| Notebook | Colab |
|---|---|
| Notebook 02 — Planificación forward |
Heurísticas para planificación: el mismo truco del módulo 14
“Simplicity is the ultimate sophistication.” — Leonardo da Vinci
Forward planning con BFS funciona perfectamente para Blocks World con 3 bloques (13 estados). Pero con 20 bloques el espacio de estados tiene más de $10^{18}$ estados — BFS no alcanza. Necesitamos el mismo truco del módulo 14: una heurística que guíe la búsqueda hacia la meta sin explorar todo el espacio.
1. El problema: explosión del espacio de estados
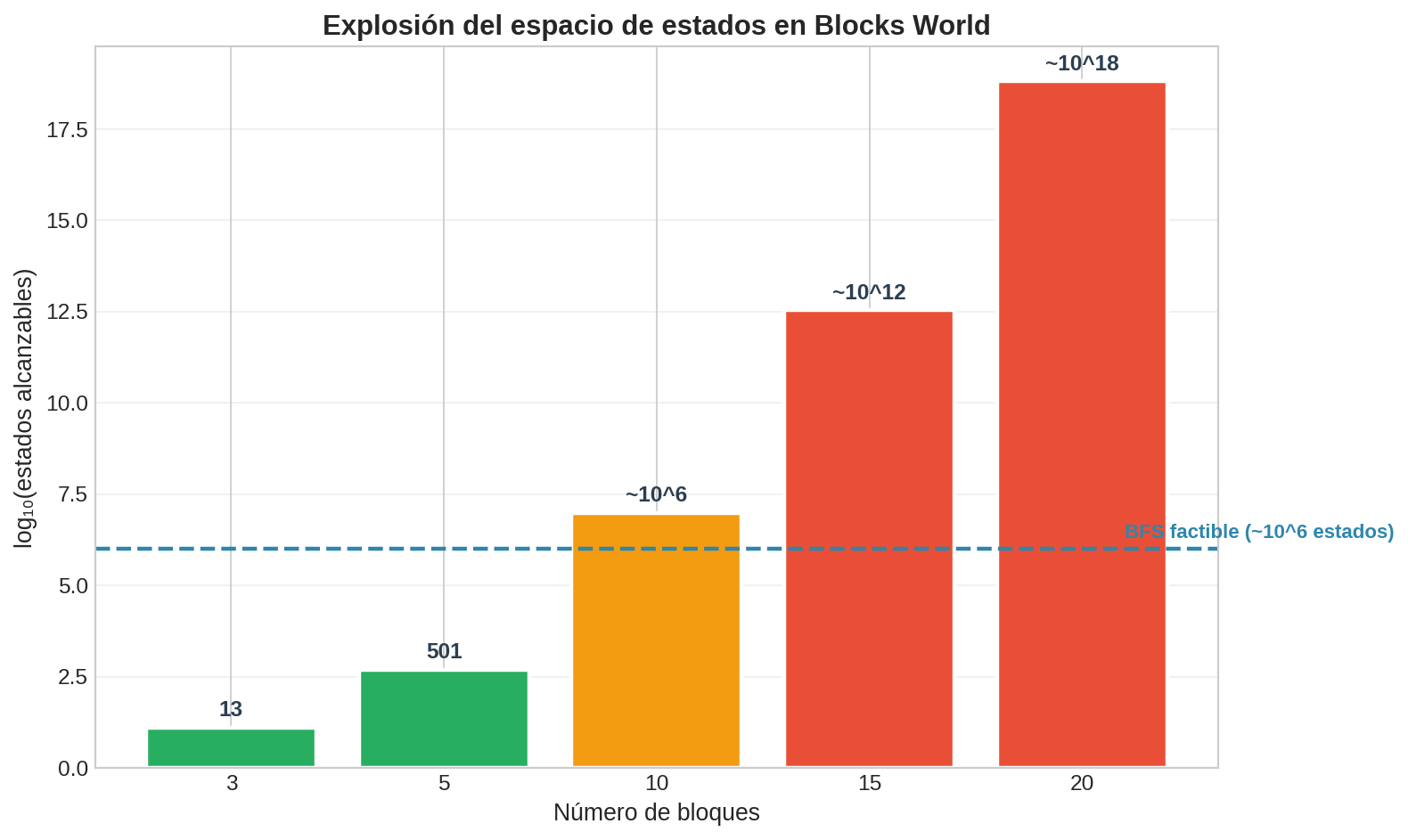
| Bloques | Estados alcanzables (aprox.) | ¿BFS factible? |
|---|---|---|
| 3 | 13 | Sí |
| 5 | ~500 | Sí |
| 10 | ~$10^7$ | Apenas |
| 15 | ~$10^{12}$ | No |
| 20 | ~$10^{18}$ | No |
El crecimiento es factorial ($\approx e \cdot n!$) — mucho peor que exponencial. Con 20 bloques, incluso a 1 billón de estados por segundo, BFS tardaría ~30 años.
Esto es exactamente el mismo muro que encontramos en el módulo 14:
- Módulo 14: BFS en un grafo ponderado es demasiado lento → A* con heurística $h(n)$.
- Módulo 16: BFS en el espacio de estados de planificación es demasiado lento → Forward search con heurística $h(s)$.
La pregunta es: ¿de dónde sacamos una heurística para planificación?
2. La técnica de relajación: recordatorio del módulo 14
En el módulo 14 aprendimos la técnica de relajación para diseñar heurísticas admisibles:
Relajar = tomar el problema original, eliminar alguna restricción, y resolver el problema más fácil. La solución del problema relajado es siempre $\leq$ que la del original → heurística admisible.
Ejemplos del módulo 14:
| Problema | Restricción eliminada | Heurística resultante |
|---|---|---|
| 8-puzzle | Las fichas no pueden pasar a través de otras | Distancia Manhattan |
| 8-puzzle | Las fichas solo se mueven a casillas adyacentes | Fichas mal colocadas |
| Navegación | Las calles tienen curvas y sentidos | Distancia euclidiana |
El patrón siempre es el mismo: el problema original tiene reglas que lo hacen difícil. Eliminamos una regla para obtener un problema más fácil. La solución del problema fácil subestima la del difícil — exactamente lo que A* necesita.
¿Qué restricción podemos eliminar en STRIPS?
3. Definición formal de un problema de planificación STRIPS
Antes de relajar, necesitamos definir con precisión qué es un problema de planificación. Un problema de planificación STRIPS es una tupla de cuatro elementos:
$$\Pi = \langle P,\ A,\ s_0,\ G \rangle$$
| Componente | Qué es | Ejemplo (Blocks World, 3 bloques) |
|---|---|---|
| $P$ | Conjunto de proposiciones posibles del dominio | ${\text{On}(A,B),\ \text{On}(A,C),\ \text{On}(A,\text{Mesa}),\ \text{Clear}(A),\ \ldots}$ — 12 proposiciones en total |
| $A$ | Conjunto de acciones — cada una con nombre, Pre, Add, Delete | Las 18 acciones concretas: Mover, MoverAMesa, MoverDesdeMesa |
| $s_0 \subseteq P$ | Estado inicial — subconjunto de proposiciones verdaderas al inicio | ${\text{On}(A,\text{Mesa}),\ \text{On}(B,\text{Mesa}),\ \text{On}(C,\text{Mesa}),\ \text{Clear}(A),\ \text{Clear}(B),\ \text{Clear}©}$ |
| $G \subseteq P$ | Meta — proposiciones que deben ser verdaderas al final | ${\text{On}(A,B),\ \text{On}(B,C)}$ |
Un estado es cualquier subconjunto $s \subseteq P$ — un conjunto de proposiciones verdaderas en ese momento.
Una acción $a \in A$ es una tupla $a = \langle \text{Pre}(a),\ \text{Add}(a),\ \text{Del}(a) \rangle$ donde:
- $\text{Pre}(a) \subseteq P$ — proposiciones que deben ser verdaderas para ejecutar $a$.
- $\text{Add}(a) \subseteq P$ — proposiciones que se vuelven verdaderas al ejecutar $a$.
- $\text{Del}(a) \subseteq P$ — proposiciones que dejan de ser verdaderas al ejecutar $a$.
Una acción $a$ es aplicable en un estado $s$ si y solo si $\text{Pre}(a) \subseteq s$.
La transición al aplicar $a$ en $s$ produce el nuevo estado:
$$s’ = (s - \text{Del}(a)) \cup \text{Add}(a)$$
Un plan es una secuencia de acciones $\pi = \langle a_1, a_2, \ldots, a_k \rangle$ tal que:
- $a_1$ es aplicable en $s_0$, produciendo $s_1$.
- $a_2$ es aplicable en $s_1$, produciendo $s_2$.
- $\ldots$
- $a_k$ es aplicable en $s_{k-1}$, produciendo $s_k$.
- $G \subseteq s_k$ — el estado final contiene todas las proposiciones de la meta.
El costo del plan es su longitud $k$ (número de acciones). El plan óptimo es el de menor costo. Llamamos $h^∗(s)$ al costo del plan óptimo desde el estado $s$ hasta la meta.
4. Relajación por eliminación de deletes: definición formal
La restricción que eliminamos
La transición de STRIPS tiene dos operaciones: eliminar proposiciones viejas y agregar proposiciones nuevas:
$$s’ = (\underset{\text{eliminar}}{s - \text{Del}(a)}) \cup \underset{\text{agregar}}{\text{Add}(a)}$$
La lista delete es la parte que hace difícil la planificación. Es lo que obliga a deshacer pasos, reorganizar bloques intermedios, y planificar con cuidado el orden de las acciones.
El problema relajado $\Pi^+$
La relajación por eliminación de deletes (delete relaxation) construye un nuevo problema $\Pi^+$ a partir de $\Pi$ eliminando todas las listas delete:
$$\Pi^+ = \langle P,\ A^+,\ s_0,\ G \rangle$$
donde $A^+$ es el conjunto de acciones con las listas delete vaciadas. Para cada acción $a \in A$, su versión relajada $a^+ \in A^+$ es:
$$a^+ = \langle \text{Pre}(a),\ \text{Add}(a),\ \emptyset \rangle$$
Las precondiciones y las listas add quedan intactas. Solo cambia la lista delete: pasa de $\text{Del}(a)$ a $\emptyset$.
La transición relajada se simplifica:
$$s’_{\text{relajado}} = (s - \emptyset) \cup \text{Add}(a) = s \cup \text{Add}(a)$$
Todo lo demás permanece igual — $P$, $s_0$, $G$, las precondiciones y las listas add.
Resumen lado a lado
| Problema original $\Pi$ | Problema relajado $\Pi^+$ | |
|---|---|---|
| Proposiciones $P$ | $P$ | $P$ (igual) |
| Acción $a$ | $\langle \text{Pre},\ \text{Add},\ \text{Del} \rangle$ | $\langle \text{Pre},\ \text{Add},\ \emptyset \rangle$ |
| Transición | $s’ = (s - \text{Del}) \cup \text{Add}$ | $s’ = s \cup \text{Add}$ |
| Estado inicial | $s_0$ | $s_0$ (igual) |
| Meta | $G \subseteq s$ | $G \subseteq s$ (igual) |
Consecuencia fundamental: crecimiento monótono
Al eliminar las listas delete, el estado solo puede crecer. Cada acción agrega proposiciones y nunca quita ninguna:
$$s \subseteq s’ = s \cup \text{Add}(a)$$
Una vez que una proposición se vuelve verdadera, nunca vuelve a ser falsa. Las proposiciones se acumulan monótonamente:
$$s_0 \subseteq s_1 \subseteq s_2 \subseteq \cdots \subseteq s_k$$
Esto hace que el problema relajado sea mucho más fácil: nunca necesitas “deshacer” algo que hiciste, porque nada se deshace. No hay que reorganizar bloques intermedios ni planificar el orden con cuidado.
Analogía: imagina que estás armando un rompecabezas. En el problema real, cada vez que colocas una pieza, otra pieza se cae (la lista delete). Tienes que planificar con cuidado el orden. En el problema relajado, las piezas nunca se caen — solo acumulas progreso. Obviamente llegas más rápido (o igual de rápido) a la solución.
Llamamos $h^+(s)$ al costo del plan óptimo en $\Pi^+$ desde el estado $s$ hasta la meta. Nuestra propuesta es usar $h^+(s)$ como heurística para guiar la búsqueda en el problema original $\Pi$.
5. Ejemplo paso a paso: normal vs relajado en Blocks World
Veamos la diferencia concretamente. Estado inicial: A, B, C en la mesa. Meta: A sobre B, B sobre C ($\text{On}(A,B)$ y $\text{On}(B,C)$).
Plan normal (con listas delete)
Paso 1 — MoverDesdeMesa(B, C):
Antes: { On(A,M), On(B,M), On(C,M), Clear(A), Clear(B), Clear(C) } 6 proposiciones
Delete: { On(B,M), Clear(C) } ← B ya no está en la mesa, C ya no está libre
Add: { On(B,C) } ← B ahora está sobre C
Después: { On(A,M), On(C,M), Clear(A), Clear(B), On(B,C) } 5 proposiciones
↑ (se perdieron 2, se ganó 1)
On(B,M) desapareció Clear(C) desapareció
Paso 2 — MoverDesdeMesa(A, B):
Antes: { On(A,M), On(C,M), Clear(A), Clear(B), On(B,C) } 5 proposiciones
Verificar precondiciones:
On(A,M) ∈ s? ✓ Clear(A) ∈ s? ✓ Clear(B) ∈ s? ✓ → aplicable
Delete: { On(A,M), Clear(B) } ← A ya no en mesa, B ya no libre
Add: { On(A,B) } ← A ahora sobre B
Después: { On(C,M), Clear(A), On(B,C), On(A,B) } 4 proposiciones
Meta: ${\text{On}(A,B), \text{On}(B,C)} \subseteq s$? Sí. Plan encontrado en 2 pasos.
El estado final tiene solo 4 proposiciones — se perdieron 2 por el camino.
Plan relajado (sin listas delete)
Mismo estado inicial, mismas acciones, pero ignoramos todas las listas delete.
Paso 1 — MoverDesdeMesa(B, C):
Antes: { On(A,M), On(B,M), On(C,M), Clear(A), Clear(B), Clear(C) } 6 proposiciones
Delete: (IGNORADO — no se elimina nada)
Add: { On(B,C) }
Después: { On(A,M), On(B,M), On(C,M), Clear(A), Clear(B), Clear(C), On(B,C) } 7 proposiciones
↑ ↑
On(B,M) SOBREVIVE Clear(C) SOBREVIVE
¡B está en la mesa y sobre C al mismo tiempo! ¡C está libre y tiene a B encima! Esto es físicamente imposible, pero en el mundo relajado no importa — las proposiciones se acumulan sin importar la consistencia.
Paso 2 — MoverDesdeMesa(A, B):
Antes: { On(A,M), On(B,M), On(C,M), Clear(A), Clear(B), Clear(C), On(B,C) } 7 proposiciones
Verificar precondiciones:
On(A,M) ∈ s? ✓ Clear(A) ∈ s? ✓ Clear(B) ∈ s? ✓ → aplicable
(¡Clear(B) sigue ahí porque nunca se borró!)
Delete: (IGNORADO)
Add: { On(A,B) }
Después: { On(A,M), On(A,B), On(B,M), On(B,C), On(C,M), Clear(A), Clear(B), Clear(C) } 8 proposiciones
Meta: ${\text{On}(A,B), \text{On}(B,C)} \subseteq s$? Sí. Plan relajado encontrado en 2 pasos.
El estado final tiene 8 proposiciones — ninguna se perdió, solo se acumularon.
Comparación lado a lado
| Normal | Relajado | |
|---|---|---|
| Proposiciones en $s_0$ | 6 | 6 |
| Proposiciones después del paso 1 | 5 | 7 |
| Proposiciones después del paso 2 | 4 | 8 |
| ¿Clear(B) disponible en paso 2? | Sí (sobrevivió) | Sí (nunca se borró) |
| ¿Clear© disponible en paso 2? | No (fue borrada) | Sí (nunca se borró) |
| Pasos del plan | 2 | 2 |
| ¿Estado final es físicamente consistente? | Sí | No (B en dos lugares) |
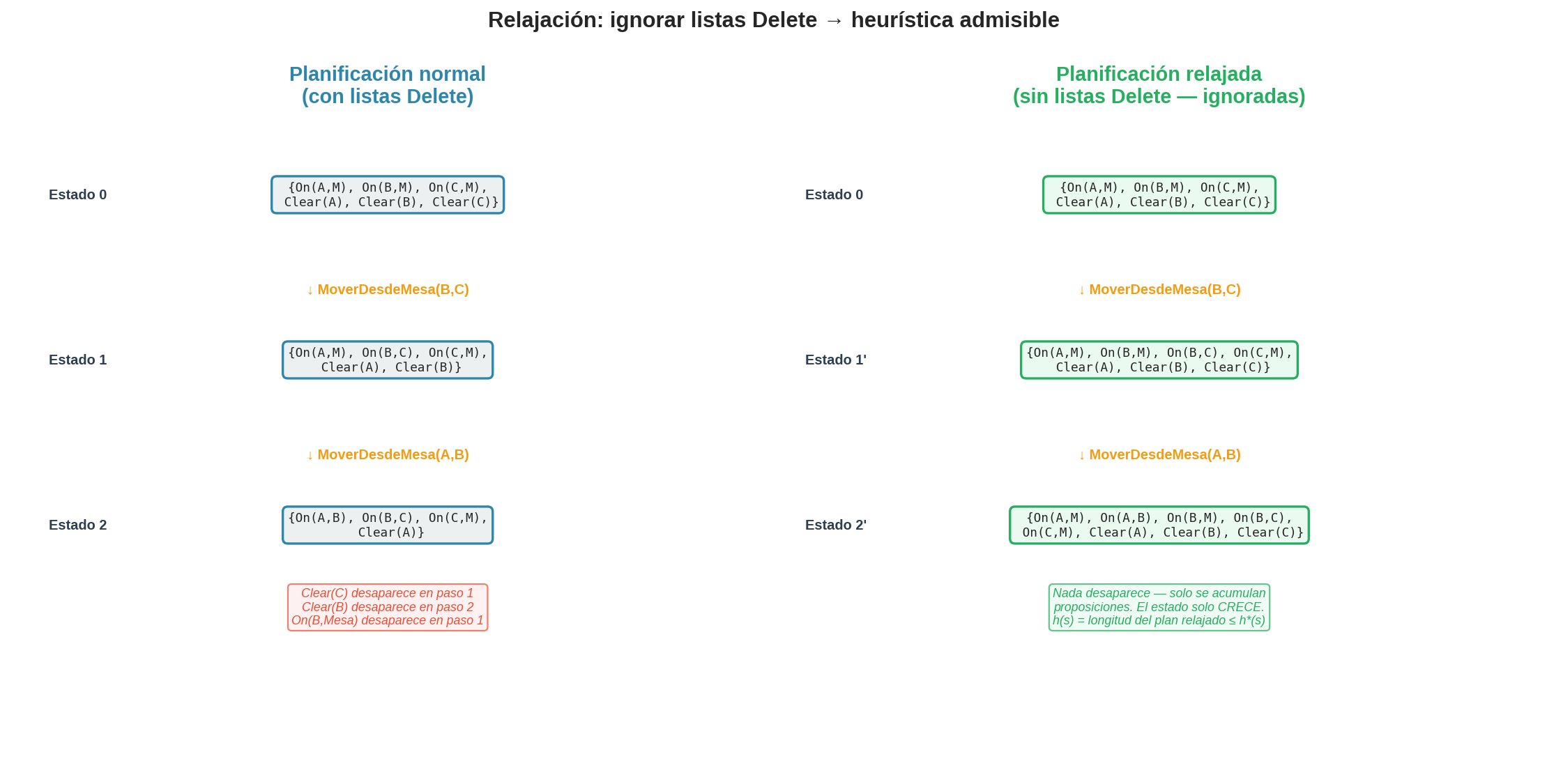
En este ejemplo simple, ambos planes tienen la misma longitud. Pero en problemas más complejos, el plan relajado puede ser más corto porque nunca necesita deshacer pasos intermedios. Eso es exactamente lo que lo hace útil como heurística.
Ejemplo donde la relajación produce un plan más corto
Consideremos una meta diferente con los mismos 3 bloques. Estado inicial: torre C sobre A sobre B ($s = {\text{On}(A,B), \text{On}(B,\text{Mesa}), \text{On}(C,A), \text{Clear}©}$). Meta: ${\text{On}(A,C)}$ — queremos A sobre C.
Plan normal: no podemos mover A directamente — C está encima. Necesitamos:
Paso 1: MoverAMesa(C, A) ← quitar C de encima de A para liberar A
Paso 2: MoverAMesa(A, B) ← bajar A a la mesa para poder reubicarla
Paso 3: MoverDesdeMesa(A, C) ← poner A sobre C
Plan normal: 3 pasos.
Plan relajado: como Clear(A) nunca se borró (no hay delete), podemos “ignorar” que C está encima:
Paso 1: MoverDesdeMesa(A, C) ← On(A,B) no se borró, pero Clear(A)... ¿está en s?
Momento — $\text{Clear}(A)$ no está en el estado inicial (C está encima de A). Así que esta acción no es directamente aplicable. Pero necesitamos menos pasos:
Paso 1: MoverAMesa(C, A) ← quitar C; en relajado, On(C,A) no se borra pero Clear(A) se agrega
Ahora: { On(A,B), On(B,M), On(C,A), On(C,M), Clear(A), Clear(B), Clear(C) }
Paso 2: MoverDesdeMesa(A, C) ← On(A,M)... no está. Pero Mover(A,B,C) sí aplica:
Pre: On(A,B)✓ Clear(A)✓ Clear(C)✓ → aplicable
Add: On(A,C) → ¡META!
Plan relajado: 2 pasos (vs 3 del normal). La relajación subestima — exactamente lo que queremos.
$$h^+(s) = 2 \leq 3 = h^∗(s)$$
6. ¿Por qué la relajación siempre subestima? (admisibilidad)
Necesitamos convencernos de que $h^+(s) \leq h^∗(s)$ para cualquier estado, no solo para nuestro ejemplo.
El argumento es directo:
-
Cualquier plan válido para $\Pi$ también es válido para $\Pi^+$. Si una secuencia de acciones $a_1, a_2, \ldots, a_k$ resuelve el problema original, también resuelve el relajado. ¿Por qué? Porque en cada paso, las precondiciones se verifican igual (las precondiciones no cambian). Y en el problema relajado, el estado tiene más proposiciones (nunca se borra nada), así que si una precondición se cumplía en el estado normal, también se cumple en el estado relajado.
-
Pero $\Pi^+$ puede tener planes más cortos que $\Pi$ no tiene. Al no borrar proposiciones, pueden existir atajos que el problema original no permite (como en el ejemplo anterior).
-
Por lo tanto: el plan óptimo de $\Pi^+$ es $\leq$ que el plan óptimo de $\Pi$.
$$h^+(s) = \text{costo óptimo en } \Pi^+ \leq \text{costo óptimo en } \Pi = h^∗(s)$$
Esto es exactamente la definición de heurística admisible del módulo 14. Podemos usar $h^+$ con A* y tenemos garantía de encontrar el plan óptimo.
7. Pseudocódigo: calcular $h^+(s)$
¿Cómo calculamos la heurística relajada en la práctica? Resolvemos el problema relajado desde el estado $s$ hasta la meta, y contamos los pasos. Podemos usar el mismo FORWARD-PLANNING de la sección anterior, pero con acciones modificadas:
# ── HEURÍSTICA RELAJADA ────────────────────────────────────────────────────
# Calcula h+(s): el número de pasos del plan óptimo en el problema relajado.
#
# Entrada:
# s — estado actual (conjunto de proposiciones)
# meta — proposiciones que deben ser verdaderas
# acciones — lista de acciones STRIPS originales
#
# Idea:
# Construimos versiones relajadas de las acciones (sin lista delete)
# y resolvemos con BFS. El número de pasos del plan es h+(s).
function H_RELAJADA(s, meta, acciones):
# ── Paso 1: construir acciones relajadas ──────────────────────────
# Copiamos cada acción pero reemplazamos su lista delete por ∅.
# Las precondiciones y la lista add quedan intactas.
acciones_relajadas ← []
for each a in acciones:
a_relajada ← Action(
name = a.name,
pre = a.precondiciones, # sin cambio
add = a.add, # sin cambio
delete = ∅ # ← esta es la relajación
)
acciones_relajadas.append(a_relajada)
# ── Paso 2: resolver el problema relajado con BFS ─────────────────
# Usamos FORWARD-PLANNING con las acciones relajadas.
# Como el espacio relajado es más pequeño (los estados solo crecen,
# así que hay menos estados distintos), esto es mucho más rápido.
plan_relajado ← FORWARD-PLANNING-BFS(s, meta, acciones_relajadas)
# ── Paso 3: la longitud del plan es la heurística ─────────────────
if plan_relajado ≠ FAILURE:
return length(plan_relajado) # h+(s)
else:
return ∞ # la meta es inalcanzable (incluso relajada)
¿Por qué BFS y no otro algoritmo?
Usamos BFS porque queremos el plan relajado más corto (óptimo en número de pasos). Si usáramos DFS, podríamos obtener un plan relajado más largo, y la heurística seguiría siendo admisible pero sería menos informativa (subestimaría más de lo necesario).
¿No es costoso resolver un problema entero por cada estado?
Sí, calcular $h^+(s)$ resuelve un subproblema en cada nodo de la búsqueda. Pero el problema relajado es mucho más fácil que el original:
- Los estados solo crecen → hay muchos menos estados distintos alcanzables.
- En la práctica, el problema relajado se resuelve en tiempo polinomial para muchos dominios.
- El costo de calcular $h^+$ se paga con creces: la búsqueda principal explora muchos menos nodos gracias a la guía de la heurística.
Nota: existen algoritmos más eficientes que BFS para resolver el problema relajado (como la propagación de alcanzabilidad que usa el planificador FF). No los cubrimos aquí, pero la idea fundamental es la misma: resolver el problema sin deletes y contar los pasos.
8. Poniendo todo junto: A* + relajación = planificador FF
Ahora conectamos las piezas. En el módulo 14, A* usa $f(n) = g(n) + h(n)$ para ordenar la frontera:
- $g(n)$ = costo acumulado desde el inicio.
- $h(n)$ = estimación del costo restante (heurística admisible).
En planificación con relajación:
- $g(s)$ = número de acciones aplicadas desde $s_0$ hasta $s$.
- $h(s)$ = $h^+(s)$ = longitud del plan relajado desde $s$ hasta la meta.
Forward planning + Cola FIFO = BFS (módulo 13) — explora todo
Forward planning + Cola de prioridad = A* (módulo 14) — explora lo prometedor
con f(s) = g(s) + h_relajada(s) = planificador FF
El pseudocódigo es exactamente FORWARD-PLANNING de la sección anterior, pero cambiando la frontera de una cola FIFO a una cola de prioridad ordenada por $f(s)$:
# ── FORWARD-PLANNING CON A* ───────────────────────────────────────────────
# Idéntico al pseudocódigo de la sección 3, con dos cambios:
# 1. La frontera es una cola de prioridad (min-heap por f(s))
# 2. Al insertar un estado, calculamos f(s) = g(s) + h+(s)
function FORWARD-PLANNING-ASTAR(problema):
# ── Inicialización ────────────────────────────────────────────────
g₀ ← 0 # costo desde s₀ a s₀ = 0
h₀ ← H_RELAJADA(problema.s₀, problema.meta, problema.acciones)
f₀ ← g₀ + h₀
frontera ← new MinHeap() # cola de prioridad (menor f primero)
frontera.push(problema.s₀, priority = f₀)
explorado ← empty set
g_cost ← { problema.s₀: 0 } # mapa: estado → costo acumulado
padre ← { problema.s₀: (null, null) }
# ── Bucle principal ───────────────────────────────────────────────
while frontera is not empty:
s ← frontera.pop_min() # sacar el estado con menor f(s)
# ── Test de meta ──────────────────────────────────────────────
if problema.meta ⊆ s:
return reconstruct_plan(padre, s)
explorado.add(s)
# ── Expandir ──────────────────────────────────────────────────
for each a in APLICABLES(s, problema.acciones):
v ← APLICAR(s, a)
new_g ← g_cost[s] + 1 # cada acción cuesta 1
if v ∉ explorado and (v ∉ g_cost or new_g < g_cost[v]):
g_cost[v] ← new_g
h_v ← H_RELAJADA(v, problema.meta, problema.acciones) # ← aquí se calcula h+
f_v ← new_g + h_v
padre[v] ← (s, a)
frontera.push(v, priority = f_v) # prioridad = g + h+
return FAILURE
El planificador FF (FastForward, Hoffmann & Nebel, 2001) usa exactamente esta estructura. Ganó la competencia internacional de planificación (IPC) y estableció el estándar para la década siguiente.
La intuición es la misma que en A*: en vez de explorar todos los estados ciegamente (BFS), priorizamos los estados que parecen más cercanos a la meta según la heurística relajada. Esto reduce drásticamente los nodos explorados.
9. El arco completo: módulos 13–16
| Algoritmo | Módulo | Tipo de estados | Transiciones | Heurística |
|---|---|---|---|---|
| BFS / DFS | 13 | Nodos explícitos | Aristas del grafo | Ninguna |
| A* | 14 | Nodos explícitos | Aristas del grafo | $h(n)$ — relajación del problema |
| Minimax | 15 | Configuraciones del juego | Turnos + acciones | Ninguna (exacto) |
| Alpha-beta | 15 | Configuraciones del juego | Turnos + acciones | Ninguna (poda, no heurística) |
| Forward BFS | 16 | Proposiciones | Acciones STRIPS | Ninguna |
| Forward + A* | 16 | Proposiciones | Acciones STRIPS | $h^+$ — ignorar deletes |
El patrón es siempre el mismo:
- Definir el espacio de estados y las transiciones.
- Buscar con alguna variante de búsqueda genérica.
- Escalar añadiendo heurísticas que guíen la búsqueda.
Lo que cambia es el lenguaje de representación (nodos vs proposiciones vs configuraciones de juego) y la fuente de las heurísticas (distancia geométrica vs relajación de restricciones vs evaluación de posición). El algoritmo subyacente es el mismo que aprendimos en el módulo 13.
Siguiente: Búsqueda hacia atrás →