Fundamentos Formales
“In its simplest form, the Monte Carlo method is just the sample mean.” — Art Owen, Monte Carlo theory, methods and examples (2013)
El problema central
Casi todo lo que queremos calcular en probabilidad y estadística tiene la forma de una esperanza:
$$\mu = \mathbb{E}[f(X)] = \int f(x), p(x), dx$$
Esto parece abstracto, pero abarca una cantidad enorme de problemas concretos:
| Lo que quieres calcular | Cómo se escribe como $\mathbb{E}[f(X)]$ |
|---|---|
| $P(X \in A)$ | $f(x) = \mathbf{1}[x \in A]$, integral de la densidad sobre $A$ |
| $\mathbb{E}[X^2]$, $\mathbb{E}[X^3]$, … | $f(x) = x^k$ |
| $\text{Var}[X]$ | $f(x) = (x - \mu)^2$ |
| Precio de una opción financiera | $f(S_T) = \max(S_T - K, 0)$, $X = S_T$ |
| Probabilidad posterior $P(\theta \mid \text{datos})$ | Integral de la likelihood por el prior |
El obstáculo es que la mayoría de estos integrales no tienen forma cerrada. No es que no hayamos encontrado la fórmula todavía — en general no existe. Y los métodos numéricos clásicos, como veremos, colapsan cuando la dimensión del problema crece.
Monte Carlo es la respuesta a este problema.
El estimador de Monte Carlo
La idea detrás del estimador es una observación casi filosófica:
Si no puedes calcular $\mathbb{E}[f(X)]$ analíticamente, obsérvalo empíricamente.
Si tienes acceso a muestras $X_1, \ldots, X_n \sim p$, puedes sustituir la esperanza teórica por un promedio muestral. Por la ley de los grandes números (que formalizaremos enseguida), esos son la misma cosa cuando $n$ es grande.
Dados $n$ puntos muestreados independientemente de $p$:
$$X_1, X_2, \ldots, X_n \stackrel{\text{i.i.d.}}{\sim} p$$
el estimador Monte Carlo es:
$$\hat{\mu}n = \frac{1}{n} \sum^n f(X_i)$$
Observa que $\hat{\mu}_n$ es una variable aleatoria — depende de qué puntos se hayan muestreado. Si corres el estimador dos veces con muestras distintas, obtienes valores distintos. Lo que vamos a estudiar es cómo se comporta esta variable aleatoria: qué tan cerca está de $\mu$, y con qué probabilidad.
Por qué funciona: la Ley de los Grandes Números
El estimador funciona porque la Ley de los Grandes Números (LLN) garantiza que el promedio muestral converge al verdadero valor esperado.
Antes de enunciar el teorema, conviene entender intuitivamente qué dice. Cada $f(X_i)$ es una observación “ruidosa” de $\mu$: es $\mu$ más alguna fluctuación aleatoria con media cero. Al promediar $n$ de estas observaciones, las fluctuaciones se van cancelando entre sí — las positivas con las negativas. Con más y más muestras, las cancelaciones son cada vez más completas y el promedio se acerca al valor verdadero.
Teorema (LLN fuerte): Si $X_1, X_2, \ldots$ son i.i.d. con distribución $p$ y se cumple:
$$\mathbb{E}[|f(X)|] < \infty \qquad \text{(supuesto: f es integrable)}$$
entonces, con probabilidad 1:
$$\hat{\mu}_n \xrightarrow{n \to \infty} \mu$$
¿Qué significa “con probabilidad 1”? Significa que si imaginamos todas las secuencias posibles de muestras $X_1, X_2, \ldots$, la fracción de secuencias para las que el promedio no converge a $\mu$ es cero. Es la convergencia más fuerte que existe — se llama convergencia casi segura (almost sure).
¿Por qué importa el supuesto $\mathbb{E}[|f(X)|] < \infty$? Si $f$ no es integrable (por ejemplo, $f(x) = 1/x$ cerca de $x=0$ con $X$ uniforme), entonces $\mu$ no está bien definido. No podemos converger a algo que no existe. El supuesto simplemente pide que el problema tenga solución.
El resultado clave: el estimador MC es consistente — siempre converge al valor correcto si el problema está bien planteado.
Cuán bueno es: el Teorema Central del Límite
La LLN responde “¿converge?”. La siguiente pregunta es “¿con qué rapidez?”. Para $n$ finito, ¿qué tan grande puede ser el error $|\hat{\mu}_n - \mu|$?
El Teorema Central del Límite (CLT) responde esto de forma precisa. Requiere un supuesto adicional:
$$\text{Var}[f(X)] = \sigma^2 < \infty \qquad \text{(la varianza de } f \text{ existe y es finita)}$$
Bajo este supuesto, para $n$ suficientemente grande:
$$\sqrt{n}(\hat{\mu}_n - \mu) \xrightarrow{d} \mathcal{N}(0, \sigma^2)$$
Esto dice que el error escalado $\sqrt{n}(\hat{\mu}_n - \mu)$ converge en distribución a una normal. En términos prácticos:
$$\hat{\mu}_n \approx \mathcal{N}!\left(\mu,\ \frac{\sigma^2}{n}\right) \qquad \text{para } n \text{ grande}$$
El estimador fluctúa alrededor del valor verdadero $\mu$ con una distribución aproximadamente normal de desviación estándar $\sigma/\sqrt{n}$.
¿Qué es $\sigma^2$ y por qué importa?
$\sigma^2 = \text{Var}[f(X)]$ mide cuánto varía $f(X)$ de una muestra a otra. Si $f$ es una función muy “plana” (casi constante), entonces $\sigma^2$ es pequeño y el estimador es muy preciso. Si $f$ tiene picos altos y valles profundos, $\sigma^2$ es grande y necesitas más muestras para que el promedio se estabilice.
Esta observación es crucial porque hay formas de reducir $\sigma^2$ sin cambiar el valor de $\mu$ — eso es exactamente lo que hacen las técnicas de reducción de varianza del Notebook 02.
El intervalo de confianza
Del CLT se desprende directamente cómo cuantificar la incertidumbre del estimador. Un intervalo de confianza al $(1-\alpha)$ para $\mu$ es:
$$\hat{\mu}n \pm z{\alpha/2} \cdot \frac{\hat{\sigma}}{\sqrt{n}}$$
donde:
- $\hat{\sigma}$ es la desviación estándar muestral de $f(X_1), \ldots, f(X_n)$ (estimamos $\sigma$ de los datos)
- $z_{0.025} = 1.96$ para el IC al 95%
La interpretación: si repitieras el experimento muchas veces, el 95% de los intervalos construidos así contendrían el valor verdadero $\mu$.
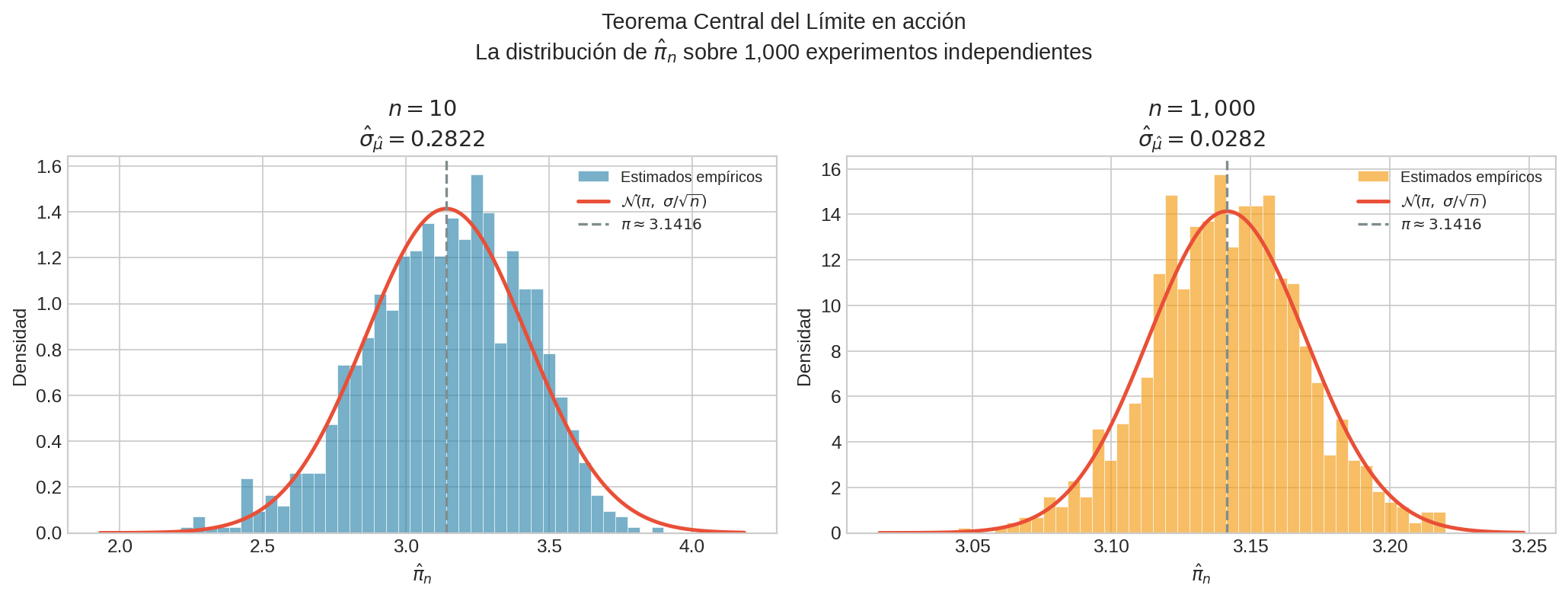
La imagen muestra exactamente esto: 1,000 estimados independientes de $\pi$ forman una distribución aproximadamente normal, centrada en $\pi$ con ancho que cae como $\sigma/\sqrt{n}$ cuando $n$ crece.
El error escala como $O(1/\sqrt{n})$: lento pero universal
El error estándar del estimador es:
$$\text{SE}(\hat{\mu}_n) = \frac{\sigma}{\sqrt{n}}$$
La tasa $1/\sqrt{n}$ es lenta. Para ganar un dígito decimal de precisión (reducir el error por un factor de 10), necesitas 100 veces más muestras. Para ganar dos dígitos, necesitas 10,000 veces más.
Esto puede sonar como una limitación. Y lo es. Pero tiene una propiedad que lo compensa todo: $\sigma/\sqrt{n}$ no depende de la dimensión del problema. El número de variables de $\mathbf{X}$ no aparece en ningún lugar de esta fórmula. Esta invariancia dimensional es el corazón del poder de Monte Carlo.
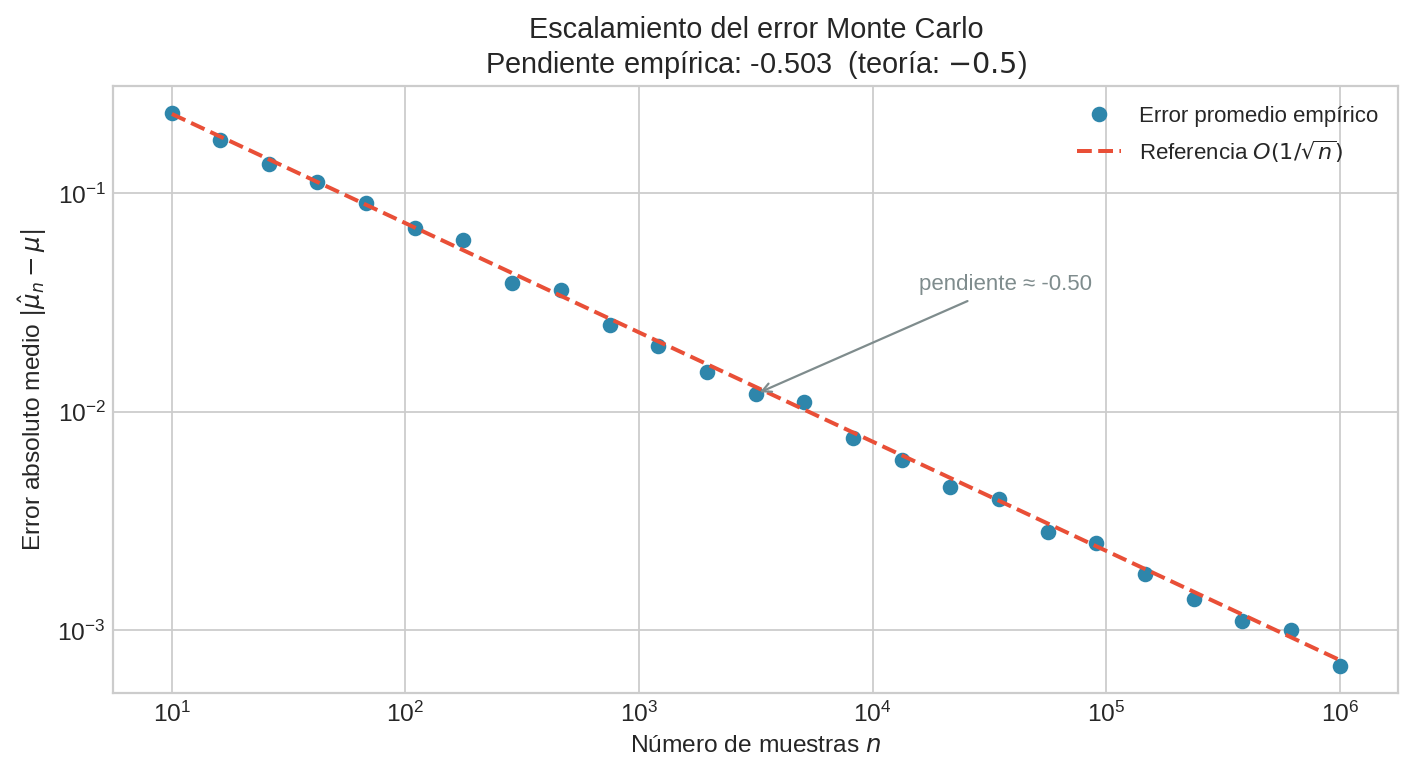
La gráfica log-log confirma la teoría: la pendiente empírica es $\approx -0.5$, exactamente $-1/2$, para cualquier función $f$ de cualquier dimensión.
La ventaja dimensional: Monte Carlo vs. Cuadratura
Para entender por qué Monte Carlo es tan importante, necesitamos compararlo con la alternativa natural: los métodos de cuadratura. Primero explicamos qué son, luego derivamos su costo, y finalmente vemos dónde se rompen.
¿Qué es cuadratura?
Cuadratura es el nombre genérico para los métodos deterministas de integración numérica. La idea es aproximar el integral de $f$ evaluando $f$ en una colección de puntos fijos (no aleatorios) y combinando esas evaluaciones con pesos predeterminados.
El ejemplo más simple es la regla del rectángulo en 1D. Para estimar $\int_0^1 f(x), dx$:
- Divide $[0,1]$ en $m$ subintervalos iguales de longitud $h = 1/m$
- En cada subintervalo, evalúa $f$ en el punto medio: $x_k = (k - \tfrac{1}{2})/m$
- Aproxima el área bajo $f$ como suma de rectángulos:
$$\int_0^1 f(x), dx \approx \sum_{k=1}^m f(x_k) \cdot h = \frac{1}{m}\sum_{k=1}^m f!\left(\frac{k-1/2}{m}\right)$$
Con $n = m$ puntos en 1D, el error de esta aproximación es $O(h^2) = O(m^{-2}) = O(n^{-2})$. Existen métodos más sofisticados (trapezoidal, Simpson, cuadratura gaussiana) con tasas aún mejores en 1D, pero la idea fundamental es la misma: una rejilla determinista de puntos de evaluación.
El costo en alta dimensión
El problema aparece cuando el integral es sobre un espacio de alta dimensión: $\int_{[0,1]^d} f(\mathbf{x}), d\mathbf{x}$.
El enfoque natural es construir una rejilla $d$-dimensional: si usas $m$ puntos uniformes por dimensión, la rejilla tiene $n = m^d$ puntos en total. Esto se llama el producto tensorial de las rejillas 1D.
$$\text{total de puntos: } n = m^d \quad \Longleftrightarrow \quad m = n^{1/d}$$
El error de la regla del rectángulo en $d$ dimensiones sigue siendo $O(h^2) = O(m^{-2})$ en términos de $m$ puntos por dimensión. Pero en términos del total de puntos $n$:
$$\text{error}_{\text{cuad}}(n, d) = O!\left(m^{-2}\right) = O!\left((n^{1/d})^{-2}\right) = O!\left(n^{-2/d}\right)$$
Este es el resultado central: el exponente que controla la convergencia se divide por la dimensión. Mientras más dimensiones, más lento converge la cuadratura para el mismo número total de puntos.
La catástrofe de la dimensionalidad
Mira qué le pasa al error cuando $d$ crece, fijando el número de puntos $n$:
| Dimensión $d$ | Tasa de error | Puntos para error $\varepsilon = 0.01$ |
|---|---|---|
| 1 | $O(n^{-2})$ | $n \approx 10$ |
| 2 | $O(n^{-1})$ | $n \approx 100$ |
| 4 | $O(n^{-1/2})$ | $n \approx 10{,}000$ |
| 10 | $O(n^{-1/5})$ | $n \approx 10^{10}$ |
| 20 | $O(n^{-1/10})$ | $n \approx 10^{20}$ |
| 100 | $O(n^{-1/50})$ | $n \approx 10^{100}$ |
Para $d = 20$ y $\varepsilon = 0.01$: necesitas del orden de $10^{20}$ evaluaciones. Si cada una tarda un nanosegundo, eso es unos 3,000 años de cómputo. Esto no es un problema de hardware — es un problema matemático fundamental. Se llama la maldición de la dimensionalidad.
¿Por qué ocurre? Intuitivamente: para cubrir bien un cubo $d$-dimensional con una rejilla, necesitas puntos en todas las combinaciones de valores de cada coordenada. Si usas 10 valores por coordenada en $d = 20$ dimensiones, son $10^{20}$ puntos. El número de puntos crece exponencialmente con la dimensión.
El poder de Monte Carlo
Monte Carlo tiene un comportamiento completamente diferente. El error del estimador es $\sigma/\sqrt{n}$, y en ningún lugar de esta fórmula aparece $d$:
$$\text{error}_{\text{MC}}(n) = \frac{\sigma}{\sqrt{n}} = O!\left(n^{-1/2}\right)$$
¿Por qué Monte Carlo no sufre la maldición de la dimensionalidad? Porque muestrear un vector $d$-dimensional tiene el mismo costo que muestrear un escalar: genera $d$ números aleatorios independientes. No intentas cubrir todo el espacio sistemáticamente — simplemente evalúas $f$ en puntos aleatorios. Las regiones que no importan (donde $f \cdot p$ es pequeño) reciben pocas muestras automáticamente.
El número de puntos necesarios para alcanzar error $\varepsilon$ es:
$$n_{\text{MC}} = \left(\frac{z_{\alpha/2} \cdot \sigma}{\varepsilon}\right)^2$$
Para $\varepsilon = 0.01$ y $\sigma = 0.5$: $n_{\text{MC}} \approx 10{,}000$ — independientemente de si $d = 2$ o $d = 10{,}000$.
La comparación directa
| Método | Tasa de error en función de $n$ total | ¿Depende de $d$? |
|---|---|---|
| Cuadratura | $O(n^{-2/d})$ | Sí — empeora exponencialmente |
| Monte Carlo | $O(n^{-1/2})$ | No — constante en $d$ |
El punto de cruce se encuentra igualando las tasas:
$$n^{-2/d} = n^{-1/2} \quad \Longleftrightarrow \quad \frac{2}{d} = \frac{1}{2} \quad \Longleftrightarrow \quad d = 4$$
- Para $d < 4$: cuadratura converge más rápido (la tasa $n^{-2/d}$ supera a $n^{-1/2}$)
- Para $d = 4$: ambos métodos tienen exactamente la misma tasa
- Para $d > 4$: Monte Carlo domina de forma creciente
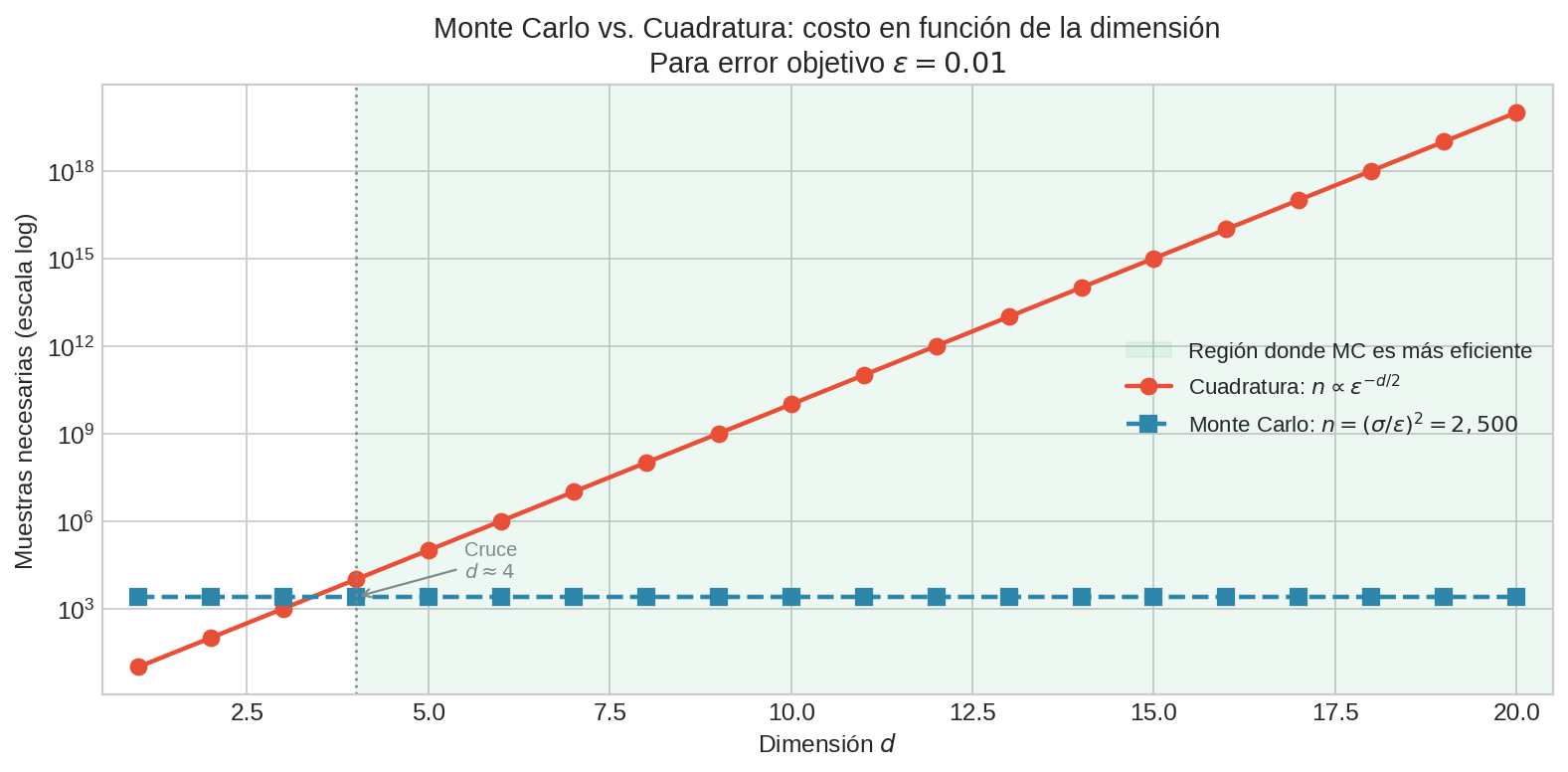
Esta propiedad es la razón por la que Monte Carlo es el método estándar en machine learning (donde los modelos tienen millones de parámetros), física estadística, inferencia bayesiana, y simulación financiera. En todos estos dominios, los integrales de interés viven en espacios de dimensión muy alta.
Los tres requisitos
Monte Carlo funciona cuando se cumplen tres condiciones. Vale la pena entender cada una a fondo, porque en la práctica alguna puede fallar.
1. Muestras i.i.d.
$X_1, \ldots, X_n$ deben ser independientes e idénticamente distribuidas de $p$. Este es el supuesto que permite la LLN y el CLT. Si las muestras están correlacionadas (por ejemplo, puntos consecutivos de una cadena de Markov que todavía no mezcló), el promedio puede no converger al valor correcto, o converger más lentamente de lo que predice $\sigma/\sqrt{n}$.
2. Varianza finita
$\text{Var}[f(X)] = \sigma^2 < \infty$. Este supuesto garantiza que el CLT aplica y que los intervalos de confianza son válidos. Si $\sigma^2 = \infty$ — por ejemplo, $f(x) = 1/x^2$ cerca de $x = 0$ con $X$ uniforme — los promedios siguen oscilando violentamente sin estabilizarse, y el IC que calculamos es una ilusión. El notebook 01 tiene un ejercicio que muestra exactamente esto con $f(x) = 1/x$.
3. Capacidad de muestrear de $p$
El estimador requiere generar $X \sim p$. Para distribuciones estándar (normal, exponencial, uniforme) esto es trivial. Pero para el posterior bayesiano de un modelo complejo — que es exactamente cuando MC sería más útil — muestrear directamente de $p$ puede ser imposible. Resolver este problema es el objetivo de MCMC (Markov Chain Monte Carlo): construir una cadena de Markov cuya distribución estacionaria es $p$, lo que permite obtener muestras aproximadamente distribuidas según $p$ aunque no puedas muestrearla directamente.
| Requisito | Condición formal | Qué pasa si se viola |
|---|---|---|
| i.i.d. | $X_i$ independientes, misma distribución $p$ | Estimador posiblemente sesgado o tasa de convergencia peor |
| Varianza finita | $\sigma^2 = \text{Var}[f(X)] < \infty$ | CLT no aplica; ICs inválidos; estimados inestables |
| Muestreable | Se puede generar $X \sim p$ | Necesitas MCMC, IS, o rejection sampling |
Colas largas: cuando el supuesto se viola en serio
En el módulo 05 estudiamos en detalle las colas largas (fat tails). Aquí conectamos ese material directamente con Monte Carlo: ¿qué le pasa al estimador cuando la distribución de $f(X)$ tiene colas pesadas?
La respuesta corta: depende de cuánto le pesan las colas — y hay tres regímenes muy distintos.
Los tres regímenes, repasados desde MC
Recordemos la clasificación de colas con el exponente $\alpha$ de una distribución Pareto-like $P(|f(X)| > t) \sim t^{-\alpha}$:
| Régimen | Condición | Media | Varianza | LLN | CLT | Consecuencia para MC |
|---|---|---|---|---|---|---|
| Cola ligera | $\alpha > 2$ | Finita | Finita | ✓ | ✓ | MC funciona, IC válido |
| Cola pesada moderada | $1 < \alpha \leq 2$ | Finita | Infinita | ✓ (lento) | ✗ | MC converge, pero IC es inválido |
| Cola pesada extrema | $\alpha \leq 1$ | Infinita | Infinita | ✗ | ✗ | MC no converge a nada |
Caso 1: $\alpha > 2$ — todo funciona
Cuando la varianza es finita, el CLT aplica y los intervalos de confianza son válidos. El error cae como $\sigma/\sqrt{n}$ como siempre. Este es el escenario del mundo feliz.
Caso 2: $1 < \alpha \leq 2$ — el caso engañoso
Este es el régimen más peligroso, porque parece que Monte Carlo funciona.
La media $\mu = \mathbb{E}[f(X)]$ existe y es finita. La LLN sigue siendo verdadera: el promedio muestral sí converge a $\mu$. Pero la tasa de convergencia ya no es $O(n^{-1/2})$ — es $O(n^{-(1-1/\alpha)})$. Para $\alpha = 1.5$, esto es $O(n^{-1/3})$: necesitas $n = 10^9$ para lograr lo que con varianza finita lograrías con $n = 1{,}000$.
Lo más peligroso: el intervalo de confianza que calculamos es una ilusión. El CLT no aplica cuando $\sigma^2 = \infty$. La fórmula $\hat{\mu}_n \pm 1.96 \cdot \hat{\sigma}/\sqrt{n}$ sigue produciendo un número, y ese número parece razonable. Pero no tiene la cobertura prometida del 95%. En la práctica, $\hat{\sigma}$ muestral es inestable — dominada por el valor extremo que haya aparecido en la muestra — y el IC real puede ser mucho más ancho de lo que indica.
Esto es exactamente el problema que llevó al colapso financiero de 2008: modelos que asumían varianza finita en distribuciones donde $1 < \alpha \leq 2$.
Caso 3: $\alpha \leq 1$ (Cauchy) — el promedio no converge a nada
La distribución de Cauchy tiene $\alpha = 1$: no tiene media ni varianza. Si $X_1, \ldots, X_n \sim \text{Cauchy}$, el promedio muestral $\hat{\mu}_n = \frac{1}{n}\sum X_i$ sigue siendo $\text{Cauchy}$ — exactamente igual que si tuviéramos una sola muestra. No hay ninguna ganancia al acumular más datos. El promedio nunca converge.
Intentar estimar $\mathbb{E}[f(X)]$ para un integrand con colas Cauchy o más pesadas es simplemente un error: $\mathbb{E}[f(X)]$ no existe.
¿Qué hacer en la práctica?
Antes de aplicar Monte Carlo, vale la pena preguntarse: ¿tiene mi función $f$ colas pesadas? Señales de alerta:
- Los estimados saltan drásticamente cada vez que cae un punto extremo
- $\hat{\sigma}$ muestral es muy inestable (no se estabiliza conforme crece $n$)
- El IC calculado cambia mucho de una corrida a otra con el mismo $n$
Si hay colas pesadas con $\sigma^2 < \infty$, las técnicas de reducción de varianza del Notebook 02 — especialmente importance sampling — pueden transformar el integrando en uno con colas más ligeras. Si $\sigma^2 = \infty$, el problema requiere una reformulación más profunda.
En el notebook a continuación hay un experimento interactivo para ver cómo se ve este fenómeno en la práctica.
Resumen
Problema: Calcular μ = E[f(X)], X ~ p
Estimador: μ̂ₙ = (1/n) Σ f(Xᵢ), Xᵢ i.i.d. ~ p
Garantía: LLN → μ̂ₙ →(c.s.) μ [supuesto: E[|f|] < ∞]
Precisión: CLT → error ∝ σ/√n [supuesto: Var[f] < ∞]
IC 95%: μ̂ₙ ± 1.96 · σ̂/√n
Cuadratura: error = O(n^{-2/d}) ← el exponente se divide por d
MC: error = O(n^{-1/2}) ← sin dependencia en d
Cruce: d = 4 (MC domina para d > 4)
Con esto en mano, pasemos al notebook donde todo esto cobra vida con código.