| Notebook | Colab |
|---|---|
| Notebook 02 — Minimax y alpha-beta |
Minimax: el peor caso garantizado
“The essence of strategy: make sure you win even if the other player is perfect.”
Minimax es DFS con propagación de valores hacia atrás. Al igual que DFS explora ramas en profundidad antes de retroceder, minimax desciende hasta las hojas del árbol de juego y, al subir, propaga el mejor valor que cada jugador puede garantizarse. La estructura es idéntica — la diferencia está en qué hace cada llamada recursiva al retroceder.
1. Intuición
Pregunta central de minimax: “Si mi oponente juega perfectamente contra mí, ¿cuál es la mejor decisión que puedo tomar?”
No buscamos el mejor resultado posible — eso sería optimismo ingenuo. Buscamos el mejor resultado garantizado, asumiendo que el oponente es exactamente tan bueno como nosotros. Esta es la diferencia entre “espero que el oponente se equivoque” y “gano aunque el oponente no se equivoque”.
La estrategia que minimax descubre se llama estrategia minimax u óptima: ningún agente racional puede hacer mejor contra un oponente que también juega óptimamente.
2. La conexión con DFS
Minimax usa DFS como motor de exploración. La estructura es idéntica — la diferencia está en qué hace cada llamada recursiva al retroceder:
| DFS (módulo 13) | Minimax | |
|---|---|---|
| Estructura | Recursión / pila | Recursión |
| Orden de visita | Profundidad primero | Profundidad primero |
| Complejidad tiempo | $O(b^m)$ | $O(b^m)$ |
| Complejidad espacio | $O(b \cdot m)$ | $O(b \cdot m)$ |
| Al visitar un nodo | Marca como explorado | Determina si es MAX o MIN |
| Al retroceder | Nada (solo desapila) | Retorna un valor (max o min de los hijos) |
| Se detiene | Al llegar al destino | Al llegar a estados terminales |
DFS visita y olvida. Minimax visita y recuerda un valor que propaga hacia arriba.
Esta analogía es profunda: la complejidad de espacio de minimax es $O(b \cdot m)$ — igual que DFS, no $O(b^m)$. Solo necesita mantener el camino desde la raíz hasta el nodo actual, no todos los nodos explorados.
3. En lenguaje natural
El algoritmo en cuatro pasos:
- Si el estado es terminal: devuelve su utilidad. El juego terminó — sabemos el resultado exacto.
- Si es el turno de MAX: evalúa todos los estados sucesores recursivamente, devuelve el máximo de sus valores. MAX elige la mejor opción disponible.
- Si es el turno de MIN: evalúa todos los estados sucesores recursivamente, devuelve el mínimo de sus valores. MIN elige la opción que peor le va a MAX.
- En la raíz: la acción que lleva al sucesor con mayor valor minimax es la acción óptima de MAX.
La clave: para conocer el valor de un nodo MAX, necesitamos conocer el valor de todos sus hijos. Eso nos obliga a explorar cada rama hasta las hojas antes de poder comparar — exactamente el orden de DFS.
4. La función de valor
Definimos $V(s)$ como el valor minimax del estado $s$ — el resultado que ambos jugadores pueden garantizarse con juego perfecto desde $s$.
La función se define por casos según el tipo de nodo:
$$V(s) = \begin{cases} U(s) & \text{si } \text{Terminal}(s) \ \displaystyle\max_{a \in \text{Acciones}(s)} V!\left(\text{Resultado}(s,,a)\right) & \text{si } \text{Jugador}(s) = \text{MAX} \ \displaystyle\min_{a \in \text{Acciones}(s)} V!\left(\text{Resultado}(s,,a)\right) & \text{si } \text{Jugador}(s) = \text{MIN} \end{cases}$$
Cada caso tiene una interpretación directa:
- Caso 1 — Terminal: el valor es conocido porque la partida terminó. $U(s)$ es la utilidad exacta del resultado (por ejemplo, $+1$ si MAX ganó, $-1$ si MIN ganó, $0$ empate).
- Caso 2 — Turno de MAX: MAX elige la acción que lleva al estado sucesor de mayor valor. Toma el máximo sobre todos los movimientos posibles.
- Caso 3 — Turno de MIN: MIN elige la acción que lleva al estado sucesor de menor valor (el peor para MAX). Toma el mínimo sobre todos los movimientos posibles.
La recursión es bien fundada porque cada llamada opera sobre un estado estrictamente más profundo en el árbol, y los árboles de juegos finitos tienen profundidad acotada.
5. Pseudocódigo
El algoritmo se divide en tres funciones:
MINIMAX— punto de entrada. Decide si llama a MAX o MIN y devuelve la acción a tomar (no el valor numérico).MAX_VALUE— se llama cuando es el turno de MAX. Devuelve el mayor valor posible entre todos los sucesores.MIN_VALUE— se llama cuando es el turno de MIN. Devuelve el menor valor posible entre todos los sucesores.
MAX_VALUE y MIN_VALUE se llaman mutuamente de forma recursiva, alternando el turno en cada nivel del árbol. La recursión termina cuando se llega a un estado terminal (hoja).
# ── MINIMAX ─────────────────────────────────────────────────────────────────
# Punto de entrada: recibe el juego y el estado actual.
# Devuelve la ACCIÓN óptima (no el valor): el agente necesita saber qué hacer.
function MINIMAX(juego, estado):
if juego.jugador(estado) == MAX: # ¿A quién le toca mover?
valor, accion ← MAX_VALUE(juego, estado) # MAX mueve → maximizar
else:
valor, accion ← MIN_VALUE(juego, estado) # MIN mueve → minimizar
return accion # [P1] devolvemos ACCIÓN, no valor
# ── MAX_VALUE ────────────────────────────────────────────────────────────────
# Calcula el valor del mejor movimiento cuando le toca a MAX.
# Explora todos los sucesores y devuelve el máximo de sus valores.
function MAX_VALUE(juego, estado):
if juego.terminal(estado): # ¿El juego terminó aquí?
return juego.utilidad(estado), None # [P2] hoja: devuelve utilidad conocida, sin acción
v ← -∞ # peor valor inicial para MAX (toda comparación lo mejora)
mejor ← None # aún no hay mejor acción
for each accion in juego.acciones(estado): # recorre cada movimiento legal
sucesor ← juego.resultado(estado, accion) # aplica la acción → estado hijo
v2, _ ← MIN_VALUE(juego, sucesor) # [P3] baja al nivel MIN (turno del oponente)
if v2 > v: # ¿este hijo es mejor que el mejor visto hasta ahora?
v ← v2 # actualiza el mejor valor
mejor ← accion # guarda qué acción lo produjo
return v, mejor # propaga hacia arriba: valor + acción que lo logra
# ── MIN_VALUE ────────────────────────────────────────────────────────────────
# Calcula el valor del mejor movimiento cuando le toca a MIN.
# Explora todos los sucesores y devuelve el mínimo de sus valores.
function MIN_VALUE(juego, estado):
if juego.terminal(estado): # ¿El juego terminó aquí?
return juego.utilidad(estado), None # hoja: devuelve utilidad conocida, sin acción
v ← +∞ # peor valor inicial para MIN (toda comparación lo mejora)
mejor ← None # aún no hay mejor acción
for each accion in juego.acciones(estado): # recorre cada movimiento legal
sucesor ← juego.resultado(estado, accion) # aplica la acción → estado hijo
v2, _ ← MAX_VALUE(juego, sucesor) # [P4] sube al nivel MAX (turno del jugador principal)
if v2 < v: # ¿este hijo es peor para MAX (= mejor para MIN)?
v ← v2 # actualiza el mejor valor para MIN
mejor ← accion # guarda qué acción lo produjo
return v, mejor # propaga hacia arriba: valor + acción que lo logra
La alternancia MAX_VALUE ↔ MIN_VALUE implementa la alternancia de turnos. Cada llamada profundiza un nivel en el árbol — exactamente DFS. La única adición sobre DFS puro es que al retroceder se retorna un valor numérico en lugar de simplemente desapilar.
6. Implementación en Python
def minimax(estado, es_max):
"""
Minimax para Nim.
Args:
estado : tupla de enteros, cada elemento es el tamaño de una pila
por ejemplo (1, 2) = pila A con 1 ficha, pila B con 2 fichas
es_max : True si es turno de MAX, False si es turno de MIN
Returns:
(valor, accion)
valor : +1 si MAX gana con juego perfecto, -1 si MIN gana
accion : (indice_pila, cantidad_a_retirar) o None si estado terminal
"""
# ── Caso base: estado terminal ───────────────────────────────────────────
# En Nim, el estado terminal es (0, 0, ..., 0): todas las pilas vacías.
# El jugador en turno no puede mover → pierde.
if all(p == 0 for p in estado):
# Si es_max=True → MAX no puede mover → MAX pierde → valor = -1
# Si es_max=False → MIN no puede mover → MIN pierde → valor = +1 (bueno para MAX)
return (-1 if es_max else +1), None
# ── Inicialización ───────────────────────────────────────────────────────
# Para MAX: queremos el máximo, empezamos con -∞ para que cualquier valor lo mejore.
# Para MIN: queremos el mínimo, empezamos con +∞ para que cualquier valor lo mejore.
mejor_valor = -float('inf') if es_max else float('inf')
mejor_accion = None # guardamos la acción que produjo el mejor valor
# ── Exploración de sucesores ─────────────────────────────────────────────
for i, pila in enumerate(estado): # i = índice de la pila
for cant in range(1, pila + 1): # cant = cuántas fichas retirar (al menos 1)
nuevo = list(estado) # copia del estado actual
nuevo[i] -= cant # aplica el movimiento: retira 'cant' de pila i
# Llamada recursiva: turno alterna (not es_max)
v, _ = minimax(tuple(nuevo), not es_max)
# ── Actualizar si este sucesor es mejor ──────────────────────────
if es_max and v > mejor_valor: # MAX quiere el mayor valor
mejor_valor = v
mejor_accion = (i, cant) # (pila i, retirar cant fichas)
elif not es_max and v < mejor_valor: # MIN quiere el menor valor
mejor_valor = v
mejor_accion = (i, cant)
return mejor_valor, mejor_accion
# ── Ejemplo de uso ───────────────────────────────────────────────────────────
if __name__ == '__main__':
estado = (1, 2) # pila A=1, pila B=2
valor, accion = minimax(estado, es_max=True)
print(f"Estado inicial: {estado}")
print(f"Valor garantizado para MAX: {valor}")
print(f"Mejor acción (pila, cantidad): {accion}")
# → Valor garantizado para MAX: 1
# → Mejor acción (pila, cantidad): (1, 1) [retirar 1 de la pila B]
7. Traza paso a paso: Nim(1,2)
El juego Nim(1,2)
Recordatorio rápido del juego (detallado en la sección 01):
- Hay 2 pilas: pila A con 1 ficha y pila B con 2 fichas. El estado se escribe como la tupla (A, B).
- En cada turno el jugador activo elige una pila y retira al menos 1 ficha de ella (puede retirar todas).
- El jugador que no puede mover (todas las pilas están vacías cuando le toca) pierde.
- MAX mueve primero.
Notación de acciones: A-1 significa “retirar 1 ficha de la pila A”; B-2 significa “retirar 2 fichas de la pila B”.
Lectura del árbol de juego
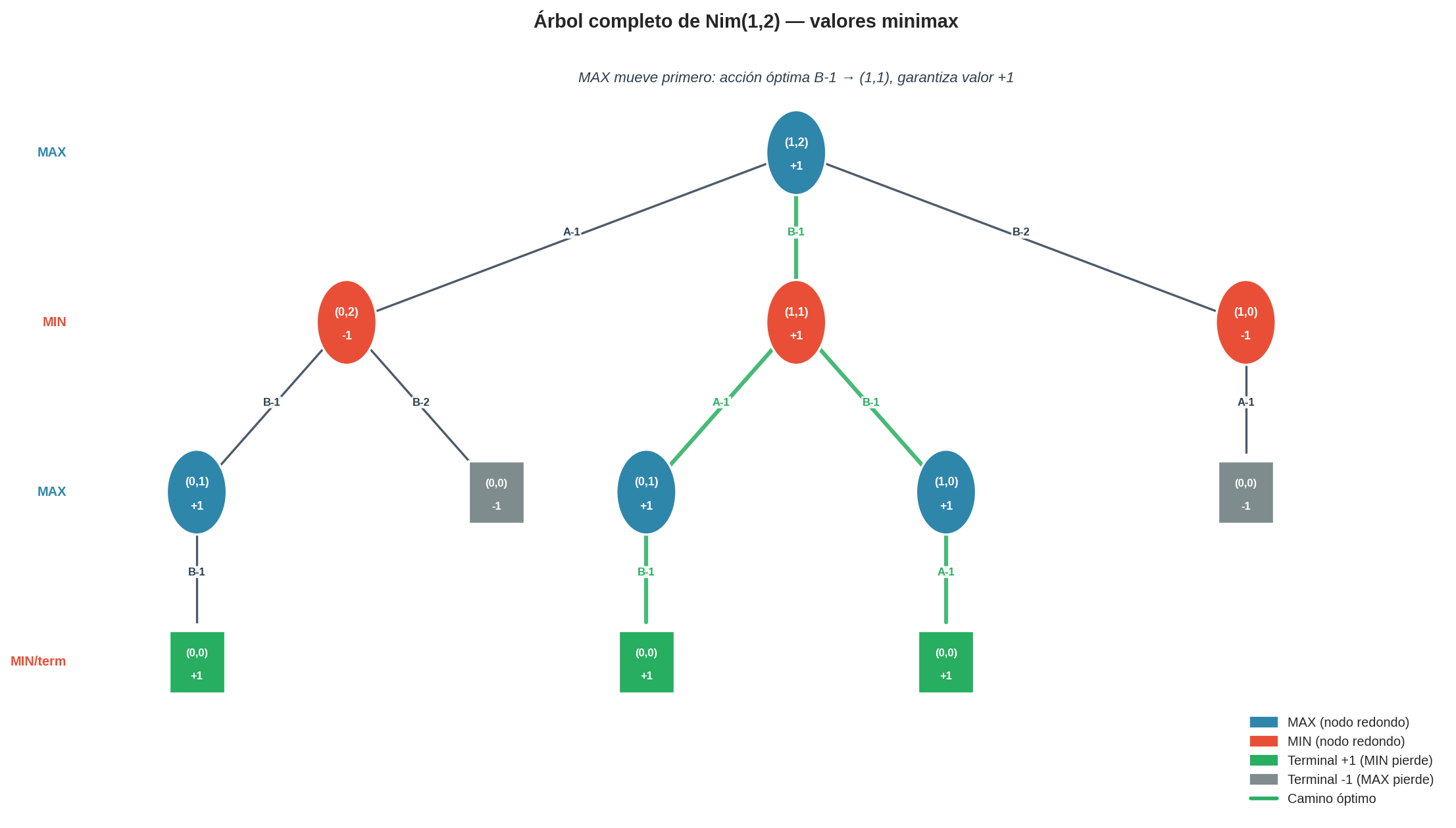
Cómo leer la figura:
- Cada nodo es un estado del juego, etiquetado con la tupla (A, B) — el tamaño actual de cada pila.
- Los círculos azules son nodos MAX (turno de MAX). Los círculos rojos son nodos MIN (turno de MIN).
- Los cuadrados son estados terminales: todas las pilas están vacías, (0,0). El número dentro del cuadrado es la utilidad: +1 si el jugador que llegó aquí (es decir, el que acaba de mover) deja a su oponente sin movimiento (entonces MAX gana), −1 si ocurre lo contrario.
- Cada arista representa un movimiento legal. La etiqueta sobre la arista (p.ej.
B-1) indica qué ficha(s) se retiraron: la letra es la pila y el número es la cantidad retirada. - El valor anotado dentro de cada nodo (número grande) es el valor minimax calculado por retropropagación. Un nodo MAX muestra el máximo de sus hijos; un nodo MIN muestra el mínimo de sus hijos.
- La arista verde gruesa marca el camino óptimo: la acción que MAX debe elegir en la raíz y el resultado que sigue bajo juego perfecto.
- Las aristas grises más delgadas son ramas subóptimas — MAX no debería tomarlas.
El árbol completo tiene exactamente 12 nodos — lo suficientemente pequeño para trazar cada llamada.
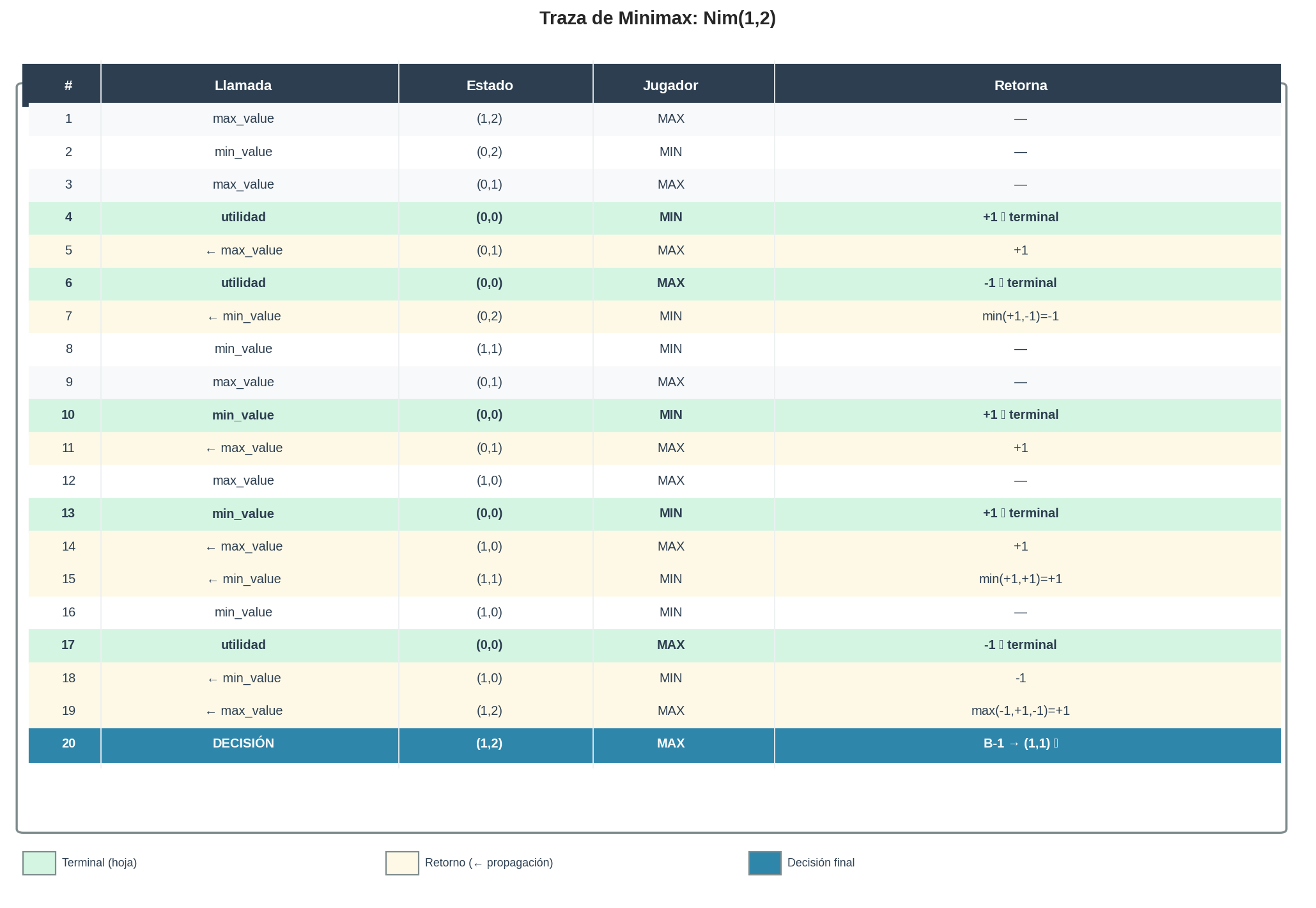
Tabla de traza
| # | Llamada | Estado | Jugador | Retorna | Nota |
|---|---|---|---|---|---|
| 1 | max_value |
(1,2) | MAX | — | inicio; explora 3 acciones: A-1, B-1, B-2 |
| 2 | min_value |
(0,2) | MIN | — | acción A-1: retirar 1 de pila A |
| 3 | max_value |
(0,1) | MAX | — | acción B-1 desde (0,2) |
| 4 | min_value |
(0,0) | MIN | +1 | terminal — MIN no puede mover, MAX gana |
| 5 | ← max_value |
(0,1) | MAX | max(+1) = +1 | único hijo; propaga hacia arriba |
| 6 | max_value |
(0,0) | MAX | −1 | terminal — MAX no puede mover desde (0,2) vía B-2 |
| 7 | ← min_value |
(0,2) | MIN | min(+1, −1) = −1 | MIN elige B-2; valor −1 para MAX |
| 8 | min_value |
(1,1) | MIN | — | acción B-1: retirar 1 de pila B desde raíz |
| 9 | max_value |
(0,1) | MAX | — | acción A-1 desde (1,1) |
| 10 | min_value |
(0,0) | MIN | +1 | terminal — MIN no puede mover |
| 11 | ← max_value |
(0,1) | MAX | max(+1) = +1 | único hijo; propaga +1 |
| 12 | max_value |
(1,0) | MAX | — | acción B-1 desde (1,1) |
| 13 | min_value |
(0,0) | MIN | +1 | terminal — MIN no puede mover |
| 14 | ← max_value |
(1,0) | MAX | max(+1) = +1 | único hijo; propaga +1 |
| 15 | ← min_value |
(1,1) | MIN | min(+1, +1) = +1 | MIN no puede evitar el +1; (1,1) vale +1 para MAX |
| 16 | min_value |
(1,0) | MIN | — | acción B-2: retirar 2 de pila B desde raíz |
| 17 | max_value |
(0,0) | MAX | −1 | terminal — MAX no puede mover |
| 18 | ← min_value |
(1,0) | MIN | min(−1) = −1 | MIN fuerza derrota de MAX |
| 19 | ← max_value |
(1,2) | MAX | max(−1, +1, −1) = +1 | MAX elige B-1 → (1,1) — acción óptima |
Análisis de la decisión: MAX parte de (1,2) y tiene tres opciones:
| Acción | Estado resultante | Valor minimax | Resultado |
|---|---|---|---|
| A-1 (retirar 1 de pila A) | (0,2) | −1 | MIN gana |
| B-1 (retirar 1 de pila B) | (1,1) | +1 | MAX gana ← óptima |
| B-2 (retirar 2 de pila B) | (1,0) | −1 | MIN gana |
Solo la acción B-1 → (1,1) garantiza victoria para MAX. Desde (1,1), cualquier movimiento de MIN deja exactamente una ficha en una sola pila, y MAX la retira para ganar.
Verificación por nim-sum: en la sección 15.5 veremos que el operador $\oplus$ (XOR bit a bit) permite calcular el resultado óptimo sin explorar el árbol. De momento, como anticipo: $1 \oplus 2 = 3 \neq 0$ confirma que (1,2) es posición ganadora para MAX; $1 \oplus 1 = 0$ confirma que (1,1) es posición perdedora para el jugador en turno (MIN). El símbolo $\oplus$ aquí significa “suma nim” — lo derivaremos formalmente en la sección 5.
8. Propiedades
| Propiedad | Valor | Condición |
|---|---|---|
| Completo | Sí | En árboles de juego finitos |
| Óptimo | Sí∗ | ∗Contra un oponente que también juega óptimamente |
| Tiempo | $O(b^m)$ | $b$ = factor de ramificación, $m$ = profundidad máxima |
| Espacio | $O(b \cdot m)$ | Igual que DFS — solo mantiene el camino actual |
Comparación con los algoritmos de módulos anteriores:
| Algoritmo | Tiempo | Espacio | Completo | Óptimo |
|---|---|---|---|---|
| DFS | $O(b^m)$ | $O(b \cdot m)$ | No | No |
| BFS | $O(b^d)$ | $O(b^d)$ | Sí | Sí (sin pesos) |
| A* | $O(b^d)$ | $O(b^d)$ | Sí | Sí |
| Minimax | $O(b^m)$ | $O(b \cdot m)$ | Sí | Sí∗ |
El espacio lineal de minimax ($O(b \cdot m)$) es una ventaja importante: igual que DFS, solo necesita mantener el camino desde la raíz hasta el nodo actual en la pila de recursión.
9. Los números reales
| Juego | $b$ | $m$ | Nodos aprox. | ¿Minimax exacto? |
|---|---|---|---|---|
| Nim(1,2) | 3 | 4 | 12 | Sí |
| Tic-tac-toe | 9 | 9 | $\leq 9! = 362{,}880$ | Sí (con simetría) |
| Ajedrez | 35 | 80 | $\approx 10^{123}$ | No |
| Go | 250 | 150 | $\approx 10^{360}$ | No |
Para ajedrez, incluso a 1 billón de nodos por segundo, explorar $10^{123}$ nodos tomaría más tiempo que la edad del universo ($\approx 4 \times 10^{17}$ segundos). La siguiente sección muestra cómo reducir este costo hasta la raíz cuadrada manteniendo la misma respuesta.
Siguiente: Poda alfa-beta →