| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda informada (Greedy, Dijkstra, A*) |
Dijkstra: el costo mínimo garantizado
"Dijkstra’s algorithm solves the single-source shortest path problem on a graph with non-negative edge weights."
Dijkstra es busqueda_generica con frontera = ColaDePrioridad(key=g). Es A* con $h(n) = 0$ para todo $n$ — no usa ninguna estimación hacia la meta, solo rastrea cuánto costó llegar aquí. A cambio, garantiza el camino de menor costo a todos los nodos alcanzables desde el inicio.
1. Intuición: inundación por costo
¿Por qué Greedy no es suficiente? Greedy va hacia donde parece más cercana la meta, pero puede meterse en caminos baratos hacia un nodo equivocado. Necesitamos un algoritmo que expanda siempre el nodo más barato disponible — sin importar dónde esté la meta.
La imagen mental es la de una inundación por costo: imagina verter agua en el nodo inicial. El agua se propaga por las aristas más baratas primero, luego las más caras. Cuando el agua llega a un nodo, lo hace por el camino de menor costo posible.
Esto tiene una propiedad poderosa: la primera vez que sacamos un nodo de la cola de prioridad, hemos encontrado el camino óptimo hasta él. No hay ningún camino alternativo más barato esperando ser descubierto, porque todos los nodos más baratos ya fueron procesados.
La consecuencia práctica: Dijkstra calcula el árbol de rutas mínimas desde el inicio hacia todos los nodos alcanzables — no solo hacia la meta. Esto lo hace ideal cuando necesitas responder múltiples consultas desde un mismo origen, o cuando no sabes de antemano cuál es la meta.
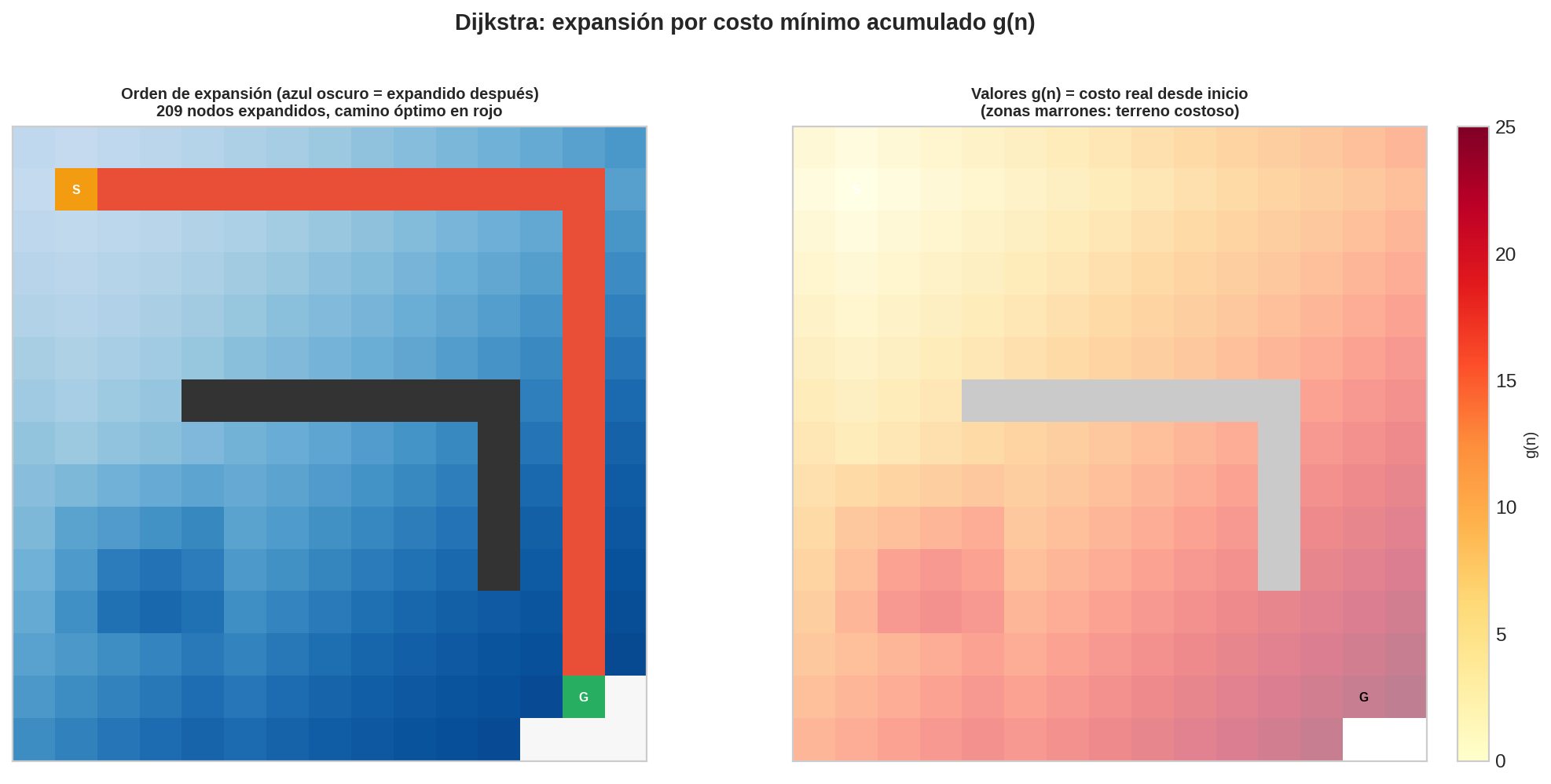
2. El problema con BFS: costos desiguales
BFS garantiza el camino con menos aristas. Pero en grafos con pesos, "menos aristas" ≠ "menor costo":
Grafo ponderado:
A ──1── B ──1── C ──1── Meta (3 saltos, costo = 3)
│
10
│
D ──────────────────1── Meta (2 saltos, costo = 11)
BFS responde: A → D → Meta (2 saltos — el más corto en hops)
Costo real: 10 + 1 = 11 ← ¡casi 4 veces más caro!
Dijkstra: A → B → C → Meta (3 saltos, costo = 1+1+1 = 3) ← óptimo
BFS eligió el camino de menos saltos, pero ese camino usa la arista cara A→D (costo 10). El camino óptimo tiene más saltos pero aristas baratas. Dijkstra usa una cola de prioridad para expandir siempre el nodo con menor $g(n)$ — el costo real acumulado desde el inicio.
3. En lenguaje natural
Dijkstra es busqueda_generica con una cola de prioridad ordenada por $g(n)$ como frontera. Compáralo con las fronteras que ya conoces:
| Frontera | ¿Qué saca primero? | Resultado |
|---|---|---|
| Cola FIFO | El nodo más antiguo (lleva más tiempo esperando) | BFS — menos saltos |
| Pila LIFO | El nodo más reciente (el último que entró) | DFS — profundidad primero |
| Cola de prioridad por $g$ | El nodo con menor costo acumulado hasta ahora | Dijkstra — menos costo |
La única diferencia con BFS es qué criterio usa el pop(). BFS saca el más antiguo; Dijkstra saca el más barato. Greedy saca el que tiene menor $h$ (estimación al objetivo); Dijkstra saca el que tiene menor $g$ (costo real hasta aquí). A* combina ambos.
Además Dijkstra necesita una cosa que BFS y Greedy no necesitan: actualizar nodos que ya están en la frontera si encontramos un camino más barato. Eso se llama relajar una arista (ver más abajo).
El algoritmo paso a paso:
-
Inicializa $g(\text{inicio}) = 0$ y $g(n) = \infty$ para todos los demás nodos.
Todavía no sabemos cómo llegar a nadie. El único costo conocido es llegar al inicio (costo 0).
-
Añade el nodo inicial a la cola de prioridad con prioridad $g = 0$.
-
Mientras la cola no esté vacía:
- Saca el nodo con menor $g(n)$ — el nodo más barato de llegar hasta ahora. Esto es el
pop()del algoritmo genérico. - Si es la meta, reconstruye y devuelve el camino.
- Márcalo como explorado — con pesos no negativos, el primer
popde un nodo ya es su costo óptimo definitivo. No hay camino más barato esperando en la cola. - Para cada vecino no explorado, intenta relajar la arista:
- Calcula $g_{\text{nuevo}} = g(\text{nodo actual}) + \text{costo arista}$.
- Si $g_{\text{nuevo}} < g(\text{vecino})$: encontramos un camino más barato a ese vecino. Actualiza $g(\text{vecino}) \leftarrow g_{\text{nuevo}}$, guarda el padre, y añade/actualiza en la cola.
- Si $g_{\text{nuevo}} \geq g(\text{vecino})$: el camino que ya teníamos es igual o mejor. No hacemos nada.
- Saca el nodo con menor $g(n)$ — el nodo más barato de llegar hasta ahora. Esto es el
-
Si la cola se vacía sin encontrar la meta, devuelve fallo.
¿Qué significa «relajar» una arista?
El nombre viene de la idea de que $g(n)$ empieza «tenso» (muy alto, en $\infty$) y se va relajando (bajando) conforme encontramos caminos más baratos.
Relajar la arista $(u, v)$ significa: «¿puedo llegar a $v$ más barato pasando por $u$ que por cualquier camino que conocía antes?»
Antes de relajar:
g[v] = 10 ← el mejor camino a v que conocemos cuesta 10
g[u] = 3 ← acabamos de expandir u con costo 3
costo(u→v) = 4
Calculamos: g_nuevo = g[u] + costo(u→v) = 3 + 4 = 7
¿7 < 10? Sí → RELAJAMOS: g[v] ← 7, padre[v] ← u
¿7 ≥ 10? No → No hacemos nada, el camino anterior era mejor
En BFS y Greedy, si un vecino ya está en la frontera simplemente lo ignoramos (ya está pendiente de procesarse). Dijkstra no puede hacer eso: podría haber descubierto un camino más barato al mismo nodo — y si no lo actualiza, terminará con una solución subóptima. La relajación es exactamente esa actualización.
4. Pseudocódigo
function DIJKSTRA(problema):
# ── Inicialización ────────────────────────────────────────────────────────
#
# g[n] = mejor costo conocido para llegar desde inicio hasta n.
# Al empezar no sabemos cómo llegar a ningún nodo, así que todo es ∞
# excepto el inicio, que cuesta 0 llegar (ya estamos ahí).
g ← { inicio: 0, todos los demás: ∞ }
# La frontera es una cola de PRIORIDAD ordenada por g(n).
# pop() siempre devuelve el nodo más barato de alcanzar hasta ahora.
# ← diferencia clave con BFS (FIFO) y Greedy (ordenada por h)
frontera ← new PriorityFrontier()
frontera.push(problema.inicio, priority=0)
# explorado = nodos cuyo camino óptimo ya está confirmado.
# Una vez dentro, nunca se vuelve a tocar.
explorado ← empty set
# padre[n] = el nodo desde el que llegamos a n por el camino más barato.
# Se usa al final para reconstruir el camino completo.
padre ← { problema.inicio: null }
# ── Bucle principal ───────────────────────────────────────────────────────
while frontera is not empty:
# Extraemos el nodo con MENOR g(n) — el más barato de todos los pendientes.
# Con pesos ≥ 0, este es su costo óptimo definitivo: ningún camino futuro
# puede ser más barato (los costos solo pueden crecer o mantenerse).
# ← esto es lo que distingue a Dijkstra de BFS (que sacaría el más antiguo)
nodo ← frontera.pop()
if problema.is_goal(nodo):
return reconstruct(padre, nodo) # reconstruye el camino via padre[]
# Marcamos como explorado: ya conocemos el camino óptimo a este nodo.
# Nunca lo volveremos a procesar aunque aparezca en la frontera otra vez.
explorado.add(nodo)
# Miramos cada vecino y preguntamos: ¿pasar por `nodo` mejora
# el mejor camino conocido a ese vecino?
for each (vecino, costo_arista) in problema.neighbors(nodo):
# Saltamos vecinos ya confirmados: su costo óptimo ya está fijo.
if vecino in explorado:
continue
# Calculamos cuánto costaría llegar a `vecino` pasando por `nodo`.
g_nuevo = g[nodo] + costo_arista
# ── RELAJACIÓN ────────────────────────────────────────────────────
# ¿Es este nuevo camino más barato que el mejor que conocíamos?
# Sí → actualizamos: este nuevo camino es mejor, lo registramos.
# No → ignoramos: el camino anterior ya era igual o mejor.
#
# Diferencia con BFS/Greedy: ellos ignoran vecinos ya en la frontera.
# Dijkstra los ACTUALIZA si encontró un camino más barato.
if g_nuevo < g.get(vecino, ∞):
g[vecino] = g_nuevo # nuevo mejor costo a vecino
padre[vecino] = nodo # venimos desde nodo
frontera.push_or_update(vecino, priority=g_nuevo)
# ↑ si vecino ya estaba en frontera con g mayor, lo actualizamos
# si no estaba, lo añadimos por primera vez
return FAILURE # la meta no es alcanzable desde el inicio
Diferencias respecto a Greedy y BFS en una línea cada una:
| Línea | BFS | Greedy | Dijkstra |
|---|---|---|---|
pop() devuelve |
El más antiguo (FIFO) | El menor $h$ (estimación) | El menor $g$ (costo real) |
| ¿Rastrea $g$? | No | No | Sí — es la clave |
| ¿Actualiza frontera? | No (ignora si ya está) | No | Sí — relajación |
Versión con PriorityFrontier
class PriorityFrontier:
"""Cola de prioridad con actualización de prioridad (lazy deletion)."""
def __init__(self):
self.heap = [] # (prioridad, nodo)
self.miembros = {} # nodo → prioridad actual
def push(self, nodo, priority):
heapq.heappush(self.heap, (priority, nodo))
self.miembros[nodo] = priority
def push_or_update(self, nodo, priority):
"""Si nodo ya está, actualiza su prioridad (lazy deletion)."""
self.miembros[nodo] = priority # siempre guarda la mejor
heapq.heappush(self.heap, (priority, nodo)) # entrada nueva; la vieja se ignora al hacer pop
def pop(self):
while self.heap:
pri, nodo = heapq.heappop(self.heap)
if nodo in self.miembros and self.miembros[nodo] == pri:
del self.miembros[nodo]
return nodo
return None
def contains(self, nodo):
return nodo in self.miembros
def is_empty(self):
return not self.miembros
# Dijkstra = GENERIC-SEARCH con PriorityFrontier(key=g)
g = {inicio: 0}
frontera = PriorityFrontier()
frontera.push(inicio, priority=0)
La tabla completa de instancias:
| Frontera | pop() devuelve |
Algoritmo |
|---|---|---|
ColaDeFrontera (FIFO) |
el más antiguo | BFS |
PilaDeFrontera (LIFO) |
el más reciente | DFS |
PilaConLimite(d) |
el más reciente hasta prof. $d$ | IDDFS |
PriorityFrontier(key=h) |
el de menor $h(n)$ | Greedy |
PriorityFrontier(key=g) |
el de menor $g(n)$ | Dijkstra |
PriorityFrontier(key=g+h) |
el de menor $f(n)=g+h$ | A* |
5. La relajación: qué es y por qué importa
La relajación de una arista $(u, v)$ con costo $c$ consiste en preguntar: ¿es el camino que pasa por $u$ hacia $v$ más barato que el mejor camino que conocemos a $v$ hasta ahora?
Antes de relajar: g[v] = 10 (camino antiguo)
Arista u → v: g[u] = 3, costo = 4
g_nuevo = g[u] + costo = 3 + 4 = 7 < 10
Después de relajar: g[v] = 7 ← ¡actualización!
padre[v] = u
Cada relajación exitosa significa que encontramos un camino más barato a algún nodo. Dijkstra garantiza que cuando un nodo sale de la cola de prioridad, ya no puede ser relajado más — su $g(n)$ es definitivo.
6. Ejemplo paso a paso
El mismo grafo que usaremos también para A* — los tres algoritmos comparados en el mismo problema.
Aristas dirigidas y pesos:
S→A: 1 S→B: 4 A→C: 1 A→G: 10 B→C: 1 C→G: 2
Posiciones de cuadrícula (para calcular h en A*):
S=(0,0) A=(0,2) B=(3,0) C=(2,2) G=(3,4)
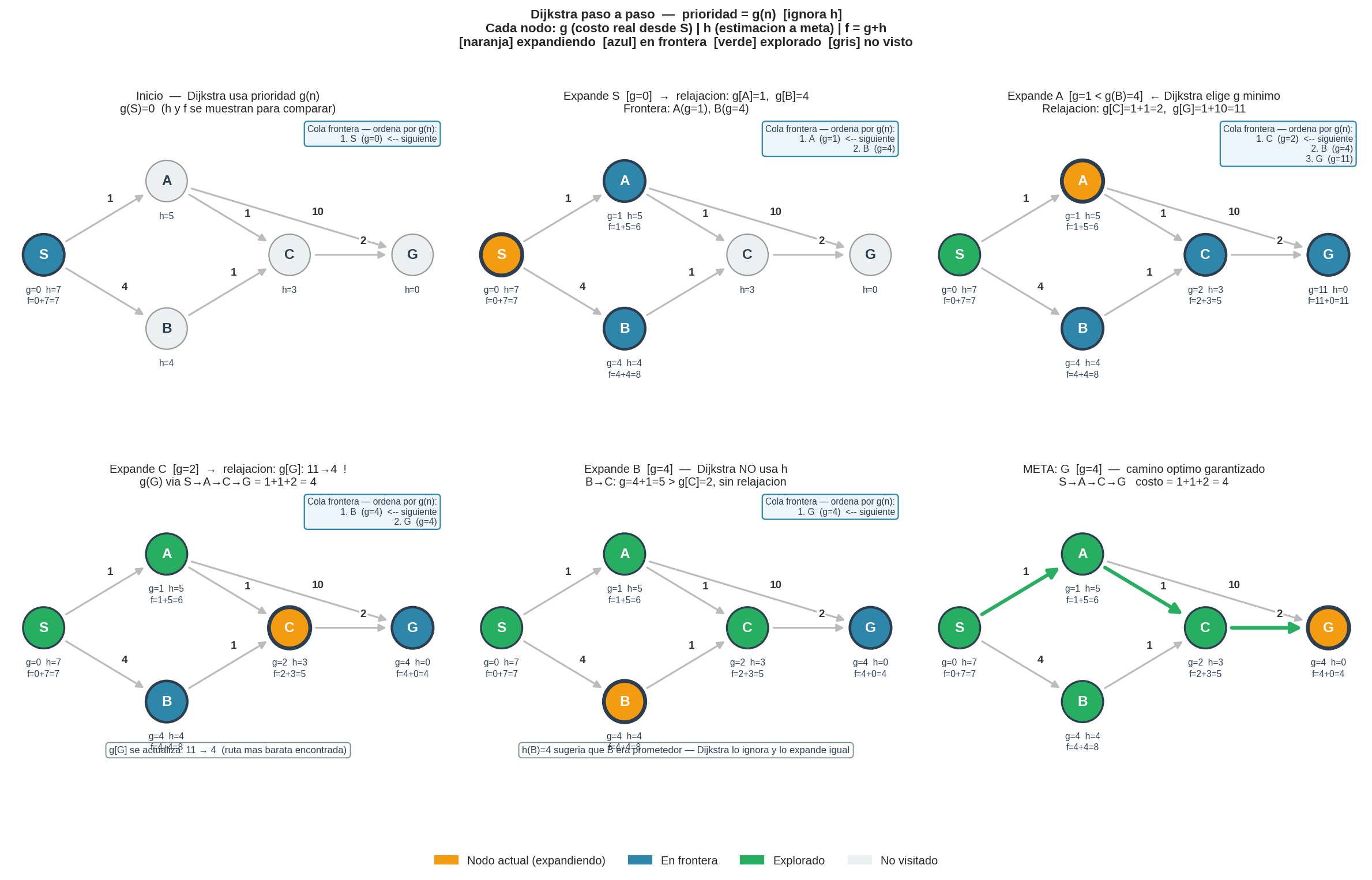
| Paso | Nodo expandido | $g(n)$ | Relajaciones realizadas | Frontera (g valores) |
|---|---|---|---|---|
| 1 | S | 0 | g[A]=1, g[B]=4 | {A:1, B:4} |
| 2 | A | 1 | g[C]=2, g[G]=11 | {C:2, B:4, G:11} |
| 3 | C | 2 | g[G]: 11 → 4 | {B:4, G:4} |
| 4 | B | 4 | B→C: 4+1=5 > g[C]=2, sin cambio | {G:4} |
| 5 | G | 4 | ¡Meta! | — |
Camino devuelto: S → A → C → G con costo total 4.
¿Dónde ocurrió la relajación interesante? En el paso 3, al expandir C se descubrió un camino más barato hasta G: en lugar de S→A→G (costo=11), ahora S→A→C→G (costo=4). Eso es exactamente la relajación: $g[G]$ se actualiza de 11 a 4.
Contraste con Greedy: Greedy expande B antes que A (porque $h(B)=4 < h(A)=5$) y encuentra S→B→C→G (costo=7). Dijkstra expande A antes que B (porque $g(A)=1 < g(B)=4$) y llega al camino óptimo.
7. ¿Por qué el conjunto explorado es válido?
Con Dijkstra, cuando sacamos un nodo de la cola de prioridad, su $g(n)$ es definitivo. La demostración informal:
Si existiera un camino más barato a $n$, tendría que pasar por algún nodo $u$ con $g(u) < g(n)$ que todavía no hemos explorado. Pero si $g(u) < g(n)$, entonces $u$ habría salido de la cola antes que $n$, y ya habría sido explorado. Contradicción.
Este argumento requiere que todos los pesos sean no negativos. Con pesos negativos, añadir una arista podría hacer que un camino que parecía caro se vuelva el más barato — y el razonamiento anterior colapsa.
8. Implementación Python
import heapq
def dijkstra(problema):
"""
Dijkstra: camino de costo mínimo desde inicio hasta meta.
Devuelve (camino, nodos_expandidos) o (None, nodos_expandidos).
"""
inicio = problema.inicio
g = {inicio: 0}
frontera = [(0, inicio)] # min-heap: (g(n), nodo)
en_frontera = {inicio: 0} # nodo → mejor g visto
explorado = set()
padre = {inicio: None}
nodos_expandidos = 0
while frontera:
g_actual, nodo = heapq.heappop(frontera)
if nodo not in en_frontera or en_frontera[nodo] != g_actual:
continue # entrada obsoleta (lazy deletion)
del en_frontera[nodo]
if problema.es_meta(nodo):
return reconstruir_camino(padre, nodo), nodos_expandidos
explorado.add(nodo)
nodos_expandidos += 1
for vecino, costo in problema.vecinos(nodo): # usa el costo ← diferencia con Greedy
if vecino not in explorado:
g_nuevo = g_actual + costo
if g_nuevo < g.get(vecino, float('inf')):
g[vecino] = g_nuevo
padre[vecino] = nodo
heapq.heappush(frontera, (g_nuevo, vecino))
en_frontera[vecino] = g_nuevo
return None, nodos_expandidos
Punto clave: la línea for vecino, costo in problema.vecinos(nodo) usa el costo de la arista — al contrario que Greedy, que lo descartaba con _. Esa es la diferencia fundamental.
9. Completitud y optimalidad
| Propiedad | Dijkstra | Condición |
|---|---|---|
| Completo | Sí* | En grafos finitos con conjunto explorado |
| Óptimo | Sí | Si todos los pesos de arista son $\geq 0$ |
*Sin explorado, puede ciclar en grafos con ciclos.
¿Por qué es óptimo? Porque siempre expande el nodo con menor $g(n)$ conocido, y con pesos no negativos, la primera expansión ya es definitiva (ver sección 7).
10. Complejidad de tiempo y espacio
Tiempo
Con un binary heap (como heapq de Python):
$$O((V + E) \log V)$$
- $V$ = número de vértices (nodos)
- $E$ = número de aristas
- Cada nodo entra y sale de la cola una vez: $O(V \log V)$
- Cada arista puede causar una relajación (inserción en heap): $O(E \log V)$
Con una Fibonacci heap (más compleja de implementar): $O(V \log V + E)$ — óptimo en teoría.
Espacio
$O(V + E)$ — hay que almacenar el grafo, el diccionario $g$, la cola de prioridad, y el diccionario padre.
Recordatorio: $V$ = nodos, $E$ = aristas. En grafos densos $E \approx V^2$, en grafos dispersos $E \approx V$.
Para comparar con los algoritmos del módulo anterior: si $b$ = factor de ramificación y $d$ = profundidad de la solución, entonces $V \approx b^d$ y $E \approx V \cdot b$, por lo que la complejidad de Dijkstra en un árbol de búsqueda es $O(b^d \log b)$, similar a BFS pero con el $\log b$ por las operaciones de heap.
11. ¿Cuándo usar Dijkstra?
Usa Dijkstra cuando:
| Señal del problema | ¿Por qué favorece Dijkstra? |
|---|---|
| No tienes heurística | Si $h(n) = 0$, A* se convierte exactamente en Dijkstra |
| Necesitas rutas a todos los nodos | Dijkstra calcula el árbol completo de caminos mínimos |
| El grafo tiene pesos variables | BFS falla; Dijkstra garantiza optimalidad |
| Los pesos son no negativos | Condición necesaria para la garantía de optimalidad |
Ejemplo real: enrutamiento de red. Los routers usan versiones de Dijkstra (OSPF — Open Shortest Path First) para calcular las rutas de menor costo en una red. Cada router construye el árbol de caminos mínimos desde sí mismo hacia todos los demás routers. Las métricas de costo incluyen ancho de banda, latencia y confiabilidad.
Dijkstra vs A*:
| Dijkstra | A* | |
|---|---|---|
| ¿Necesita heurística? | No | Sí |
| ¿Óptimo? | Sí | Sí (si $h$ es admisible) |
| ¿Expande todos los nodos? | Sí, en todas direcciones | No — se enfoca hacia la meta |
| Mejor cuando | Sin heurística disponible, o se necesitan rutas a todos los nodos | Hay una buena heurística y se busca un destino específico |
Si conoces la meta y puedes calcular una heurística admisible, A* expandirá muchos menos nodos que Dijkstra.
Señales de alerta:
- El grafo tiene pesos negativos → usa Bellman-Ford ($O(VE)$).
- Necesitas la ruta entre todos los pares de nodos → usa Floyd-Warshall ($O(V^3)$).
- Tienes una buena heurística y solo te importa un destino → usa A*.
12. Resumen
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Cola de prioridad por $g(n)$ | Siempre expande el nodo más barato hasta ahora |
| Tiempo | $O((V+E) \log V)$ | Binary heap; $V$ pops + $E$ inserciones |
| Espacio | $O(V + E)$ | Grafo + cola + diccionarios |
| Completo | Sí (finito + explorado) | Sin explorado, puede ciclar |
| Óptimo | Sí (pesos ≥ 0) | Primer pop = costo definitivo |
Conexión con A*: Dijkstra es A* con $h(n) = 0$ para todo $n$. Todo lo que aprenderemos sobre A* (admisibilidad, consistencia, conjunto explorado) se hereda directamente de las propiedades que acabamos de demostrar para Dijkstra.
Siguiente: A*: lo mejor de los dos mundos →