| Notebook | Colab |
|---|---|
| Notebook 02 — Minimax y alpha-beta |
Juegos complejos: más allá de minimax exacto
“The game of chess is not about perfect play — it’s about better play than your opponent.”
Minimax exacto funciona perfectamente para Nim(1,2) porque el árbol tiene 12 nodos. Para ajedrez, incluso con alpha-beta y el mejor ordenamiento posible, el árbol es inmanejable con la tecnología actual. Esta sección presenta tres adaptaciones que hacen posible jugar juegos complejos — y muestra por qué Nim es especialmente interesante: esconde una fórmula matemática exacta que minimax descubre implícitamente.
1. Los números
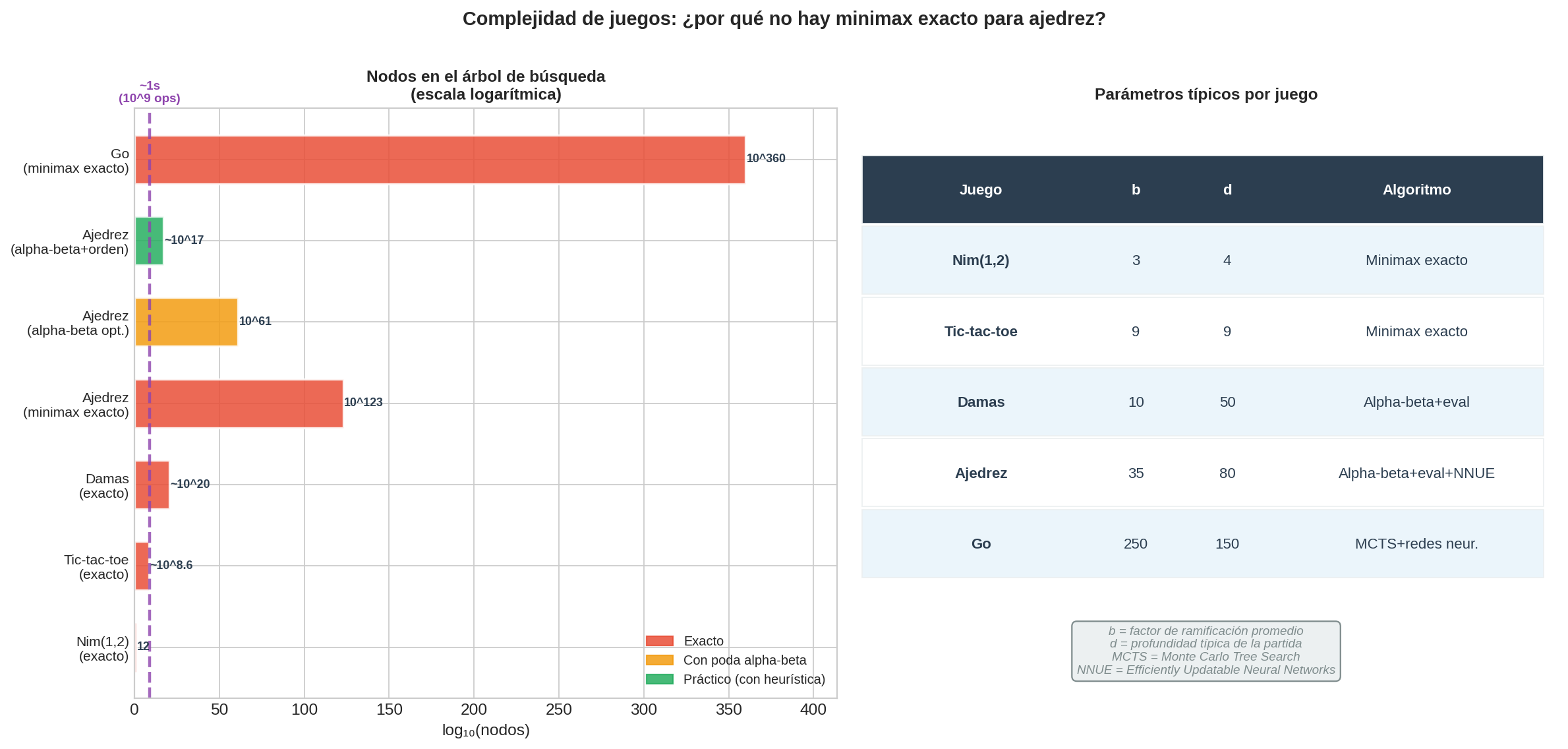
| Juego | Nodos exactos / aprox. | ¿Minimax exacto? |
|---|---|---|
| Nim(1,2) | 12 | Sí |
| Tic-tac-toe | $\leq 362{,}880$ | Sí (con simetría) |
| Ajedrez (árbol completo) | $\approx 10^{123}$ | No |
| Ajedrez (alpha-beta óptimo) | $\approx 10^{61}$ | No |
| Ajedrez (práctica, prof. 12) | $\approx 10^{17}$ | No — pero factible |
| Go | $\approx 10^{360}$ | No |
Incluso $10^{17}$ nodos es difícil para ajedrez — los mejores motores manejan $10^8$–$10^9$ nodos por segundo con hardware dedicado, llegando a profundidades útiles en segundos gracias a tres adaptaciones.
2. Adaptación 1: límite de profundidad
En minimax exacto el único caso base es Terminal(s) — el juego terminó. Con límite de profundidad añadimos una segunda condición de parada: profundidad == 0. Cuando se alcanza ese nivel, en vez de devolver la utilidad real (que no sabemos porque no llegamos a las hojas), devolvemos una estimación EVALUAR(s).
# ── MINIMAX_LIMITADO ─────────────────────────────────────────────────────────
# Igual que MINIMAX, con un parámetro adicional: la profundidad restante.
# Cuando profundidad llega a 0 nos detenemos aunque el juego no haya terminado
# y usamos EVALUAR(s) para estimar el valor de esa posición.
#
# Parámetros:
# juego : objeto con los 7 componentes (acciones, resultado, terminal, etc.)
# estado : configuración actual del tablero
# profundidad : cuántos niveles más podemos bajar (decrece en cada llamada)
# es_max : True si le toca a MAX, False si le toca a MIN
function MINIMAX_LIMITADO(juego, estado, profundidad, es_max):
# ── Caso base ────────────────────────────────────────────────────────────
# Hay DOS razones para parar:
# 1. El juego terminó realmente → devolvemos utilidad exacta
# 2. Llegamos al límite de profundidad → devolvemos estimación eval
# En minimax exacto solo existía la razón 1; este es el cambio [P1].
if juego.terminal(estado) or profundidad == 0: # [P1] condición de corte ampliada
return EVALUAR(estado, es_max), None # [P1] EVALUAR sustituye a UTILIDAD en el corte
# ── Inicialización (idéntica a MINIMAX) ──────────────────────────────────
mejor_valor = -∞ if es_max else +∞ # MAX quiere maximizar, MIN quiere minimizar
mejor_accion = None # guardará la acción que produce mejor_valor
# ── Exploración de sucesores ─────────────────────────────────────────────
for accion in juego.acciones(estado): # recorre cada movimiento legal
sucesor ← juego.resultado(estado, accion) # aplica la acción → estado hijo
v, _ ← MINIMAX_LIMITADO(juego, sucesor,
profundidad - 1, # baja un nivel (acerca al corte)
not es_max) # alterna el turno
if es_max and v > mejor_valor: # ¿MAX encontró algo mejor?
mejor_valor ← v
mejor_accion ← accion
elif not es_max and v < mejor_valor: # ¿MIN encontró algo peor para MAX?
mejor_valor ← v
mejor_accion ← accion
return mejor_valor, mejor_accion # propaga el mejor valor encontrado hacia arriba
Los dos cambios sobre MINIMAX exacto:
| Cambio | Línea | Qué hace |
|---|---|---|
[P1a] |
condición de parada | Añade or profundidad == 0 — detiene la búsqueda aunque el juego no haya terminado |
[P1b] |
valor de retorno en el corte | Llama a EVALUAR(s) en lugar de UTILIDAD(s) — estima el valor porque no conocemos el resultado exacto |
El resto del algoritmo es idéntico a minimax: misma alternancia MAX/MIN, misma propagación de valores hacia arriba, misma estructura recursiva.
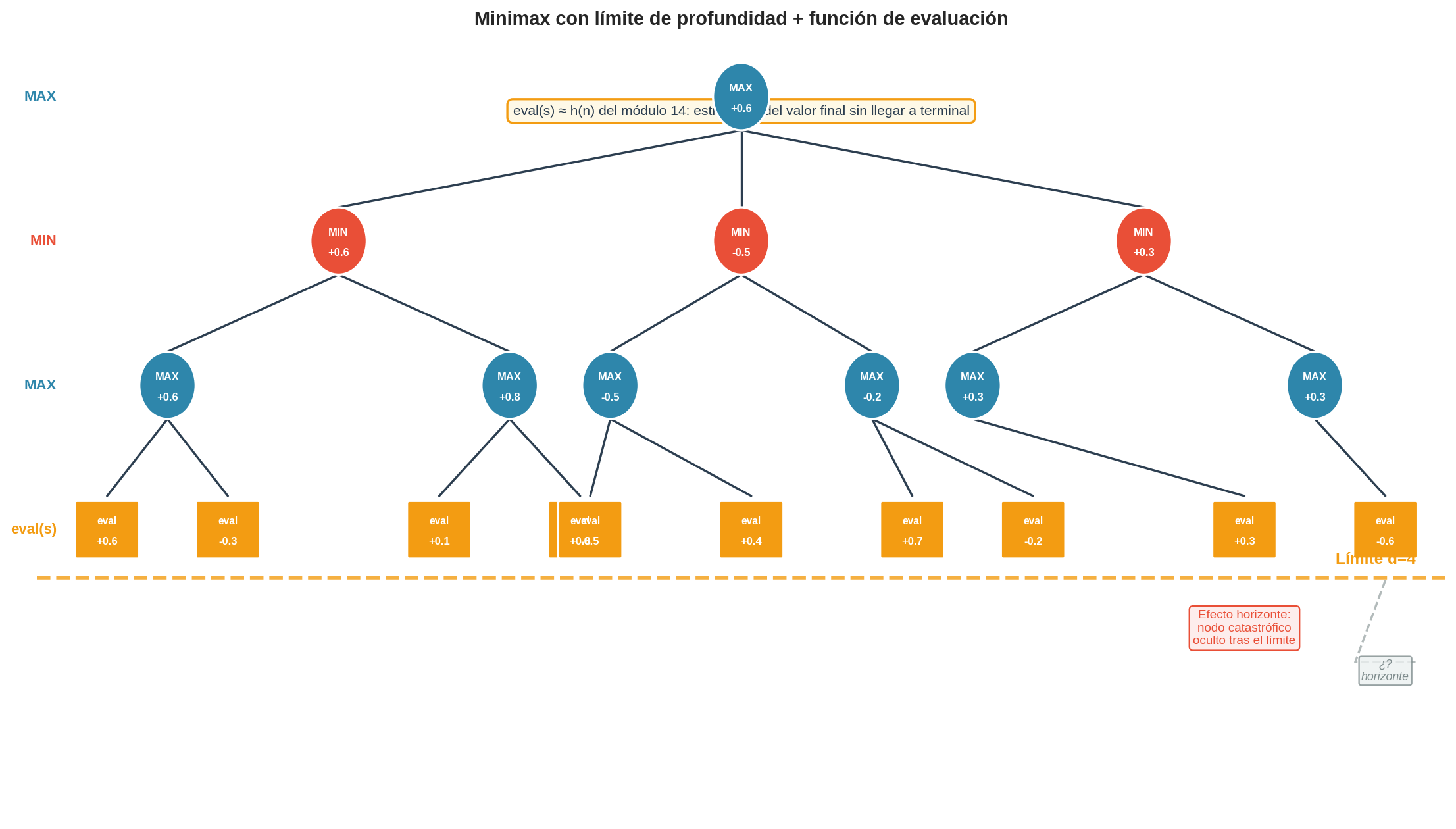
La figura ilustra el árbol truncado: los nodos en el nivel de corte son evaluados por eval(s) en lugar de tener utilidad exacta. Las ramas que continúan más allá del límite se muestran punteadas — el algoritmo no las explora.
3. Adaptación 2: función de evaluación
La conexión con el módulo 14 es directa:
En A*, $h(n)$ estimaba el costo restante hasta la meta. En minimax con límite, $eval(s)$ estima el valor final del juego desde $s$ — sin llegar a las hojas. Son análogos exactos: una estimación rápida que guía la búsqueda cuando la información exacta es inaccesible.
Propiedades que debe cumplir eval(s):
- Rápida: computable en tiempo constante — se llama millones de veces por partida.
- Acotada: devuelve valores en el rango de la utilidad real. Si $U \in [-1, +1]$, entonces $eval(s) \in [-1, +1]$.
- Correlacionada: posiciones donde MAX tiene ventaja real deben tener $eval(s)$ alta.
Para ajedrez, una función clásica combina características de la posición:
$$eval(s) = w_1 \cdot \text{material}(s) + w_2 \cdot \text{posición}(s) + w_3 \cdot \text{estructura-peones}(s) + \cdots$$
Los pesos $w_i$ se calibran contra una base de datos de partidas o por auto-juego. Los motores modernos aprenden estos pesos con redes neuronales.
Valores de material estándar en ajedrez:
| Pieza | Valor aproximado |
|---|---|
| Peón | 1 |
| Caballo | 3 |
| Alfil | 3 |
| Torre | 5 |
| Dama | 9 |
| Rey | $\infty$ |
def eval_ajedrez_simple(tablero, es_max):
"""
Función de evaluación material básica para ajedrez.
Positivo = ventaja de blancas (MAX), negativo = ventaja de negras (MIN).
"""
VALORES = {'P': 1, 'N': 3, 'B': 3, 'R': 5, 'Q': 9, 'K': 0}
score = 0
for pieza, color in tablero.piezas():
v = VALORES.get(pieza.tipo, 0)
score += v if color == 'blancas' else -v
return score if es_max else -score
4. El efecto horizonte
El árbol se corta en profundidad $d$. Un movimiento catastrófico ocurre en profundidad $d+1$ — el motor no lo ve. Ejemplo clásico: el motor calcula que puede capturar un peón en el movimiento $d$, sin notar que en el movimiento $d+1$ el oponente captura su dama. El motor “empuja” el problema más allá del horizonte de búsqueda.
Profundidad límite = 4:
Movimiento 4: MAX captura peón → eval(s) mejora para MAX
Movimiento 5: MIN captura dama → colapso real, fuera del límite
↑ el motor no lo ve
Solución parcial: búsqueda de quiescencia — extender la búsqueda más allá del límite para posiciones “inestables” (capturas, jaques, amenazas inmediatas). Solo se termina la búsqueda en posiciones “tranquilas” donde eval es confiable. Esto añade complejidad pero elimina los errores más graves del efecto horizonte.
5. Adaptación 3: búsqueda iterativa
La conexión con IDA* del módulo 14 es directa:
IDA* aumentaba el límite de $f$ iteración por iteración, usando la búsqueda anterior para guiar la siguiente. Minimax iterativo hace exactamente lo mismo con la profundidad: busca a
depth=1, luegodepth=2,depth=3…
def minimax_iterativo(juego, estado, tiempo_limite):
"""
Minimax con profundización iterativa.
Devuelve la mejor acción encontrada antes de que expire el tiempo.
"""
mejor_accion = None
profundidad = 1
while tiempo_restante(tiempo_limite) > 0:
v, accion = minimax_limitado(juego, estado, profundidad, es_max=True)
mejor_accion = accion # guardamos siempre la última respuesta completa
profundidad += 1
return mejor_accion # la búsqueda de profundidad anterior fue completa
La ventaja es doble:
- Anytime: si el tiempo se acaba durante la búsqueda de profundidad $d$, todavía tenemos la respuesta completa de profundidad $d-1$.
- Ordenamiento de movimientos: la acción óptima a profundidad $d-1$ probablemente lo sea también a profundidad $d$. Explorarla primero maximiza las podas de alpha-beta en la iteración siguiente.
6. El caso de Nim: la fórmula que minimax descubre
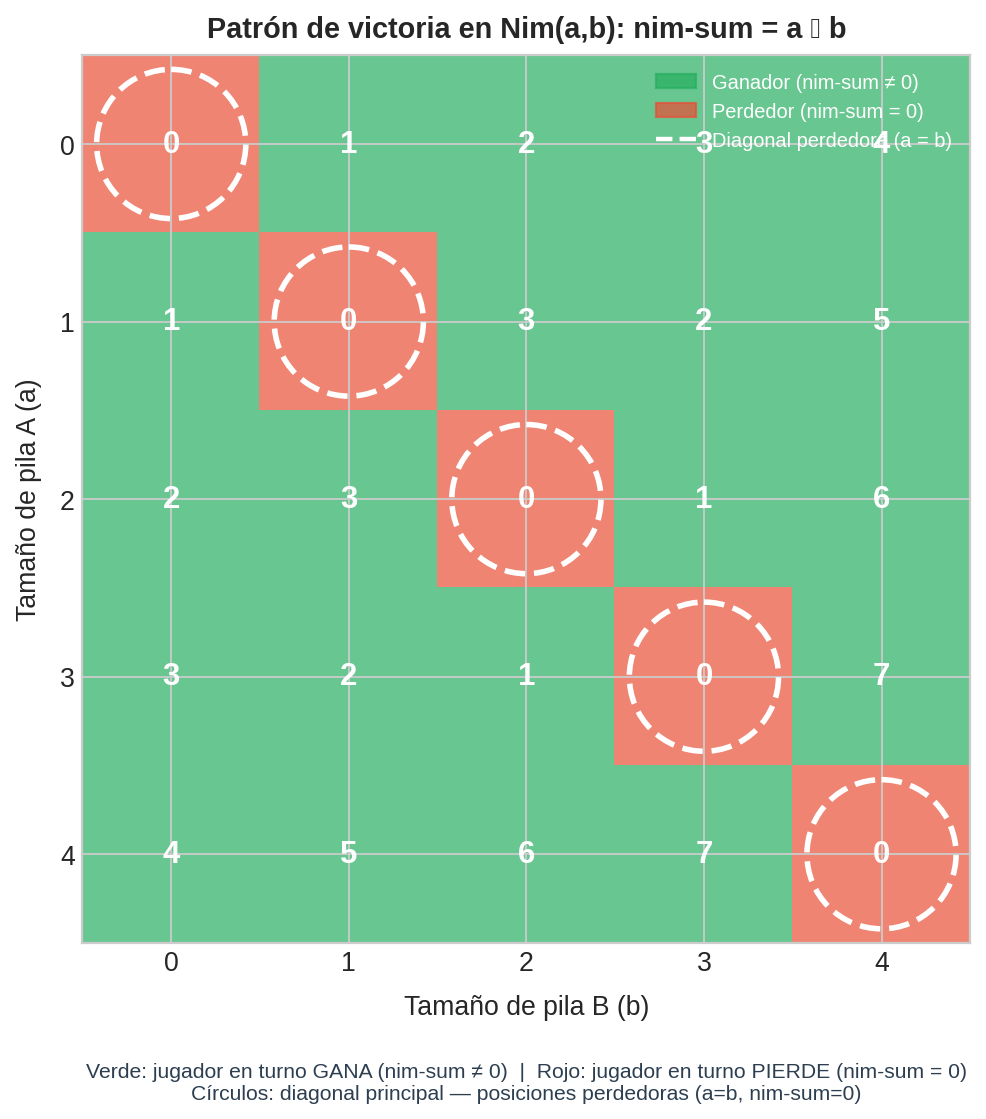
Minimax exploró el árbol de Nim(1,2) y encontró que la jugada óptima es B-1 → (1,1). Podemos verificar: el nim-sum de (1,1) es $1 \oplus 1 = 0$. ¿Coincidencia? No.
El nim-sum de $k$ pilas es el XOR bit a bit de todos sus tamaños:
$$\text{nim-sum}(a_1, a_2, \ldots, a_k) = a_1 \oplus a_2 \oplus \cdots \oplus a_k$$
Ejemplos: $1 \oplus 2 = 3$ (en binario: $01 \oplus 10 = 11$). $1 \oplus 1 = 0$. $2 \oplus 3 = 1$ (en binario: $010 \oplus 011 = 001$).
La regla de la estrategia óptima (teorema de Sprague-Grundy):
- Si nim-sum $= 0$ en tu turno → estás en posición perdedora con juego perfecto del oponente.
- Si nim-sum $\neq 0$ en tu turno → siempre existe al menos una jugada que lleva a nim-sum $= 0$ → ganas.
La estrategia óptima en Nim se reduce a: muévete siempre a una posición con nim-sum $= 0$.
Verificación para Nim(1,2):
- Estado inicial: $1 \oplus 2 = 3 \neq 0$ → MAX tiene posición ganadora. ✓
- Acción óptima B-1 → (1,1): $1 \oplus 1 = 0$ → MIN está en posición perdedora. ✓
- Acción A-1 → (0,2): $0 \oplus 2 = 2 \neq 0$ → MIN seguiría en posición ganadora. ✗
- Acción B-2 → (1,0): $1 \oplus 0 = 1 \neq 0$ → MIN seguiría en posición ganadora. ✗
Solo B-1 lleva a nim-sum $= 0$ — exactamente lo que minimax calculó.
def estrategia_nim_xor(estado):
"""
Estrategia óptima para Nim usando nim-sum XOR.
Mucho más rápida que minimax: O(k) en vez de O(b^m).
"""
nim_sum = 0
for pila in estado:
nim_sum ^= pila
if nim_sum == 0:
# Posición perdedora — cualquier movimiento es subóptimo
# Devuelve el primer movimiento disponible
for i, pila in enumerate(estado):
if pila > 0:
return (i, 1)
return None
# Buscar una pila cuyo tamaño XOR nim_sum sea menor que la pila actual
for i, pila in enumerate(estado):
objetivo = pila ^ nim_sum
if objetivo < pila:
return (i, pila - objetivo) # retirar (pila - objetivo) fichas
return None # no debería ocurrir si nim_sum != 0
La figura muestra el patrón XOR para todas las posiciones Nim(a,b) con $a, b \in {0, 1, 2, 3, 4}$. Las posiciones marcadas en rojo (nim-sum $= 0$) forman un patrón visualmente reconocible — la diagonal y ciertos antidiagonales. Minimax descubre ese patrón a través de la exploración recursiva; la teoría lo comprime en una fórmula.
Para ajedrez, no existe ese XOR. Nadie ha encontrado una fórmula compacta para el valor perfecto de una posición de ajedrez. Ahí es donde
eval(s)es irreemplazable — y donde el progreso en IA de juegos sigue ocurriendo.
7. Juegos estocásticos
Backgammon tiene dados; póker tiene cartas ocultas. Minimax asume que MIN elige el peor resultado para MAX — pero los dados no eligen, promedian.
Si aplicamos minimax al backgammon, asumiríamos que MIN controla los dados — demasiado pesimista. La solución: expectimax — reemplazar los nodos MIN con nodos de azar que toman el valor esperado:
$$V_{\text{azar}}(s) = \sum_{r} P® \cdot V!\left(\text{Resultado}(s, r)\right)$$
El árbol tiene tres tipos de nodos:
- MAX: elige la acción que maximiza.
- MIN: elige la acción que minimiza.
- Azar: promedia sobre todos los resultados posibles ponderados por probabilidad.
Mismo árbol, semántica distinta en ciertos nodos. Lo dejamos aquí como puntero — el módulo de decisiones bajo incertidumbre lo formaliza.
8. El panorama: de Deep Blue a AlphaZero
Tres hitos que muestran la evolución del marco:
| Sistema | Año | Técnica | Resultado |
|---|---|---|---|
| Deep Blue | 1997 | Alpha-beta + eval manual (~8,000 características) + hardware especializado. Profundidad ~12 | Derrotó a Kasparov |
| Stockfish | 2023 | Alpha-beta + evaluación neuronal (NNUE — Efficiently Updatable Neural Network). Profundidad 25-30 | Motor de código abierto más fuerte |
| AlphaZero | 2018 | MCTS (Monte Carlo Tree Search) + red neuronal profunda. Sin eval manual — aprendida por auto-juego | Derrotó a Stockfish |
El marco es el mismo en todos los casos: árbol de juego + propagación de valores + alguna forma de evaluar posiciones. Lo que evolucionó es la función de evaluación (de manual a aprendida) y la estrategia de búsqueda (de alpha-beta a MCTS).
9. Tabla comparativa: módulos 13–15
| Módulo | Algoritmo | Motor | ¿Adversarial? | Óptimo | Tiempo | Espacio |
|---|---|---|---|---|---|---|
| 13 | BFS | FIFO | No | Sí (sin pesos) | $O(b^d)$ | $O(b^d)$ |
| 13 | DFS | LIFO | No | No | $O(b^m)$ | $O(b \cdot m)$ |
| 13 | IDDFS | LIFO + límite | No | Sí (sin pesos) | $O(b^d)$ | $O(b \cdot d)$ |
| 14 | Dijkstra | $g(n)$ | No | Sí | $O((V+E)\log V)$ | $O(V)$ |
| 14 | Greedy | $h(n)$ | No | No | $O(b^m)$ | $O(b^m)$ |
| 14 | A* | $g+h$ | No | Sí | $O(b^d)$ | $O(b^d)$ |
| 14 | IDA* | DFS + límite $f$ | No | Sí | $O(b^d)$ | $O(b \cdot d)$ |
| 15 | Minimax | DFS recursivo | Sí | Sí* | $O(b^m)$ | $O(b \cdot m)$ |
| 15 | Alpha-beta | DFS + poda | Sí | Sí* | $O(b^{m/2})$ | $O(b \cdot m)$ |
| 15 | Min. límite+eval | DFS + corte | Sí | No | $O(b^d)$ | $O(b \cdot d)$ |
*Óptimo contra oponente óptimo.
Los algoritmos del módulo 15 ocupan las últimas tres filas de la tabla. El patrón se mantiene: todos son variantes del mismo esquema de búsqueda — árbol, recursión, propagación de valores hacia atrás — con distintos compromisos entre exactitud, tiempo y espacio.