| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda informada (Greedy, Dijkstra, A*) |
Greedy best-first: seguir el instinto
“Greedy algorithms: at each step, take the best option available right now.”
Greedy es busqueda_generica con frontera = ColaDePrioridad(key=h). La única diferencia respecto a BFS es el tipo de frontera: en lugar de una cola FIFO, usamos una cola de prioridad ordenada por $h(n)$ — la heurística. El algoritmo siempre expande el nodo que parece más cercano a la meta.
1. Intuición: ir directo al objetivo
¿Para qué sirve Greedy? Úsalo cuando necesitas una solución rápidamente y no te importa si es óptima. Greedy aprovecha todo el conocimiento del dominio encapsulado en $h(n)$ para moverse lo más directamente posible hacia la meta.
La estrategia es simple: en cada paso, expande el nodo que tiene el menor valor de $h(n)$ — el que está “más cerca” de la meta según nuestra estimación. No mira el pasado (cuánto costó llegar aquí), solo el futuro (cuánto cuesta llegar a la meta desde aquí).
Esto tiene una consecuencia inmediata: Greedy puede ser muy rápido cuando la heurística guía bien. En casos ideales (sin paredes, obstáculos, ni caminos engañosos), puede ir casi en línea recta desde el inicio hasta la meta.
Pero también tiene un problema grave: Greedy es codicioso y cortoplacista. Puede meterse en un callejón sin salida atractivo (bajo $h$) sin darse cuenta de que el verdadero camino óptimo requería alejarse brevemente de la meta antes de acercarse.
2. En lenguaje natural
La pregunta que Greedy responde es: “¿cuál es el camino que parece más corto a la meta en cada paso?” — no necesariamente el más barato ni el más corto real.
- Crea una cola de prioridad con el nodo inicial (prioridad = $h(\text{inicio})$).
- Mientras la cola no esté vacía:
- Saca el nodo con menor $h(n)$ — el que parece más cercano a la meta.
- Si es la meta, reconstruye y devuelve el camino.
- Márcalo como explorado.
- Para cada vecino no explorado, calcula $h(\text{vecino})$ y añádelo a la cola.
- Si la cola se vacía sin encontrar la meta, devuelve fallo.
La diferencia con BFS: el paso 2.1 saca el nodo con menor $h(n)$ en lugar del más antiguo. La diferencia con A*: no se rastrea $g(n)$ — Greedy ignora completamente cuánto ha costado llegar hasta aquí.
3. Pseudocódigo
function GREEDY(problema, h):
# ── Inicialización ─────────────────────────────────────────────────
frontera ← new PriorityFrontier()
frontera.push(problema.inicio, priority=h(problema.inicio))
# ↑ prioridad = h(n), NO g(n) — Greedy ignora el costo acumulado
explorado ← empty set
padre ← { problema.inicio: null }
# ── Bucle principal ─────────────────────────────────────────────────
while frontera is not empty:
nodo ← frontera.pop() # [P1] saca el nodo con MENOR h(n)
# ← única diferencia con BFS
if problema.is_goal(nodo):
return reconstruct(padre, nodo)
explorado.add(nodo)
for each (vecino, costo) in problema.neighbors(nodo):
if vecino not in explorado and vecino not in frontera:
padre[vecino] ← nodo
frontera.push(vecino, priority=h(vecino)) # [P2] prioridad = h solo
return FAILURE
Diferencia mínima respecto a GENERIC-SEARCH: solo cambia el tipo de frontera (PriorityFrontier con key=h) y la condición de vecinos no chequea si hay camino más barato (no hay $g$ que comparar).
Versión con PriorityFrontier
class PriorityFrontier:
"""Cola de prioridad — siempre saca el nodo con menor f(n)."""
def __init__(self):
self.heap = [] # (prioridad, nodo)
self.miembros = {} # nodo → prioridad actual
def push(self, nodo, priority):
heapq.heappush(self.heap, (priority, nodo))
self.miembros[nodo] = priority
def pop(self):
while self.heap:
pri, nodo = heapq.heappop(self.heap)
if nodo in self.miembros and self.miembros[nodo] == pri:
del self.miembros[nodo]
return nodo
return None
def contains(self, nodo):
return nodo in self.miembros
def is_empty(self):
return not self.miembros
# Greedy = GENERIC-SEARCH con PriorityFrontier(key=h)
frontera = PriorityFrontier()
frontera.push(inicio, priority=h(inicio))
La tabla completa de instancias:
| Frontera | pop() devuelve |
Algoritmo |
|---|---|---|
ColaDeFrontera (FIFO) |
el más antiguo | BFS |
PilaDeFrontera (LIFO) |
el más reciente | DFS |
PilaConLimite(d) |
el más reciente hasta prof. $d$ | IDDFS |
PriorityFrontier(key=h) |
el de menor $h(n)$ | Greedy |
PriorityFrontier(key=g) |
el de menor $g(n)$ | Dijkstra |
PriorityFrontier(key=g+h) |
el de menor $f(n)=g+h$ | A* |
4. Ejemplo paso a paso
Grafo ponderado con 5 nodos. $h$ = distancia Manhattan al nodo G.
Aristas dirigidas y pesos:
S→A: 1 S→B: 4 A→C: 1 A→G: 10 B→C: 1 C→G: 2
Posiciones de cuadrícula (para calcular h):
S=(0,0) A=(0,2) B=(3,0) C=(2,2) G=(3,4)
h(n) = Manhattan a G=(3,4):
h(S)=7 h(A)=5 h(B)=4 h(C)=3 h(G)=0
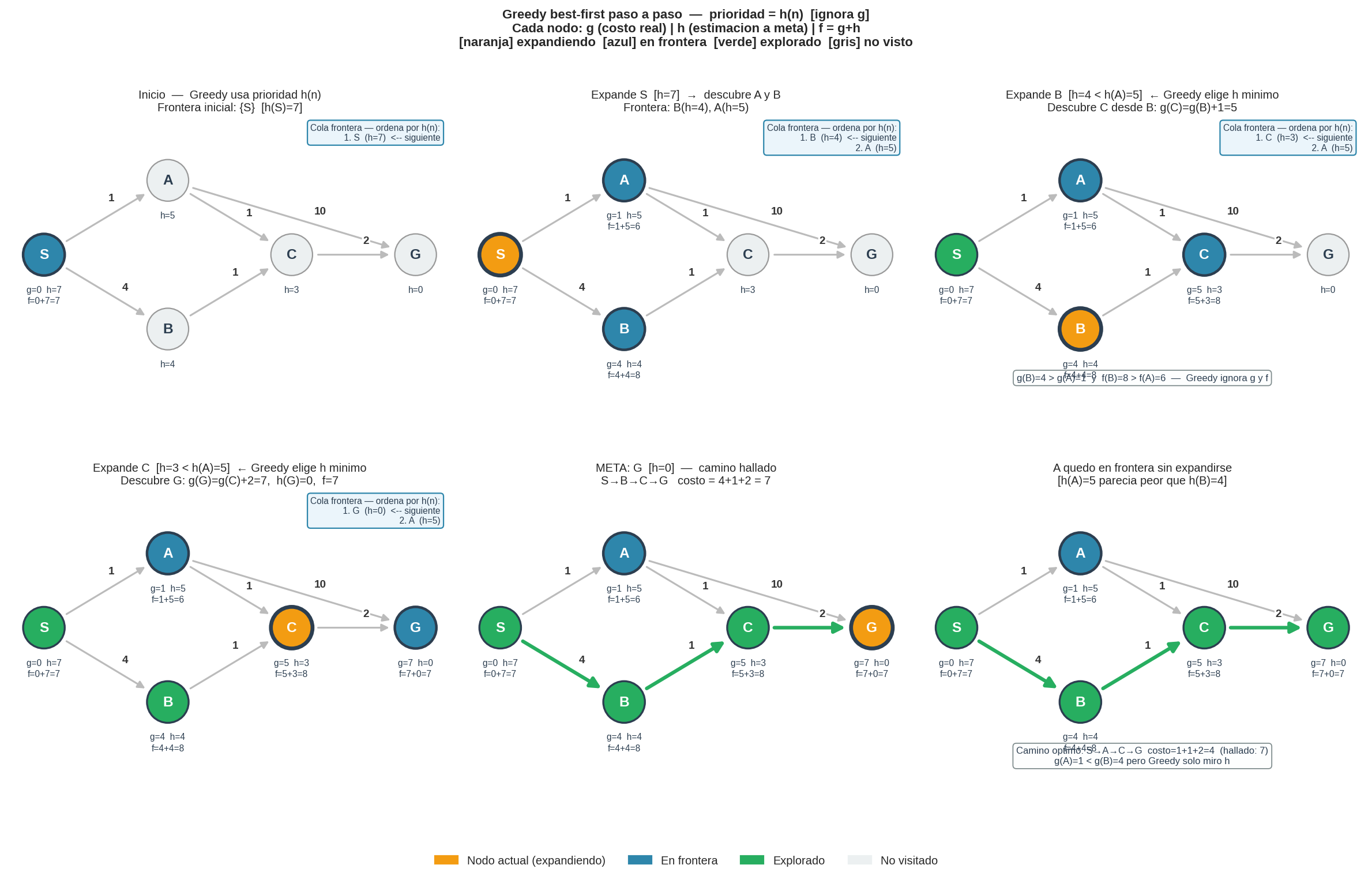
| Paso | Nodo expandido | $h(n)$ | Frontera tras expansión | Nota |
|---|---|---|---|---|
| 1 | S | 7 | {B:4, A:5} | Añade vecinos A y B |
| 2 | B | 4 | {C:3, A:5} | h(B)=4 < h(A)=5 — Greedy prefiere B |
| 3 | C | 3 | {G:0, A:5} | Añade G |
| 4 | G | 0 | — | ¡Meta! Camino: S→B→C→G, costo=7 |
Camino devuelto: S → B → C → G con costo 7.
¿Es óptimo? No. El camino óptimo es S → A → C → G con costo 4 (1+1+2). Greedy falló porque $h(B)=4 < h(A)=5$ — pero S→B cuesta 4 y S→A solo 1. Al ignorar $g(n)$, Greedy eligió el camino con la arista cara. El panel 6 de la imagen muestra que A quedó en la frontera sin ser expandido.
5. El caso de fallo: la pared engañosa
10×10 grid, Inicio=(1,1), Meta=(8,8)
Pared horizontal en fila 5, columnas 2–9
Único paso: columna 1 (izquierda)
La pared impide el camino directo.
El camino óptimo rodea por la izquierda.
Greedy ve que la meta está abajo-a-la-derecha y sigue expandiendo en esa dirección hasta chocar con la pared. Al no poder avanzar, retrocede pero ha expandido muchos nodos inútiles a la derecha, y el camino final es más largo que el óptimo.
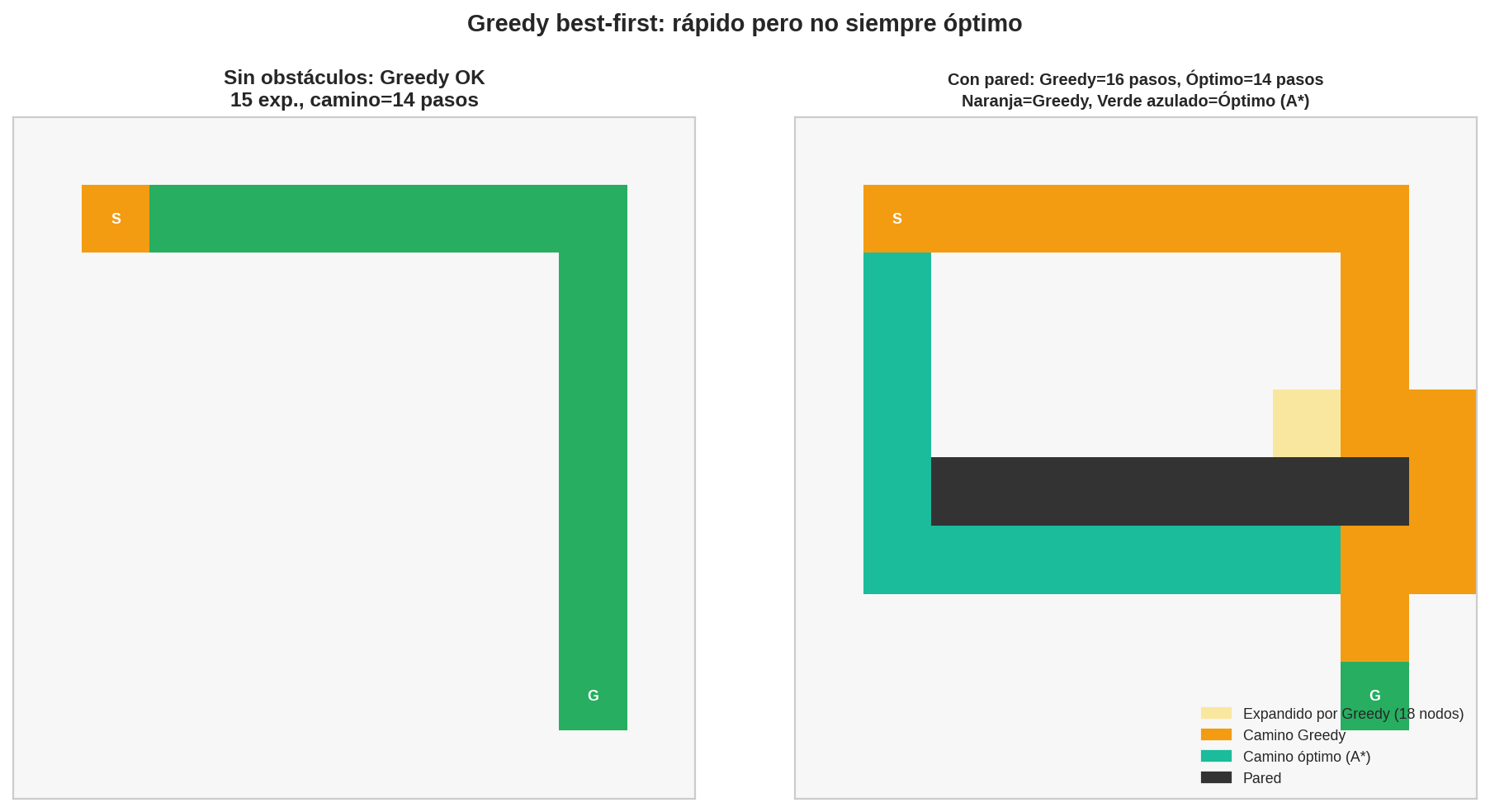
El panel derecho muestra exactamente este escenario: Greedy expande nodos en la dirección equivocada, mientras A* (en verde azulado) encuentra el rodeo óptimo por la izquierda directamente.
6. Implementación Python
import heapq
def greedy(problema, h):
"""
Greedy best-first.
h: callable h(nodo) → estimación al objetivo.
Devuelve (camino, nodos_expandidos) o (None, nodos_expandidos).
"""
inicio = problema.inicio
frontera = [(h(inicio), inicio)] # min-heap por h(n)
en_frontera = {inicio}
explorado = set()
padre = {inicio: None}
nodos_expandidos = 0
while frontera:
_, nodo = heapq.heappop(frontera)
if nodo not in en_frontera: # entrada obsoleta (lazy deletion)
continue
en_frontera.discard(nodo)
if problema.es_meta(nodo):
return reconstruir_camino(padre, nodo), nodos_expandidos
explorado.add(nodo)
nodos_expandidos += 1
for vecino, _ in problema.vecinos(nodo): # ignora el costo
if vecino not in explorado and vecino not in en_frontera:
padre[vecino] = nodo
heapq.heappush(frontera, (h(vecino), vecino))
en_frontera.add(vecino)
return None, nodos_expandidos
Punto clave: la línea for vecino, _ in problema.vecinos(nodo) ignora el costo de la arista (_). Greedy no necesita saber cuánto costó llegar aquí. Esa es la diferencia fundamental con Dijkstra y A*.
7. Completitud y optimalidad
| Propiedad | Greedy | Condición |
|---|---|---|
| Completo | Sí* | En grafos finitos con conjunto explorado |
| Óptimo | No | Puede encontrar caminos subóptimos (ejemplo de la pared) |
*Sin conjunto explorado, Greedy puede entrar en ciclos infinitos.
¿Por qué no es óptimo? Porque ignora $g(n)$. Si un camino caro lleva a un nodo con bajo $h$, Greedy lo preferirá sobre un camino barato que lleva a un nodo con $h$ algo mayor — aunque el segundo sea globalmente mejor.
8. Complejidad de tiempo y espacio
Tiempo
En el peor caso: $O(b^m)$ — igual que DFS. Si la heurística guía mal (o el problema tiene muchos callejones sin salida con bajo $h$), Greedy puede explorar todo el grafo.
En el mejor caso (heurística perfecta, $h = h^{∗}$): $O(d)$ — expande solo los nodos del camino óptimo.
La diferencia entre estos extremos puede ser enorme. El comportamiento real depende completamente de la calidad de $h$.
Espacio
$O(b^m)$ en el peor caso — igual que BFS. La frontera puede llenarse con todos los nodos descubiertos.
Recordatorio: $b$ = factor de ramificación (máximo de vecinos), $d$ = prof. de la solución, $m$ = prof. máxima del grafo. Definidos en 03 — Algoritmo genérico →.
9. ¿Cuándo usar Greedy?
Usa Greedy cuando:
| Señal del problema | ¿Por qué favorece Greedy? |
|---|---|
| La velocidad importa más que la optimalidad | Greedy no rastrea $g$ ni actualiza costos → más rápido |
| Tienes una heurística muy buena | Si $h \approx h^{∗}$, Greedy va casi directamente a la meta |
| El problema es de “buena-suficiente” solución | NPC en videojuegos, prototipado rápido |
| El espacio de estados es enorme | Greedy explora menos que Dijkstra en casos favorables |
Ejemplo real: NPC pathfinding en videojuegos. Los personajes no jugadores necesitan encontrar rutas en tiempo real, a 60 fps, en mapas grandes. Una pequeña imprecisión en la ruta no importa visualmente. Greedy da rutas “suficientemente buenas” con mucho menos cómputo que A*.
Señales de alerta:
- El problema tiene paredes o zonas que parecen atractivas pero son callejones sin salida (Greedy se atasca).
- Necesitas garantía de camino óptimo (usa A* o Dijkstra).
- La heurística es poco confiable o constante cero (Greedy degenera a DFS desordenado).
10. Resumen
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Cola de prioridad por $h(n)$ | Siempre expande el nodo “más cercano” a la meta |
| Tiempo | $O(b^m)$ peor / $O(d)$ mejor | Depende enteramente de la calidad de $h$ |
| Espacio | $O(b^m)$ peor | Frontera puede contener todos los nodos descubiertos |
| Completo | Sí (finito + explorado) | Sin explorado, puede ciclar |
| Óptimo | No | Ignora $g(n)$ — puede pagar demasiado |
Recordatorio de notación: $b$ = factor de ramificación (máximo de vecinos; peor caso), $d$ = profundidad de la solución, $m$ = profundidad máxima del grafo. Definidos en 03 — Algoritmo genérico →.
Siguiente: Dijkstra: el costo mínimo garantizado →