| Notebook | Colab |
|---|---|
| Notebook 01 — Grafos ponderados y colas de prioridad | |
| Notebook 02 — Búsqueda informada (Greedy, Dijkstra, A*) |
Grafos con pesos y la frontera de prioridad
“The measure of intelligence is the ability to change.” — Albert Einstein
En 03 — Algoritmo genérico de búsqueda quedaron dos filas en la tabla de fronteras con la nota “veremos en módulos posteriores”:
| Frontera | Estrategia de pop() |
Algoritmo |
|---|---|---|
| Cola de prioridad (por costo) | El más barato primero | Dijkstra |
| Cola de prioridad ($g + h$) | El más prometedor primero | A* |
Este módulo entrega esa promesa. Pero primero necesitamos entender por qué BFS ya no es suficiente — y qué dos nuevas cantidades, $g(n)$ y $h(n)$, dan lugar a todos los algoritmos de búsqueda informada.
1. El problema con BFS: no todos los pasos cuestan igual
BFS funciona perfectamente cuando moverse de un nodo a cualquiera de sus vecinos tiene el mismo costo. En ese mundo, “menor número de pasos” = “menor costo total”.
Pero los problemas reales casi nunca son así. Una ruta de navegación puede tener autopistas (rápidas) y carreteras de montaña (lentas). Un robot puede moverse por suelo firme (barato) o por terreno arenoso (costoso). Un grafo de dependencias puede tener operaciones ligeras y pesadas.
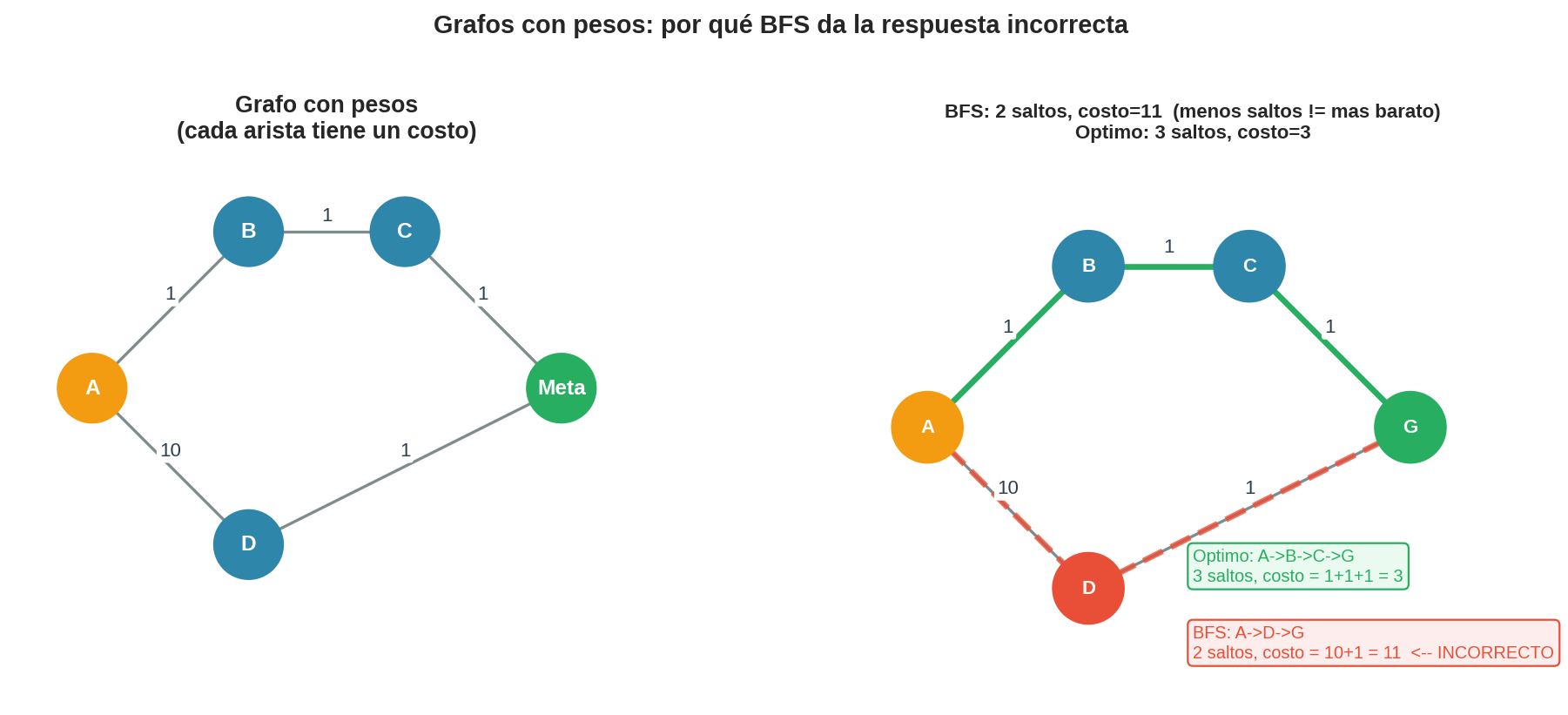
En cuanto los costos difieren, BFS da la respuesta incorrecta:
Grafo ponderado:
A ──1── B ──1── C ──1── Meta
│
10
│
D ──────────────────1── Meta
BFS responde: A → D → Meta (2 saltos — el más corto en hops)
Costo real: 10 + 1 = 11
Pero A → B → C → Meta tiene 3 saltos y costo:
1 + 1 + 1 = 3 ← ¡mucho más barato!
BFS eligió el camino de menos saltos — pero ese camino es casi 4 veces más caro. Cuantos más saltos no implica más caro: la arista A→D cuesta 10 mientras cada paso por B y C cuesta solo 1. Necesitamos un algoritmo que expanda el nodo con el menor costo acumulado, no el que esperó más tiempo en la cola.
2. La nueva cantidad: $g(n)$
Definimos:
$$g(n) = \text{costo total acumulado desde el inicio hasta el nodo } n \text{ (por el camino encontrado hasta ahora)}$$
$g(n)$ no es fijo — depende del camino por el que llegamos a $n$. Si llegamos por un camino más barato, $g(n)$ se actualiza.
Ejemplos:
- Si el inicio tiene costo 0: $g(\text{inicio}) = 0$
- Si la arista inicio→A tiene peso 2: $g(A) = 2$
- Si luego A→B tiene peso 3: $g(B) = 2 + 3 = 5$
La clave: siempre queremos expandir el nodo con el menor $g(n)$ actual. Así garantizamos que cuando procesamos un nodo, hemos encontrado la ruta más barata posible hasta él (asumiendo pesos no negativos — ver nota al final).
3. La frontera de prioridad
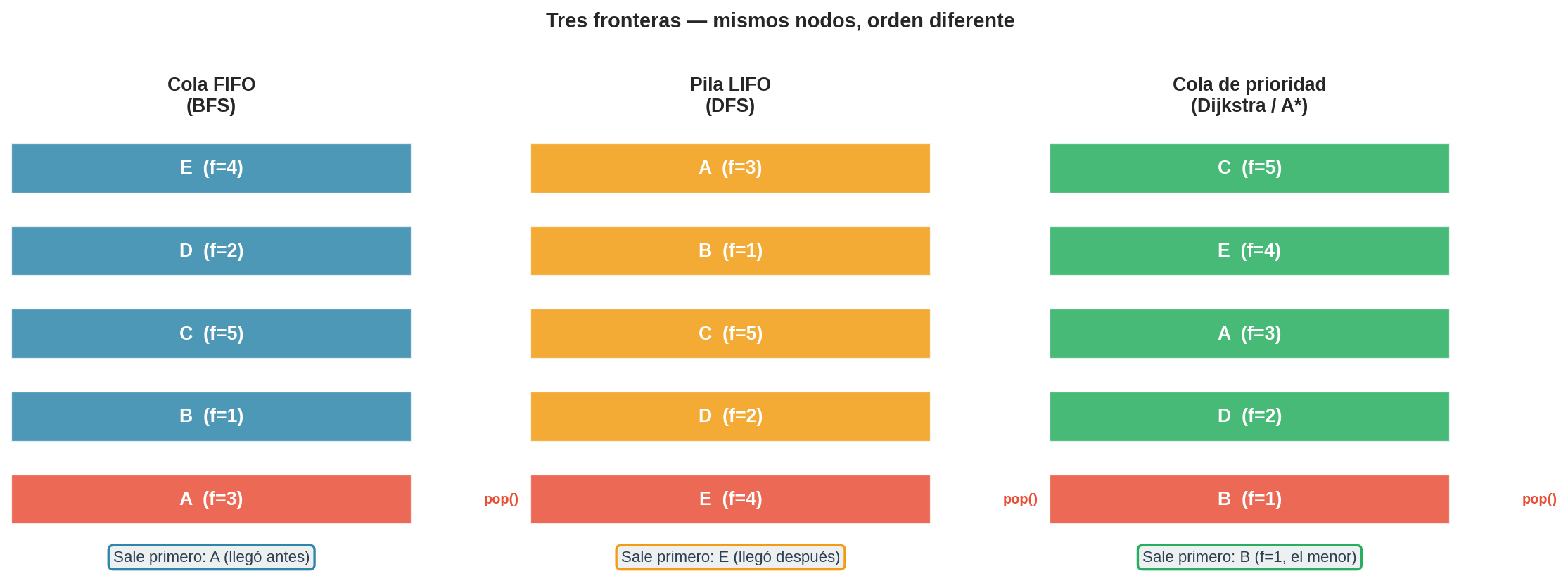
Para expandir siempre el nodo de menor costo, necesitamos una estructura que saque el elemento con menor valor de prioridad primero: una cola de prioridad (priority queue o min-heap).
| Operación | Cola FIFO (BFS) | Cola de prioridad |
|---|---|---|
push(nodo) |
Añade al final | Añade con una prioridad $f(n)$ |
pop() |
Saca el más antiguo | Saca el de menor $f(n)$ |
contains(nodo) |
O(1) con set auxiliar | O(1) con dict auxiliar |
En Python: heapq de la biblioteca estándar implementa un min-heap en O(log n).
import heapq
# Insertar con prioridad:
heap = []
heapq.heappush(heap, (prioridad, nodo))
# Extraer el de menor prioridad:
prioridad, nodo = heapq.heappop(heap)
¿Qué poner como prioridad? Esa pregunta define el algoritmo:
| Prioridad $f(n)$ | Algoritmo | ¿Óptimo? |
|---|---|---|
| $g(n)$ — costo acumulado | Dijkstra | Sí (pesos no negativos) |
| $h(n)$ — estimación al objetivo | Greedy best-first | No |
| $g(n) + h(n)$ — costo real + estimación | A* | Sí (si $h$ es admisible) |
Los tres son busqueda_generica con frontera = ColaDePrioridad(key=f). La única diferencia es la fórmula de $f$.
4. El problema del camino múltiple: push_or_update
En BFS y DFS, cuando descubrimos un vecino que ya está en la frontera, lo ignoramos — ya está pendiente. En búsqueda con pesos, eso puede ser un error: podríamos haber encontrado un camino más barato al mismo nodo.
Situación: nodo X ya está en la frontera con g(X) = 10.
Ahora encontramos un nuevo camino a X con g(X) = 6.
BFS haría: ignorar (X ya está en frontera)
Dijkstra/A* deben: actualizar la prioridad de X a g=6.
Llamamos a esta operación push_or_update:
si vecino no está en explorado:
nuevo_g ← g[nodo_actual] + costo(nodo_actual, vecino)
si vecino no está en frontera:
añadir vecino a frontera con prioridad f(vecino)
sino si nuevo_g < g[vecino]: ← ¡nuevo camino más barato!
actualizar prioridad de vecino en frontera
Esta es la única diferencia estructural entre el algoritmo genérico de módulo 13 y los algoritmos de este módulo.
Nota técnica — lazy deletion: actualizar la prioridad de un nodo en un heap estándar es O(n). En la práctica se usa lazy deletion: se añade la nueva entrada
(nuevo_g, nodo)al heap y se ignoran las entradas antiguas cuando se hacepop(si el nodo ya está en explorado). Los pseudocódigos en este módulo usanpush_or_updatepara claridad conceptual; los notebooks muestran la implementación con lazy deletion.
5. ¿Qué es $h(n)$?
Antes de ver los algoritmos, anticipamos brevemente la segunda cantidad nueva:
$$h(n) = \text{estimación del costo desde el nodo } n \text{ hasta la meta más cercana}$$
$h(n)$ es conocimiento del dominio — el diseñador del algoritmo lo proporciona, no se calcula automáticamente. El próximo capítulo lo define en detalle. Por ahora basta saber:
- $h(n) = 0$ → no tenemos información → el algoritmo es ciego → Dijkstra
- $h(n) > 0$ → tenemos una estimación → podemos guiar la búsqueda → Greedy o A*
6. Advertencia: pesos negativos
Los algoritmos de este módulo (Dijkstra, A*) asumen pesos de arista no negativos. Con pesos negativos, la garantía “primer pop = costo óptimo” deja de ser válida — un camino que parece caro al principio podría volverse barato al atravesar una arista negativa. Para grafos con pesos negativos, usa el algoritmo de Bellman-Ford (O(VE), más lento pero correcto).
Siguiente: Heurísticas h(n) →