Historia y Motivación
“The first suggestion was to use a statistical approach — to try to follow by machine computation the actual progress of individual neutrons, one at a time.” — Stanislaw Ulam, 1983
El problema que nadie podía resolver
Era 1946. La Segunda Guerra Mundial había terminado hacía menos de un año, pero el trabajo en Los Álamos National Laboratory, en Nuevo México, continuaba. Los físicos y matemáticos que habían construido la bomba atómica enfrentaban ahora un problema diferente y, en cierto sentido, más difícil: diseñar armas y reactores nucleares de manera óptima y segura, lo que requería entender con precisión cómo los neutrones viajan, se dispersan, y reaccionan dentro de materiales específicos.
El proceso en cuestión se llama transporte de neutrones: un neutrón libre entra a un material, choca con los núcleos atómicos, puede dispersarse en cualquier dirección, puede ser absorbido, puede provocar fisión y generar más neutrones. En cada colisión, el neutrón cambia de dirección y energía de manera aleatoria, siguiendo distribuciones probabilísticas que los físicos conocían bien. La pregunta era: dado un diseño geométrico específico del material, ¿cuántos neutrones escapan? ¿Cuántos producen fisión? ¿Cómo se distribuyen al final?
La ecuación que describe esto — la ecuación de transporte de Boltzmann — es una ecuación integro-diferencial de alta dimensión. Las variables son la posición $(x, y, z)$, la dirección de viaje $(\theta, \phi)$, la energía $E$, y el tiempo $t$. En total, 7 dimensiones.
Los métodos numéricos estándar de la época — construir una cuadrícula sobre el espacio de estados y resolver el sistema numéricamente — requerían un número de puntos que crecía exponencialmente con la dimensión. En 7 dimensiones, incluso con resoluciones muy gruesas, el tamaño del sistema era completamente inmanejable. Y la ENIAC, la computadora más poderosa del planeta en ese momento, tenía apenas unos miles de operaciones por segundo.
El problema era real, urgente, y aparentemente sin solución computacional. Hasta que Ulam fue al hospital.
El solitario de Ulam
Stanislaw Ulam era un matemático polaco excepcional. Había escapado de la Polonia ocupada por los nazis, trabajado en el Proyecto Manhattan, y se había convertido en uno de los pensadores más creativos de Los Álamos. En 1946, convaleciente de una encefalitis severa, pasaba horas en la cama jugando solitario — específicamente, el solitario de cartas llamado Canfield.
Mientras jugaba, su mente matemática se activó en torno a una pregunta aparentemente simple:
¿Cuál es la probabilidad de que una partida de Canfield sea ganadora?
Ulam intentó el enfoque natural: enumerar todas las configuraciones posibles, contar las ganadoras, dividir. Era un problema de combinatoria pura — finito, exacto en principio. Pero el número de configuraciones era tan astronómico que el cálculo era completamente inviable. El problema combinatorio era tan difícil como muchos problemas “serios” de física.
Y entonces tuvo el momento de claridad:
¿Por qué no jugar 100 partidas y contar cuántas gané?
La idea era tan obvia que casi daba vergüenza. Pero sus implicaciones eran enormes. Si juegas 100 partidas y ganas 30, la probabilidad estimada de ganar es 0.30. Con 1,000 partidas, el estimado es más preciso. Con 10,000, más aún. Y lo crucial: el número de partidas que necesitas no depende de la complejidad interna del juego — no depende de cuántas configuraciones posibles existen, ni de cuántas dimensiones tiene el espacio de estados.
Esto rompe la maldición de la dimensionalidad de raíz: en lugar de explorar el espacio de todas las posibilidades, simplemente sigues instancias individuales del proceso aleatorio y promedias.
Ulam entendió de inmediato que la misma lógica aplicaba al problema de los neutrones. En lugar de resolver la ecuación de transporte de Boltzmann en 7 dimensiones sobre una cuadrícula, podías simular la trayectoria de cada neutrón individualmente: lanzar el neutrón, samplear el ángulo de colisión de su distribución, samplear la energía de pérdida de su distribución, seguir el neutrón hasta que es absorbido o escapa, y repetir miles de veces. El promedio de los resultados te da la respuesta.
Cada neutrón individual es un “ensayo” del experimento. La ley de los grandes números garantiza que el promedio converge al valor esperado real.
Von Neumann y la formalización
John von Neumann no necesitaba que le explicaran las cosas dos veces. Cuando Ulam le presentó la idea en una carta famosa, von Neumann la formalizó matemáticamente de inmediato y vio alcances que Ulam no había articulado explícitamente.
El estimador general que von Neumann escribió era:
$$\hat{\mu}n = \frac{1}{n} \sum^n f(X_i), \qquad X_i \stackrel{\text{i.i.d.}}{\sim} p$$
La lectura de esto es: si quieres calcular $\mathbb{E}[f(X)]$ — una integral, una probabilidad, cualquier promedio — simplemente muestrea $n$ valores $X_i$ de la distribución $p$, evalúa $f$ en cada uno, y promedia. La Ley de los Grandes Números garantiza que este promedio converge al valor verdadero conforme $n$ crece.
Von Neumann reconoció que esto no era un truco específico para neutrones: era un método universal de integración para cualquier problema que pudiera formularse como una esperanza. La clase de problemas era enorme: probabilidades de eventos complejos, valores esperados de funciones complicadas, integrales que no tienen forma cerrada.
También reconoció el talón de Aquiles del método: la aleatoriedad. El estimador $\hat{\mu}_n$ es una variable aleatoria — cada corrida da un resultado diferente. La pregunta precisa era: ¿cuán grande puede ser el error? Von Neumann sabía que el Teorema Central del Límite respondía esto: el error escala como $\sigma/\sqrt{n}$, donde $\sigma$ mide la variabilidad de $f(X)$.
Esta tasa $1/\sqrt{n}$ es lenta — para ganar un dígito de precisión necesitas 100 veces más muestras. Pero es completamente independiente de la dimensión del problema. Y eso lo cambia todo.
graph LR
U["Ulam\n(intuición: simula instancias)"] --> V["Von Neumann\n(formalización: estimador general)"]
V --> E["ENIAC 1947\n(primera corrida a gran escala)"]
E --> M["Metropolis & Ulam 1949\n(primer paper público)"]
M --> HOY["Hoy\nML · Bayes · Finanzas · Física"]
La primera corrida computacional a gran escala se realizó en la ENIAC en 1947, simulando procesos de difusión de neutrones. Los resultados superaron las expectativas. Un método que parecía demasiado simple para funcionar dio resultados mejores que los métodos deterministas que nadie había logrado escalar a alta dimensión.
La controversia del nombre
¿Quién le puso el nombre “Monte Carlo” al método?
La disputa es un pequeño escándalo histórico que mezcla orgullo, memoria selectiva, y la imposibilidad de verificar documentos que estaban clasificados.
Nicholas Metropolis, físico que trabajaba junto a Ulam y von Neumann, publicó en 1949 el paper que puso el método en el mapa: “The Monte Carlo Method”, co-escrito con Ulam, en el Journal of the American Statistical Association. Metropolis siempre afirmó haber sido el autor del nombre, inspirado en el Casino de Monte Carlo en Mónaco — la capital del juego de azar en Europa, símbolo de que la suerte produce regularidades cuando se acumula suficiente experiencia.
Pero Ulam contó una historia diferente en sus memorias. El nombre venía de su tío Szymon, un hombre que no podía resistir los juegos de azar y frecuentaba el Casino de Monte Carlo. Cuando Ulam le explicó el método a von Neumann, mencionó casualmente: “es como lo que haría mi tío en Mónaco” — y el nombre se quedó pegado.
Von Neumann aparece en ambas versiones como el catalizador intelectual central, pero nunca reclamó el crédito del nombre. Tal vez no le importaba; tal vez simplemente no recordaba el momento exacto.
Lo que sí sabemos: los documentos de Los Álamos eran en su mayoría clasificados, las conversaciones informales no se registraban, y cuando el método finalmente salió al público en 1949, el nombre ya era un hecho establecido. La disputa nunca se resolvió.
| Protagonista | Contribución principal | Posición en la disputa del nombre |
|---|---|---|
| Stanislaw Ulam | Intuición original: simular instancias del proceso | El nombre venía de su tío Szymon |
| John von Neumann | Formalización matemática; reconoció universalidad | No reclamó el nombre |
| Nicholas Metropolis | Primer paper público (1949); implementación en ENIAC | Afirmó ser el autor del nombre |
El nombre es apropiado de cualquier forma. El Casino de Monte Carlo es el lugar donde la aleatoriedad produce, a largo plazo, resultados absolutamente predecibles — la casa siempre gana exactamente su ventaja esperada, sin importar las fluctuaciones de cualquier noche particular. Eso es precisamente lo que hace el método: transformar fluctuaciones aleatorias en estimados precisos.
El insight dimensional
Para apreciar verdaderamente por qué Monte Carlo fue revolucionario, necesitas entender el problema que venía a resolver: la maldición de la dimensionalidad.
Imagina que quieres calcular la integral de una función $f$ sobre el cubo $d$-dimensional $[0,1]^d$. El enfoque clásico es discretizar cada dimensión en $m$ puntos y evaluar $f$ en todos los nodos de la rejilla. Si usas $m = 10$ puntos por dimensión:
- $d = 1$: $10^1 = 10$ evaluaciones
- $d = 2$: $10^2 = 100$ evaluaciones
- $d = 3$: $10^3 = 1{,}000$ evaluaciones
- $d = 7$ (transporte de neutrones): $10^7 = 10{,}000{,}000$ evaluaciones
- $d = 20$ (modelos modernos de ML): $10^{20}$ evaluaciones — imposible
El crecimiento es exponencial en la dimensión. Esto no es un problema de hardware — es una barrera matemática fundamental. No hay computadora, presente ni futura, que pueda evaluar $10^{100}$ puntos.
El insight de Ulam, formalizado por von Neumann, fue que muestrear el proceso rompe este esquema. Con Monte Carlo:
$$n_{\text{MC}} = \left(\frac{z \cdot \sigma}{\varepsilon}\right)^2 \quad \text{(independiente de } d\text{)}$$
Para alcanzar error $\varepsilon = 0.01$ con $\sigma \approx 0.5$ y confianza 95%, necesitas $n \approx 10{,}000$ evaluaciones — para cualquier dimensión $d$. El número de muestras necesario no crece con $d$ porque cada muestra ya es un punto $d$-dimensional: genera $d$ números aleatorios independientes y ya tienes un punto en el espacio. No intentas cubrir el espacio sistemáticamente; simplemente visitas regiones proporcionalmente a su probabilidad.
Este es el núcleo de por qué Monte Carlo sobrevivió 75 años y se convirtió en el motor de machine learning moderno, inferencia bayesiana, simulación financiera, y física computacional.
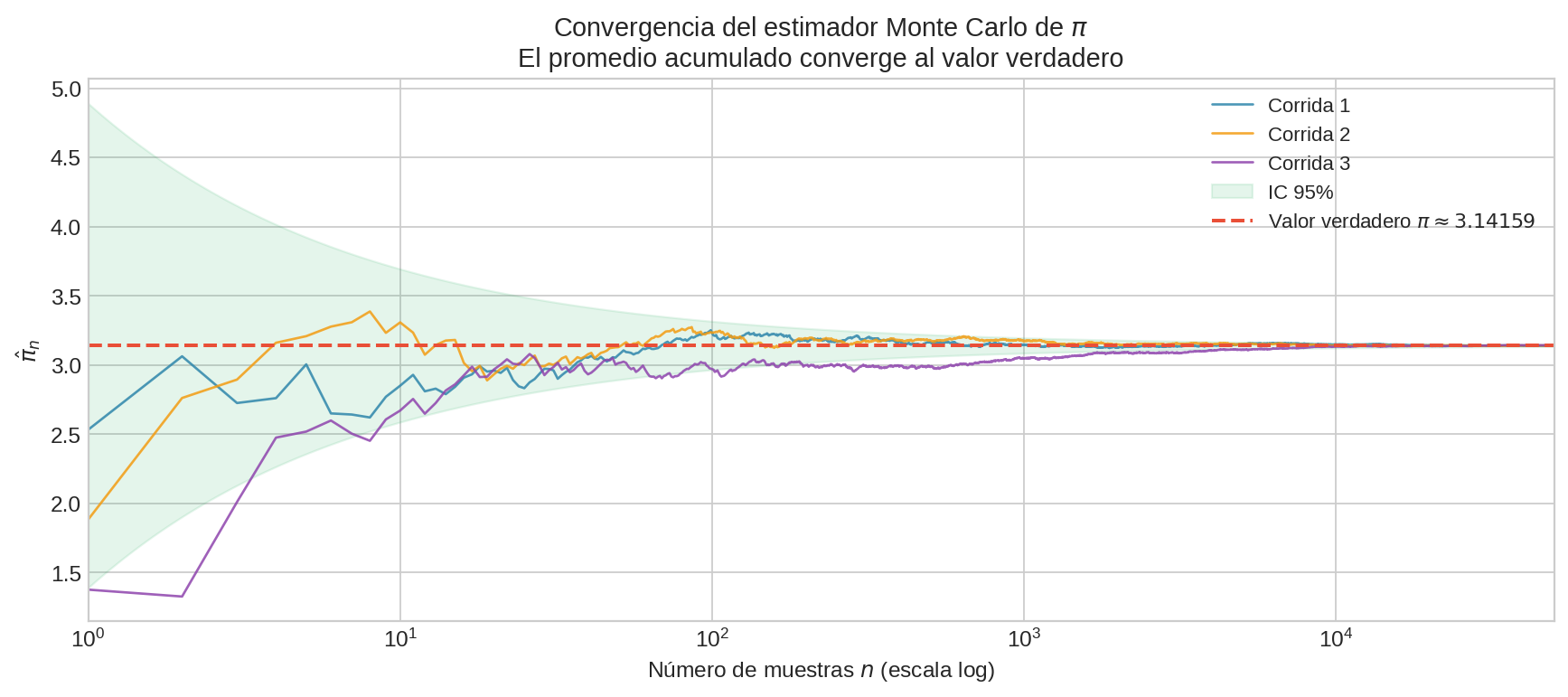
La imagen muestra tres corridas independientes del estimador Monte Carlo de $\pi$. Al principio, con pocas muestras, el estimado oscila. Pero conforme $n$ crece, todas las trayectorias convergen al valor verdadero, y las bandas de confianza se estrechan exactamente como predice la teoría: proporcionales a $1/\sqrt{n}$. Esto ocurre para $\pi$ (un escalar), pero también ocurriría para una integral en 100 dimensiones — con la misma tasa de convergencia.
El truco del círculo: Monte Carlo en acción
Antes de entrar a los fundamentos formales, hay un ejemplo clásico que ilustra perfectamente la idea.
Considera el cuarto de círculo unitario inscrito en el cuadrado $[0,1]^2$. Su área es $\pi/4$. Si “lanzas dardos al azar” dentro del cuadrado — es decir, muestreas puntos $(x, y)$ uniformes en $[0,1]^2$ — la fracción de puntos que cae dentro del cuarto de círculo (es decir, que satisface $x^2 + y^2 \leq 1$) es exactamente $\pi/4$. Multiplica por 4 y tienes $\pi$.
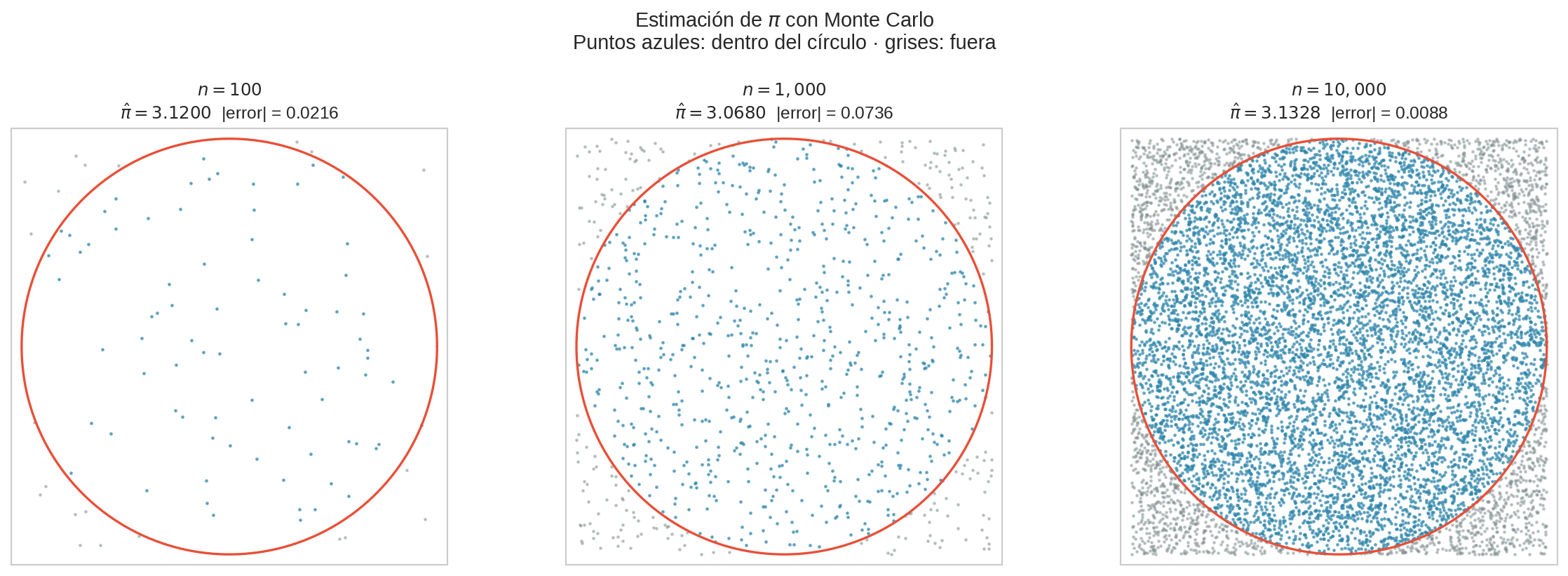
Con $n = 100$ puntos la estimación es tosca — típicamente correcta a 1 decimal. Con $n = 10{,}000$ ya tienes 3-4 decimales correctos. El error cae como $1/\sqrt{n}$.
Formalizado: estamos calculando
$$\mathbb{E}!\left[\mathbf{1}[X^2 + Y^2 \leq 1]\right] = P(X^2 + Y^2 \leq 1) = \frac{\pi}{4}$$
donde $(X, Y) \sim \text{Uniforme}([0,1]^2)$. El estimador Monte Carlo es simplemente el conteo de “dardos dentro del círculo” dividido por el total. Esto no es una casualidad geométrica — es exactamente la misma maquinaria que permite calcular integrales en 100 dimensiones, o simular la propagación de epidemias, o valorar derivados financieros exóticos cuyo payoff depende de 500 variables de mercado.
La siguiente sección formaliza exactamente por qué funciona, cuándo falla, y qué garantías tenemos sobre el error.