| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda (BFS, DFS e IDDFS en Python) |
Búsqueda en profundidad (DFS)
“In order to understand recursion, one must first understand recursion.”
DFS es busqueda_generica con frontera = PilaDeFrontera. La diferencia respecto a BFS es exactamente una línea: en lugar de popleft() (FIFO), usamos pop() (LIFO). Esta pequeña diferencia produce un comportamiento radicalmente distinto.
1. Intuición: explorar hasta el fondo antes de volver
¿Para qué sirve DFS? Úsalo cuando quieres explorar exhaustivamente — no te importa encontrar el camino más corto, sino encontrar algún camino, o explorar todas las posibilidades, o verificar si algo existe. Ejemplos concretos: listar todos los archivos dentro de una carpeta (y sus subcarpetas, y las subcarpetas de las subcarpetas…), resolver un Sudoku probando combinaciones y deshaciendo cuando llegas a una contradicción, o calcular el orden en que instalar dependencias de software. En todos estos casos lo que importa es ir hasta el fondo de una posibilidad antes de considerar la siguiente.
La estrategia es directa: imagina que estás explorando un laberinto. DFS dice: siempre avanza por el pasillo más reciente que descubriste. Si llegas a un callejón sin salida, retrocede (backtrack) al punto donde tomaste el último desvío y prueba el siguiente pasillo.
DFS va tan profundo como puede en una rama antes de considerar ramas alternativas. El resultado: puede encontrar la solución rápido si está en la rama que elige primero, o puede explorar muchos caminos muertos antes de encontrarla si eligió mal. Pero su gran ventaja es la memoria: solo necesita recordar el camino actual, no todo el grafo explorado hasta el momento.
El término backtracking describe un ciclo de tres pasos que DFS repite continuamente:
- Tomar una decisión — elige un vecino y avanza hacia él.
- Explorar hasta el fondo — sigue tomando decisiones hasta que encuentras la meta o detectas que no hay salida.
- Deshacer y volver — si fallaste, retrocede (backtrack) al punto donde tomaste la última decisión y elige la siguiente opción disponible.
Ejemplo concreto: buscar una sala en un edificio desconocido.
Llegas a un edificio nuevo buscando la sala 204. No tienes mapa. Solo puedes entrar por un pasillo a la vez.
Edificio (vista de planta):
Entrada
│
Pasillo A ──── Pasillo B ──── Sala 101 (callejón sin salida)
│
Pasillo C ──── Sala 204 ← meta
│
Sala 300 (callejón sin salida)
Así funciona DFS con backtracking:
Decisión 1: tomas el Pasillo A.
Decisión 2: desde A, eliges Pasillo B.
Decisión 3: desde B, llegas a Sala 101. No es la 204 y no hay más salidas.
→ BACKTRACK: vuelves al Pasillo B. No quedan opciones. Vuelves al Pasillo A.
Decisión 4: desde A, ahora eliges Pasillo C (el único que no probaste).
Decisión 5: desde C, llegas a Sala 204. ¡Encontrada!
En cada retroceso deshiciste exactamente una decisión — no tiraste todo el recorrido, solo volviste un paso atrás. Eso es backtracking: la memoria solo guarda el camino que estás explorando en este momento, no todos los caminos posibles.
El punto clave: “backtrack” no es un algoritmo separado — es simplemente DFS aplicado a un espacio de decisiones. El retroceso ocurre naturalmente cuando la pila hace pop() de un nodo sin salida: automáticamente volvemos al nodo padre, que tiene otros vecinos sin explorar.
En la versión iterativa esto es literal — un pop() de la pila. En la versión recursiva lo hace Python por nosotros: cuando una llamada recursiva devuelve None (fallo), la función anterior sigue con el siguiente vecino en su for.
¿Por qué DFS es natural para backtracking? Porque mantiene exactamente la información que necesitas: el camino activo desde el inicio hasta el nodo actual. BFS, en cambio, tiene muchos caminos parciales en vuelo simultáneamente — es mucho más difícil «deshacer» una decisión.
2. En lenguaje natural
La pregunta que DFS responde es: “¿existe algún camino del nodo A al nodo B, y si es así cuál?” (o más generalmente: “¿qué nodos puedo alcanzar desde A?”). No se preocupa por si es el más corto — eso es trabajo de BFS. El truco es procesar siempre el nodo que llegó más recientemente a la frontera, lo que hace que el algoritmo se entierre en una rama antes de probar otras.
- Crea una pila (LIFO) con el nodo inicial.
- Mientras la pila no esté vacía:
- Toma el nodo más reciente de la pila (el último en entrar).
- Si es la meta, reconstruye y devuelve el camino.
- Márcalo como explorado.
- Añade a la pila todos sus vecinos que no hayan sido explorados ni estén ya en la pila.
- Si la pila se vacía sin encontrar la meta, devuelve fallo.
La diferencia con BFS está en el paso 2.1: el más reciente, no el más antiguo. Esto hace que DFS “se entierre” en la rama más nueva antes de retroceder.
3. Pseudocódigo (antes del ejemplo)
function DFS(problema):
# ── Initialization ─────────────────────────────────────────────────────
frontera ← new StackFrontier() # pila LIFO vacía — el más reciente sale primero
frontera.push(problema.inicio) # el nodo inicial es el primer pendiente
explorado ← empty set # nodos ya procesados completamente
padre ← { problema.inicio: null } # de dónde llegamos a cada nodo; inicio no tiene padre
# ── Main loop ──────────────────────────────────────────────────────────
while frontera is not empty:
nodo ← frontera.pop() # [L1] LIFO → saca el más RECIENTE de la pila
# ← única diferencia con BFS (que usa FIFO)
if problema.is_goal(nodo): # [L2] ¿es este nodo la meta?
return reconstruct(padre, nodo) # sí → seguir padres hacia atrás para obtener el camino
explorado.add(nodo) # [L3] marcar como procesado — no volver a expandirlo
for each vecino in problema.neighbors(nodo): # [L4] mirar todos los nodos conectados a nodo
if vecino not in explorado # condición 1: ¿ya lo procesamos? → ignorar
and vecino not in frontera: # condición 2: ¿ya está pendiente? → no duplicar
padre[vecino] ← nodo # registrar: "llegué a vecino viniendo desde nodo"
frontera.push(vecino) # [L5] añadirlo a la pila de pendientes
return FAILURE # pila vacía sin encontrar meta → no hay solución
Compara con el pseudocódigo de BFS: la única diferencia es [L1] — pop() saca el más reciente (LIFO) en vez del más antiguo (FIFO). Todo lo demás es línea por línea idéntico.
4. Ejemplo paso a paso
Usamos el mismo grafo de 6 nodos. Recordemos: ${A,B}, {A,C}, {B,D}, {B,E}, {C,E}, {D,F}, {E,F}$. Buscamos F desde A. Los vecinos se ordenan alfabéticamente, pero al apilarlos en orden alfabético, el primero en entrar es el último en salir — así que B estará encima de C.
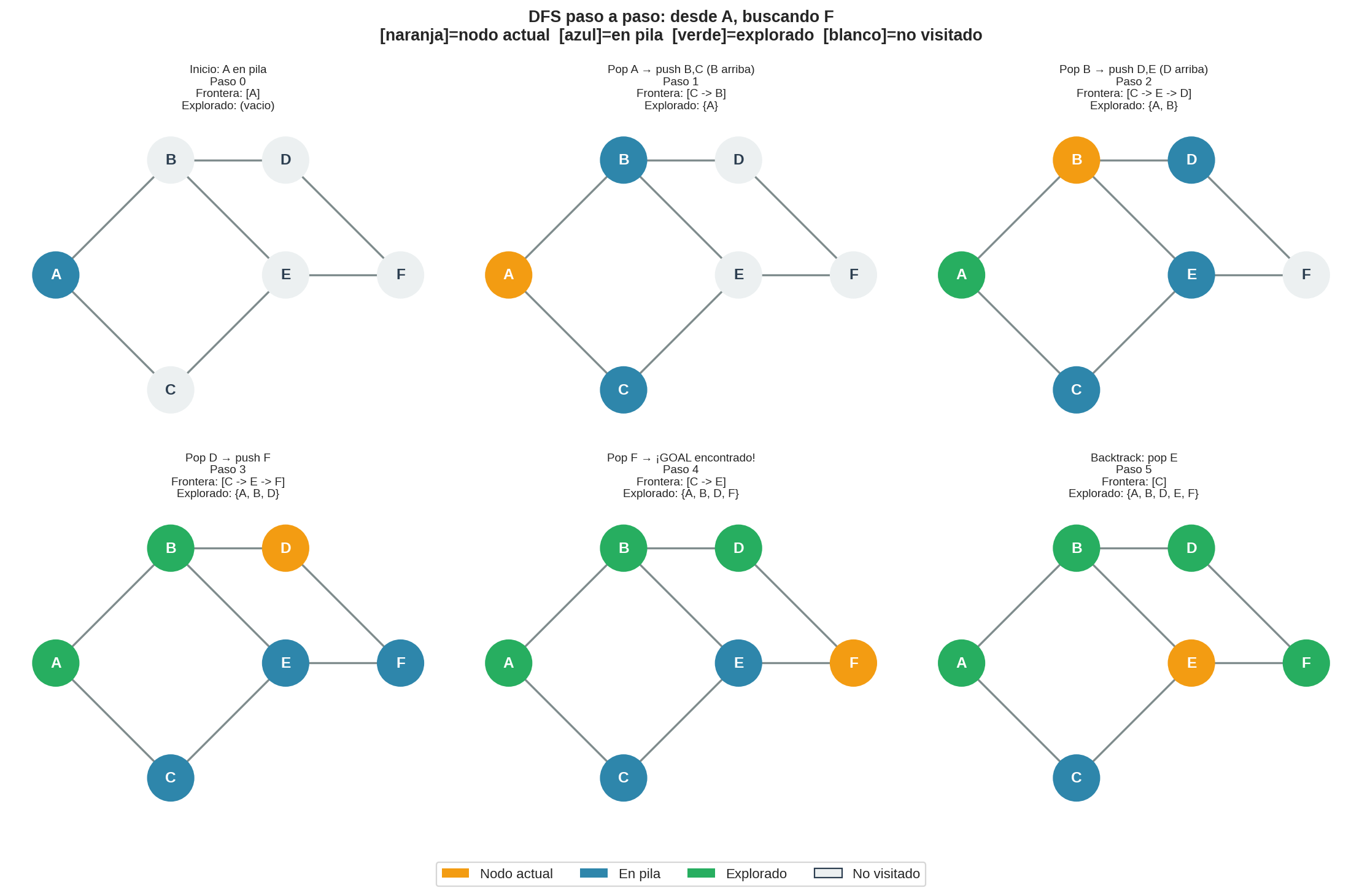
| Paso | Nodo actual | Pila (tope a la derecha) | Explorado | Qué pasó |
|---|---|---|---|---|
| 0 | — | [A] |
{} |
Inicialización. |
| 1 | A | [C, B] |
{A} |
L1: pop A. L4-L5: push C, luego B. B queda en tope. |
| 2 | B | [C, E, D] |
{A, B} |
L1: pop B (tope). L4-L5: push E, luego D. D queda en tope. |
| 3 | D | [C, E, F] |
{A, B, D} |
L1: pop D. L5: push F. |
| 4 | F | — | — | L1: pop F. L2: F es la meta. ¡Encontrado! |
Camino encontrado: A → B → D → F (longitud 3).
En este caso particular, DFS encontró el mismo camino óptimo que BFS. Eso es coincidencia — DFS no garantiza optimalidad.
Modifica el grafo: añade la arista ${A, F}$ directamente. Ahora el camino óptimo es A → F (longitud 1). BFS lo encontraría de inmediato (F está en el nivel 1). DFS, si explora B antes que F, se iría por la rama A → B → D → F y devolvería un camino de longitud 3 — no el óptimo.
5. DFS y la recursión
Hemos visto DFS como busqueda_generica con una PilaDeFrontera. Pero hay otra forma de escribir exactamente el mismo algoritmo que muchos programadores encuentran aún más natural: la versión recursiva. Antes de ver el código, conviene entender por qué la recursión aparece aquí de forma tan natural.
La idea: la pila ya existe — es el call stack
Cuando una función se llama a sí misma en Python, el intérprete guarda el estado de la llamada actual (variables locales, punto de retorno) en una estructura interna llamada call stack o pila de llamadas. Esa pila crece cuando hacemos una llamada recursiva y decrece cuando retornamos.
¿Suena familiar? Es exactamente lo que hace PilaDeFrontera. En la versión iterativa nosotros construimos y gestionamos la pila explícitamente. En la versión recursiva dejamos que Python lo haga por nosotros usando su propio call stack. La pila del sistema es la frontera de DFS — no es una metáfora, es literalmente la misma estructura.
¿Cómo difiere del algoritmo genérico?
La versión recursiva no es busqueda_generica con una frontera distinta. Es una reorganización del mismo comportamiento que elimina la frontera explícita y el bucle while, sustituyéndolos por el mecanismo de llamada y retorno del propio lenguaje. Lo que cambia:
busqueda_generica + PilaDeFrontera |
dfs_recursivo |
|---|---|
Bucle while que saca de la pila |
Llamada recursiva que avanza un nivel |
push añade a la pila explícita |
La propia llamada apila el estado |
pop retira de la pila explícita |
El return desapila el estado |
frontera.contains(vecino) evita duplicados |
No hay frontera; solo se revisa explorado |
Nota que la versión recursiva no chequea si el vecino está “en la frontera” antes de añadirlo — simplemente comprueba explorado. Esto es seguro porque la recursión nunca tiene varios caminos al mismo nodo en cola al mismo tiempo: siempre estamos en un único camino y retrocedemos por él.
El código, línea a línea
def dfs_recursivo(problema, nodo, explorado, padre):
# Caso base 1: llegamos a la meta → reconstruir y devolver el camino
if problema.es_meta(nodo):
return reconstruir_camino(padre, nodo)
# Marcar nodo como explorado antes de visitar vecinos
explorado.add(nodo)
for vecino in problema.vecinos(nodo):
if vecino not in explorado: # ¿ya lo procesamos? → saltar
padre[vecino] = nodo # registrar de dónde venimos
resultado = dfs_recursivo(problema, vecino, explorado, padre)
# ↑ aquí ocurre el "push": Python apila el estado actual
# y empieza a procesar el vecino desde cero
if resultado is not None: # ¿el vecino (o algún descendiente) encontró la meta?
return resultado # propagar hacia arriba: "desapilar con éxito"
# Caso base 2: ningún vecino llevó a la meta → backtrack
return None
# ↑ este return hace pop implícito: Python restaura el estado de quien nos llamó
# y continuará con el siguiente vecino en el bucle for de arriba
Traza en el grafo de ejemplo
Usando el mismo grafo $A-B-D-F$ de las secciones anteriores, la recursión funciona así:
dfs_recursivo(A) ← "apilar A"
dfs_recursivo(B) ← "apilar B" (primer vecino no explorado de A)
dfs_recursivo(D) ← "apilar D"
dfs_recursivo(F) ← "apilar F"
F es la meta → return camino ← "desapilar con éxito"
← propaga resultado
← propaga resultado
← propaga resultado
← devuelve camino: [A, B, D, F]
Cada nivel de indentación es un frame en el call stack. La profundidad máxima de la recursión es exactamente la profundidad máxima del grafo — lo mismo que el tamaño máximo de PilaDeFrontera.
Versión iterativa vs. recursiva
Ambas implementaciones son equivalentes en comportamiento. La elección es práctica:
| Recursiva | Iterativa (PilaDeFrontera) |
|
|---|---|---|
| Claridad | Muy concisa, expresa la idea directamente | Más explícita, más cercana al algoritmo genérico |
| Riesgo | Stack overflow en grafos muy profundos (límite ~1000 frames en Python) | Sin límite de profundidad (solo memoria del heap) |
| Generalización | Difícil de convertir en busqueda_generica |
Encaja directamente en el framework |
En este módulo usamos la versión iterativa porque encaja en busqueda_generica y evita el riesgo de desbordamiento. La versión recursiva es útil para entender la intuición y para grafos que se sabe que son poco profundos.
6. Comparación directa: BFS vs DFS en el mismo grafo
La diferencia de comportamiento queda clara viendo los árboles de búsqueda que genera cada algoritmo:
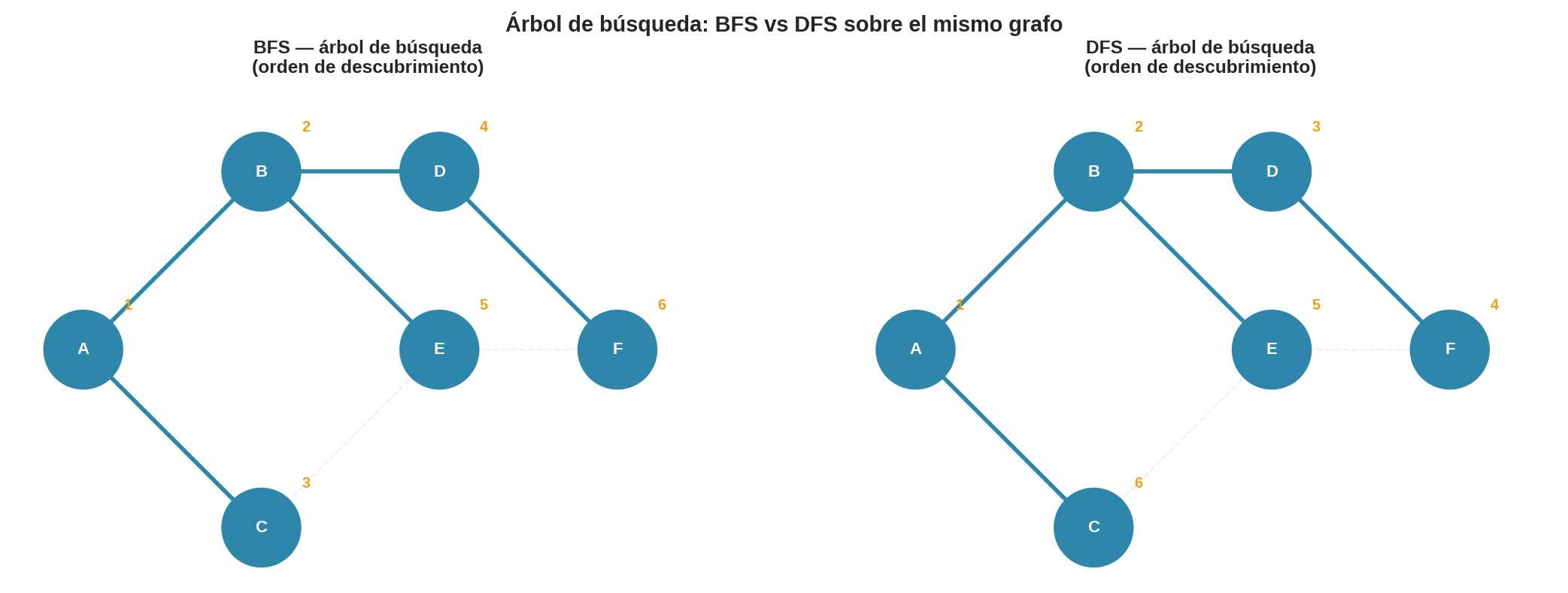
Los números junto a cada nodo indican el orden de descubrimiento.
- BFS descubre A(1), B(2), C(3), D(4), E(5), F(6) — nivel a nivel.
- DFS descubre A(1), B(2), D(3), F(4), E(5), C(6) — se hunde primero por B→D→F.
7. Implementación Python
class PilaDeFrontera(Frontera):
"""Frontera tipo pila (LIFO). Produce DFS cuando se usa con busqueda_generica."""
def __init__(self):
self.pila = [] # lista Python — O(1) para append/pop
self.miembros = set() # para contains en O(1)
def push(self, nodo, padre=None):
# padre se ignora — DFS básico no rastrea profundidad
self.pila.append(nodo)
self.miembros.add(nodo)
def pop(self):
nodo = self.pila.pop() # ← LIFO: el más reciente primero
self.miembros.discard(nodo)
return nodo
def contains(self, nodo):
return nodo in self.miembros
def is_empty(self):
return len(self.pila) == 0
def dfs(problema):
return busqueda_generica(problema, PilaDeFrontera())
Comparación directa con ColaDeFrontera:
ColaDeFrontera (BFS) |
PilaDeFrontera (DFS) |
|---|---|
self.cola = deque() |
self.pila = [] |
self.cola.append(nodo) |
self.pila.append(nodo) |
self.cola.popleft() ← FIFO |
self.pila.pop() ← LIFO |
Eso es todo. Una línea diferente produce un algoritmo completamente distinto.
8. Complejidad de tiempo y espacio
Tiempo: $O(b^m)$
Al igual que BFS, cada nodo entra y sale de la frontera a lo sumo una vez: $O(V + E)$.
En términos del factor de ramificación $b$ (número máximo de vecinos de cualquier nodo) y $m$ (profundidad máxima del grafo):
$$T_{\text{DFS}} = O(b^m)$$
En el peor caso, DFS puede explorar hasta $b^m$ nodos — el árbol completo hasta profundidad $m$ — antes de encontrar (o no encontrar) la solución. Cada nodo tiene a lo sumo $b$ vecinos, y hay a lo sumo $m$ niveles.
Nota sobre $b$ máximo vs. promedio: con $b = b_{max}$ esta es una cota de peor caso. Si el grafo es irregular y la mayoría de nodos tienen menos de $b_{max}$ vecinos, el número real de nodos explorados será menor — pero $O(b^m)$ sigue siendo válido como garantía superior.
Nota importante: si $m \gg d$ (la profundidad máxima es mucho mayor que la profundidad de la solución), DFS puede ser mucho más lento que BFS en el peor caso. BFS garantiza no explorar más allá del nivel $d$; DFS puede bajar hasta el fondo del grafo antes de encontrar la solución.
Espacio: $O(bm)$ — la gran ventaja de DFS frente a BFS
Esta es la diferencia más importante entre DFS y BFS, y vale la pena entenderla con precisión.
¿Por qué la pila de DFS solo necesita $O(bm)$? En cualquier momento, la pila contiene únicamente:
- El camino activo: los nodos desde la raíz hasta el nodo que se está expandiendo ahora — como máximo $m$ nodos (uno por nivel).
- Los hermanos pendientes de cada nodo en el camino: los vecinos que aún no se han explorado. En cada nivel hay como máximo $b-1$ hermanos pendientes ($b$ = número máximo de vecinos).
En total: $(b-1) \times m + 1 \approx b \times m$ nodos. En cualquier instante, la pila tiene esta forma:
Pila DFS en un grafo con b=3, m=4:
[raíz, hermano1_de_raíz, hermano2_de_raíz, ← nivel 0: hasta b-1 hermanos
hijo_activo, hermano1, hermano2, ← nivel 1: hasta b-1 hermanos
nieto_activo, hermano1, ← nivel 2: hasta b-1 hermanos
bisnieto_activo] ← nivel 3: nodo actual, sin hermanos aún
El punto clave: DFS nunca necesita guardar todos los nodos del mismo nivel. Cuando baja al nivel $k+1$, los nodos del nivel $k$ que no son el padre activo ya no están en la pila.
$$S_{\text{DFS}} = O(bm)$$
Comparación directa con BFS para $b = 10$, $d = m$:
| $d$ | BFS: cola en pico | DFS: pila máxima | Factor de diferencia |
|---|---|---|---|
| 2 | $100$ nodos | $20$ nodos | $5\times$ |
| 4 | $10{,}000$ nodos | $40$ nodos | $250\times$ |
| 6 | $1{,}000{,}000$ nodos | $60$ nodos | $16{,}666\times$ |
| 8 | $10^8$ nodos | $80$ nodos | $1{,}250{,}000\times$ |
| 10 | $10^{10}$ nodos | $100$ nodos | $100{,}000{,}000\times$ |
DFS usa órdenes de magnitud menos memoria que BFS. A profundidad 10, BFS necesita ~320 GB de RAM; DFS necesita apenas unos kilobytes. Esta es la ventaja principal de DFS — y la razón de ser de IDDFS, que tomará exactamente esta propiedad y la combinará con las garantías de BFS.
9. Completitud y optimalidad
Completitud: depende del grafo
En grafos finitos con conjunto explorado: DFS es completo. El conjunto explorado previene que el algoritmo entre en bucles infinitos.
Sin conjunto explorado en grafos con ciclos: DFS puede entrar en un bucle infinito y nunca encontrar la solución, aunque exista.
En grafos infinitos: DFS puede seguir bajando por una rama infinita y nunca volver. No es completo en este caso.
Optimalidad: no
DFS no es óptimo. Puede encontrar un camino largo antes de descubrir uno corto, simplemente porque exploró esa rama primero. En el ejemplo de la sección 4, si se añade una arista directa ${A,F}$, DFS podría devolverla camino de longitud 3 en vez de 1.
10. Aplicaciones de DFS
Encontrar componentes conexas
Imagina que tienes un grafo desconectado — por ejemplo, una red de ciudades donde algunas ciudades no tienen carretera entre sí. Quieres saber cuántos grupos de ciudades existen y cuáles pertenecen a cada grupo. Eso es encontrar las componentes conexas: los subgrafos dentro de los cuales puedes moverte entre cualquier par de nodos.
La idea es simple: arranca DFS desde cualquier nodo sin visitar. DFS llegará a exactamente todos los nodos que son alcanzables desde ahí — eso es una componente. Luego busca el siguiente nodo que todavía no hayas visitado y repite. Cada DFS nuevo descubre una componente distinta.
¿Cómo se relaciona con busqueda_generica?
Esta función no usa busqueda_generica porque el objetivo es distinto: aquí no buscamos una meta, queremos recorrer todo el grafo. Pero el mecanismo interno del DFS por componente es idéntico al de PilaDeFrontera: una pila local, pop() para sacar el nodo más reciente, y un set de visitados para no repetir. La diferencia es que en lugar de parar al encontrar la meta, continuamos hasta que la pila se vacía — y entonces sabemos que terminamos una componente.
busqueda_generica + PilaDeFrontera |
componentes_conexas (DFS interno) |
|---|---|
| Busca un nodo meta específico | Recorre todos los nodos alcanzables |
| Para al encontrar la meta | Para cuando la pila se vacía |
| Devuelve un camino | Devuelve la lista de nodos de la componente |
| Un solo DFS | Un DFS por componente, en bucle externo |
El código, línea a línea
def componentes_conexas(grafo):
visitado = set() # nodos ya asignados a alguna componente — nunca volver a ellos
componentes = [] # lista de listas: cada sublista es una componente
for nodo in grafo: # recorremos todos los nodos del grafo
if nodo not in visitado: # ¿ya lo procesamos? → pertenece a una componente anterior, saltar
# si no fue visitado → es el punto de entrada de una nueva componente
componente = [] # acumular nodos de esta componente
pila = [nodo] # ← inicio del DFS: la pila con el nodo semilla
while pila: # mientras queden nodos pendientes en esta componente
v = pila.pop() # sacar el más reciente — LIFO, igual que PilaDeFrontera
if v not in visitado: # puede que v fue añadido a la pila varias veces antes de procesarse
visitado.add(v) # marcarlo como procesado
componente.append(v) # registrar que pertenece a esta componente
for vecino in grafo[v]:
if vecino not in visitado: # solo añadir vecinos no visitados
pila.append(vecino) # ← "push": exploraremos este vecino luego
componentes.append(componente) # DFS terminó: guardamos la componente completa
return componentes # lista de todas las componentes encontradas
Traza en un ejemplo
Supón el grafo: ${A-B, B-C, D-E}$ — dos componentes: ${A,B,C}$ y ${D,E}$.
Iteración 1 (nodo=A, no visitado):
pila=[A]
pop A → visitado={A}, componente=[A], push B
pila=[B]
pop B → visitado={A,B}, componente=[A,B], push A (ignorado), push C
pila=[C]
pop C → visitado={A,B,C}, componente=[A,B,C], sin vecinos nuevos
pila=[] → componentes=[[A,B,C]]
Iteración 2 (nodo=B, ya visitado → saltar)
Iteración 3 (nodo=C, ya visitado → saltar)
Iteración 4 (nodo=D, no visitado):
pila=[D]
pop D → visitado={A,B,C,D}, componente=[D], push E
pop E → visitado={A,B,C,D,E}, componente=[D,E]
pila=[] → componentes=[[A,B,C],[D,E]]
El bucle externo garantiza que ningún nodo quede sin clasificar, aunque el grafo esté completamente desconectado.
Exploración de sistemas de archivos
Una de las aplicaciones más cotidianas de DFS es recorrer un árbol de directorios — lo que hace el comando find en Linux, o os.walk en Python. Cuando pides “lista todos los archivos dentro de esta carpeta”, el sistema entra en la primera subcarpeta, luego en la primera subcarpeta de esa, y así hasta llegar a un directorio sin más subdirectorios. Solo entonces retrocede y explora el siguiente hermano. Eso es DFS.
Considera este árbol de directorios:
proyecto/
├── src/
│ ├── main.py
│ └── utils/
│ ├── io.py
│ └── math.py
├── tests/
│ └── test_main.py
└── README.md
DFS recorre esto en orden: proyecto → src → main.py → utils → io.py → math.py → tests → test_main.py → README.md. Entra en src completamente antes de siquiera mirar tests. BFS haría lo contrario: primero vería todos los elementos del nivel 1 (src, tests, README.md), luego todos los del nivel 2 (main.py, utils, test_main.py), etc.
Formulación como grafo de búsqueda:
- Nodos: directorios y archivos
- Aristas: relación “contiene” (padre → hijo)
- Meta: no hay — queremos visitar todo
- ¿Por qué DFS y no BFS? Porque queremos agrupar el contenido por rama (todo lo de
srcjunto), y porque el árbol puede ser muy profundo pero no muy ancho — DFS usa $O(bm)$ memoria, BFS usaría $O(b^d)$.
import os
def listar_archivos_dfs(ruta_raiz):
"""Recorre un árbol de directorios en profundidad (DFS iterativo)."""
archivos = []
pila = [ruta_raiz] # empezamos con la raíz
while pila:
ruta = pila.pop() # el más reciente — LIFO
if os.path.isfile(ruta):
archivos.append(ruta) # es un archivo: registrarlo
else:
# es un directorio: apilar sus hijos (en orden inverso para procesar alfabéticamente)
hijos = sorted(os.listdir(ruta), reverse=True)
for hijo in hijos:
pila.append(os.path.join(ruta, hijo))
return archivos
La traza en el árbol de ejemplo:
pila inicial: [proyecto/]
pop proyecto/ → es dir → push [README.md, tests/, src/]
pop src/ → es dir → push [utils/, main.py]
pop main.py → es archivo → archivos=[main.py]
pop utils/ → es dir → push [math.py, io.py]
pop io.py → es archivo → archivos=[main.py, io.py]
pop math.py → es archivo → archivos=[main.py, io.py, math.py]
pop tests/ → es dir → push [test_main.py]
pop test_main.py → archivos=[..., test_main.py]
pop README.md → archivos=[..., README.md]
Todo el contenido de src/ aparece junto, antes de pasar a tests/. Eso es exactamente lo que esperamos de DFS.
Resolución de dependencias
Cuando instalas un paquete con pip install o npm install, el gestor de paquetes necesita instalar primero las dependencias de las dependencias antes de instalar el paquete en sí. Eso es un orden topológico, y DFS lo calcula naturalmente.
Si el paquete A depende de B y C, y B depende de D:
A → B → D
A → C
DFS desde A visita: A, luego B, luego D (instala D primero porque no tiene dependencias), regresa a B (instala B), regresa a A, visita C (instala C), finalmente instala A. El orden de instalación es D, B, C, A — exactamente el orden topológico inverso al orden en que DFS termina de procesar cada nodo.
Detección de ciclos
DFS puede detectar ciclos: si durante la exploración encontramos un nodo que ya está en el camino actual (en la pila activa, no solo en explorado), hay un ciclo. Esto es útil para detectar dependencias circulares — el caso donde A depende de B y B depende de A — que harían imposible instalar cualquiera de los dos.
Resumen de DFS
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Pila (LIFO) | Nodo más reciente primero |
| Tiempo | $O(b^m)$ | Puede bajar hasta la profundidad máxima $m$ antes de retroceder |
| Espacio | $O(bm)$ | Un camino activo ($m$ nodos) + hermanos pendientes (hasta $b-1$ por nivel) |
| Completo | Sí (finito + explorado) | No en grafos infinitos |
| Óptimo | No | Puede encontrar camino largo antes del corto |
Recordatorio de notación: $b$ = factor de ramificación (máximo de vecinos por nodo; peor caso), $d$ = profundidad de la solución, $m$ = profundidad máxima del grafo ($m \geq d$, puede ser $\gg d$). Definidos en 03 — Algoritmo genérico →.
¿DFS o BFS? Cómo elegir
La elección no es arbitraria — depende de lo que sabes sobre tu problema antes de buscar. Hay tres dimensiones que importan: lo que necesitas (¿camino más corto?), lo que sabes (¿cuán profunda está la solución? ¿cuántas conexiones tiene cada nodo?), y los recursos disponibles (¿cuánta RAM tienes?).
Señales de que debes usar BFS
Usa BFS cuando necesitas el camino más corto Y tu problema tiene estas características:
| Señal del problema | ¿Por qué favorece BFS? |
|---|---|
| $d$ es pequeño o lo conoces (ej. “la solución tiene 5 pasos”) | $O(b^d)$ en memoria es manejable — la cola no explota |
| $b$ es moderado (pocos vecinos por nodo, ej. $b \leq 6$) | La cola crece lentamente nivel a nivel |
| La solución probablemente está cerca del inicio | BFS llega antes — no pierde tiempo bajando lejos |
| Tienes RAM suficiente (puedes guardar todo un nivel) | El costo de memoria de BFS no es un problema práctico |
| El grafo es ancho y poco profundo | BFS procesa todos los niveles cercanos de forma natural |
Ejemplos concretos donde BFS es la elección correcta:
| Problema real | $b$ aprox. | $d$ aprox. | ¿Por qué BFS? |
|---|---|---|---|
| Camino mínimo en un laberinto de cuadrícula 20×20 | 4 | ≤ 40 | $b^d = 4^{40}$… pero en práctica $d$ es mucho menor porque el laberinto está acotado |
| Grados de separación en una red social local | 50–150 | 3–6 | $d$ pequeño — “6 grados” funciona porque $d \leq 6$ incluso con $b$ alto |
| Flood fill en una imagen pequeña | 4 | ≤ imagen | BFS visita todos los píxeles conectados nivel a nivel |
| Movimientos mínimos para resolver un puzzle de 8 piezas | 3 | ≤ 31 | $d$ acotado y conocido — BFS explora en el mínimo garantizado |
Señales de alerta — evita BFS si:
- $d$ es desconocido y potencialmente grande ($d > 20$ con $b > 5$ ya son millones de nodos en cola)
- $b$ es grande y $d$ no es trivialmente pequeño — $10^{10}$ nodos a $d=10, b=10$
- La memoria es un recurso limitado (servidores pequeños, dispositivos embebidos)
Señales de que debes usar DFS
Usa DFS cuando no te importa la longitud del camino, o cuando necesitas explorar exhaustivamente:
| Señal del problema | ¿Por qué favorece DFS? |
|---|---|
| No necesitas el camino más corto — cualquier solución sirve | DFS puede encontrar una respuesta rápido sin explorar todos los niveles |
| El grafo es muy profundo ($m$ grande) y la solución está lejos | DFS baja directamente — no pierde tiempo en niveles superficiales |
| Necesitas explorar todas las ramas (backtracking) | DFS visita exhaustivamente una rama antes de retroceder — natural para puzzles |
| La RAM es escasa y $b \times m$ cabe pero $b^d$ no | $O(bm)$ de DFS es lineal — siempre cabe si el grafo tiene profundidad finita |
| Quieres agrupar resultados por rama (ej. todos los archivos de un directorio) | DFS completa una rama entera antes de pasar a la siguiente |
| No hay ciclos infinitos (grafo finito + conjunto explorado activo) | DFS es completo en este caso |
Ejemplos concretos donde DFS es la elección correcta:
| Problema real | $b$ aprox. | $m$ aprox. | ¿Por qué DFS? |
|---|---|---|---|
| Resolver Sudoku por backtracking | 9 | 81 | No importa en qué orden se llena — DFS prueba opciones y retrocede al fallar |
| Listar archivos en árbol de directorios | 10–100 | 10–20 | Agrupar por directorio es natural con DFS; BFS daría archivos mezclados de todos los niveles |
| Detectar ciclos en grafo de dependencias | variable | variable | DFS puede marcar si un nodo está en el camino activo — BFS no tiene esa noción |
| Generar permutaciones o combinaciones | $n$ | $n$ | Exploración completa de cada rama antes de la siguiente |
| Encontrar componentes conexas | variable | variable | DFS desde nodo no visitado completa exactamente una componente |
Señales de alerta — evita DFS si:
- Necesitas el camino más corto — DFS puede devolver una ruta arbitrariamente larga
- El grafo puede tener ramas infinitas sin conjunto explorado — DFS se perderá
- $m \gg d$ y la solución está cerca de la raíz — DFS puede tardar mucho bajando por ramas equivocadas
La regla de oro
¿Conoces d y es pequeño? ¿Tienes RAM? ¿Necesitas camino corto? → BFS
¿No importa la longitud? ¿Necesitas backtracking? ¿RAM limitada? → DFS
¿Necesitas camino corto pero d es grande/desconocido/RAM escasa? → IDDFS
La pregunta clave es: “¿qué sé sobre mi problema antes de empezar a buscar?” Si sabes que la solución está cerca, BFS es eficiente. Si no sabes dónde está o no necesitas la óptima, DFS gasta menos memoria. Si necesitas lo mejor de ambos mundos, IDDFS — próxima sección.
Siguiente: IDDFS y comparación →