| Notebook | Colab |
|---|---|
| Notebook 02 — Minimax y alpha-beta |
Poda alfa-beta: la misma respuesta, menos trabajo
“The art of being wise is the art of knowing what to overlook.” — William James
Alpha-beta es minimax con una observación sencilla: no necesitas explorar ramas que no pueden cambiar tu decisión. La respuesta final es idéntica a minimax — la acción que retorna es la misma. El trabajo se puede reducir hasta a la raíz cuadrada del de minimax.
Esta sección construye el concepto desde cero con dos ejemplos concretos antes de introducir cualquier fórmula.
Nota sobre los valores en los ejemplos. En Nim usamos utilidades terminales ${+1, -1}$ donde el signo indicaba directamente quién gana: $+1$ = MAX gana, $-1$ = MIN gana. Aquí usamos enteros arbitrarios (3, 5, 8, …) para que α y β sean valores concretos y distintos, lo que hace más visible cómo funciona la ventana $[\alpha, \beta]$.
La convención es exactamente la misma: cada valor es siempre la utilidad de MAX. El juego sigue siendo de suma cero — MIN minimiza esa misma cantidad, lo que equivale a maximizar la suya propia. Valores más altos siguen siendo mejores para MAX y peores para MIN. La única diferencia con Nim es que el rango no está restringido a $\pm 1$; puede ser cualquier entero que devuelva la función de evaluación.
1. Ejemplo A: α-cutoff — MAX ya tiene algo mejor
El árbol
Considera este árbol abstracto de 3 niveles:
MAX(raíz)
/ \
MIN(L) MIN(R)
/ \ / \
3 5 1 ?
Las hojas tienen valores enteros (el resultado del juego según una función de evaluación). MAX elige entre las dos ramas disponibles.
Lo que pasa paso a paso
Paso 1 — Explorar MIN(L):
MIN(L) ve el hijo 3. Anota que puede limitar el resultado a 3. MIN(L) ve el hijo 5. Como min(3,5)=3, el valor no mejora. MIN(L) retorna 3 a la raíz MAX.
Paso 2 — La raíz MAX anota lo que ya sabe:
MAX recibió 3 desde la rama izquierda. Ahora sabe: “sin importar lo que haga el oponente en MIN(L), puedo garantizarme al menos 3.” Esa garantía se llama α = 3.
Paso 3 — Explorar MIN® con α=3 en mente:
MAX entra a MIN® llevando consigo el conocimiento de que ya tiene α=3 disponible. MIN® ve el hijo 1. MIN® anota que puede forzar el valor a 1 como máximo — actualiza su límite superior β = 1. Ahora β=1 ≤ α=3.
Paso 4 — ¿Por qué parar aquí?
MIN® puede forzar a MAX a obtener como máximo 1 en esta rama. MAX ya tiene 3 garantizado en MIN(L). MAX nunca elegiría ir por MIN® — ¿para qué, si ya tiene algo mejor? El valor de “?” es completamente irrelevante. No necesitamos explorarlo.
Esto es un α-cutoff: la rama se poda porque MIN encontró algo tan malo para MAX que MAX nunca vendría aquí.
La figura
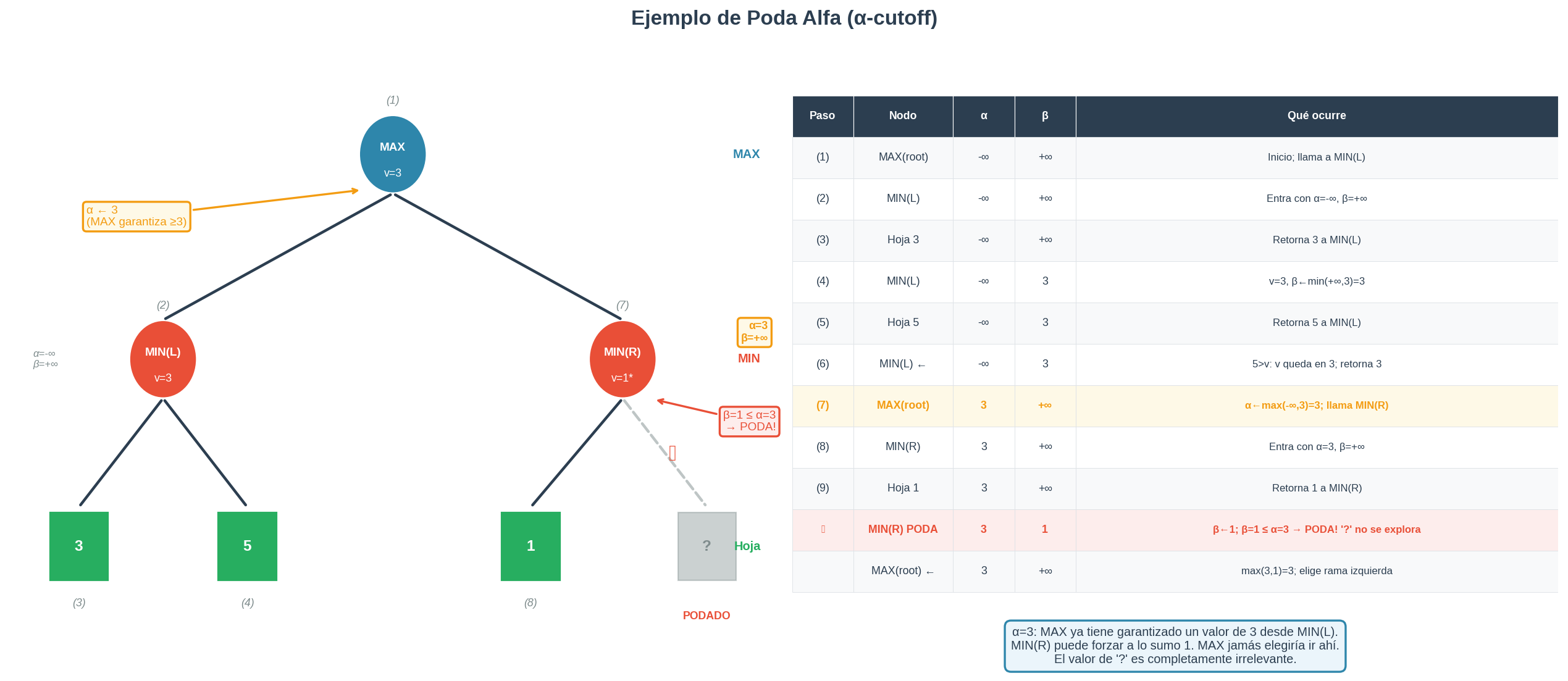
Cómo leer la figura:
- Círculos azules = nodo MAX; círculos rojos = nodo MIN.
- Cuadrados verdes = hojas exploradas (valor entero).
- Cuadrado gris “?” = hoja podada — nunca se visita.
- Borde punteado gris + X = arista podada.
- Caja naranja junto a MIN®: el valor α=3 que se hereda al entrar. Este es el umbral que dispara la poda.
- Caja roja “β=1 ≤ α=3”: el momento exacto de la poda.
- Los números entre paréntesis (1),(2)… indican el orden de visita.
2. Ejemplo B: β-cutoff — MIN ya puede limitar el resultado
El árbol
El árbol simétrico al anterior, pero ahora la raíz es MIN:
MIN(raíz)
/ \
MAX(L) MAX(R)
/ \ / \
8 6 9 ?
MIN elige entre las dos ramas. MAX es el maximizador interno.
Lo que pasa paso a paso
Paso 1 — Explorar MAX(L):
MAX(L) ve el hijo 8. Anota que puede garantizar al menos 8. MAX(L) ve el hijo 6. Como max(8,6)=8, el valor no mejora. MAX(L) retorna 8 a la raíz MIN.
Paso 2 — La raíz MIN anota lo que ya sabe:
MIN recibió 8 desde la rama izquierda. Sabe: “puedo forzar que MAX obtenga como máximo 8.” Ese techo se llama β = 8.
Paso 3 — Explorar MAX® con β=8 en mente:
MIN entra a MAX® llevando consigo el conocimiento de que ya tiene β=8. MAX® ve el hijo 9. MAX® anota que puede garantizar al menos 9 — actualiza su piso α = 9. Ahora α=9 ≥ β=8.
Paso 4 — ¿Por qué parar aquí?
MAX® puede garantizarle a MAX al menos 9 en esta rama. MIN ya sabe que puede forzar el resultado a ≤8 desde MAX(L). MIN nunca elegiría ir por MAX® — si lo hiciera, MAX obtendría ≥9, peor para MIN. El valor de “?” es completamente irrelevante. No necesitamos explorarlo.
Esto es un β-cutoff: la rama se poda porque MAX encontró algo tan bueno que MIN nunca lo permitiría.
La figura
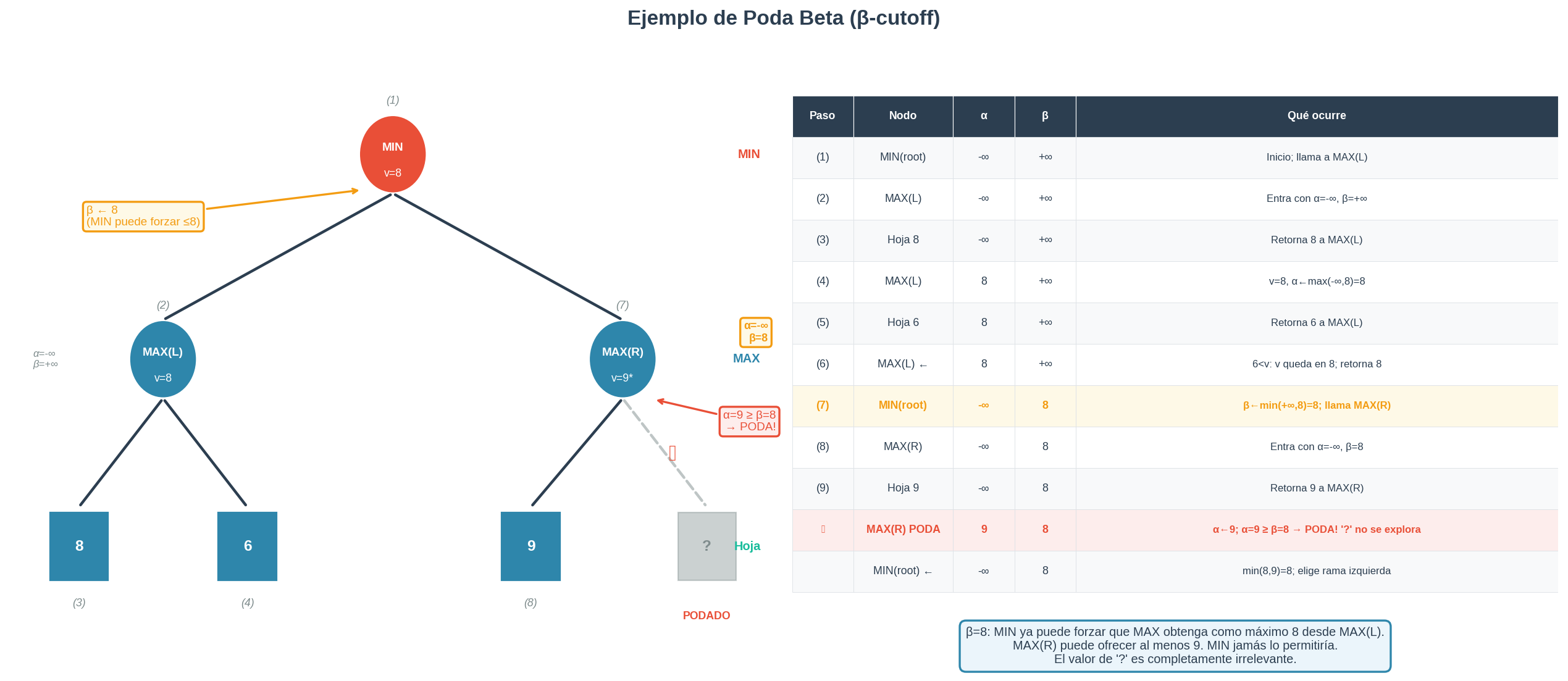
La figura tiene la misma estructura que el Ejemplo A pero con los roles invertidos: raíz MIN en rojo, hijos MAX en azul, β=8 heredado al entrar a MAX®, y el cutoff ocurre cuando α=9 ≥ β=8.
3. Generalizando: ¿qué son α y β?
Ahora que viste los dos ejemplos, las definiciones formales tienen significado concreto:
-
$\alpha$ = el mejor valor que MAX puede garantizarse a lo largo del camino desde la raíz hasta el nodo actual. Representa el piso — ninguna rama que le dé a MAX menos de α es útil. Empieza en $-\infty$ (MAX no sabe nada al inicio) y sube a medida que MAX encuentra mejores opciones.
-
$\beta$ = el mejor valor que MIN puede garantizarse a lo largo del camino desde la raíz hasta el nodo actual. Representa el techo — ninguna rama que le dé a MAX más de β es útil para MIN. Empieza en $+\infty$ (MIN no sabe nada al inicio) y baja a medida que MIN encuentra mejores opciones.
Ambos valores se pasan hacia abajo en el árbol — cada hijo hereda los α y β de su padre. Conforme exploramos, la ventana se estrecha:
$$[\alpha, \beta] \quad \text{(la ventana de valores “todavía útiles”)}$$
| Al inicio | Después de explorar MIN(L)/MAX(L) | Cuando poda |
|---|---|---|
| $\alpha=-\infty$, $\beta=+\infty$ | α sube o β baja | $\alpha \geq \beta$ → poda |
¿Pueden α y β ser positivos o negativos? Sí, cualquier valor en el rango de utilidades. En el Ejemplo A, α=3 es positivo. En un juego con utilidades ${-1, 0, +1}$, α y β estarían en ese rango. No son siempre positivos ni siempre negativos — dependen de lo que ya se exploró.
4. Las dos condiciones de poda
α-cutoff (ocurre en nodo MIN): MIN encontró un hijo con valor $v \leq \alpha$
Situación:
- α es lo mejor que MAX tiene garantizado en otra rama.
- MIN acaba de probar que puede forzar v ≤ α en esta rama.
- MAX nunca elegiría esta rama — ya tiene algo mejor.
Condición: v ≤ α → retornar v inmediatamente
β-cutoff (ocurre en nodo MAX): MAX encontró un hijo con valor $v \geq \beta$
Situación:
- β es lo mejor que MIN puede garantizarse en otra rama (el techo).
- MAX acaba de probar que puede forzar v ≥ β en esta rama.
- MIN nunca elegiría esta rama — si lo hiciera, MAX obtendría demasiado.
Condición: v ≥ β → retornar v inmediatamente
Regla nemotécnica: α-cutoff = MIN descubrió algo demasiado malo para MAX (MAX ya tiene mejor). β-cutoff = MAX descubrió algo demasiado bueno (MIN jamás lo permitiría).
5. En lenguaje natural
El algoritmo completo en cuatro pasos — idéntico a minimax excepto por α y β:
- Si el estado es terminal: devuelve su utilidad. Igual que minimax.
- Si es el turno de MAX: evalúa sucesores, actualiza α. Si en algún momento $v \geq \beta$ — para. MAX encontró algo tan bueno que MIN nunca vendría aquí.
- Si es el turno de MIN: evalúa sucesores, actualiza β. Si en algún momento $v \leq \alpha$ — para. MIN encontró algo tan malo para MAX que MAX nunca vendría aquí.
- En la raíz: la acción elegida es idéntica a minimax. Solo cambia cuántos nodos se exploraron.
α y β se pasan hacia abajo acumulando el conocimiento de ramas ya exploradas.
6. Pseudocódigo
La estructura es idéntica a minimax (mismas tres funciones). Los únicos cambios son tres líneas — [P1], [P2], [P3]:
[P1]— la llamada inicial pasa α=-∞, β=+∞ (sin información todavía).[P2]— dentro del bucle, se actualiza α (en MAX) o β (en MIN) con el mejor valor visto.[P3]— si la ventana se cierra (α≥β), se retorna antes de terminar el bucle.
# ── ALPHA_BETA ───────────────────────────────────────────────────────────────
# Punto de entrada. Igual que MINIMAX pero pasa α y β hacia abajo.
# α=-∞ y β=+∞ iniciales: aún no sabemos nada del árbol.
function ALPHA_BETA(juego, estado):
if juego.jugador(estado) == MAX:
v, accion ← MAX_VALUE_AB(juego, estado, -∞, +∞) # [P1] sin información aún
else:
v, accion ← MIN_VALUE_AB(juego, estado, -∞, +∞) # [P1] ídem
return accion # devolvemos la ACCIÓN óptima, igual que minimax
# ── MAX_VALUE_AB ─────────────────────────────────────────────────────────────
# Igual que MAX_VALUE en minimax, más dos líneas: actualiza α y poda si v≥β.
function MAX_VALUE_AB(juego, estado, α, β):
if juego.terminal(estado): # ¿el juego terminó?
return juego.utilidad(estado), None # hoja: valor exacto conocido
v ← -∞ # peor caso inicial para MAX
mejor ← None
for each accion in juego.acciones(estado): # recorre movimientos legales
sucesor ← juego.resultado(estado, accion) # aplica la acción → hijo
v2, _ ← MIN_VALUE_AB(juego, sucesor, α, β) # evalúa en nivel MIN
if v2 > v: # ¿este hijo es mejor para MAX?
v ← v2
mejor ← accion
α ← max(α, v) # [P2] MAX ahora garantiza al menos v; sube el piso
if v ≥ β: # [P3] β-cutoff: MAX puede forzar ≥β;
return v, mejor # MIN nunca vendría aquí (ya tiene ≤β en otra rama)
return v, mejor
# ── MIN_VALUE_AB ─────────────────────────────────────────────────────────────
# Igual que MIN_VALUE en minimax, más dos líneas: actualiza β y poda si v≤α.
function MIN_VALUE_AB(juego, estado, α, β):
if juego.terminal(estado): # ¿el juego terminó?
return juego.utilidad(estado), None # hoja: valor exacto conocido
v ← +∞ # peor caso inicial para MIN (el valor más alto)
mejor ← None
for each accion in juego.acciones(estado): # recorre movimientos legales
sucesor ← juego.resultado(estado, accion) # aplica la acción → hijo
v2, _ ← MAX_VALUE_AB(juego, sucesor, α, β) # evalúa en nivel MAX
if v2 < v: # ¿este hijo es peor para MAX (=mejor para MIN)?
v ← v2
mejor ← accion
β ← min(β, v) # [P2] MIN ahora garantiza a lo sumo v; baja el techo
if v ≤ α: # [P3] α-cutoff: MIN puede forzar ≤α;
return v, mejor # MAX nunca vendría aquí (ya tiene ≥α en otra rama)
return v, mejor
Los tres cambios sobre minimax:
| Cambio | Dónde | Qué hace |
|---|---|---|
[P1] |
Punto de entrada | Inicializa α=-∞, β=+∞ — sin información al inicio |
[P2] |
Dentro del bucle | Sube α (MAX) o baja β (MIN) — acumula garantías de ramas ya vistas |
[P3] |
Dentro del bucle | Si α≥β la ventana se cerró — retorna antes de ver todos los hijos |
7. Implementación en Python
def alpha_beta(estado, es_max, alpha=-float('inf'), beta=float('inf')):
"""
Alpha-beta para Nim.
Args:
estado : tupla de enteros — tamaño de cada pila, e.g. (2, 3)
es_max : True si es turno de MAX, False si es turno de MIN
alpha : piso — mejor valor que MAX puede garantizarse en el camino actual
beta : techo — mejor valor que MIN puede garantizarse en el camino actual
Returns:
(valor, accion) → valor en {+1, -1}, accion = (indice_pila, cantidad) o None
"""
# ── Caso base ────────────────────────────────────────────────────────────
# En Nim, el terminal es (0,0,...): el jugador en turno no puede mover → pierde
if all(p == 0 for p in estado):
return (-1 if es_max else +1), None # MAX pierde si es su turno, MIN si es el suyo
# ── Inicialización ───────────────────────────────────────────────────────
mejor_valor = -float('inf') if es_max else float('inf')
mejor_accion = None
# ── Exploración de sucesores ─────────────────────────────────────────────
for i, pila in enumerate(estado): # i = índice de la pila
for cant in range(1, pila + 1): # cant = fichas a retirar (1 al tamaño)
nuevo = list(estado)
nuevo[i] -= cant # aplica el movimiento
v, _ = alpha_beta(tuple(nuevo), not es_max, alpha, beta)
if es_max:
# ── Nodo MAX ─────────────────────────────────────────────────
if v > mejor_valor:
mejor_valor = v
mejor_accion = (i, cant)
alpha = max(alpha, mejor_valor) # sube el piso α
if mejor_valor >= beta: # β-cutoff: MAX puede forzar ≥β
return mejor_valor, mejor_accion # MIN nunca vendría aquí
else:
# ── Nodo MIN ─────────────────────────────────────────────────
if v < mejor_valor:
mejor_valor = v
mejor_accion = (i, cant)
beta = min(beta, mejor_valor) # baja el techo β
if mejor_valor <= alpha: # α-cutoff: MIN puede forzar ≤α
return mejor_valor, mejor_accion # MAX nunca vendría aquí
return mejor_valor, mejor_accion
# ── Verificación: alpha-beta == minimax ──────────────────────────────────────
if __name__ == '__main__':
estado = (1, 2)
v_mm, a_mm = minimax(estado, es_max=True)
v_ab, a_ab = alpha_beta(estado, es_max=True)
assert v_mm == v_ab, "Los valores deben coincidir"
assert a_mm == a_ab, "Las acciones deben coincidir"
print(f"Minimax: valor={v_mm}, accion={a_mm}")
print(f"Alpha-beta: valor={v_ab}, accion={a_ab}")
# → Minimax: valor=1, accion=(1, 1)
# → Alpha-beta: valor=1, accion=(1, 1)
8. Traza: Nim(2,3)
Nim(2,3) es el primer juego donde alpha-beta tiene suficientes ramas para podar de forma visible. La estructura es la misma que en los ejemplos abstractos anteriores, pero ahora las utilidades son solo ±1 (no enteros arbitrarios) y hay más niveles.
La decisión final es idéntica a minimax. La diferencia es cuántos nodos se visitaron.
Lectura de la figura
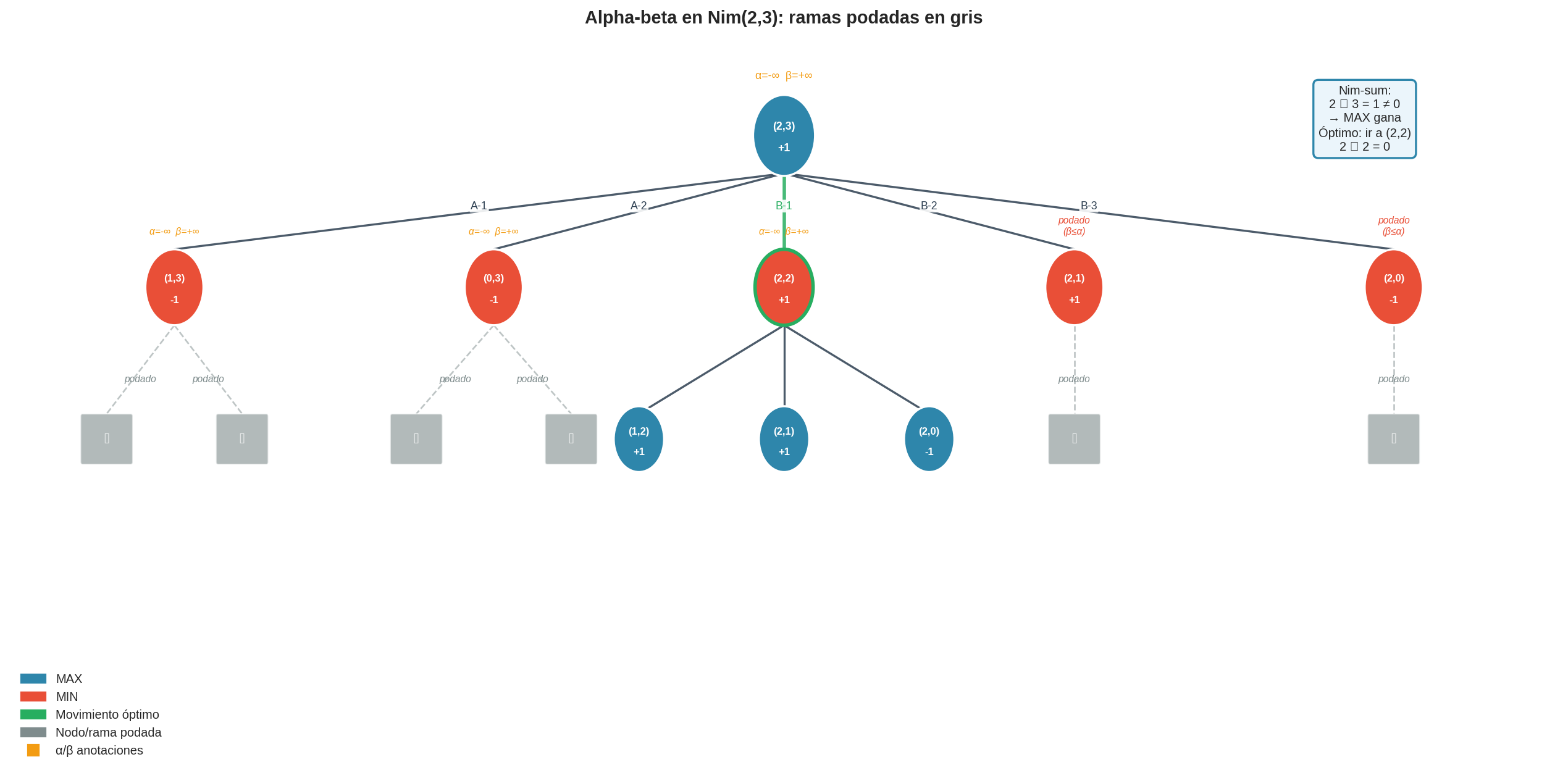
- Nodos azules = turno de MAX. Nodos rojos = turno de MIN.
- Aristas punteadas grises = ramas podadas — esos subárboles nunca se expanden.
- El par (α, β) anotado junto a cada nodo muestra los valores al momento de visita. α y β se heredan del padre y se actualizan localmente. Observa cómo α sube cuando MAX encuentra una buena jugada, y β baja cuando MIN encuentra una buena respuesta.
- Nodos terminales (cuadrados): estado (0,0). Como las utilidades de Nim son solo ±1, α y β también tomarán valores en {-∞, -1, 0, +1, +∞}. El mecanismo es exactamente el mismo que en los ejemplos abstractos — solo el rango es más estrecho.
Traza parcial — el momento de la primera poda
| # | Estado | Jugador | α | β | Retorna | Nota |
|---|---|---|---|---|---|---|
| 1 | (2,3) | MAX | $-\infty$ | $+\infty$ | — | inicio |
| 2 | (1,3) | MIN | $-\infty$ | $+\infty$ | — | acción A-1 |
| 3 | (0,3) | MAX | $-\infty$ | $+\infty$ | — | MIN→A-1 |
| 4 | (0,2) | MIN | $-\infty$ | $+\infty$ | — | MAX→B-1 |
| 5 | (0,1) | MAX | $-\infty$ | $+\infty$ | — | MIN→B-1 |
| 6 | (0,0) | MAX | $-\infty$ | $+\infty$ | −1 | terminal |
| 7 | ← (0,1) | MAX | $-\infty$ | $+\infty$ | +1 | única acción |
| 8 | ← (0,2) | MIN | $-\infty$ | +1 | — | β ← +1 |
| 9 | (0,0) | MIN | $-\infty$ | +1 | +1 | terminal |
| 10 | ← (0,2) | MIN | $-\infty$ | +1 | — | v=+1, β queda +1 |
| 11 | ← (0,3) | MAX | +1 | $+\infty$ | +1 | α ← +1 |
| 12 | (1,2) | MIN | +1 | $+\infty$ | — | segunda rama de (1,3) |
| 13 | (0,2) | MAX | +1 | $+\infty$ | — | |
| 14 | (0,1) | MIN | +1 | $+\infty$ | — | |
| 15 | (0,0) | MIN | +1 | $+\infty$ | +1 | terminal |
| 16 | ← (0,1) | MIN | +1 | +1 | +1 | β←+1; β=+1 ≤ α=+1 → α-CUTOFF |
| 17 | (1,2) podado | MIN | — | — | — | ramas restantes no se exploran |
| 18 | ← (1,3) | MIN | — | — | +1 | MIN no puede hacer mejor que +1 |
| 19 | ← (2,3) | MAX | +1 | — | +1 | acción A-1 confirmada óptima |
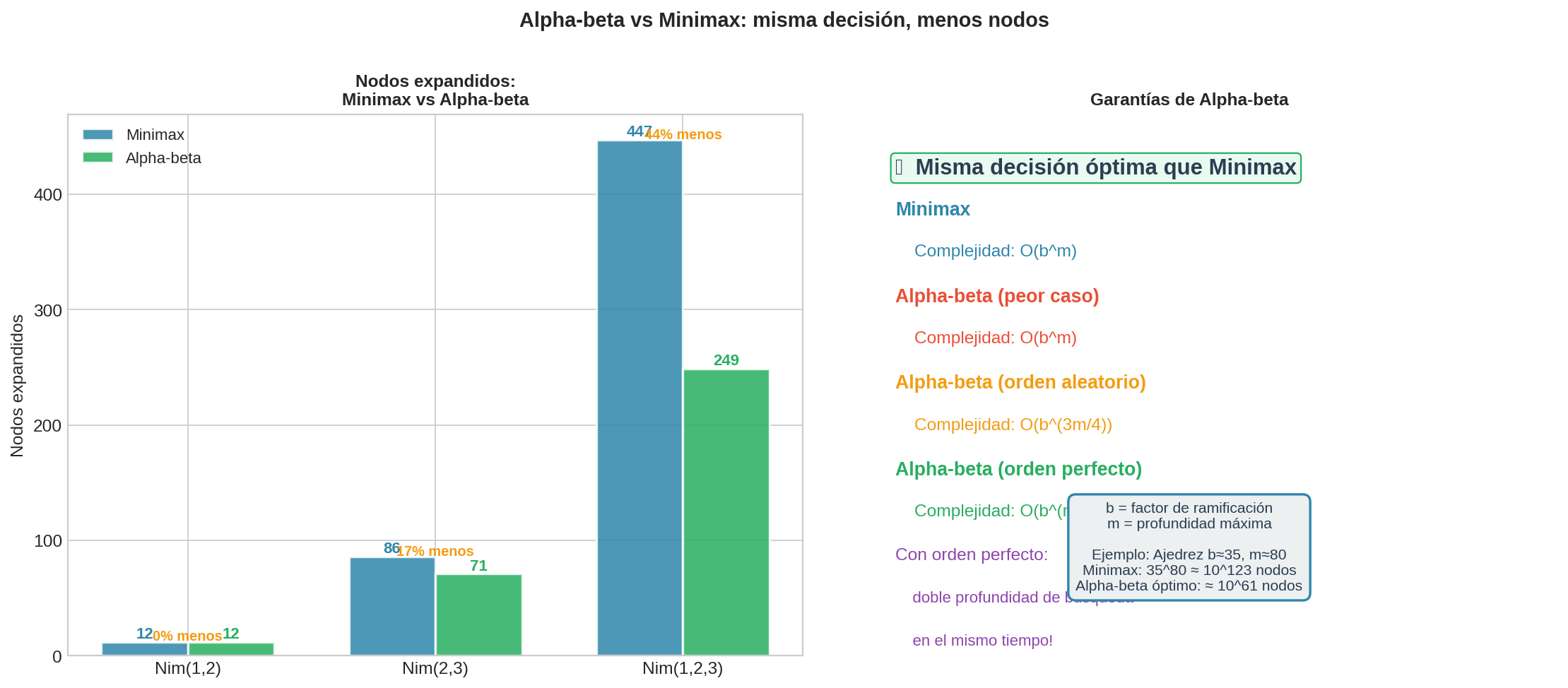
La figura muestra el número de nodos expandidos por minimax vs. alpha-beta en varios juegos Nim. La barra azul es minimax (todos los nodos), la barra verde es alpha-beta (subconjunto). La acción elegida es idéntica en ambos — la reducción es solo en trabajo.
9. Análisis de eficiencia
| Ordenamiento | Complejidad | Equivalencia | Ejemplo: ajedrez |
|---|---|---|---|
| Peor caso | $O(b^m)$ | = minimax | Sin ahorro — poda nunca dispara |
| Orden aleatorio | $O(b^{3m/4})$ | ≈ 25% menos profundidad | De profundidad 4 a ~3 |
| Orden perfecto | $O(b^{m/2})$ | dobla la profundidad efectiva | De profundidad 4 a 8 |
Con orden perfecto, alpha-beta puede buscar el doble de profundidad que minimax con el mismo tiempo. Para ajedrez, pasar de profundidad 4 a 8 es la diferencia entre un programa que comete errores tácticos obvios y uno que planea combinaciones de varias jugadas.
Intuición del orden perfecto: si siempre exploramos primero el mejor movimiento disponible, α sube (o β baja) tan rápido como es posible, generando cortes en todos los hermanos que restan. Esto se parece a la heurística $h(n)$ en A* del módulo 14 — ordenar mejor = buscar más eficientemente.
10. Ordenamiento de movimientos
El análogo adversarial de $h(n)$ en A*:
En A*, ordenar la frontera por $f(n)=g+h$ guía la búsqueda hacia la meta. En alpha-beta, explorar primero los movimientos más prometedores genera cortes más pronto.
Estrategias comunes:
- Killer moves: movimientos que ya causaron cortes en otras ramas del mismo nivel.
- Evaluación rápida: calcular un valor aproximado por movimiento antes de ordenarlos.
- Tabla de transposición: reutilizar valores de posiciones ya calculadas que se repiten por distintas secuencias de movimientos.
11. Una posición real de tic-tac-toe
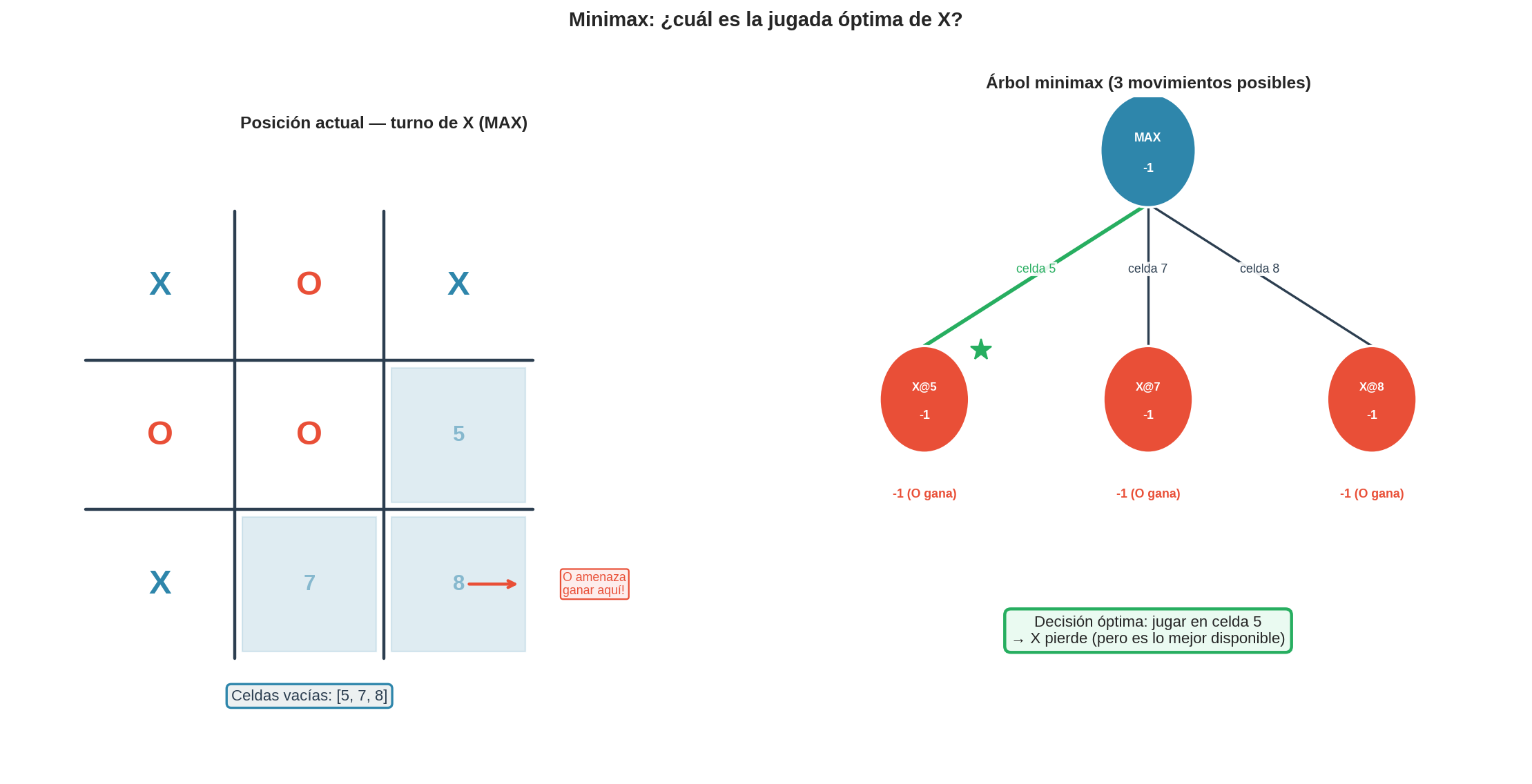
La figura muestra una posición donde O amenaza ganar en la siguiente jugada. Minimax identifica el único movimiento correcto de X — bloquear. Alpha-beta llega a la misma conclusión expandiendo un subconjunto estrictamente menor de nodos: en cuanto encuentra el bloqueo obligatorio, poda todas las ramas alternativas.
12. ¿Y el ajedrez?
Alpha-beta con orden perfecto puede alcanzar profundidad 8 en lugar de 4 con el mismo cómputo. Para los motores modernos (profundidad 12-25), se combinan alpha-beta + ordenamiento sofisticado + funciones de evaluación entrenadas con redes neuronales. El mecanismo de poda es el mismo que en los ejemplos A y B de esta sección — lo que cambió es la escala.
Siguiente: Juegos complejos →