Optimización Estocástica
“The future ain’t what it used to be.” — Yogi Berra
De determinista a estocástica
En el módulo 07, optimizábamos funciones deterministas: dado $x$, el valor $f(x)$ es conocido. Pero en la vida real, el resultado de una decisión depende de factores inciertos.
La transición es directa:
| Optimización determinista (módulo 07) | Optimización estocástica (módulo 09) |
|---|---|
| $\min_x f(x)$ | $\min_x E_\theta[f(x, \theta)]$ |
| Variables de decisión $x$ | Variables de decisión $x$ |
| Resultado conocido $f(x)$ | Resultado aleatorio $f(x, \theta)$ |
| Una solución $x^{∗}$ | Una solución $x^{∗}$ (o una política $\pi$) |
| Restricciones $g(x) \leq 0$ | Restricciones pueden ser estocásticas |
Aquí $\theta$ representa la incertidumbre — un estado del mundo que no controlamos. Lo que la sección 9.1 llamaba $S$ (estados), aquí lo llamamos $\theta$ para mantener la notación de optimización.
La conexión: La teoría de la decisión bajo riesgo es optimización estocástica con $f(x, \theta) = -U(x, \theta)$ (negamos porque optimización suele minimizar).
El problema del vendedor de periódicos
El newsvendor problem es el ejemplo canónico de optimización estocástica. Lo construimos paso a paso.
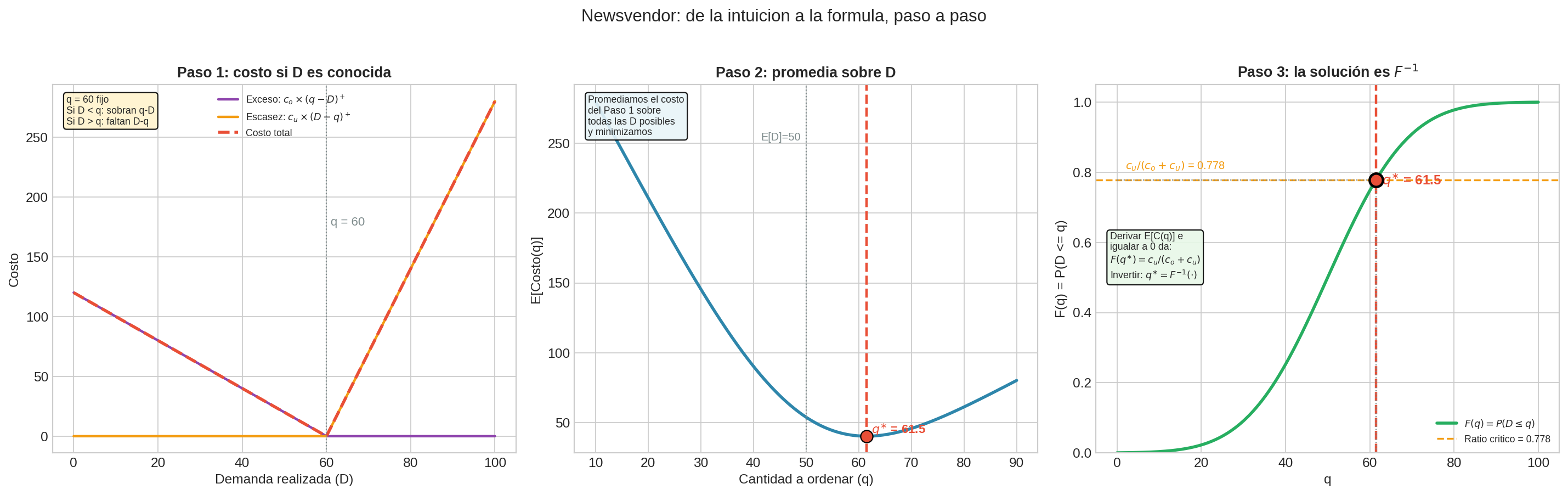
Paso 1: el costo para una demanda conocida
Un vendedor debe decidir cuántos periódicos ordenar ($q$) antes de saber la demanda ($D$). Si después resulta que la demanda es $D = d$:
- Sobraron $q - d$ periódicos (si $q > d$): pierde $c_o$ por cada sobrante
- Faltaron $d - q$ periódicos (si $d > q$): pierde $c_u$ por cada cliente no atendido
El costo para una demanda conocida $d$ es:
$$C(q, d) = c_o \cdot \max(q - d,; 0) + c_u \cdot \max(d - q,; 0)$$
Si $d$ fuera conocido, la respuesta trivial es $q = d$ (costo = 0). Pero no conocemos $d$ — eso es lo que hace al problema interesante.
Paso 2: promediamos sobre la demanda
Como $D$ es aleatorio con distribución conocida, minimizamos el costo esperado:
$$\min_q ; E_D[C(q, D)] = \min_q ; E_D\left[c_o \cdot \max(q - D, 0) + c_u \cdot \max(D - q, 0)\right]$$
Esto es optimización (módulo 07) pero el objetivo es un promedio sobre estados inciertos — exactamente la estructura de la sección 9.1.
Paso 3: derivar y obtener la fórmula
Para encontrar el $q$ que minimiza $E[C(q, D)]$, derivamos respecto a $q$ e igualamos a cero. La derivada del costo esperado es:
$$\frac{d}{dq} E[C(q, D)] = c_o \cdot P(D \leq q) - c_u \cdot P(D > q)$$
Intuición: al aumentar $q$ en una unidad, con probabilidad $P(D \leq q)$ esa unidad sobra (costo $c_o$), y con probabilidad $P(D > q)$ esa unidad evita una falta (ahorro $c_u$).
Igualando a cero:
$$c_o \cdot P(D \leq q^{∗}) = c_u \cdot (1 - P(D \leq q^{∗}))$$
Usando $F(q) = P(D \leq q)$ y despejando:
$$c_o \cdot F(q^{∗}) = c_u - c_u \cdot F(q^{∗})$$
$$F(q^{∗}) \cdot (c_o + c_u) = c_u$$
$$F(q^{∗}) = \frac{c_u}{c_o + c_u}$$
Invirtiendo la CDF:
$$\boxed{q^{∗} = F^{-1}!\left(\frac{c_u}{c_o + c_u}\right)}$$
La fracción $c_u / (c_o + c_u)$ se llama ratio crítico. Es la probabilidad de que la demanda no exceda la cantidad óptima.
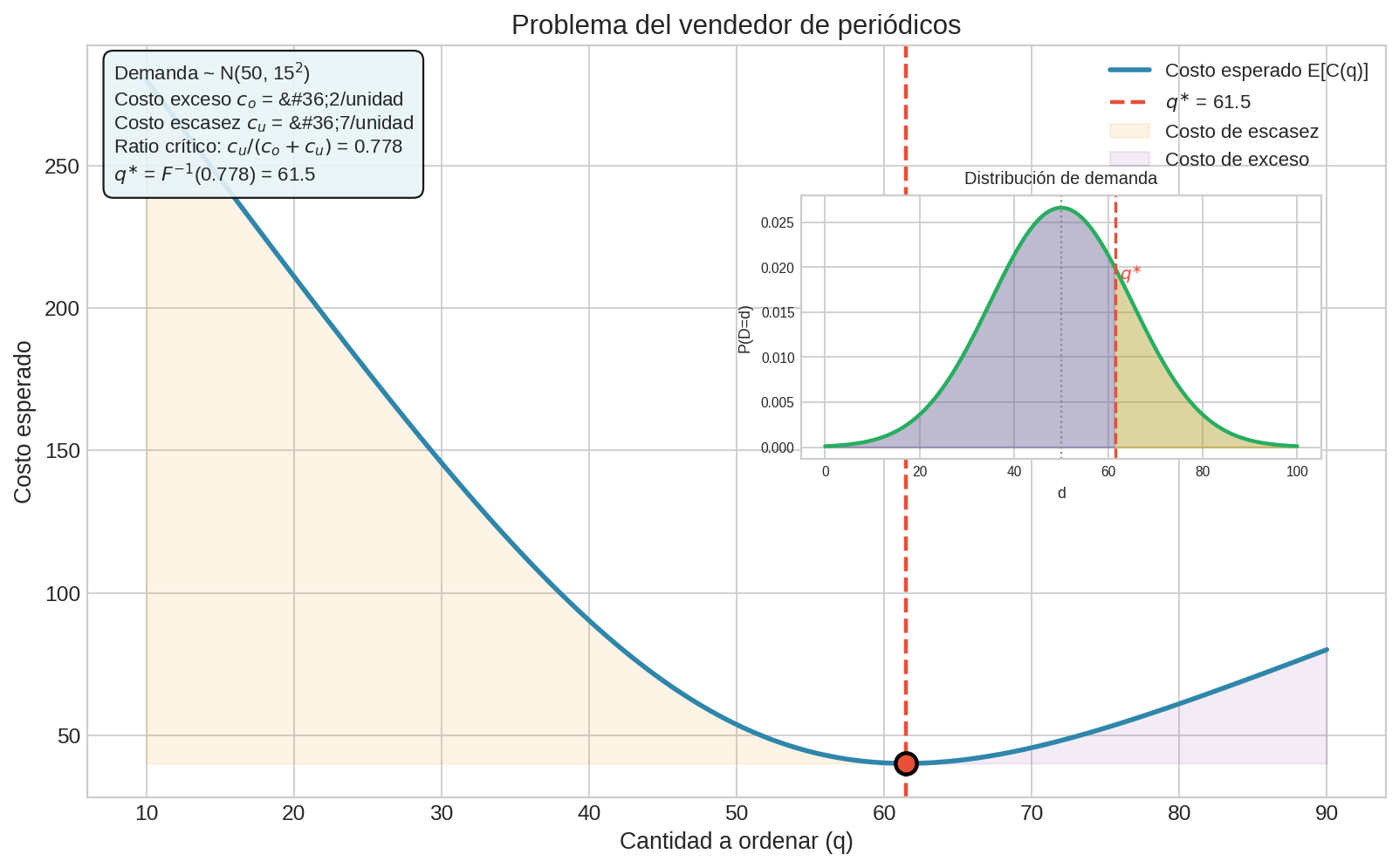
Ejemplo numérico
Demanda $D \sim N(50, 15^2)$, costo exceso $c_o = 2$, costo escasez $c_u = 7$.
Paso 1: Ratio crítico = $\frac{7}{2 + 7} = \frac{7}{9} \approx 0.778$
Paso 2: Necesitamos $q^{∗}$ tal que $F(q^{∗}) = 0.778$, donde $F$ es la CDF de $N(50, 15^2)$.
Paso 3: Usando la inversa de la normal: $q^{∗} = 50 + 15 \times \Phi^{-1}(0.778) \approx 50 + 15 \times 0.765 \approx 61.5$
Ordena ~62 periódicos. Nota que $q^{∗} > E[D] = 50$ porque $c_u > c_o$ — es más caro quedarse corto que sobrar, así que ordenas de más como “seguro”.
¿Y si $c_o = c_u$? Ratio crítico = 0.5, y $q^{∗} = F^{-1}(0.5) = \text{mediana}(D)$. Con costos simétricos, ordenas la mediana.
¿Y si $c_u \gg c_o$? Ratio crítico → 1, y $q^{∗}$ crece: ordenas mucho para casi nunca quedarte corto.
¿De dónde sale $F$?
De la predicción (módulo 08). Si tienes un modelo que predice la distribución de demanda $P(D \mid X)$ dado features $X$ (día de la semana, clima, eventos), entonces $F$ es la CDF de esa distribución condicional.
Conexión completa:
- Predicción te da $P(D \mid X)$ → la distribución $F$
- Decisión usa $F$ y la fórmula del ratio crítico para calcular $q^{∗}$
- Si mejoras la predicción (mejor $F$), reduces el costo esperado
Políticas: la solución es una función, no un número
En optimización determinista (módulo 07), la solución es un número: $x^{∗} = 3.7$, listo. En optimización estocástica, la solución puede ser una función que dice qué hacer dependiendo de lo que observes.
Esa función se llama política:
$$\pi: \text{Observación} \to \text{Acción}$$
Ejemplo concreto: newsvendor con y sin información
Sin información (no sabes nada del contexto):
- Tu política es un número fijo: $\pi = 62$ (ordenas 62 periódicos todos los días, sin importar nada)
- Es la $q^{∗}$ que calculamos arriba
Con información (observas el día de la semana y el clima):
- Tu política es una función que adapta la orden al contexto:
| Observación | Política $\pi(\text{obs})$ | Razón |
|---|---|---|
| Lunes + lluvia | 45 | Poca gente en la calle |
| Miércoles + nublado | 55 | Día promedio |
| Viernes + sol | 70 | Mucha gente, buen clima |
| Domingo + lluvia | 30 | Casi nadie sale |
Cada fila usa la misma fórmula $q^{∗} = F^{-1}(c_u / (c_o + c_u))$, pero con una $F$ diferente — la distribución de demanda condicional a lo que observaste.
¿Por qué importa la distinción?
| Solución fija $a^{∗}$ | Política $\pi(\text{obs})$ | |
|---|---|---|
| Qué es | Un número | Una función |
| Cuándo | No observas nada antes de decidir | Observas algo antes de decidir |
| Ejemplo | “Siempre ordena 62” | “Si lunes ordena 45, si viernes ordena 70” |
| Calidad | Buena en promedio | Mejor porque se adapta |
La diferencia entre solución fija y política es exactamente la diferencia entre $\max_a E[U(a)]$ (una acción para todos los estados) y $E[\max_a U(a, s)]$ (adaptas la acción al estado) — la misma idea del VPI en la sección 9.3.
Las políticas son el concepto central de los procesos de decisión de Markov (MDPs) y el aprendizaje por refuerzo (RL), donde el agente toma decisiones secuenciales y aprende su política por experiencia — módulos futuros del curso.
Varianza, riesgo y robustez
Maximizar $E[U]$ no siempre es suficiente. A veces nos importa la dispersión de los resultados.
Tradeoff media-varianza
En finanzas, el objetivo clásico de Markowitz es:
$$\max_w ; E[R_p] - \lambda \cdot \text{Var}(R_p)$$
donde $w$ son los pesos del portafolio, $R_p = w^T R$ es el retorno del portafolio, y $\lambda > 0$ controla la aversión al riesgo.
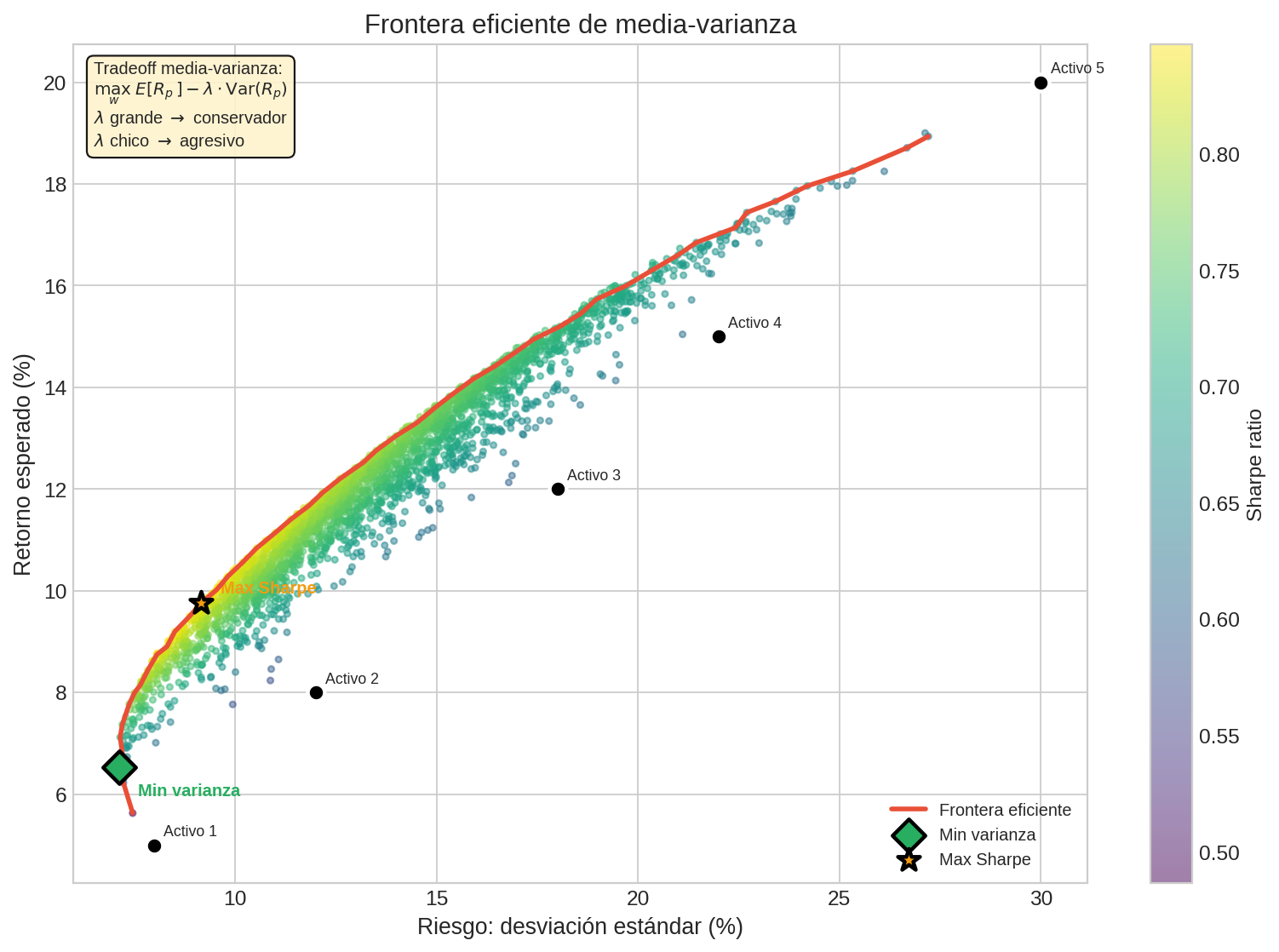
- $\lambda = 0$: solo maximiza retorno (ignora riesgo)
- $\lambda \to \infty$: solo minimiza varianza (ignora retorno)
- $\lambda$ intermedio: tradeoff
La frontera eficiente es el conjunto de portafolios que no pueden mejorar en retorno sin empeorar en riesgo (ni viceversa). Es una curva de Pareto — exactamente el concepto de optimización multiobjetivo del módulo 07.
Value at Risk (VaR)
El VaR responde: “¿cuánto puedo perder en el peor caso razonable?”
$$\text{VaR}{\alpha} = -Q{\alpha}®$$
donde $Q_{\alpha}®$ es el cuantil $\alpha$ de la distribución de retornos $R$. El VaR al nivel $\alpha$ es la pérdida máxima que esperas con probabilidad $1 - \alpha$.
Ejemplo: si $\text{VaR}_{0.05} = 10{,}000$ pesos, significa “con 95% de confianza, no perderás más de 10,000 pesos”.
Optimización robusta
Cuando no confías en la distribución $P(\theta)$, puedes optimizar para el peor caso:
$$\min_x \max_{\theta \in \Theta} f(x, \theta)$$
Esto es el maximin de la sección 9.3, pero formulado como problema de optimización. No necesita probabilidades — solo un conjunto de escenarios posibles $\Theta$.
| Enfoque | Necesita $P(\theta)$ | Actitud |
|---|---|---|
| Estocástico ($\min E[f]$) | Sí | Neutral al modelo |
| Media-varianza | Sí | Averso al riesgo |
| Robusto ($\min\max f$) | No | Pesimista |
Monte Carlo: cuando no hay fórmulas cerradas
El newsvendor tuvo suerte: la derivada del costo esperado tenía forma cerrada y pudimos despejar $q^{∗}$ con álgebra. Pero en muchos problemas reales, $E[f(x, \theta)]$ no se puede calcular analíticamente (la integral no tiene solución cerrada, la distribución de $\theta$ es complicada, etc.).
La idea es simple: reemplaza el valor esperado por un promedio de muestras.
$$E_\theta[f(x, \theta)] \approx \frac{1}{N} \sum_{i=1}^{N} f(x, \theta_i), \quad \theta_i \sim P(\theta)$$
Esto se llama Sample Average Approximation (SAA). El procedimiento:
- Simula $N$ escenarios $\theta_1, \ldots, \theta_N$ de la distribución $P(\theta)$
- Evalúa el costo promedio para cada decisión candidata $x$: el promedio $\frac{1}{N} \sum_i f(x, \theta_i)$
- Optimiza ese promedio usando los algoritmos del módulo 07 (gradiente, scipy, etc.)
Si no sabes que la demanda es Normal pero tienes 100 datos históricos $d_1, \ldots, d_{100}$:
- Para cada $q$ candidato, calcula el costo en cada dato: $C(q, d_i) = 2 \cdot \max(q - d_i, 0) + 7 \cdot \max(d_i - q, 0)$
- Promedia: $\hat{E}[C(q)] = \frac{1}{100} \sum_{i=1}^{100} C(q, d_i)$
- Busca el $q$ que minimiza $\hat{E}[C(q)]$
Esto es equivalente a usar la CDF empírica en la fórmula cerrada: $q^{∗} = \hat{F}^{-1}(c_u / (c_o + c_u))$, donde $\hat{F}$ es la distribución de tus datos históricos. Pero SAA funciona incluso cuando no hay fórmula cerrada.
Anterior: Decidir bajo incertidumbre | Siguiente: El agente que decide →