17.1 — El dilema: exploración vs. explotación
“You have to learn the rules of the game. And then you have to play better than anyone else.” — Albert Einstein
Tres escenarios, un mismo problema
Imagina las siguientes situaciones:
| Escenario | Opciones | Recompensa | Costo de explorar |
|---|---|---|---|
| Máquinas tragamonedas | 3 máquinas con probabilidades desconocidas | Dinero ganado | Dinero perdido en máquinas malas |
| Prueba A/B | 2 diseños de página web | Tasa de conversión (clics → compras) | Usuarios expuestos al peor diseño |
| Ensayo clínico | 3 tratamientos experimentales | Recuperación del paciente | Pacientes que reciben tratamiento inferior |
Las tres comparten una estructura: en cada ronda, debes elegir entre opciones con efectos desconocidos. Cada elección te da una recompensa (posiblemente aleatoria) y, al mismo tiempo, información sobre esa opción. El dilema: ¿aprovechas lo mejor que has visto hasta ahora (explotación) o pruebas algo menos conocido que podría ser mejor (exploración)?
Del MEU al bandido: ¿qué cambia?
En el Módulo 09 (Teoría de la Decisión) aprendimos el principio de máxima utilidad esperada (MEU):
$$a^{∗} = \arg\max_a \sum_s P(s) \cdot U(o(a, s))$$
Este principio asume que conocemos $P(s)$ — la distribución de los estados. Si supiéramos que la máquina A paga con probabilidad 0.3, la B con 0.5 y la C con 0.7, la respuesta sería trivial: siempre jalar C.
Pero en el problema del bandido multibrazo no conocemos las distribuciones. Debemos aprender $P(s)$ al mismo tiempo que maximizamos la utilidad acumulada. Cada acción produce dos cosas:
- Una recompensa inmediata
- Información sobre la calidad de esa opción
Y aquí está la tensión: una acción que nos da buena información (explorar un brazo poco conocido) puede darnos mala recompensa. Una acción que explota el mejor brazo conocido no nos enseña nada nuevo — y tal vez estamos explotando el brazo equivocado.
Definición formal
El problema del bandido multibrazo (multi-armed bandit, MAB) se define con 5 componentes:
| Componente | Símbolo | Descripción |
|---|---|---|
| Número de brazos | $K$ | Cantidad de opciones disponibles |
| Distribuciones de recompensa | $\nu_1, \ldots, \nu_K$ | Cada brazo $i$ tiene una distribución $\nu_i$ con media $\mu_i$ (desconocida para el agente) |
| Horizonte | $T$ | Número total de rondas |
| Política | $\pi$ | Regla de decisión: dado el historial, ¿qué brazo jalar? |
| Regret acumulado | $R_T$ | Medida de rendimiento (definida abajo) |
En cada ronda $t = 1, 2, \ldots, T$:
- El agente elige un brazo $A_t \in {1, \ldots, K}$ (según su política $\pi$)
- El entorno genera una recompensa $r_t \sim \nu_{A_t}$
- El agente observa solo $r_t$ (no las recompensas de los otros brazos)
- El agente actualiza sus estimaciones y repite
El brazo óptimo es $i^{∗} = \arg\max_i \mu_i$, con media $\mu^{∗} = \mu_{i^{∗}}$.
Distribuciones de recompensa
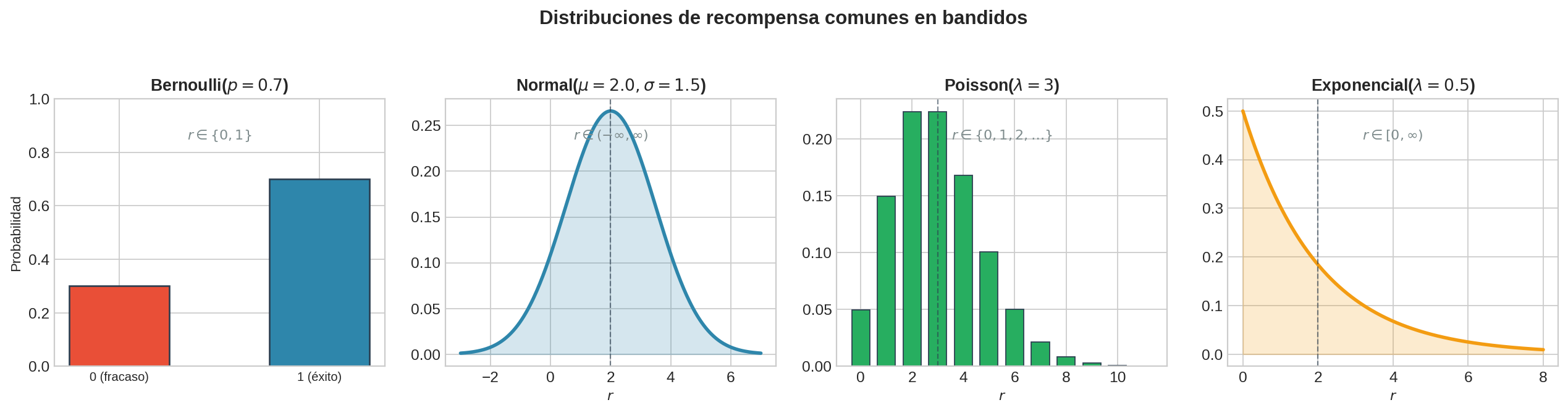
La definición dice que cada brazo tiene una distribución $\nu_i$, pero no dice qué tipo de distribución. Este es un punto clave: la teoría de bandidos funciona con cualquier distribución, y la elección afecta tanto la naturaleza de las recompensas como la dificultad del problema.
Bernoulli: éxito o fracaso
La distribución más simple para bandidos. Cada pull da $r \in {0, 1}$:
$$r \sim \text{Bernoulli}(p) \implies P(r=1) = p, \quad P(r=0) = 1-p$$
La media es $\mu_i = p_i$. Este es el modelo natural para situaciones de sí/no: ¿hizo clic el usuario?, ¿se curó el paciente?, ¿ganó la máquina tragamonedas?
Bernoulli tiene una propiedad especial: la media $p$ determina completamente la distribución. Esto hace que la cota de Lai-Robbins se exprese directamente en términos de las medias (ver más abajo).
Normal: recompensas continuas
Cada pull da un valor real $r \in (-\infty, \infty)$:
$$r \sim \mathcal{N}(\mu, \sigma^2)$$
Aquí la media $\mu_i$ es lo que queremos estimar, pero la varianza $\sigma^2$ controla cuánto ruido hay. Con $\sigma$ grande, las distribuciones de brazos distintos se solapan mucho → se necesitan más muestras para distinguirlos.
Este modelo es natural para recompensas como ingresos, tiempos de respuesta o puntuaciones.
Otras distribuciones
El marco de bandidos funciona con cualquier distribución paramétrica con media finita:
| Distribución | Soporte | Parámetro(s) | Ejemplo de uso |
|---|---|---|---|
| Bernoulli | ${0, 1}$ | $p$ | Clics, conversiones, diagnósticos |
| Normal | $(-\infty, \infty)$ | $\mu, \sigma^2$ | Ingresos, ratings, señales |
| Poisson | ${0, 1, 2, \ldots}$ | $\lambda$ | Conteos de eventos (visitas, fallos) |
| Exponencial | $[0, \infty)$ | $\lambda$ | Tiempos de espera, duración de sesión |
La elección de distribución importa por dos razones:
- Algoritmos paramétricos como Thompson Sampling requieren un modelo conjugado específico para cada familia (veremos Beta-Bernoulli y Normal-Normal en la sección 4)
- La cota inferior de Lai-Robbins depende de la divergencia KL entre distribuciones, que cambia según la familia. Bernoulli y Normal con misma diferencia de medias $\Delta$ tienen KL distintas → la dificultad del problema cambia
En este módulo usamos Bernoulli y Normal como problemas canónicos porque cubren los dos casos fundamentales (discreto binario y continuo) y porque tienen conjugados analíticos. Los algoritmos no-paramétricos como ε-greedy y UCB1 funcionan igual sin importar la distribución.
Dos problemas canónicos
Usaremos dos problemas estándar a lo largo de todo el módulo, jugando el mismo papel que Nim(1,2) en el Módulo 15:
Problema canónico A: Bernoulli

- 3 brazos con recompensas Bernoulli: $r \in {0, 1}$ (éxito o fracaso)
- Probabilidades de éxito: $\mu_A = 0.3$, $\mu_B = 0.5$, $\mu_C = 0.7$
- Brazo óptimo: C ($\mu^{∗} = 0.7$)
- Brechas (gaps): $\Delta_A = 0.7 - 0.3 = 0.4$, $\Delta_B = 0.7 - 0.5 = 0.2$, $\Delta_C = 0$
¿Por qué estos valores? La brecha entre B y C ($\Delta_B = 0.2$) es más difícil de detectar que la de A ($\Delta_A = 0.4$). Un buen algoritmo debe dejar de explorar A rápidamente, pero necesitará más muestras para distinguir B de C.
Problema canónico B: Gaussiano
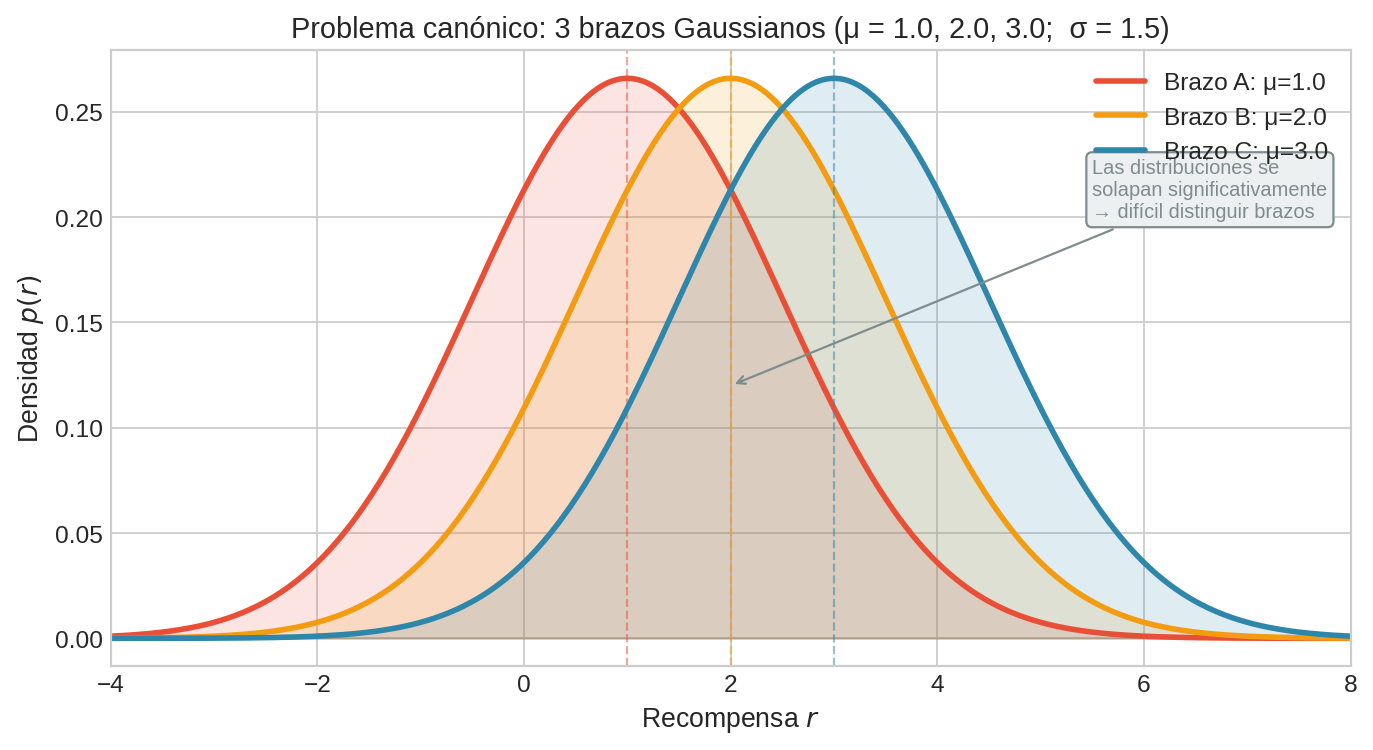
- 3 brazos con recompensas normales: $r \sim \mathcal{N}(\mu_i, \sigma^2)$
- Medias: $\mu_A = 1.0$, $\mu_B = 2.0$, $\mu_C = 3.0$, con $\sigma = 1.5$ compartida
- Brazo óptimo: C ($\mu^{∗} = 3.0$)
- Brechas: $\Delta_A = 2.0$, $\Delta_B = 1.0$
La diferencia clave con el caso Bernoulli: las recompensas son continuas y las distribuciones se solapan significativamente (un pull de A puede dar más que uno de C). Esto hace que se necesiten más muestras para identificar al mejor brazo.
Regret: la medida del arrepentimiento
¿Cómo evaluamos una política de bandidos? No por la recompensa total (que depende de las distribuciones), sino por cuánto peor lo hicimos comparado con el oráculo que siempre jala el brazo óptimo.
Regret por ronda
$$r_t = \mu^{∗} - \mu_{A_t}$$
Es la diferencia entre la media del mejor brazo y la del brazo que efectivamente jalamos. Notar que $r_t \geq 0$ siempre.
Regret acumulado
$$R_T = \sum_{t=1}^{T} (\mu^{∗} - \mu_{A_t}) = T \cdot \mu^{∗} - \sum_{t=1}^{T} \mu_{A_t}$$
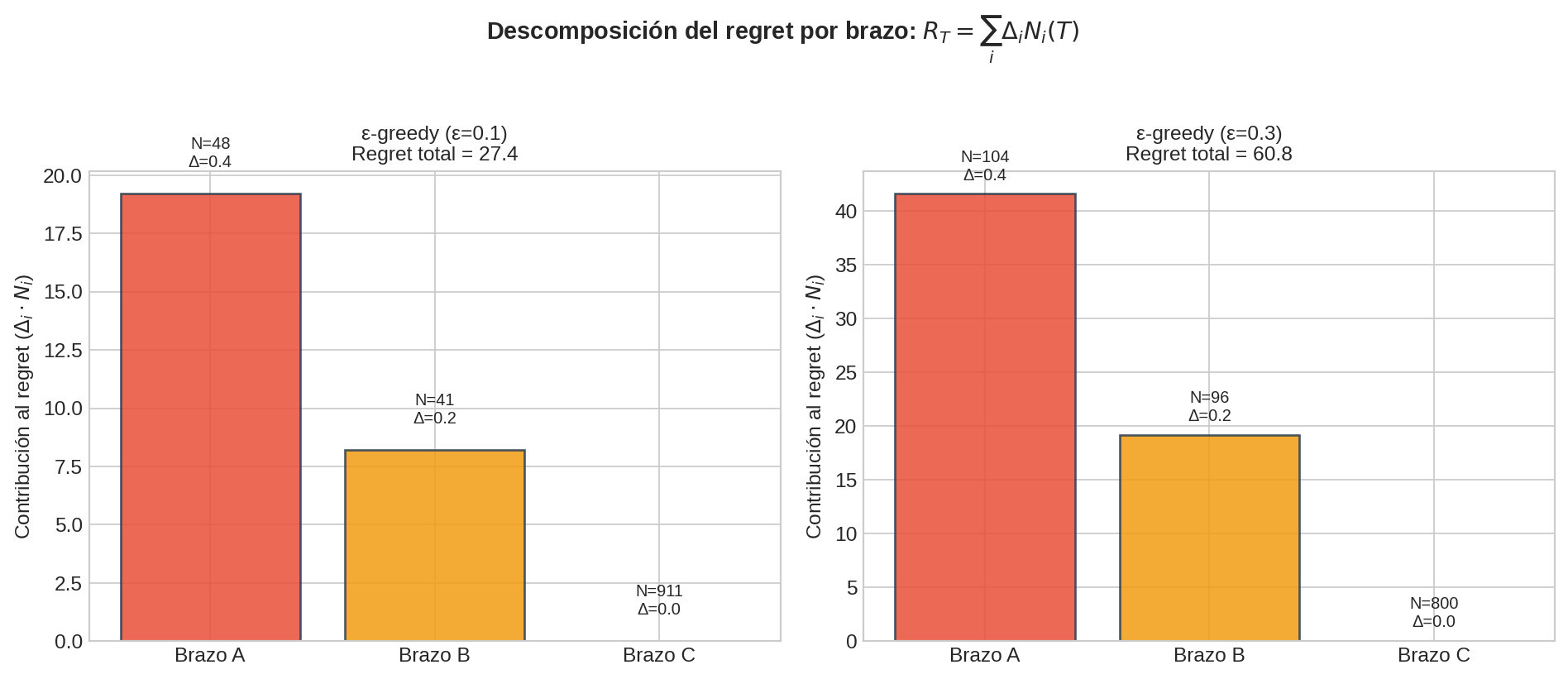
Descomposición por brazo
Esta forma es clave para entender de dónde viene el regret:
$$R_T = \sum_{i=1}^{K} \Delta_i \cdot N_i(T)$$
donde $\Delta_i = \mu^{∗} - \mu_i$ es la brecha del brazo $i$ y $N_i(T)$ es el número de veces que se jaló el brazo $i$.
Interpretación: el regret crece cuando jalamos brazos subóptimos ($\Delta_i > 0$) muchas veces ($N_i$ grande). Un buen algoritmo mantiene $N_i(T)$ pequeño para brazos con $\Delta_i$ grande.
¿Cuánto regret es inevitable?
Estrategias puras: ningún extremo funciona
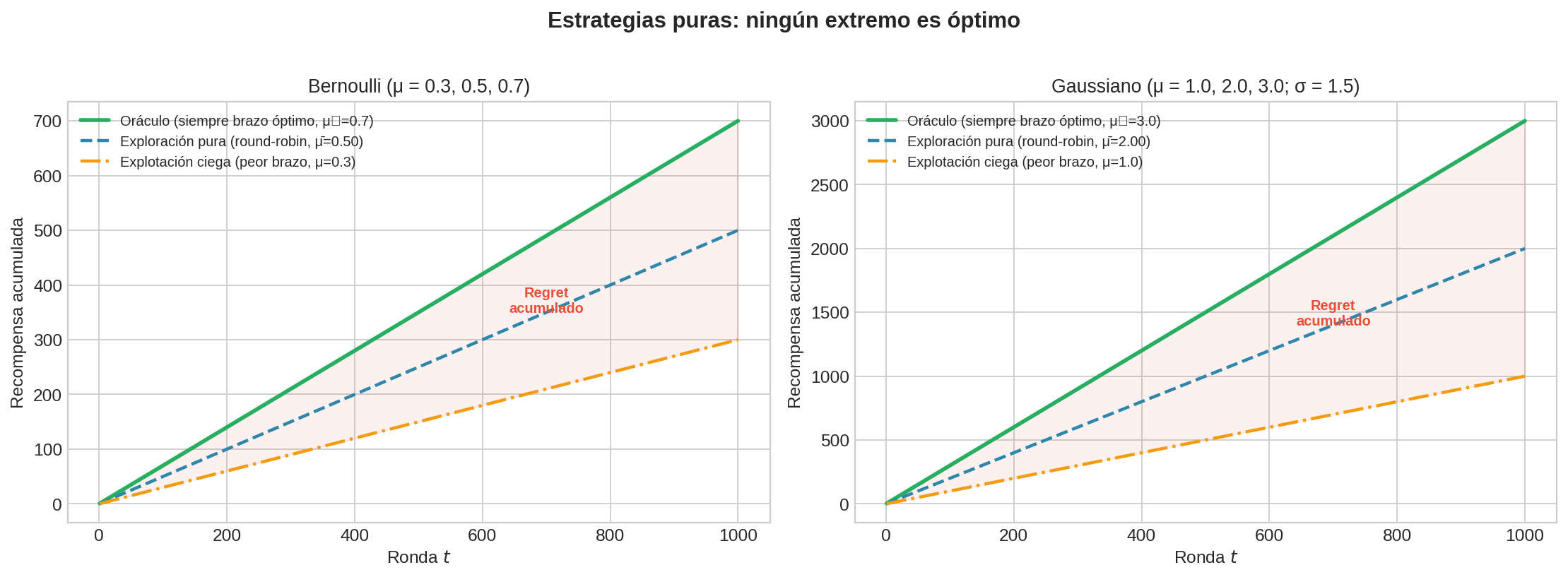
- Explotación pura (siempre jalar un brazo fijo sin explorar): si por suerte eliges C, excelente. Pero si caes en A (el peor), el regret crece linealmente como $\Delta_A \cdot T = 0.4T$.
- Exploración pura (round-robin): recompensa promedio $\bar{\mu} = \frac{1}{K}\sum_i \mu_i$, siempre peor que $\mu^{∗}$. Regret lineal de $(\mu^{∗} - \bar{\mu})T$.
- Oráculo (siempre el mejor brazo): regret = 0. Pero requiere saber las distribuciones de antemano.
Necesitamos algo entre los dos extremos: explorar lo suficiente para identificar al mejor brazo, y explotar lo aprendido.
Divergencia KL: midiendo la distancia entre distribuciones
Antes de enunciar la cota, necesitamos una herramienta del Módulo 06: la divergencia de Kullback-Leibler (KL). Dadas dos distribuciones $P$ y $Q$, la KL mide cuánta información se pierde al usar $Q$ como aproximación de $P$:
$$\text{KL}(P | Q) = \sum_x P(x) \ln \frac{P(x)}{Q(x)}$$
Tres propiedades clave:
- No-negatividad: $\text{KL}(P | Q) \geq 0$, con igualdad solo si $P = Q$
- Asimetría: $\text{KL}(P | Q) \neq \text{KL}(Q | P)$ en general — no es una distancia simétrica
- Distribuciones cercanas → KL pequeña: si $P$ y $Q$ son difíciles de distinguir con muestras, la KL entre ellas es pequeña
Para Bernoulli con parámetros $p$ y $q$, la KL tiene forma cerrada:
$$\text{KL}(p | q) = p \ln \frac{p}{q} + (1 - p) \ln \frac{1 - p}{1 - q}$$
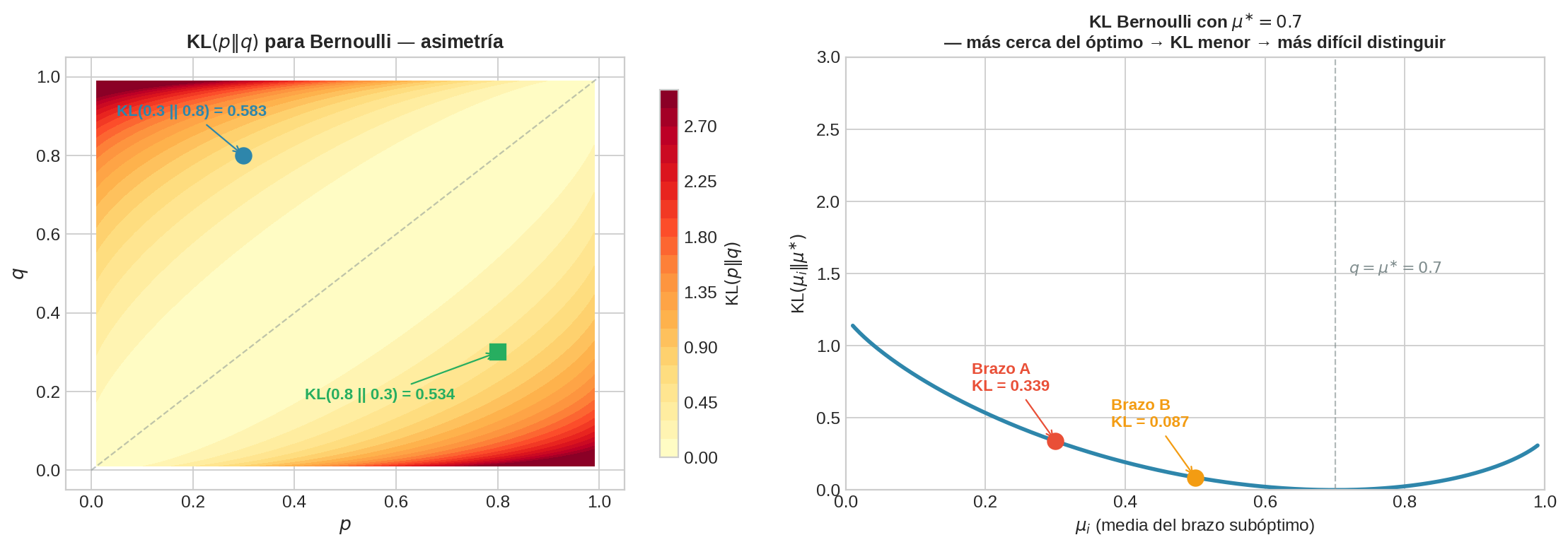
El panel izquierdo muestra la asimetría: $\text{KL}(0.3 | 0.8) = 0.583$ pero $\text{KL}(0.8 | 0.3) = 0.534$ — mismos valores, distinto orden, distinto resultado. El panel derecho fija $\mu^{∗} = 0.7$ y muestra cómo la KL crece conforme $\mu_i$ se aleja del óptimo. El brazo B ($\mu_B = 0.5$, KL $= 0.087$) está mucho más cerca del óptimo que A ($\mu_A = 0.3$, KL $= 0.339$), por lo que es más difícil de distinguir.
La cota inferior de Lai-Robbins
¿Existe un límite fundamental de cuánto regret es inevitable? Sí. Lai y Robbins (1985) demostraron que ningún algoritmo consistente puede tener regret menor que:
$$\liminf_{T \to \infty} \frac{R_T}{\log T} \geq \sum_{i:, \mu_i < \mu^{∗}} \frac{\Delta_i}{\text{KL}(\mu_i | \mu^{∗})}$$
donde $\Delta_i = \mu^{∗} - \mu_i$ es la brecha del brazo $i$ y $\text{KL}(\mu_i | \mu^{∗})$ es la divergencia KL entre la distribución del brazo $i$ y la del brazo óptimo $i^{∗}$.
¿De dónde sale esta cota? La intuición es la siguiente. Para que un algoritmo tenga regret sublineal, necesita eventualmente dejar de jalar cada brazo subóptimo $i$. Pero para saber que $i$ es subóptimo, necesita suficientes muestras de $i$ para distinguir su distribución de la del óptimo. Distinguir dos distribuciones con KL pequeña requiere más muestras (por la teoría de tests de hipótesis). Concretamente, se necesitan al menos $\sim \frac{\log T}{\text{KL}(\mu_i | \mu^{∗})}$ muestras del brazo $i$ para tener confianza suficiente de que es peor. Cada una de esas muestras contribuye $\Delta_i$ de regret. Multiplicando:
$$N_i(T) \gtrsim \frac{\log T}{\text{KL}(\mu_i | \mu^{∗})} \implies \text{regret de brazo } i \gtrsim \frac{\Delta_i \cdot \log T}{\text{KL}(\mu_i | \mu^{∗})}$$
Sumando sobre todos los brazos subóptimos se obtiene la cota.
Interpretación práctica: el mejor regret posible crece logarítmicamente con $T$, es decir $R_T = \Omega(\log T)$. Un algoritmo que logra $R_T = O(\log T)$ es asintóticamente óptimo. Brazos con distribuciones más “parecidas” al óptimo (KL pequeña) contribuyen más al regret inevitable, porque son más difíciles de distinguir.
Para nuestro Problema A con $\mu^{∗} = 0.7$:
| Brazo | $\Delta_i$ | $\text{KL}(\mu_i | \mu^{∗})$ | $\Delta_i / \text{KL}$ | Interpretación |
|---|---|---|---|---|
| A | 0.4 | 0.339 | 1.18 | Fácil de distinguir → pocas muestras necesarias |
| B | 0.2 | 0.087 | 2.29 | Difícil de distinguir → muchas muestras necesarias |
El brazo B domina el regret inevitable: aunque su brecha $\Delta_B$ es menor, la KL es tan pequeña que necesita casi el doble de muestras ponderadas. Esta cota será nuestro benchmark: en las siguientes secciones veremos que ε-greedy no la alcanza, UCB1 se acerca, y Thompson Sampling la iguala asintóticamente.
Lo que viene
Ahora que tenemos el problema y la métrica, estamos listos para el primer algoritmo. La siguiente sección presenta ε-greedy: la estrategia más simple para balancear exploración y explotación. Veremos por qué funciona razonablemente bien — y exactamente dónde falla.