con scipy:
from scipy.optimize import minimize
f = lambda x: 2*x[0]**2 + 3*x[1]**2 + x[0]*x[1]
constraint = {"type": "ineq", "fun": lambda x: x[0] + x[1] - 10}
bounds = [(0, None), (0, None)]
result = minimize(f, x0=[5.0, 5.0], constraints=constraint, bounds=bounds)
print(f"x1={result.x[0]:.4f}, x2={result.x[1]:.4f}, f={result.fun:.4f}")
# x1=6.2500, x2=3.7500, f=110.6250
Notebook — Abre NB2: Capstone
- Escribe tus valores analíticos de $x_1^{∗}$ y $x_2^{∗}$.
- Verifica con scipy que coinciden.
- Visualiza la solución en los contornos de $f$ con la restricción.
Resuelve 5 problemas de optimización en el notebook. Para cada uno debes:
- Formular el problema en notación matemática (variables, objetivo, restricciones)
- Elegir el optimizador adecuado y justificar tu elección
- Implementar la solución completando las funciones esqueleto
- Visualizar y reportar el resultado
Los problemas cubren: programación lineal, optimización cuadrática con restricciones, programación entera binaria, optimización black-box multimodal y programación entera mixta.
Entrega: Pull request en estudiantes/<tu-usuario>/tarea_07/ con el notebook ejecutado. También entregar en Canvas.
Siguiente: ← Volver al índice