| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda informada (Greedy, Dijkstra, A*) |
A*: lo mejor de los dos mundos
"A* is the most widely-known form of best-first search. It finds the least-cost path from the given initial node to one goal node, out of one or more possible goals." — Peter Hart, Nils Nilsson, Bertram Raphael (1968)
A* es busqueda_generica con frontera = ColaDePrioridad(key=f) donde $f(n) = g(n) + h(n)$.
Es la síntesis de todo lo que hemos visto:
- De Dijkstra: rastrea $g(n)$ — el costo real acumulado hasta $n$.
- De Greedy: usa $h(n)$ — la estimación heurística del costo restante.
- Juntos: $f(n) = g(n) + h(n)$ es la estimación del costo total del camino que pasa por $n$.
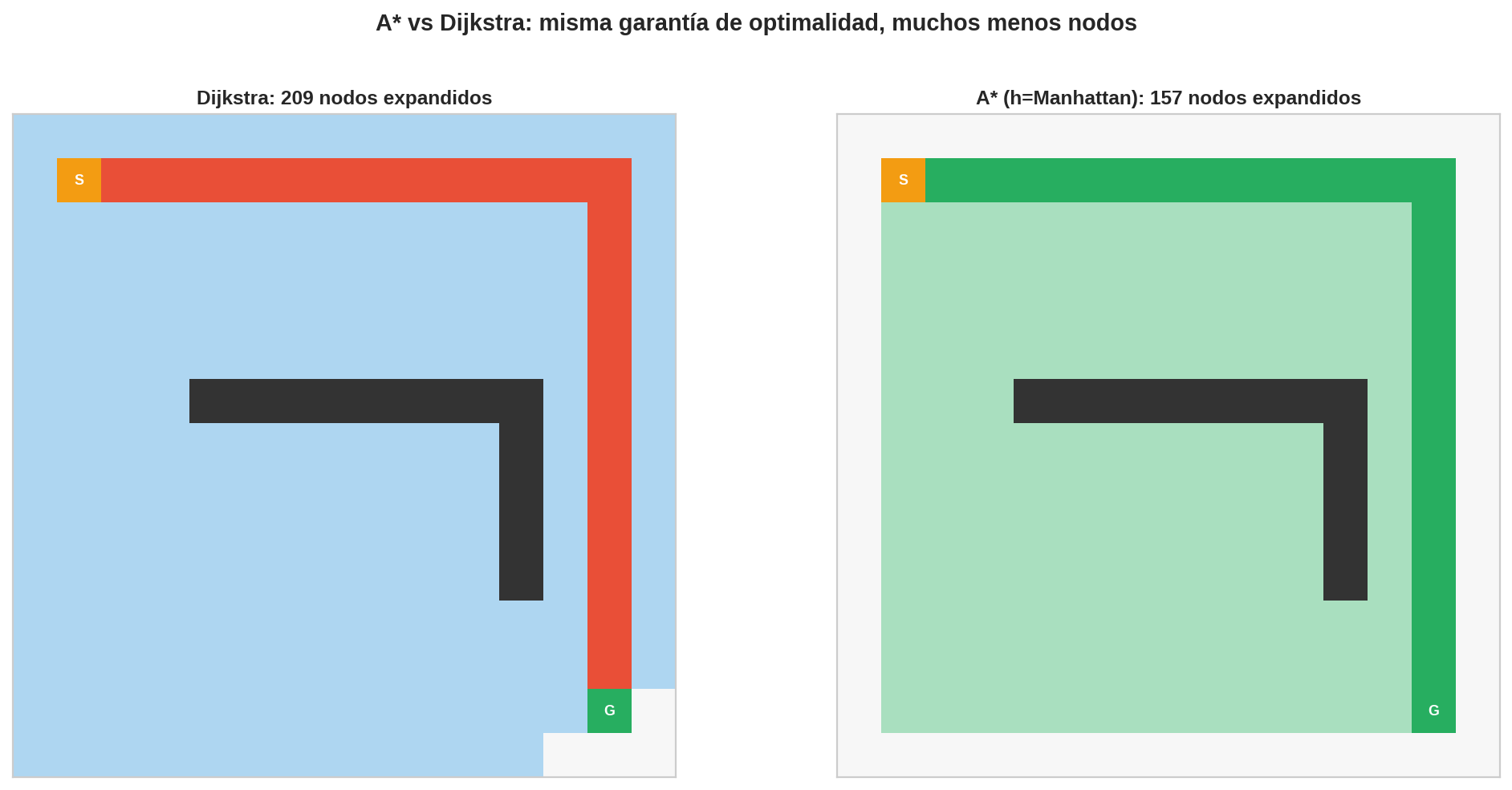
Greedy llegaba rápido pero podía equivocarse porque ignoraba $g$. Dijkstra encontraba el óptimo pero exploraba en todas direcciones porque ignoraba $h$. A* encuentra el camino óptimo expandiendo los nodos más prometedores primero.
1. Intuición: estimar el costo total del camino
La pregunta que A* responde en cada paso es: "¿qué nodo tiene la mejor estimación del costo total del camino que pasa por él hasta la meta?"
$$f(n) = \underbrace{g(n)}{\text{costo ya pagado}} + \underbrace{h(n)}{\text{costo estimado restante}}$$
Si $h$ es perfecta ($h(n) = h^{∗}(n)$ para todo $n$), A* solo expande los nodos del camino óptimo. En la práctica, $h$ es una subestimación admisible, y A* expande solo aquellos nodos que podrían estar en el camino óptimo — una búsqueda enfocada y exacta.
La imagen mental: A* es como un explorador con mapa parcial. Sabe cuánto ha caminado ($g$) y puede estimar cuánto falta ($h$). Siempre elige la ruta que parece tener el menor costo total, no solo la que parece más cercana a la meta ni la más barata hasta ahora.
2. Pseudocódigo
function A_STAR(problema, h):
# ── Inicialización ─────────────────────────────────────────────────
g ← dict con g[problema.inicio] = 0 y g[n] = ∞ para el resto
frontera ← new PriorityFrontier()
frontera.push(problema.inicio, priority=g[inicio] + h(inicio))
# ↑ prioridad = f(n) = g(n) + h(n) ← única diferencia con Dijkstra
explorado ← empty set
padre ← { problema.inicio: null }
# ── Bucle principal ─────────────────────────────────────────────────
while frontera is not empty:
nodo ← frontera.pop() # [P1] saca el nodo con MENOR f(n)
if problema.is_goal(nodo):
return reconstruct(padre, nodo)
explorado.add(nodo) # [P2] con h consistente: primera vez = óptimo
for each (vecino, costo) in problema.neighbors(nodo):
if vecino not in explorado:
g_nuevo = g[nodo] + costo
if g_nuevo < g.get(vecino, ∞): # [P3] relajación
g[vecino] = g_nuevo
padre[vecino] = nodo
f_vecino = g_nuevo + h(vecino) # [P4] f = g + h ← diferencia con Dijkstra
frontera.push_or_update(vecino, priority=f_vecino)
return FAILURE
Diferencia mínima respecto a Dijkstra: solo cambia la línea [P4] — la prioridad usa g + h en lugar de solo g. El resto del algoritmo es idéntico.
3. Admisibilidad → optimalidad
Si $h$ es admisible ($h(n) \leq h^{∗}(n)$ para todo $n$), entonces A* encuentra el camino óptimo.
Demostración informal por contradicción: supón que A* devuelve un camino subóptimo con costo $C > C^{∗}$ (donde $C^{∗}$ es el costo óptimo). En el momento en que se expandió el nodo meta por ese camino caro, debe existir un nodo $n$ en la frontera que esté en el camino óptimo y aún no haya sido expandido. Su valor $f(n)$ satisface:
$$f(n) = g(n) + h(n) \leq g(n) + h^{∗}(n) = C^{∗} < C$$
Entonces $f(n) < C$ — el nodo $n$ debería haberse sacado de la cola antes que la meta subóptima. Contradicción.
La clave: la admisibilidad garantiza que $f$ nunca sobreestima el costo del camino óptimo que pasa por $n$. Ningún nodo en el camino óptimo puede ser descartado porque su $f$ parezca demasiado alto.
4. Consistencia → sin reapertura
Si $h$ es consistente ($h(n) \leq \text{costo}(n, n’) + h(n’)$ para toda arista), entonces:
- Los valores de $f$ son monótonamente no decrecientes a lo largo de cualquier camino.
- La primera vez que A* expande un nodo, ya tiene su costo óptimo.
- Nunca necesitamos reabrir un nodo del conjunto explorado.
Esto hace que el conjunto explorado funcione exactamente igual que en Dijkstra. En la práctica, la mayoría de heurísticas útiles son consistentes (Manhattan, Euclidiana, etc.), así que la implementación que hemos visto es correcta.
Sin consistencia (solo admisibilidad), A* podría necesitar reabrir nodos ya explorados — la implementación se complica. En ese caso, hay que comparar si el nuevo $g$ es menor antes de añadir al explorado.
5. Ejemplo paso a paso
El mismo grafo que Greedy y Dijkstra — los tres algoritmos sobre el mismo problema para comparar directamente.
Aristas dirigidas y pesos:
S→A: 1 S→B: 4 A→C: 1 A→G: 10 B→C: 1 C→G: 2
Posiciones de cuadrícula:
S=(0,0) A=(0,2) B=(3,0) C=(2,2) G=(3,4)
h(n) = Manhattan a G=(3,4):
h(S)=7 h(A)=5 h(B)=4 h(C)=3 h(G)=0
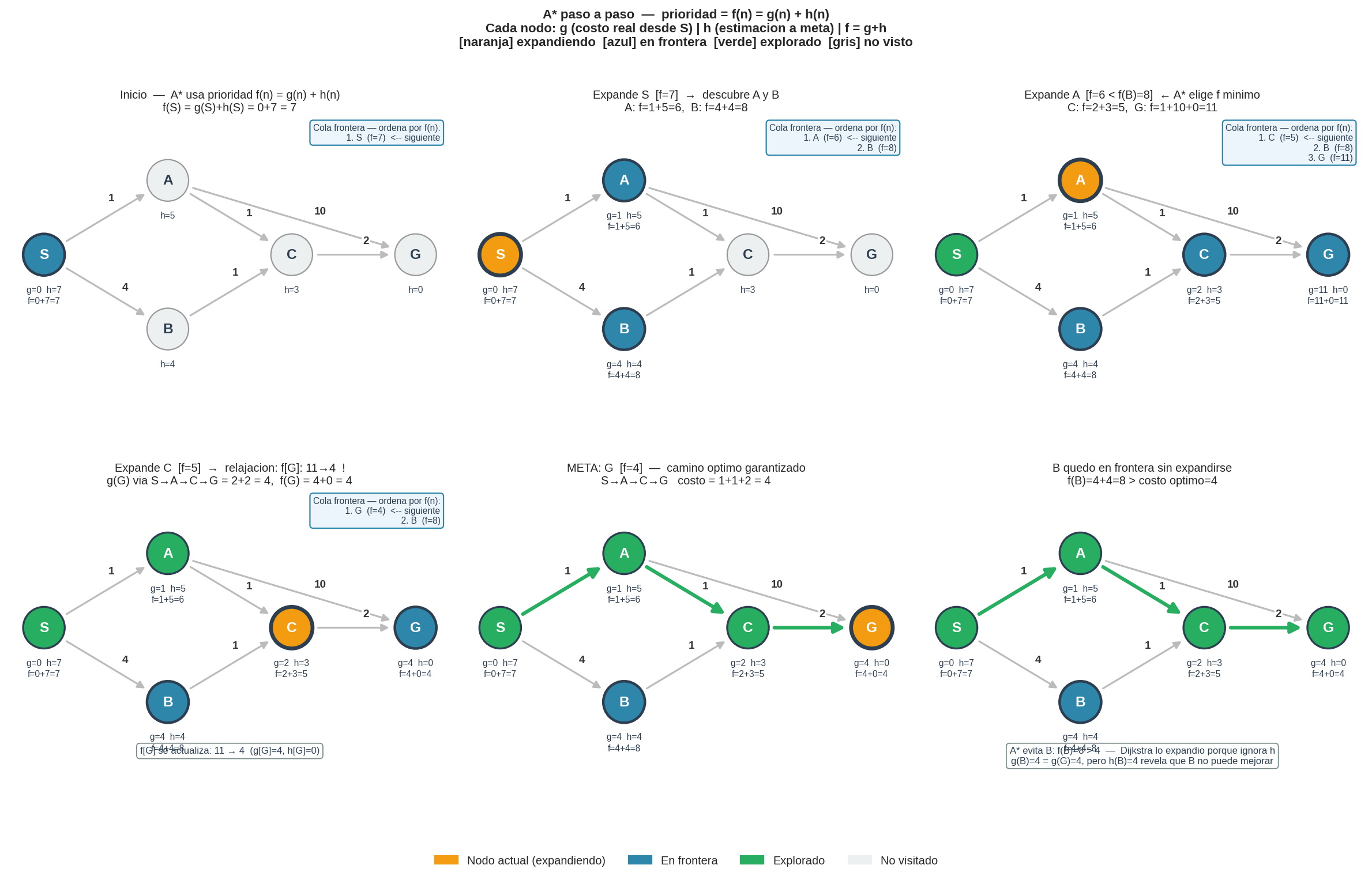
| Paso | Nodo expandido | $g(n)$ | $h(n)$ | $f(n)=g+h$ | Frontera tras expansión |
|---|---|---|---|---|---|
| 1 | S | 0 | 7 | 7 | {A: f=1+5=6, B: f=4+4=8} |
| 2 | A | 1 | 5 | 6 | {C: f=2+3=5, B:8, G: f=11+0=11} |
| 3 | C | 2 | 3 | 5 | {B:8, G: f=4+0=4} ← G actualizado |
| 4 | G | 4 | 0 | 4 | ¡Meta! |
Camino: S → A → C → G con costo 4 — óptimo, en solo 4 expansiones.
B nunca fue expandido. $f(B)=8 > f^{∗}(G)=4$: A* sabe que B no puede llevar a nada mejor que lo que ya encontró. El panel 6 de la imagen lo muestra — B quedó en la frontera al terminar.
| Algoritmo | Expansiones | Camino | Costo | ¿Óptimo? |
|---|---|---|---|---|
| Greedy | 4 | S→B→C→G | 7 | No |
| Dijkstra | 5 | S→A→C→G | 4 | Sí |
| A* | 4 | S→A→C→G | 4 | Sí |
A* iguala la velocidad de Greedy y la optimalidad de Dijkstra — gracias a $f = g + h$.
6. La calidad de $h$ afecta cuánto se expande
| Heurística | $f(n)$ | Comportamiento | Nodos expandidos |
|---|---|---|---|
| $h = 0$ | $g(n)$ | Dijkstra: expande en todas direcciones | Máximo |
| $h$ = buena estimación admisible | $g + h$ | A*: enfocado | Mucho menos |
| $h = h^{∗}$ exacta | $g + h^{∗}$ | A* perfecto: solo el camino óptimo | Mínimo |
| $h > h^{∗}$ (inadmisible) | $g + h_{\text{malo}}$ | Rápido pero puede ser subóptimo | Variable |
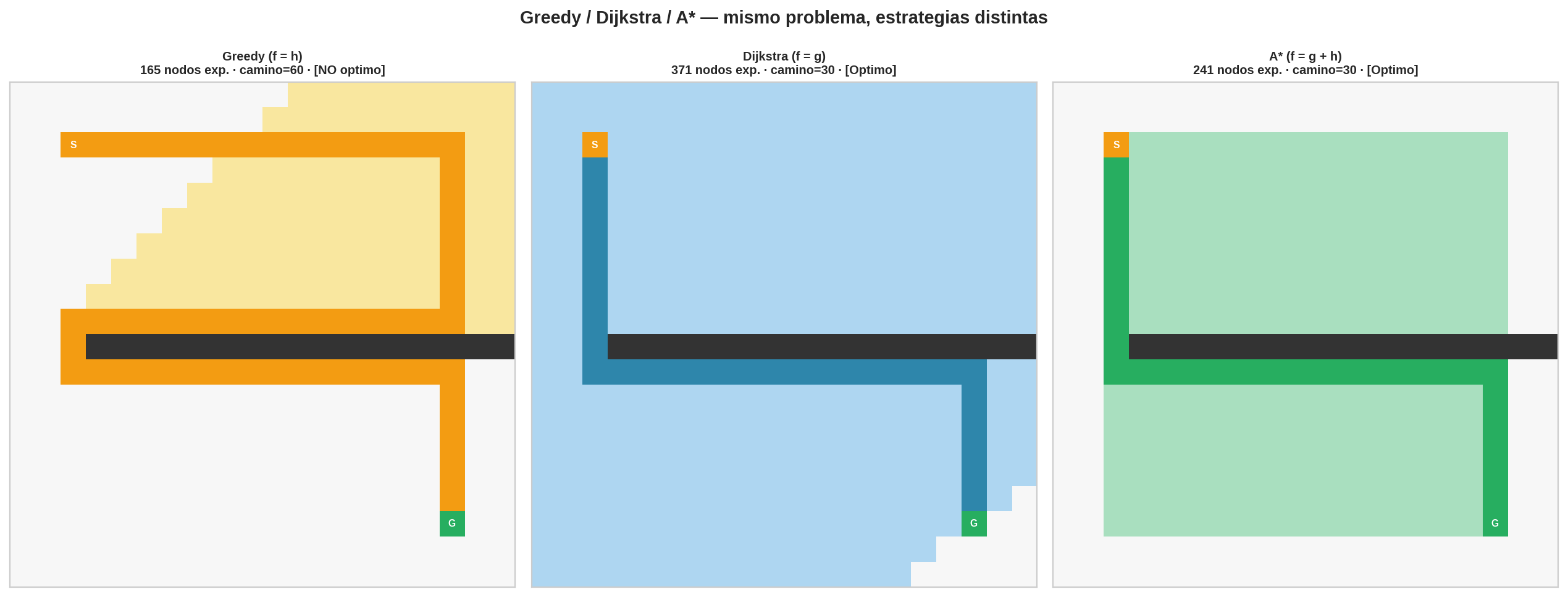
El panel muestra el mismo laberinto con obstáculos resuelto por Greedy, Dijkstra y A*. Los nodos en color son los expandidos. Greedy expande pocos pero puede no encontrar el óptimo. Dijkstra siempre es óptimo pero expande más. A* equilibra ambos.
7. Factor de ramificación efectivo $b^{∗}$
El factor de ramificación efectivo $b^{∗}$ mide empíricamente la calidad de una heurística. Si A* expande $N$ nodos para encontrar una solución a profundidad $d$:
$$b^{∗} = N^{1/d}$$
Un buen indicador:
- $b^{∗} = 1$: la heurística es perfecta — A* solo expande el camino óptimo.
- $b^{∗} = b$: la heurística aporta cero información — A* se comporta como Dijkstra.
- $b^{∗} \approx 1.5$ para el puzzle de 8 piezas con heurística Manhattan — excelente.
Esta métrica permite comparar heurísticas para el mismo problema: la que produce menor $b^{∗}$ en promedio es mejor.
8. Implementación Python
import heapq
def a_star(problema, h):
"""
A*: camino óptimo usando f(n) = g(n) + h(n).
h: callable h(nodo) → estimación admisible al objetivo.
Devuelve (camino, nodos_expandidos) o (None, nodos_expandidos).
"""
inicio = problema.inicio
g = {inicio: 0}
frontera = [(h(inicio), inicio)] # min-heap: (f(n), nodo)
en_frontera = {inicio: h(inicio)}
explorado = set()
padre = {inicio: None}
nodos_expandidos = 0
while frontera:
f_actual, nodo = heapq.heappop(frontera)
if nodo not in en_frontera or en_frontera[nodo] != f_actual:
continue # entrada obsoleta (lazy deletion)
del en_frontera[nodo]
if problema.es_meta(nodo):
return reconstruir_camino(padre, nodo), nodos_expandidos
explorado.add(nodo)
nodos_expandidos += 1
for vecino, costo in problema.vecinos(nodo):
if vecino not in explorado:
g_nuevo = g[nodo] + costo
if g_nuevo < g.get(vecino, float('inf')):
g[vecino] = g_nuevo
padre[vecino] = nodo
f_nuevo = g_nuevo + h(vecino) # ← única diferencia con Dijkstra
heapq.heappush(frontera, (f_nuevo, vecino))
en_frontera[vecino] = f_nuevo
return None, nodos_expandidos
La única diferencia respecto a Dijkstra: f_nuevo = g_nuevo + h(vecino) en lugar de f_nuevo = g_nuevo. Literalmente una adición de + h(vecino).
9. Completitud y optimalidad
| Propiedad | A* | Condición |
|---|---|---|
| Completo | Sí* | En grafos finitos con conjunto explorado |
| Óptimo | Sí | Si $h$ es admisible y los pesos son $\geq 0$ |
*Sin explorado, puede ciclar. Con $h$ inadmisible, puede devolver solución subóptima.
10. Complejidad de tiempo y espacio
Tiempo
En el peor caso con $h = 0$: $O((V + E) \log V)$ — igual que Dijkstra.
En el caso promedio con heurística buena: exponencialmente mejor. El número de nodos expandidos depende del error de la heurística $\epsilon = h^{∗}(n) - h(n)$:
- Si $\epsilon = O(\log h^{∗})$: A* expande en tiempo polinomial.
- Si $h = h^{∗}$: A* expande solo los nodos del camino óptimo — $O(d)$.
Espacio
$O(b^d)$ en el peor caso — igual que BFS. La frontera puede contener todos los nodos descubiertos a profundidad $d$.
Este es el talón de Aquiles de A*: usa demasiada memoria para problemas grandes. Para eso existe IDA* (ver módulo 7).
Recordatorio: $b$ = factor de ramificación máximo (peor caso), $d$ = profundidad de la solución. Definidos en 03 — Algoritmo genérico →.
11. ¿Cuándo usar A*?
Usa A* cuando:
| Señal del problema | ¿Por qué favorece A*? |
|---|---|
| Tienes una heurística admisible | A* la usará para reducir dramáticamente el espacio de búsqueda |
| Necesitas optimalidad garantizada | Con $h$ admisible, A* es óptimo |
| El destino es específico | A* se enfoca; Dijkstra calcula rutas a todos los nodos |
| El espacio cabe en memoria | A* usa $O(b^d)$ — si es demasiado, usa IDA* |
Ejemplo real: GPS y navegación. Google Maps, Waze, y sistemas de navegación de robots usan A* (o variantes) con la distancia en línea recta como heurística. Para un mapa de carreteras con millones de nodos, A* explora solo una fracción del grafo — típicamente los nodos cercanos al corredor directo entre origen y destino.
Ejemplo real: videojuegos. A* es el algoritmo de pathfinding estándar en juegos. Los personajes necesitan rutas óptimas en tiempo real. La heurística Manhattan o Euclidiana es rápida de calcular y guía la búsqueda efectivamente en mapas de cuadrícula.
Señales de alerta:
- La heurística es inadmisible → no hay garantía de optimalidad (pero puede ser más rápido).
- El problema tiene pesos negativos → A* no es correcto; usa Bellman-Ford.
- La memoria es muy limitada → usa IDA*.
- No hay información sobre el dominio → $h = 0$ → usa Dijkstra directamente.
12. Tabla comparativa final
| BFS | Dijkstra | Greedy | A* | |
|---|---|---|---|---|
| Frontera | FIFO | $g$ | $h$ | $g+h$ |
| ¿Usa pesos? | No | Sí | No | Sí |
| ¿Usa heurística? | No | No | Sí | Sí |
| ¿Completo? | Sí | Sí | Sí* | Sí* |
| ¿Óptimo? | Sí (sin pesos) | Sí | No | Sí |
| Tiempo peor caso | $O(b^d)$ | $O((V+E)\log V)$ | $O(b^m)$ | $O(b^d)$ |
| Tiempo mejor caso | $O(b^d)$ | $O((V+E)\log V)$ | $O(d)$ | $O(d)$ |
| Espacio | $O(b^d)$ | $O(V+E)$ | $O(b^m)$ | $O(b^d)$ |
*Con conjunto explorado en grafos finitos.
13. Resumen
| Propiedad | Valor | Justificación |
|---|---|---|
| Frontera | Cola de prioridad por $f(n) = g(n) + h(n)$ | Siempre expande el nodo más prometedor en total |
| Tiempo | $O((V+E)\log V)$ peor / $O(d)$ mejor | Depende de la calidad de $h$ |
| Espacio | $O(b^d)$ peor | La frontera puede contener $b^d$ nodos |
| Completo | Sí (finito + explorado) | Sin explorado, puede ciclar |
| Óptimo | Sí (con $h$ admisible y pesos ≥ 0) | Demostrado por contradicción |
A* cierra el arco narrativo del módulo:
busqueda_genericaconfrontera = ColaDePrioridad(key=g+h). La misma estructura abstracta de módulo 13, ahora con la frontera más poderosa posible para búsqueda informada.
Siguiente: Diseño de heurísticas →