| Notebook | Colab |
|---|---|
| Notebook 02 — Búsqueda informada (Greedy, Dijkstra, A*) | |
| Notebook 04 — Puzzle de 8 piezas (aplicación) |
Branch & Bound e IDA*: búsqueda óptima sin memoria exponencial
"IDA* demonstrates that optimal search does not require exponential memory." — Richard Korf (1985)
A* es óptimo y enfocado, pero tiene un problema de escala: guarda todos los nodos descubiertos en memoria. Para problemas grandes (como el puzzle de 15 piezas con $10^{13}$ estados), la frontera de A* crece exponencialmente y agota la RAM antes de encontrar la solución.
Este módulo presenta dos ideas que resuelven ese problema:
- Branch & Bound: la estrategia general para podar búsquedas costosas.
- IDA*: IDDFS con límite de costo $f$ en lugar de profundidad — obtiene la optimalidad de A* con la memoria de DFS.
1. Branch & Bound: podar ramas costosas
Branch & Bound (B&B) es una estrategia meta-algorítmica, no un algoritmo específico. La idea central:
Mantén una cota superior
mejor_encontradodel costo óptimo. Al explorar un nodo $n$, calcula una cota inferior $f(n)$ de cualquier solución que pase por $n$. Si $f(n) \geq$mejor_encontrado, poda — no tiene sentido explorar esa rama.
Árbol de búsqueda con B&B:
Raíz (f=0)
/ \
A (f=5) B (f=12)
/ \
C (f=8) D (f=15)
|
Meta (costo=10)
Secuencia:
1. Expandir Raíz → A (f=5), B (f=12)
2. Expandir A → C (f=8), D (f=15)
3. Expandir C → Meta (costo=10)
→ mejor_encontrado = 10
4. Intentar D: f(D)=15 ≥ mejor_encontrado=10 → PODA
5. Intentar B: f(B)=12 ≥ mejor_encontrado=10 → PODA
6. No hay más ramas → óptimo = 10
La efectividad de B&B depende de:
- La calidad de la cota inferior $f(n)$: mejor cota → más podas → menos trabajo.
- El orden de exploración: encontrar una buena solución pronto establece una cota alta que poda más ramas después.
A* como B&B: A* es exactamente Branch & Bound en orden best-first. Su cota inferior es $f(n) = g(n) + h(n)$, y cuando extrae un nodo de la cola de prioridad con $f(n) \geq$ costo de la mejor solución conocida, lo descarta. La diferencia es que A* mantiene la frontera explícita en memoria.
2. IDA*: IDDFS con límite de costo
La analogía IDDFS → IDA* es directa:
| IDDFS | IDA* |
|---|---|
Profundidad máxima d_max |
Costo $f$ máximo f_limit |
Si profundidad(n) > d_max: poda |
Si f(n) > f_limit: poda |
Incrementa d_max en 1 cada iteración |
Incrementa f_limit al mínimo $f$ podado |
| Completo y óptimo (sin pesos) | Completo y óptimo (con pesos + $h$ admisible) |
| Espacio $O(bd)$ | Espacio $O(bd)$ |
IDA* resuelve el problema de memoria de A*: como usa DFS con poda por $f$, solo necesita recordar el camino actual — $O(bd)$ en lugar de $O(b^d)$.
El precio: puede reexpandir nodos al inicio de cada iteración. En la práctica, el costo de reexpansión es pequeño comparado con el ahorro de memoria.
3. Pseudocódigo IDA*
function IDA_STAR(problema, h):
f_limit ← h(problema.inicio) # primera cota = h del inicio
camino ← [problema.inicio]
loop:
resultado, nuevo_f_limit ← DFS_LIMITADO(camino, 0, f_limit, problema, h)
if resultado == FOUND:
return camino # ¡solución óptima encontrada!
if nuevo_f_limit == ∞:
return FAILURE # no hay solución
f_limit ← nuevo_f_limit # incrementa la cota al mínimo podado
function DFS_LIMITADO(camino, g, f_limit, problema, h):
nodo ← camino.último()
f ← g + h(nodo)
if f > f_limit:
return NOT_FOUND, f # poda — devuelve el nuevo f mínimo visto
if problema.is_goal(nodo):
return FOUND, f_limit
siguiente_f_limit ← ∞
for each (vecino, costo) in problema.neighbors(nodo):
if vecino not in camino: # evitar ciclos en el camino actual
camino.append(vecino)
resultado, t ← DFS_LIMITADO(camino, g + costo, f_limit, problema, h)
if resultado == FOUND:
return FOUND, f_limit
siguiente_f_limit ← min(siguiente_f_limit, t)
camino.pop()
return NOT_FOUND, siguiente_f_limit
Puntos clave:
- El estado solo almacena el camino actual (una lista) — memoria lineal $O(d)$.
siguiente_f_limitacumula el mínimo $f$ que fue podado — eso se convierte en la próxima cota.- La condición
vecino not in caminoevita ciclos sin necesitar un conjunto global de explorados.
4. Traza paso a paso
Grafo simple: A→B (costo 1), A→C (costo 3), B→D (costo 2), C→D (costo 1), D=Meta.
h: h(A)=3, h(B)=2, h(C)=1, h(D)=0
f(n) = g(n) + h(n):
A: 0+3=3
B (vía A): 1+2=3
C (vía A): 3+1=4
D (vía A→B): 3+0=3
D (vía A→C): 4+0=4
Iteración 1: f_limit = 3
DFS: A (f=3, ≤3, expandir)
→ B (f=3, ≤3, expandir)
→ D (f=3, ≤3, ¡META!) → return FOUND
Solución: A → B → D, costo = 3. Solo 1 iteración necesaria gracias a la heurística.
Un ejemplo con varias iteraciones: si la heurística subestimara más, la primera iteración posaría nodos, la segunda ampliaría el límite, y así hasta encontrar la meta.
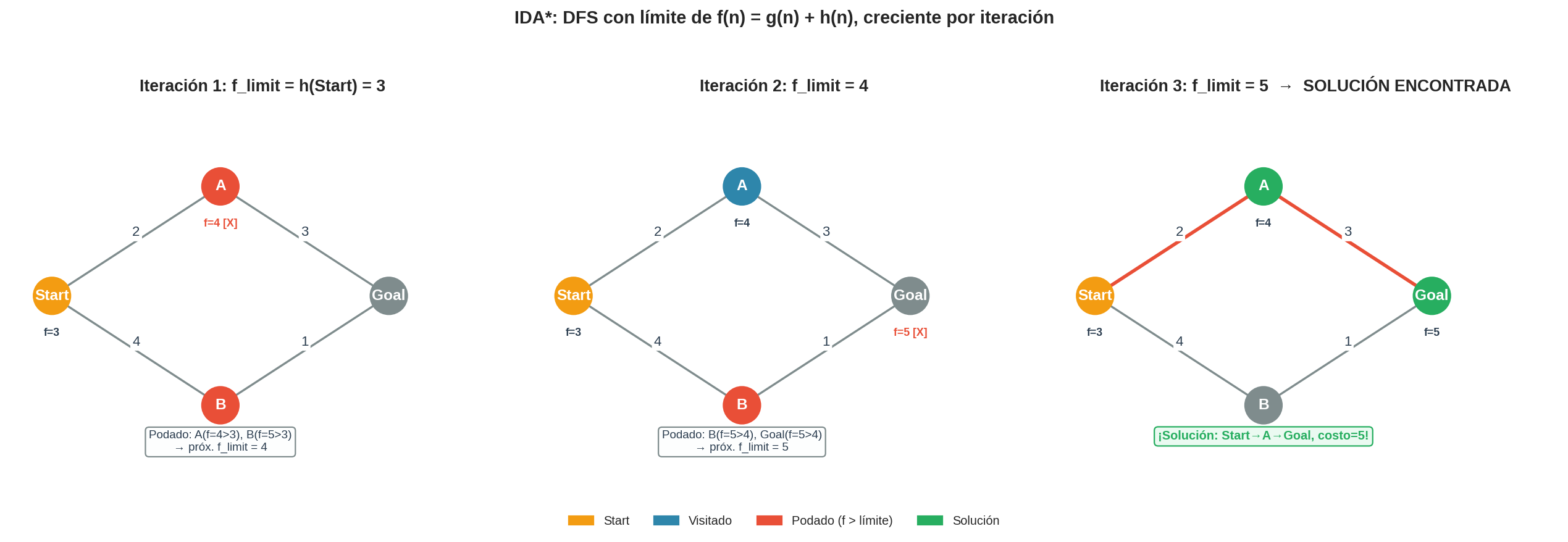
5. Traza extendida: mostrando las iteraciones
Para ilustrar el comportamiento de múltiples iteraciones, usamos un grafo donde la heurística subestima significativamente:
Grafo: Inicio → A (costo 2) → B (costo 3) → Meta (costo 1)
Inicio → Meta (costo 10)
h: h(Inicio)=1, h(A)=3, h(B)=1, h(Meta)=0
Iteración 1: f_limit = h(Inicio) = 1
| Nodo | g | h | f | Decisión |
|---|---|---|---|---|
| Inicio | 0 | 1 | 1 | f=1 ≤ 1, expandir |
| A | 2 | 3 | 5 | f=5 > 1, poda → t=5 |
| Meta | 10 | 0 | 10 | f=10 > 1, poda → t=10 |
Mínimo podado = 5. f_limit ← 5
Iteración 2: f_limit = 5
| Nodo | g | h | f | Decisión |
|---|---|---|---|---|
| Inicio | 0 | 1 | 1 | f=1 ≤ 5, expandir |
| A | 2 | 3 | 5 | f=5 ≤ 5, expandir |
| B | 5 | 1 | 6 | f=6 > 5, poda → t=6 |
| Meta | 10 | 0 | 10 | f=10 > 5, poda → t=10 |
Mínimo podado = 6. f_limit ← 6
Iteración 3: f_limit = 6
| Nodo | g | h | f | Decisión |
|---|---|---|---|---|
| Inicio | 0 | 1 | 1 | expandir |
| A | 2 | 3 | 5 | expandir |
| B | 5 | 1 | 6 | f=6 ≤ 6, expandir |
| Meta | 6 | 0 | 6 | f=6 ≤ 6, ¡META! |
Solución: Inicio → A → B → Meta, costo = 6.
6. Propiedades de IDA*
| Propiedad | IDA* | Condición |
|---|---|---|
| Completo | Sí | En grafos finitos |
| Óptimo | Sí | Si $h$ es admisible y pesos ≥ 0 |
| Memoria | $O(bd)$ | Solo el camino actual — ¡lineal! |
7. Comparación de memoria: A* vs IDA*
Esta es la diferencia más importante en la práctica:
| Algoritmo | Memoria | Escalabilidad |
|---|---|---|
| A* | $O(b^d)$ — exponencial | Puzzle de 8 piezas (9! ≈ 362.880 estados): OK |
| IDA* | $O(bd)$ — lineal | Puzzle de 15 piezas ($10^{13}$ estados): OK con IDA* |
Ejemplo concreto: para el puzzle de 15 piezas con $d \approx 50$ y $b \approx 3$:
- A*: $3^{50} \approx 7 \times 10^{23}$ nodos en la frontera → imposible en RAM.
- IDA*: $3 \times 50 = 150$ nodos en el camino actual → trivial.
Richard Korf (1985) resolvió el puzzle de 15 piezas por primera vez usando IDA* en una computadora con poca memoria. A* simplemente no podía.
8. Reexpansión: el precio de IDA*
IDA* reexpande nodos al inicio de cada iteración. En el peor caso, la iteración $k$ re-explora casi todos los nodos de las iteraciones anteriores.
En grafos de árbol con factor de ramificación constante $b$ y solución a profundidad $d$:
- Iteración con $f$-límite $c$: expande $\leq b^{c/\epsilon}$ nodos (donde $\epsilon$ = mínimo costo de arista).
- Costo total sobre todas las iteraciones: $O(b^d)$ — igual que A* en el peor caso.
En la práctica:
- Si hay pocos valores distintos de $f$: pocas iteraciones, poco overhead.
- Si hay muchos valores distintos de $f$ (costos continuos): muchas iteraciones, overhead significativo.
Variante: IDA* con tabla de transposición — almacena los mejores $g$ vistos para los nodos más costosos de reexpandir. Reduce overhead manteniendo una ventaja de memoria sobre A*.
9. Aplicación: el puzzle de 15 piezas
El puzzle de 15 piezas es el benchmark histórico donde IDA* demostró su valor:
Tablero 4×4: fichas 1-15 y un espacio vacío
Estados posibles: 16!/2 ≈ 10^{13}
Heurística: distancia Manhattan
h(n) = suma de distancias Manhattan de cada ficha
Resultado típico con IDA\*:
Profundidad de solución: ~50 movimientos
Nodos expandidos: ~10^9
Tiempo en hardware moderno: segundos
Memoria: O(15 × 50) = 750 valores en el camino actual
Con A* y pattern databases más sofisticadas, el puzzle de 15 piezas se resuelve aún más rápido, pero requiere gigabytes de memoria para las pattern databases.
10. Cuándo usar IDA* vs A*
| Criterio | A* | IDA* |
|---|---|---|
| Memoria disponible | Mucha (RAM) | Poca |
| Costos de arista | Variables | Uniformes o pocos valores |
| Heurística | Admisible | Admisible |
| Reexpansiones | Ninguna | Posibles — depende de costos |
| Mejor caso | Igual | Igual |
| Problema estándar | GPS, juegos con estados ≤ 10^7 | Puzzles, combinatoria, espacios ≥ 10^ |
11. Resumen del módulo
Hemos completado el arco completo de búsqueda informada:
| Algoritmo | Frontera | Memoria | Óptimo | Guía |
|---|---|---|---|---|
| BFS | FIFO | $O(b^d)$ | Sí (sin pesos) | No |
| Dijkstra | $g$ | $O(V+E)$ | Sí | No |
| Greedy | $h$ | $O(b^m)$ | No | Sí |
| A* | $g+h$ | $O(b^d)$ | Sí | Sí |
| IDA* | $g+h$ (límite) | $O(bd)$ | Sí | Sí |
Un algoritmo, muchas fronteras: desde BFS hasta IDA*, todos son instancias de
busqueda_genericacon diferentes estructuras de frontera y estrategias de poda. El diseño de la frontera y la calidad de $h$ determinan todo.
Siguiente: Índice del módulo →