| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda (BFS, DFS e IDDFS en Python) |
IDDFS y comparación de algoritmos
“The best of both worlds.”
IDDFS es busqueda_generica con frontera = PilaConLimite(d), ejecutada en un bucle que incrementa d desde 0 hasta encontrar la solución. Eso es todo. El resto de este capítulo es entender por qué esa idea tan simple produce un algoritmo que tiene las garantías de BFS con la eficiencia de memoria de DFS.
1. Intuición: búsqueda con radio creciente
¿Para qué sirve IDDFS? Úsalo cuando necesitas las mismas garantías que BFS — encontrar el camino más corto, no perderte en ramas infinitas — pero la memoria disponible no es suficiente para BFS. IDDFS es la solución cuando el problema es grande y profundo y no puedes permitirte guardar toda la frontera en memoria.
La intuición es la siguiente. Imagina que perdiste las llaves en algún lugar de tu ciudad. Estrategia BFS: examina simultáneamente todos los lugares a 100 metros, luego todos a 200 metros, etc. El problema: tienes que recordar todos los lugares que estás examinando a la vez — para distancias grandes, eso es una cantidad enorme de lugares en mente al mismo tiempo.
Estrategia IDDFS: en la primera vuelta, explora todo lo que está a menos de 100 metros usando la estrategia DFS (ve profundo por una calle, llega al límite, vuelve, prueba la siguiente). En la segunda vuelta, amplía el radio a 200 metros y repite DFS. En cada vuelta, solo tienes en mente un camino desde tu posición actual — mucha menos memoria.
El truco que hace esto funcionar: cuando el radio llega a la distancia real de las llaves, DFS garantizará encontrarlas antes de terminar esa vuelta — exactamente como BFS, porque exploró todas las posibilidades hasta ese radio.
2. En lenguaje natural
IDDFS responde la misma pregunta que BFS: “¿cuál es el camino de menos pasos del nodo A al nodo B?” La diferencia es cómo llega a la respuesta: en lugar de mantener toda una frontera nivel a nivel, hace múltiples pasadas DFS con un límite de profundidad creciente.
En cada pasada:
- Fija un límite de profundidad $d$ (empieza en 0).
- Ejecuta DFS normalmente, pero ignora cualquier vecino cuya profundidad superaría $d$.
- Si DFS encuentra la meta: devuelve el camino. Fin.
- Si DFS agota todos los nodos dentro del límite sin encontrar la meta: incrementa $d$ en 1 y repite desde el inicio.
La clave está en el paso 2: el límite de profundidad convierte a DFS en un explorador exhaustivo dentro de un radio fijo. Cuando $d$ iguala la profundidad de la solución, DFS la encontrará — y lo hará recorriendo exactamente los mismos nodos que hubiera explorado BFS.
Sí, si tienes una cota inferior probada para la profundidad de la solución. El riesgo es este: si empiezas con $d = 3$ y la solución real estaba a profundidad 2, nunca la encontrarás — habrás saltado por encima sin buscarlo.
Lo que sí puedes hacer de forma segura:
-
Cota inferior conocida: si el problema garantiza que la solución necesita al menos $k$ pasos (por ejemplo, en un puzzle de cuadrículas, la distancia Manhattan desde el inicio hasta la meta da un mínimo de movimientos), entonces puedes empezar con $d = k$ sin riesgo de saltarte la solución óptima.
-
Cota inferior heurística: si tienes una función heurística admisible $h(s_0)$ (que nunca sobrestima el costo real), puedes empezar con $d = h(s_0)$. Esto es exactamente lo que hace IDA*, la versión informada de IDDFS.
Si no tienes ninguna cota inferior, debes empezar en $d = 0$. Saltar límites sin garantías equivale a usar DFS sin beneficios — podrías perderte la solución más corta.
3. Pseudocódigo
IDDFS tiene dos capas: el bucle externo que incrementa el límite, y el DFS con límite que es idéntico al DFS estándar con una sola diferencia.
Capa externa: el bucle IDDFS
function IDDFS(problema):
for d = 0, 1, 2, 3, ...: # [O1] incrementar límite de profundidad en cada pasada
resultado ← DFS-WITH-LIMIT(problema, d) # [O2] DFS que no pasa de profundidad d
# internamente: busqueda_generica + PilaConLimite(d)
if resultado ≠ FAILURE: # [O3] ¿encontró la meta con este límite?
return resultado # sí → devolver el camino encontrado
# no → probar con límite d+1
Capa interna: DFS con límite de profundidad
DFS-WITH-LIMIT es busqueda_generica con PilaConLimite. El pseudocódigo es idéntico al DFS con una sola diferencia en push:
function DFS-WITH-LIMIT(problema, limite):
frontera ← new DepthLimitedStack(limite) # pila con memoria de profundidad
frontera.push(problema.inicio, padre=null) # nodo raíz tiene profundidad 0
explorado ← empty set
padre ← { problema.inicio: null }
while frontera is not empty:
nodo ← frontera.pop() # [L1] LIFO → el más reciente, igual que DFS
if problema.is_goal(nodo): # [L2] ¿es la meta?
return reconstruct(padre, nodo)
explorado.add(nodo) # [L3] marcar como procesado
for each vecino in problema.neighbors(nodo): # [L4]
if vecino not in explorado
and vecino not in frontera:
prof_vecino ← depth(nodo) + 1
if prof_vecino <= limite: # [L5] ← ÚNICA DIFERENCIA CON DFS
padre[vecino] ← nodo # ¿cabe dentro del límite? → añadir
frontera.push(vecino, padre=nodo)
# si no cabe: se descarta silenciosamente (poda)
return FAILURE
La línea [L5] es la única diferencia respecto a DFS. Todo lo demás — el bucle, el conjunto explorado, la tabla de padres, la expansión de vecinos — es idéntico.
4. Ejemplo paso a paso
Usamos un árbol binario con factor de ramificación $b = 2$ y objetivo en profundidad 3. El objetivo es el nodo K.
A
/ \
B C
/ \ / \
D E F G
/ \
H K ← objetivo (profundidad 3)
IDDFS ejecutará cuatro pasadas DFS con límites 0, 1, 2 y 3.
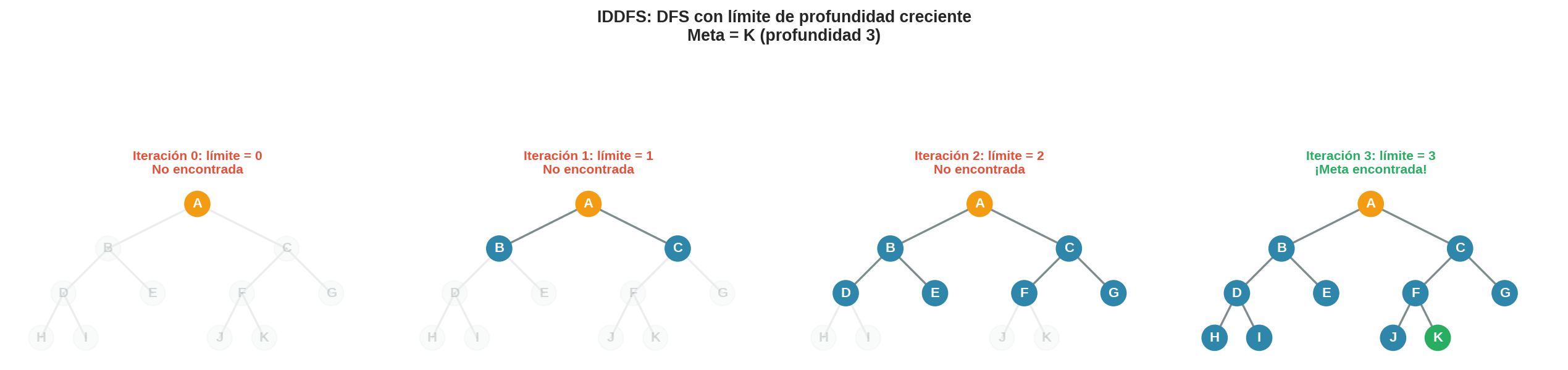
Pasada 0 — límite = 0
Solo se puede explorar el nodo raíz. Todos los hijos superan el límite y se podan.
| Paso | Nodo | Prof. | Pila (tope→) | Explorado | Qué pasó |
|---|---|---|---|---|---|
| 0 | — | — | [A] |
{} |
Inicialización. |
| 1 | A | 0 | [] |
{A} |
L1: pop A. L2: no es K. L5: hijos B, C tienen prof 1 > 0 → podados. |
Resultado: FAILURE. (Se produjeron podas → hay más nodos, vale la pena ampliar el límite.)
Pasada 1 — límite = 1
Ahora se puede llegar hasta profundidad 1: los hijos directos de A.
| Paso | Nodo | Prof. | Pila (tope→) | Explorado | Qué pasó |
|---|---|---|---|---|---|
| 0 | — | — | [A] |
{} |
Inicialización. |
| 1 | A | 0 | [B, C] |
{A} |
L1: pop A. L5: B (prof 1 ≤ 1), C (prof 1 ≤ 1) → push ambos. |
| 2 | C | 1 | [B] |
{A, C} |
L1: pop C. L5: hijos F, G tienen prof 2 > 1 → podados. |
| 3 | B | 1 | [] |
{A, C, B} |
L1: pop B. L5: hijos D, E tienen prof 2 > 1 → podados. |
Resultado: FAILURE. (Podas → ampliar.)
Pasada 2 — límite = 2
Ahora llegamos hasta profundidad 2. Llegamos a D, que es el padre de K, pero K está en profundidad 3 — todavía fuera de alcance.
| Paso | Nodo | Prof. | Pila (tope→) | Explorado | Qué pasó |
|---|---|---|---|---|---|
| 0 | — | — | [A] |
{} |
Inicialización. |
| 1 | A | 0 | [B, C] |
{A} |
Push B (1), C (1). |
| 2 | C | 1 | [B, F, G] |
{A, C} |
Push F (2), G (2). |
| 3 | G | 2 | [B, F] |
{A, C, G} |
Hoja. Sin hijos. |
| 4 | F | 2 | [B] |
{A, C, G, F} |
Hoja. Sin hijos. |
| 5 | B | 1 | [D, E] |
{A, C, G, F, B} |
Push D (2), E (2). |
| 6 | E | 2 | [D] |
{..., E} |
Hoja. Sin hijos. |
| 7 | D | 2 | [] |
{..., D} |
L5: hijos H, K tienen prof 3 > 2 → podados. |
Resultado: FAILURE. (Podas → ampliar.)
Pasada 3 — límite = 3
Ahora el límite alcanza la profundidad real de K. DFS encuentra K exactamente cuando llega a la rama correcta.
| Paso | Nodo | Prof. | Pila (tope→) | Explorado | Qué pasó |
|---|---|---|---|---|---|
| 0 | — | — | [A] |
{} |
Inicialización. |
| 1 | A | 0 | [B, C] |
{A} |
Push B (1), C (1). |
| 2 | C | 1 | [B, F, G] |
{A, C} |
Push F (2), G (2). |
| 3 | G | 2 | [B, F] |
{A, C, G} |
Hoja. |
| 4 | F | 2 | [B] |
{A, C, G, F} |
Hoja. |
| 5 | B | 1 | [D, E] |
{..., B} |
Push D (2), E (2). |
| 6 | E | 2 | [D] |
{..., E} |
Hoja. |
| 7 | D | 2 | [H, K] |
{..., D} |
L5: H (3 ≤ 3), K (3 ≤ 3) → push ambos. |
| 8 | K | 3 | — | — | L2: K es la meta → reconstruir camino. |
Camino encontrado: A → B → D → K (profundidad 3). ✓
Observa que IDDFS encontró K exactamente cuando el límite igualó la profundidad de la solución — igual que BFS habría hecho al llegar al nivel 3.
5. Implementación Python
PilaConLimite es la única pieza nueva. Todo lo demás — busqueda_generica, reconstruir_camino — es idéntico al DFS.
class PilaConLimite(Frontera):
"""
Frontera tipo pila con límite de profundidad.
Produce DFS-con-límite cuando se usa con busqueda_generica.
La única diferencia respecto a PilaDeFrontera: push rechaza nodos muy profundos.
"""
def __init__(self, limite):
self.pila = []
self.miembros = {} # nodo → profundidad (dict, no set — necesitamos guardar el número)
self.limite = limite
self.poda = False # ¿se descartó algún nodo por superar el límite?
def push(self, nodo, padre=None):
# Calculamos la profundidad del nodo a partir de la profundidad del padre
prof_padre = self.miembros.get(padre, -1) if padre is not None else -1
prof_nodo = prof_padre + 1 # el nodo está un nivel más abajo que su padre
if prof_nodo <= self.limite:
self.pila.append(nodo)
self.miembros[nodo] = prof_nodo # registrar profundidad para calcular la de sus hijos
else:
self.poda = True # hay algo más allá del límite — vale la pena ampliar en la siguiente pasada
def pop(self):
nodo = self.pila.pop() # LIFO — igual que PilaDeFrontera
# NO eliminamos de miembros: seguimos necesitando la profundidad de nodos ya procesados
# para calcular la profundidad de sus hijos cuando los expandimos
return nodo
def contains(self, nodo):
return nodo in self.miembros and nodo in self.pila # solo si aún está en la pila activa
def is_empty(self):
return len(self.pila) == 0
def dfs_con_limite(problema, limite):
"""DFS que nunca expande nodos más allá de 'limite' niveles de profundidad."""
return busqueda_generica(problema, PilaConLimite(limite))
def iddfs(problema, max_depth=1000):
"""IDDFS: DFS-con-límite en bucle con límite creciente."""
for d in range(max_depth + 1):
resultado = dfs_con_limite(problema, d)
if resultado is not None:
return resultado
return None
Comparación directa de las tres fronteras:
ColaDeFrontera (BFS) |
PilaDeFrontera (DFS) |
PilaConLimite (IDDFS) |
|
|---|---|---|---|
| Estructura interna | deque |
list |
list |
| Conjunto sombra | set |
set |
dict (guarda profundidad) |
pop |
popleft() — FIFO |
pop() — LIFO |
pop() — LIFO |
| Diferencia clave | — | — | push comprueba profundidad |
6. ¿En qué se diferencia de BFS? Parecen hacer lo mismo
Esta es la pregunta más importante. BFS e IDDFS son funcionalmente equivalentes en lo que garantizan (ambos son completos y óptimos sin pesos), pero son muy distintos en cómo usan la memoria.
BFS: guarda toda la frontera
BFS expande nivel a nivel. Para procesar el nivel $d$, tiene que guardar en la cola todos los nodos del nivel $d-1$ hasta terminarlos, y simultáneamente va acumulando los del nivel $d$. En el peor caso, la cola contiene todo el último nivel explorado: $b^d$ nodos.
BFS en nivel 3 (b=2):
Cola: [D, E, F, G] ← todos los nodos de nivel 2 más los que se van generando
↑ 2² = 4 nodos en memoria a la vez
Para $b = 10$, $d = 10$: la cola necesita hasta $10^{10}$ nodos. Eso son miles de millones de entradas — impracticable.
IDDFS: solo guarda un camino
IDDFS usa DFS internamente. DFS solo necesita mantener el camino desde la raíz hasta el nodo actual, más los hermanos pendientes de cada nodo en ese camino. Eso es como máximo $b \times d$ nodos — uno por profundidad, más los hermanos.
IDDFS en pasada 3 (b=2, límite=3):
Pila (en el peor momento): [B, D, H, K] ← un camino + un hermano
↑ b×d = 2×3 = 6 nodos como máximo
Para $b = 10$, $d = 10$: la pila nunca supera $10 \times 10 = 100$ nodos. La diferencia es de mil millones a cien.
La tabla de diferencias
| BFS | IDDFS | |
|---|---|---|
| Estructura de datos | Cola (FIFO) | Pila con límite, en bucle |
| Memoria (frontera) | $O(b^d)$ — todo un nivel | $O(bd)$ — un camino |
| Nodos expandidos | Cada nodo una vez: $O(b^d)$ | Con redundancia: $O(b^d)$ asintóticamente |
| ¿Re-expande nodos? | No | Sí — en cada pasada |
| Completo | Sí | Sí |
| Óptimo (sin pesos) | Sí | Sí |
| ¿Cuándo es mejor? | Grafos poco profundos, memoria abundante | Grafos profundos, memoria limitada |
7. Complejidad de tiempo y espacio
IDDFS tiene dos partes que analizar por separado: el tiempo (que sí se acumula en cada pasada) y el espacio (que sorprendentemente no se acumula). Entender la diferencia entre los dos es la clave para comprender IDDFS.
Tiempo: $O(b^d)$ en total, sumando todas las pasadas
La pregunta clave es: ¿cuántos nodos expande IDDFS en total, contando todas las pasadas?
Usamos $b$ como el número máximo de vecinos de cualquier nodo — lo que hace de estas cotas garantías de peor caso. En grafos con vecinos variables, $b_{max}$ da la cota superior; usar $b_{avg}$ daría una estimación más ajustada pero solo para el caso promedio.
Cada pasada con límite $k$ expande a lo sumo todos los nodos hasta profundidad $k$:
$$\text{Nodos en pasada } k \leq \sum_{j=0}^{k} b^j = 1 + b + b^2 + \cdots + b^k$$
Para llegar a una solución a profundidad $d$, IDDFS ejecuta pasadas $0, 1, 2, \ldots, d$. El total acumulado es la suma de todas las pasadas:
$$T_{\text{total}} = \sum_{k=0}^{d} \underbrace{\sum_{j=0}^{k} b^j}_{\text{pasada } k}$$
Esto no es lo mismo que la complejidad de una sola pasada — hay que sumar todas. Hagamos las cuentas explícitas para $b = 3$, solución a $d = 4$:
| Pasada $k$ | Nodos expandidos en esa pasada | Acumulado total |
|---|---|---|
| 0 | $1$ | $1$ |
| 1 | $1 + 3 = 4$ | $5$ |
| 2 | $1 + 3 + 9 = 13$ | $18$ |
| 3 | $1 + 3 + 9 + 27 = 40$ | $58$ |
| 4 | $1 + 3 + 9 + 27 + 81 = 121$ | 179 |
El total es 179. BFS habría expandido solo 121. IDDFS expandió un 48% más.
¿Por qué ese sobrecosto es tan pequeño? Porque la última pasada domina. Miremos cuánto pesa cada pasada en el total:
| Pasada | Nodos de esa pasada | % del total |
|---|---|---|
| 0 | 1 | 0.6% |
| 1 | 4 | 2.2% |
| 2 | 13 | 7.3% |
| 3 | 40 | 22.3% |
| 4 | 121 | 67.6% |
La pasada final representa el 68% del trabajo total. Las 4 pasadas anteriores juntas solo suman el 32%. ¿Por qué? Porque la pasada $d$ tiene $b^d$ nodos solo en el nivel más profundo, y eso solo ya supera en tamaño a TODAS las pasadas anteriores combinadas.
En general: la pasada $k$ tiene aproximadamente $b^k$ nodos (el nivel más profundo). La suma de todas las pasadas hasta $d-1$ es comparable a $b^{d-1} + b^{d-2} + \cdots \approx b^{d-1} \cdot \frac{b}{b-1}$, que es una fracción constante de $b^d$. Formalmente:
$$T_{\text{IDDFS}} = \sum_{k=0}^{d} \sum_{j=0}^{k} b^j = \sum_{k=0}^{d} \frac{b^{k+1}-1}{b-1} \approx \frac{b}{(b-1)^2} \cdot b^d = O(b^d)$$
La complejidad total de IDDFS — sumando todas las pasadas — es $O(b^d)$, igual que BFS. El sobrecosto del trabajo redundante es una constante multiplicativa, no un cambio de orden asintótico.
No — el porcentaje de sobrecosto converge a una constante que depende solo de $b$:
$$\text{Sobrecosto} = \frac{T_{\text{IDDFS}}}{T_{\text{BFS}}} \approx \frac{b}{b-1}$$
Para $b=2$: factor $\approx 2.0$ (doble de trabajo). Para $b=3$: factor $\approx 1.5$ (50% extra). Para $b=10$: factor $\approx 1.11$ (solo 11% extra).
Cuanto mayor es el factor de ramificación, menor es el sobrecosto relativo. Para los problemas grandes donde IDDFS es más útil (muchos vecinos por nodo), el precio del trabajo redundante es insignificante.
Espacio: $O(bd)$ — y se mantiene aunque hagamos múltiples pasadas
Aquí está la parte más sorprendente de IDDFS: aunque hace $d+1$ pasadas y en cada una re-explora los nodos de las anteriores, el uso de memoria en pico nunca supera $O(bd)$.
¿Por qué? La clave es entender qué pasa con la memoria entre pasadas:
Dentro de una pasada: la pila de IDDFS en cualquier momento contiene solo el camino activo desde la raíz hasta el nodo actual, más los hermanos pendientes de cada nivel — exactamente como DFS. Con límite $k$, la pila tiene como máximo $b \times k$ nodos.
Entre pasadas: cuando una pasada termina (sin encontrar la meta), la pila queda completamente vacía. No se guarda nada de la pasada anterior. La pasada $k+1$ empieza desde cero — con la pila vacía — igual que si fuera la primera vez.
Memoria a lo largo de IDDFS:
Pasada 0: pila sube hasta b×0 = 0... vacía al terminar
Pasada 1: pila sube hasta b×1 nodos... vacía al terminar
Pasada 2: pila sube hasta b×2 nodos... vacía al terminar
...
Pasada d: pila sube hasta b×d nodos... ← PICO MÁXIMO → solución encontrada, termina
El pico de memoria ocurre en la pasada final (límite $= d$) cuando la pila está más llena:
$$S_{\text{IDDFS}} = O(bd)$$
No importa cuántas pasadas hagamos — el pico de memoria es siempre el de la última pasada. Las pasadas anteriores usan menos memoria (pila con límite menor) y liberan toda su memoria antes de empezar la siguiente.
Comparación con BFS y DFS para $b = 10$, $d = m$:
| $d$ | BFS (cola en pico) | DFS (pila máxima) | IDDFS (pila en pico) |
|---|---|---|---|
| 2 | $100$ | $20$ | $20$ |
| 4 | $10{,}000$ | $40$ | $40$ |
| 6 | $1{,}000{,}000$ | $60$ | $60$ |
| 8 | $10^8$ | $80$ | $80$ |
| 10 | $10^{10}$ | $100$ | $100$ |
IDDFS usa la misma memoria que DFS — no la acumula entre pasadas. A profundidad 10: BFS necesita ~320 GB, IDDFS necesita la misma RAM que DFS: apenas unos kilobytes.
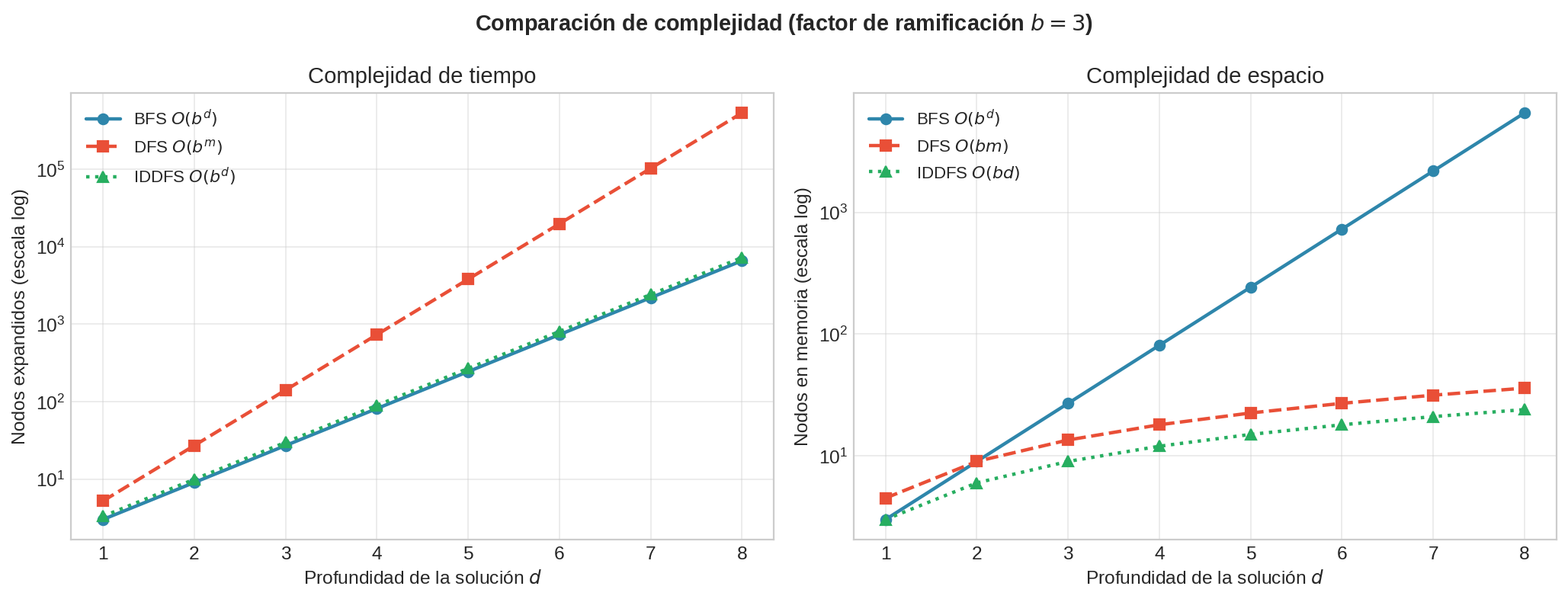
El gráfico confirma lo que acabamos de derivar: tiempo BFS ≈ IDDFS (misma curva exponencial), pero espacio BFS $\gg$ IDDFS (BFS exponencial, IDDFS lineal).
8. Completitud y optimalidad
Completitud: sí
IDDFS es completo. Para cualquier profundidad de solución $d^{∗}$, IDDFS llegará eventualmente a la pasada con límite $d^{∗}$ y encontrará la solución, siempre que el grafo sea finito.
¿Y si el grafo tiene ciclos? Igual que DFS, cada pasada de IDDFS usa un conjunto explorado para no repetir nodos dentro de esa pasada. Los ciclos no causan bucles infinitos.
¿Y si el grafo es infinito? Si la solución existe a profundidad finita $d^{∗}$, IDDFS la encontrará en la pasada $d^{∗}$. Si no existe ninguna solución, IDDFS no termina — igual que BFS.
Optimalidad: sí (sin pesos)
IDDFS es óptimo para grafos sin pesos: siempre encuentra el camino con menos aristas.
¿Por qué? En la pasada con límite $d-1$, IDDFS no encontró la solución — esto significa que no existe ninguna solución a profundidad $\leq d-1$. En la pasada con límite $d$, IDDFS encuentra la solución — y como DFS la encuentra antes de explorar profundidades mayores que $d$, la solución encontrada tiene exactamente $d$ pasos. Eso es el mínimo posible.
Al igual que BFS, IDDFS solo cuenta aristas, no pesos. Si una arista corta vale 100 y un camino largo vale 10 en total, IDDFS encontraría el camino corto (menos aristas) aunque sea el más caro. Para pesos arbitrarios se necesita una variante con costos: IDA* (Iterative Deepening A*), que usa $g(n) + h(n)$ como criterio en lugar de la profundidad.
9. Aplicaciones de IDDFS
Puzzles con profundidad desconocida
IDDFS es ideal cuando no sabes cuántos pasos necesita la solución. Por ejemplo, el puzzle del 15 (el juego de tiles deslizables): la solución mínima puede estar entre 1 y 80 movimientos. BFS tendría que guardar en memoria todos los estados a 40 movimientos antes de llegar a 41 — un número astronómico. IDDFS va aumentando el límite de uno en uno, usando solo la memoria de un camino a la vez.
Motores de ajedrez (antes de A*)
Los primeros motores de ajedrez usaban IDDFS para buscar el mejor movimiento. Dado que no se sabe de antemano cuántos movimientos hay que calcular, IDDFS empieza buscando a profundidad 1, luego 2, etc. — y si se acaba el tiempo, devuelve el mejor movimiento encontrado hasta ahora. Esto se llama iterative deepening with time control.
Sistemas con memoria muy limitada
En dispositivos embebidos (microcontroladores, robots con memoria restringida), BFS puede ser impracticable. IDDFS ofrece las mismas garantías con una fracción del uso de memoria.
10. Resumen de IDDFS
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Pila con límite (LIFO + poda) | DFS que no supera profundidad $d$ |
| Tiempo | $O(b^d)$ total (sumando todas las pasadas) | Última pasada domina; sobrecosto constante $\approx b/(b-1)$ |
| Espacio | $O(bd)$ en pico (igual que una sola pasada DFS) | Memoria liberada entre pasadas; nunca se acumula |
| Completo | Sí | Prueba todos los límites hasta $d^{∗}$ |
| Óptimo | Sí (sin pesos) | Nunca termina antes de agotar profundidad $d-1$ |
Recordatorio de notación: $b$ = factor de ramificación (máximo de vecinos por nodo; peor caso), $d$ = profundidad de la solución (aristas del camino más corto), $m$ = profundidad máxima del grafo. Definidos en 03 — Algoritmo genérico →.
11. Tabla comparativa final: BFS vs DFS vs IDDFS
| Propiedad | BFS | DFS | IDDFS |
|---|---|---|---|
| Frontera | Cola (FIFO) | Pila (LIFO) | Pila con límite $d$, en bucle |
| Tiempo | $O(b^d)$ | $O(b^m)$ | $O(b^d)$ |
| Espacio | $O(b^d)$ | $O(bm)$ | $O(bd)$ |
| Completo | Sí | Sí (finito + explorado) | Sí |
| Óptimo | Sí (sin pesos) | No | Sí (sin pesos) |
| Re-expande nodos | No | No | Sí (constante por pasada) |
| Implementación | popleft() |
pop() |
bucle + pop() con poda |
Donde: $b$ = factor de ramificación (máximo de vecinos por nodo; peor caso), $d$ = profundidad de la solución (aristas en el camino más corto a la meta), $m$ = profundidad máxima del grafo ($m \geq d$). El tiempo de IDDFS es el total acumulado de todas las pasadas — no el de una sola pasada con límite $d$.
12. Comparación directa: BFS vs DFS vs IDDFS en el mismo grafo
La diferencia de comportamiento entre los tres algoritmos queda clara comparando los árboles de búsqueda que genera cada uno sobre el mismo grafo de 6 nodos.
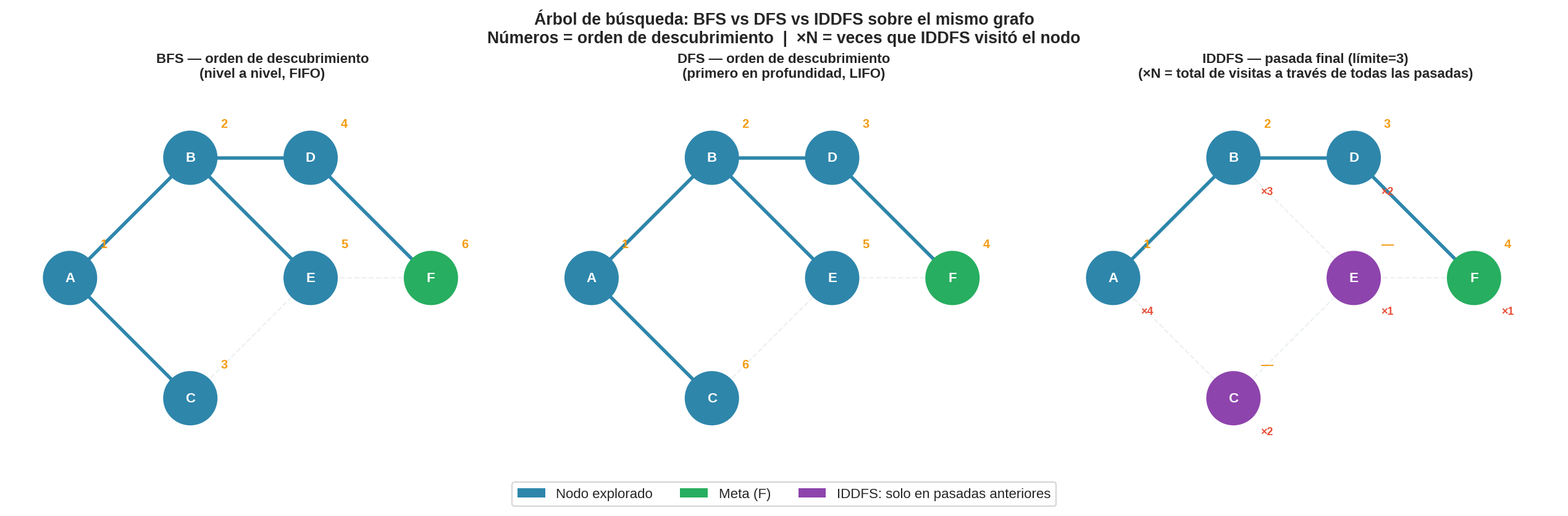
Los números naranjas indican el orden de descubrimiento de cada nodo. Los números rojos (×N) en el panel de IDDFS indican cuántas veces visitó ese nodo en total a través de todas las pasadas.
-
BFS descubre A(1), B(2), C(3), D(4), E(5), F(6) — nivel a nivel, de izquierda a derecha. Nunca llega a un nivel siguiente hasta haber terminado el anterior. F es el último nodo en ser descubierto porque está más lejos.
-
DFS descubre A(1), B(2), D(3), F(4), E(5), C(6) — se hunde por la primera rama hasta encontrar F, luego hace backtrack y explora E y C. Encuentra F en el paso 4, antes que BFS.
-
IDDFS (pasada final, límite=3) descubre A(1), B(2), D(3), F(4) y detiene — siguió exactamente el mismo camino que DFS para llegar a F. Los nodos E (morado) y C (morado) no fueron alcanzados en la pasada final: aparecen con “—” en el orden de descubrimiento porque IDDFS ya terminó al encontrar F. Sin embargo, el badge rojo muestra que IDDFS visitó E una vez (en la pasada con límite=2) y C dos veces (en las pasadas con límite=1 y límite=2).
Lo que la imagen revela
Tres observaciones clave:
-
IDDFS en la pasada final se comporta exactamente como DFS — mismo árbol de búsqueda, mismo camino hacia F, mismo orden de expansión. La diferencia no está en cómo se mueve, sino en que las pasadas anteriores garantizaron que no existe una solución más corta.
-
BFS tiene árbol más ancho, IDDFS/DFS tienen árbol más profundo — BFS genera árbol con aristas horizontales (A→B, A→C antes de bajar), DFS e IDDFS van en vertical (A→B→D→F primero).
-
El costo del trabajo redundante de IDDFS es visible: A fue visitado 4 veces, B 3 veces, C 2 veces — pero F solo 1 vez. El trabajo extra está concentrado en los nodos cercanos a la raíz, no en los profundos donde vive la solución.
14. ¿Cuándo usar cada algoritmo?
La elección depende de lo que sabes sobre tu problema antes de buscar: cuánto mide $d$, cuánto mide $b$, cuánta memoria tienes, y si necesitas la solución óptima. El siguiente árbol de decisión te lleva a la respuesta correcta.
┌─────────────────────────────────────────────────────────────┐
│ ¿Necesitas el camino MÁS CORTO? │
└───────┬──────────────────────────────┬──────────────────────┘
│ No │ Sí
▼ ▼
┌───────────────────┐ ┌───────────────────────────────────┐
│ DFS │ │ ¿Sabes que d es pequeño │
│ │ │ Y tienes RAM suficiente? │
│ backtracking, │ └──────────┬────────────────────────┘
│ exploración, │ │ Sí │ No
│ componentes, │ ▼ ▼
│ orden topológico │ ┌──────────────┐ ┌─────────────────┐
└───────────────────┘ │ BFS │ │ IDDFS │
│ │ │ │
│ simple, │ │ d desconocido, │
│ sin overhead │ │ RAM limitada, │
│ de pasadas │ │ b grande │
└──────────────┘ └─────────────────┘
Tabla de señales por dimensión
Antes de elegir, caracteriza tu problema según estas dimensiones:
| Dimensión | Favorece BFS | Favorece DFS | Favorece IDDFS |
|---|---|---|---|
| ¿Necesitas camino óptimo? | Sí, siempre | No importa | Sí, siempre |
| ¿Conoces $d$? | Sí, y es pequeño | No necesitas saberlo | No, o es grande/variable |
| Factor de ramificación $b$ | Pequeño–moderado ($b \leq 6$) | Cualquiera | Grande ($b \geq 10$) — overhead $b/(b-1) \approx 1$ |
| Profundidad de solución $d$ | Pequeña ($b^d$ cabe en RAM) | No importa (no usas BFS) | Grande o desconocida |
| Profundidad máxima $m$ | Irrelevante (BFS se detiene en $d$) | Debe ser finita | Irrelevante (IDDFS se detiene en $d$) |
| Memoria disponible | Alta — $O(b^d)$ cabe | Baja — solo necesita $O(bm)$ | Baja — solo necesita $O(bd)$ |
| ¿Tiempo límite? | No es útil parar a la mitad | No aplica | Sí — puedes parar entre pasadas y tener resultado parcial |
| ¿Necesitas explorar todo? | Sí (alcanzabilidad) | Sí (componentes, ciclos, backtracking) | No — para al encontrar la solución |
Usa BFS cuando:
Lo que sabes del problema señala hacia BFS:
- Sabes o puedes estimar que $d$ es pequeño — y confirmas que $b^d$ cabe en memoria.
- El grafo tiene pocas conexiones por nodo ($b$ pequeño) — la cola crece despacio.
- La solución está cerca del inicio — BFS la encuentra enseguida sin explorar ramas profundas.
- Tienes suficiente RAM — la complejidad de memoria $O(b^d)$ no es un obstáculo.
- Quieres una implementación directa, sin el overhead del bucle de IDDFS.
Ejemplos concretos:
| Problema | $b$ | $d$ | ¿Por qué BFS? |
|---|---|---|---|
| Ruta mínima en laberinto 50×50 | 4 | ≤ 100 | $d$ acotado por el tamaño del laberinto; $b^d$ manejable con explorado set |
| Grados de separación (red local, 1000 personas) | 10–50 | 3–4 | $d$ es pequeño — redes densas tienen diámetros pequeños |
| Mínimo de movimientos en puzzle 8-piezas | 3 | ≤ 31 | $d$ conocido y pequeño; BFS garantiza encontrar la solución en exactamente 31 movimientos |
| Flood fill (imagen 512×512) | 4 | ≤ 512² | Nodos son píxeles — el “grafo” es grande pero BFS lo procesa con una cola que nunca supera el nivel actual |
Señales de alerta para BFS:
- $b > 10$ y $d > 6$: la cola supera millones de nodos — probablemente necesitas IDDFS
- $d$ es desconocido y potencialmente grande: IDDFS es más apropiado
- Dispositivo con RAM limitada: ni BFS ni DFS con d grande
Usa DFS cuando:
Lo que sabes del problema señala hacia DFS:
- No necesitas el camino más corto — solo existencia, o exploración completa.
- La solución probablemente está profunda — DFS llega lejos sin explorar todos los niveles superficiales.
- Necesitas backtracking — probar opciones, deshacer al fallar, explorar sistemáticamente.
- La RAM es escasa — $O(bm)$ siempre cabe mientras el grafo sea finito.
- Quieres agrupar resultados por rama — componentes conexas, árbol de dependencias, árbol de directorios.
- Sabes que el grafo es finito y tiene conjunto explorado — DFS no entrará en bucles infinitos.
Ejemplos concretos:
| Problema | $b$ | $m$ | ¿Por qué DFS? |
|---|---|---|---|
| Sudoku (9×9) | 9 | 81 | Backtracking necesario; no existe “camino más corto” entre configuraciones |
| Árbol de directorios (10 niveles, 50 entradas/dir) | 50 | 10 | $O(bm) = 500$ entradas en pila — trivial; BFS requeriría $50^{10}$ |
| Encontrar componentes conexas en grafo de 10,000 nodos | variable | variable | DFS completa cada componente en una pasada; solo necesita el conjunto visitado |
| N-reinas (N=12) | 12 | 12 | Exploración exhaustiva de todas las colocaciones; DFS con backtracking es la implementación canónica |
Señales de alerta para DFS:
- Necesitas el camino más corto: DFS puede devolver uno arbitrariamente largo
- El grafo tiene ramas infinitas (sin conjunto explorado): DFS puede no terminar
- La solución está muy cerca del inicio y tienes memoria suficiente: BFS encontrará la solución más rápido
Usa IDDFS cuando:
Lo que sabes del problema señala hacia IDDFS:
- Necesitas el camino más corto, pero también se cumple alguna de estas condiciones:
- No sabes $d$ — IDDFS prueba automáticamente $d = 0, 1, 2, \ldots$
- $b^d$ excede tu RAM disponible — la cola de BFS no cabe
- $b$ es grande — el overhead de IDDFS es pequeño: con $b = 10$, solo un 11% más de trabajo que BFS
- Quieres poder parar entre pasadas y obtener el mejor resultado hasta ese momento (útil en motores de juego con límite de tiempo).
- El espacio de estados es masivo — imposible guardar la frontera completa en memoria.
Ejemplos concretos:
| Problema | $b$ | $d$ | ¿Por qué IDDFS? |
|---|---|---|---|
| Puzzle 15 piezas | 3 | ≤ 80 | $b^d = 3^{80} \approx 10^{38}$ nodos en BFS — imposible; IDDFS necesita solo $O(b \cdot d) = 240$ nodos en pila |
| Cubo de Rubik (simplificado) | 18 | ≤ 20 | $18^{20} \approx 10^{25}$ nodos en BFS; IDDFS: $18 \times 20 = 360$ nodos en pila |
| Motor de ajedrez con límite de tiempo | 35 | hasta 10 | IDDFS permite devolver el mejor movimiento a profundidad $k$ si el tiempo se acaba antes de llegar a $k+1$ |
| Planificación de rutas en grafo grande desconocido | variable | desconocido | $d$ no se conoce a priori — IDDFS es la única opción entre BFS/DFS que es óptima sin conocer $d$ |
Señales de alerta para IDDFS:
- $b = 1$ (lista lineal): el overhead de re-exploración es 100% — BFS es igual de eficiente en memoria
- $b = 2$ y $d$ grande: overhead ≈ 100% — considera si BFS cabe en memoria antes de descartarlo
- Ya sabes exactamente $d$ y BFS cabe en memoria: BFS es más simple y sin overhead
15. Preview: búsqueda informada
Los tres algoritmos que hemos visto — BFS, DFS, IDDFS — son no informados (uninformed o blind): exploran el espacio de estados sin ninguna pista sobre cuán cerca está la meta. Prueban todas las posibilidades dentro de su estrategia, sin importar en qué dirección está la solución.
El siguiente paso es añadir información heurística: una función $h(n)$ que estima cuán lejos está la meta desde el nodo $n$. Con esta guía, los algoritmos pueden evitar explorar zonas del grafo que claramente no llevan a la meta:
- Búsqueda voraz por mejor primero (greedy best-first): frontera = cola de prioridad ordenada por $h(n)$. Rápido pero no garantiza optimalidad.
- A*: frontera = cola de prioridad ordenada por $f(n) = g(n) + h(n)$ (costo real + heurística). Con una heurística admisible, es completo, óptimo, y en la práctica mucho más eficiente que BFS e IDDFS.
- IDA* (Iterative Deepening A*): como IDDFS pero usando $f(n)$ como criterio de poda en lugar de la profundidad. Combina el ahorro de memoria de IDDFS con la guía heurística de A*.
Inicio: Volver al índice →