| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda (BFS, DFS e IDDFS en Python) |
Búsqueda en amplitud (BFS)
“The most important single aspect of software development is to be clear about what you are trying to build.” — Bjarne Stroustrup
BFS es busqueda_generica con frontera = ColaDeFrontera. Eso es todo. El resto de este capítulo es entender qué consecuencias tiene esa elección: exploración nivel a nivel, garantía de camino más corto, y un costo en memoria que puede ser alto.
1. Intuición: ondas en el agua
¿Para qué sirve BFS? Úsalo cuando necesitas el camino más corto entre dos puntos — el que tiene menos pasos, no el más rápido en tiempo ni el más barato en costo, sino el que pasa por menos aristas. Ejemplos concretos: encontrar cuántos clics separan dos páginas web, calcular los grados de separación entre dos personas en una red social, o encontrar la ruta con menos intersecciones en un mapa de calles.
La razón por la que BFS garantiza eso está en su estrategia de exploración. Imagina que lanzas una piedra a un estanque. Las ondas se expanden de forma concéntrica: primero el anillo a distancia 1, luego distancia 2, luego 3, etc. BFS funciona exactamente así.
Empezando desde el nodo inicial, BFS visita todos los nodos a distancia 1, luego todos a distancia 2, y así sucesivamente. Nunca avanza al nivel $k+1$ mientras queden nodos sin visitar en el nivel $k$.
La consecuencia directa: BFS siempre encuentra el camino más corto (en número de aristas) al nodo objetivo. El precio es la memoria: en el peor caso tiene que guardar todo un nivel antes de pasar al siguiente.
2. En lenguaje natural
La pregunta que BFS responde es: “¿cuál es el camino de menos pasos del nodo A al nodo B?” El truco es procesar siempre el nodo que lleva más tiempo esperando — así los nodos cercanos salen antes que los lejanos, y el primero que llega a la meta lo hace por el camino más corto.
- Crea una cola (FIFO) con el nodo inicial.
- Mientras la cola no esté vacía:
- Toma el nodo más antiguo de la cola (el primero en entrar).
- Si es la meta, reconstruye y devuelve el camino.
- Márcalo como explorado.
- Añade a la cola todos sus vecinos que no hayan sido explorados ni estén ya en la cola.
- Si la cola se vacía sin encontrar la meta, devuelve fallo.
La clave está en el paso 2.1: siempre procesamos el nodo más antiguo. Esto garantiza que los nodos más cercanos al inicio se procesan antes que los más lejanos.
3. Pseudocódigo (antes del ejemplo)
function BFS(problema):
# ── Initialization ─────────────────────────────────────────────────────
frontera ← new QueueFrontier() # cola FIFO vacía — el más antiguo sale primero
frontera.push(problema.inicio) # el nodo inicial es el primer pendiente
explorado ← empty set # nodos ya procesados completamente
padre ← { problema.inicio: null } # de dónde llegamos a cada nodo; inicio no tiene padre
# ── Main loop ──────────────────────────────────────────────────────────
while frontera is not empty:
nodo ← frontera.pop() # [L1] FIFO → saca el más ANTIGUO de la cola
# ← aquí está la diferencia con DFS (que usa LIFO)
if problema.is_goal(nodo): # [L2] ¿es este nodo la meta?
return reconstruct(padre, nodo) # sí → seguir padres hacia atrás para obtener el camino
explorado.add(nodo) # [L3] marcar como procesado — no volver a expandirlo
for each vecino in problema.neighbors(nodo): # [L4] mirar todos los nodos conectados a nodo
if vecino not in explorado # condición 1: ¿ya lo procesamos? → ignorar
and vecino not in frontera: # condición 2: ¿ya está pendiente? → no duplicar
padre[vecino] ← nodo # registrar: "llegué a vecino viniendo desde nodo"
frontera.push(vecino) # [L5] añadirlo a la cola de pendientes
return FAILURE # cola vacía sin encontrar meta → no hay solución
Referencia rápida: las etiquetas [L1]–[L5] aparecerán en la tabla del ejemplo paso a paso a continuación.
4. Ejemplo paso a paso
Usamos el mismo grafo de 6 nodos que veremos en todos los algoritmos de este módulo. El grafo es:
A — B — D
| | |
C — E — F
|
(F)
Más precisamente: aristas ${A,B}, {A,C}, {B,D}, {B,E}, {C,E}, {D,F}, {E,F}$. Buscamos F desde A. Los vecinos se procesan en orden alfabético.
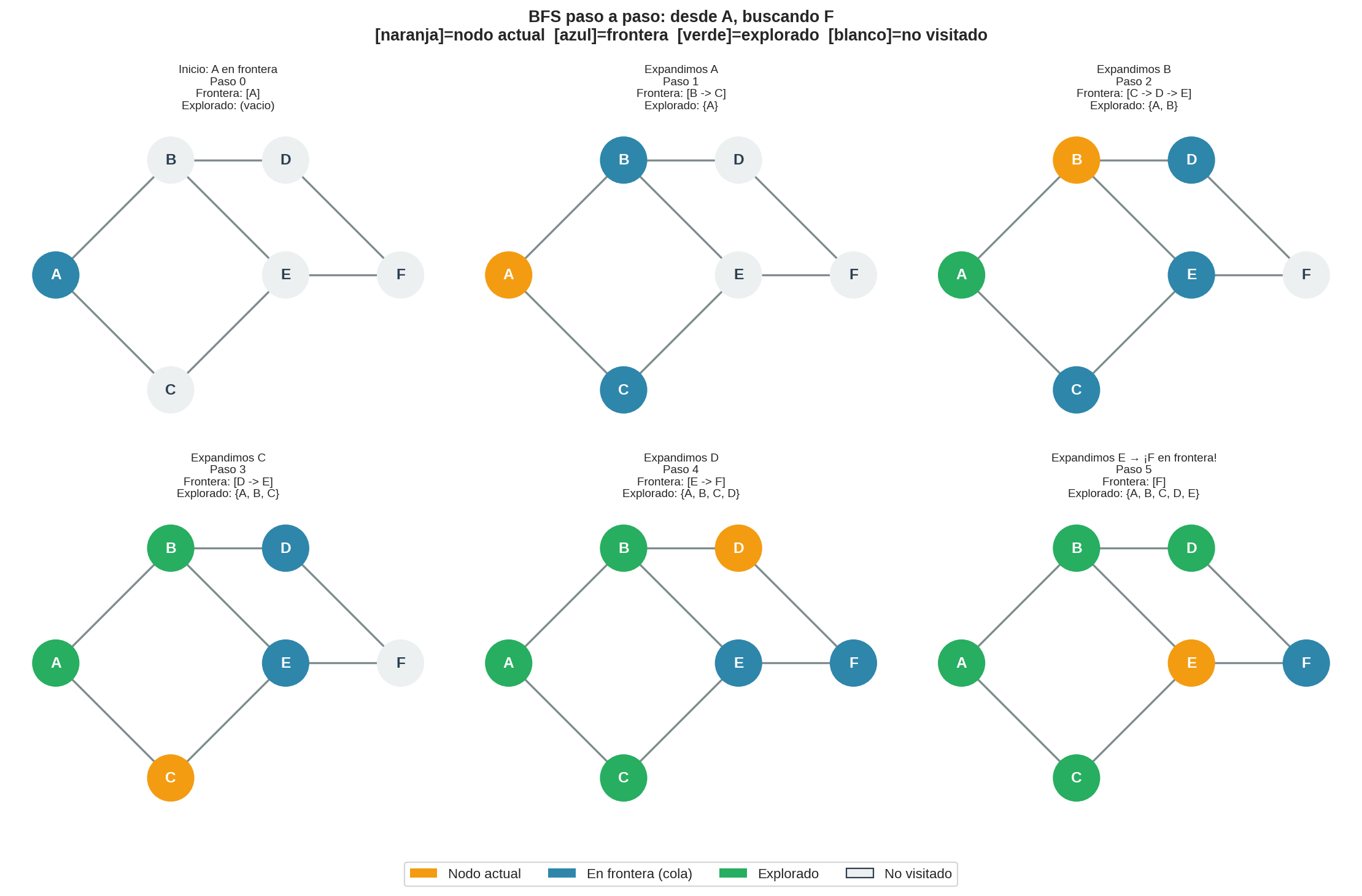
Cada panel muestra el estado después de ejecutar la iteración correspondiente:
| Paso | Nodo actual | Frontera (cola, FIFO) | Explorado | Qué pasó |
|---|---|---|---|---|
| 0 | — | [A] |
{} |
Inicialización. A entra a la cola. |
| 1 | A | [B, C] |
{A} |
L1: pop A. L2: A no es meta. L3: A → explorado. L4-L5: vecinos B, C se encolan. |
| 2 | B | [C, D, E] |
{A, B} |
L1: pop B (el más antiguo). L4-L5: D y E se encolan. C ya está en frontera, no se duplica. |
| 3 | C | [D, E] |
{A, B, C} |
L1: pop C. L4: vecino E ya está en frontera — no se añade. |
| 4 | D | [E, F] |
{A, B, C, D} |
L1: pop D. L5: F entra a la cola. |
| 5 | E | [F] |
{A, B, C, D, E} |
L1: pop E. F ya está en frontera. |
| — | F | — | — | L1: pop F. L2: F es la meta. Reconstruir camino. |
Camino encontrado: A → B → D → F (longitud 3).
¿Existe un camino más corto? No: la menor distancia de A a F es 3. BFS lo encontró.
Ambos son caminos óptimos de longitud 3. BFS devuelve uno de ellos — el que encontró primero, que depende del orden en que se procesan los vecinos. Si necesitas todos los caminos óptimos, hay una extensión de BFS para eso, pero no es necesaria aquí.
5. Visualización de niveles
La expansión por niveles queda más clara en esta vista:
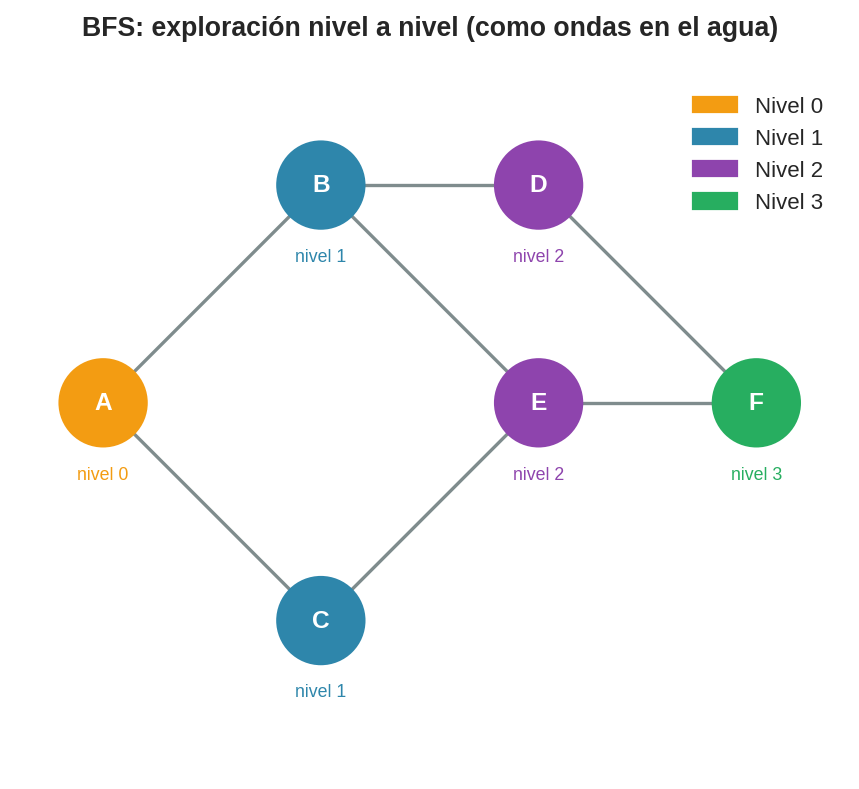
- Nivel 0:
{A}— el nodo inicial. - Nivel 1:
{B, C}— nodos a distancia 1 de A. - Nivel 2:
{D, E}— nodos a distancia 2 de A. - Nivel 3:
{F}— el objetivo, a distancia 3 de A.
6. Implementación Python
from collections import deque
class ColaDeFrontera(Frontera):
"""Frontera tipo cola (FIFO). Produce BFS cuando se usa con busqueda_generica."""
def __init__(self):
self.cola = deque() # O(1) en ambos extremos
self.miembros = set() # para contains en O(1)
def push(self, nodo, padre=None):
# padre se ignora — BFS no necesita rastrear profundidad
self.cola.append(nodo)
self.miembros.add(nodo)
def pop(self):
nodo = self.cola.popleft() # ← FIFO: el más antiguo primero
self.miembros.discard(nodo)
return nodo
def contains(self, nodo):
return nodo in self.miembros
def is_empty(self):
return len(self.cola) == 0
# BFS es una sola línea — todo el trabajo lo hace busqueda_generica
def bfs(problema):
return busqueda_generica(problema, ColaDeFrontera())
Nota: popleft() de deque es $O(1)$. Si usáramos una lista Python ordinaria, pop(0) es $O(n)$ porque desplaza todos los elementos. Siempre usa deque para colas.
7. Complejidad de tiempo y espacio
Tiempo: $O(b^d)$
Cada nodo entra a la frontera a lo sumo una vez (gracias al conjunto explorado y la verificación de frontera). Cada vez que procesamos un nodo, revisamos todas sus aristas. En términos del factor de ramificación $b$ (número máximo de vecinos de cualquier nodo) y la profundidad de la solución $d$:
$$T_{\text{BFS}} = O(b^d)$$
Esto es porque BFS explora nivel a nivel: el nivel 0 tiene 1 nodo, el nivel 1 tiene a lo sumo $b$, el nivel 2 tiene a lo sumo $b^2$, …, el nivel $d$ tiene a lo sumo $b^d$. El total es $1 + b + b^2 + \cdots + b^d = O(b^d)$ — dominado por el último nivel.
Nota sobre $b$ máximo vs. promedio: con $b = b_{max}$ esta es una cota de peor caso. Si el grafo es irregular y la mayoría de nodos tienen menos de $b_{max}$ vecinos, el número real de nodos explorados será menor — pero $O(b^d)$ sigue siendo válido como garantía superior.
Espacio: $O(b^d)$ — el verdadero cuello de botella de BFS
Este es el problema serio de BFS, y vale la pena entenderlo bien porque motivará directamente el diseño de IDDFS.
¿Por qué la cola crece hasta $O(b^d)$? BFS nunca descarta los nodos de la cola hasta procesarlos. Para avanzar del nivel $k$ al nivel $k+1$, necesita tener todos los nodos de nivel $k$ simultáneamente en la cola — de lo contrario, no podría saber que ya terminó ese nivel y podría emitir vecinos fuera de orden.
Al final del nivel $k$, la cola contiene todos los nodos del nivel $k$ (esperando ser procesados) más los del nivel $k+1$ ya descubiertos. En el peor momento — al terminar el nivel $d-1$ — la cola tiene:
| Nivel | Nodos en la cola simultáneamente |
|---|---|
| 0 → 1 | $b$ nodos (hijos de la raíz) |
| 1 → 2 | $b^2$ nodos |
| 2 → 3 | $b^3$ nodos |
| $d-1$ → $d$ | $b^d$ nodos ← pico de memoria |
$$S_{\text{BFS}} = O(b^d)$$
Esto no es un detalle menor. Con $b = 10$ y $d = 6$ (una búsqueda moderadamente profunda):
| $d$ | Nodos en la cola | Memoria aprox. (32 bytes/nodo) |
|---|---|---|
| 2 | $100$ | $3\ \text{KB}$ |
| 4 | $10{,}000$ | $320\ \text{KB}$ |
| 6 | $1{,}000{,}000$ | $32\ \text{MB}$ |
| 8 | $100{,}000{,}000$ | $3.2\ \text{GB}$ |
| 10 | $10{,}000{,}000{,}000$ | $320\ \text{GB}$ |
A profundidad 8, BFS ya requiere gigabytes. A profundidad 10, necesita más RAM de la que existe en la mayoría de los servidores. El espacio es la razón por la que BFS no escala — y es exactamente lo que IDDFS resolverá.
8. Completitud y optimalidad
Completitud
BFS es completo: si existe una solución en un grafo finito, BFS la encontrará.
Demostración (por construcción): BFS explora los nodos por niveles crecientes. Si la meta está a profundidad $d$, BFS la alcanzará al procesar todos los nodos del nivel $d$. Dado que el grafo es finito, esto siempre ocurre en tiempo finito.
Optimalidad
BFS es óptimo para grafos sin pesos (o con todos los pesos iguales): siempre encuentra el camino con menor número de aristas.
Demostración (sketch): BFS expande los nodos en orden no-decreciente de distancia desde el inicio. Cuando un nodo $n$ es extraído de la cola, todos los nodos a menor distancia ya han sido extraídos antes. Por lo tanto, la primera vez que BFS alcanza la meta, lo hace por el camino más corto.
Si queremos minimizar la suma de pesos (no solo el número de aristas), BFS ya no es óptimo. Por ejemplo: si hay un camino directo con peso 100 y un camino largo con suma 10, BFS encontraría el camino largo (más aristas) pero más barato. Para pesos arbitrarios se necesita búsqueda de costo uniforme (Dijkstra), que veremos en el módulo de búsqueda informada.
9. Aplicaciones de BFS
Flood fill: coloreando regiones de píxeles
Una de las aplicaciones más visuales y concretas de BFS es el flood fill — el algoritmo que usa Paint cuando rellenas una región con un color.
Dado un pixel semilla, queremos colorear todos los píxeles conectados del mismo color original.
Formulación:
- Nodos: píxeles $(r, c)$ con el color de la semilla
- Aristas: entre píxeles adyacentes (4-vecinos) del mismo color
- Meta: no hay — queremos encontrar todos los nodos alcanzables
BFS desde la semilla visita exactamente la componente conexa del mismo color.
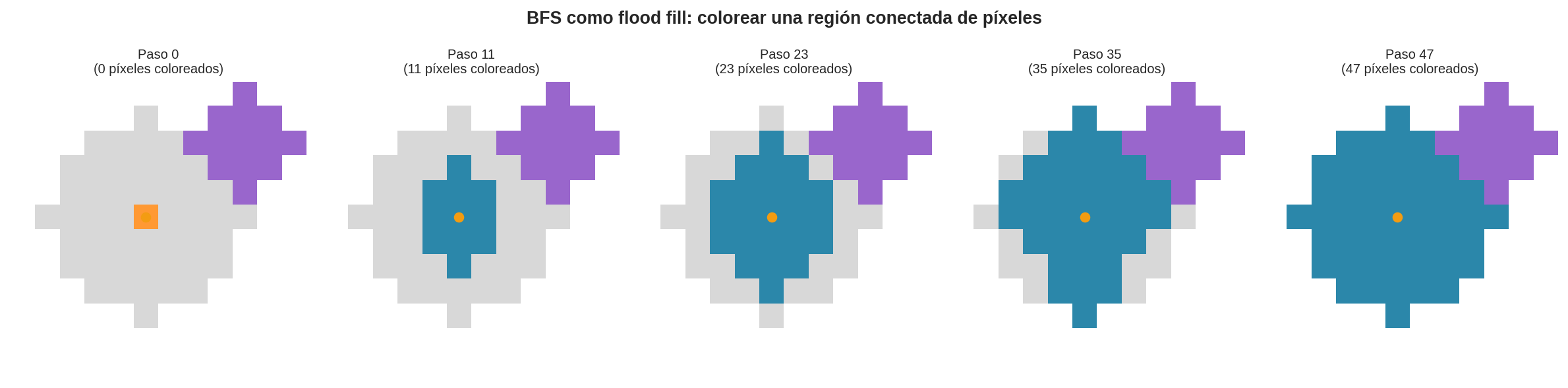
El círculo naranja marca el pixel semilla. BFS expande la región coloreada (azul) nivel a nivel. La región morada (arriba a la derecha) no es alcanzable desde la semilla porque está aislada.
Grados de separación en redes sociales
El famoso “6 grados de separación” es un problema de BFS: dado un nodo en un grafo social, ¿cuál es la distancia mínima a otro nodo? BFS desde el nodo inicial da la distancia exacta a todos los nodos alcanzables.
Camino más corto en redes no ponderadas
En mapas de cuadrículas (videojuegos, robótica), BFS da el camino mínimo en número de pasos. La propiedad es exactamente la que probamos: BFS garantiza encontrar el camino con menos aristas.
Resumen de BFS
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Cola (FIFO) | Nodo más antiguo primero |
| Tiempo | $O(b^d)$ | Explora todos los nodos hasta prof. $d$ |
| Espacio | $O(b^d)$ | La cola debe guardar todo el nivel $d$ simultáneamente |
| Completo | Sí | Explora exhaustivamente nivel a nivel |
| Óptimo | Sí (sin pesos) | Expande nodos en orden no-decreciente de distancia |
Recordatorio de notación: $b$ = factor de ramificación (máximo de vecinos por nodo; peor caso), $d$ = profundidad de la solución, $m$ = profundidad máxima del grafo. Definidos en 03 — Algoritmo genérico →.
Siguiente: Búsqueda en profundidad (DFS) →