17.2 — ε-Greedy: la estrategia más simple
“The simplest solution is almost always the best.” — Occam
Intuición
La idea es directa: la mayor parte del tiempo, explota (jala el brazo con mejor estimación actual). Pero con probabilidad $\varepsilon$, explora (jala un brazo al azar, sin importar qué tan bueno o malo parezca).
Es como un chef que 90% del tiempo cocina su plato estrella, pero 10% del tiempo prueba una receta aleatoria del libro. Simple, fácil de implementar, y sorprendentemente efectivo como primera aproximación.
Regla de selección
Tenemos $K$ brazos (en nuestro problema canónico, $K = 3$: los brazos A, B, C). En cada ronda, lanzamos una moneda con probabilidad $\varepsilon$:
- Con probabilidad $\varepsilon$: elegir un brazo al azar (explorar)
- Con probabilidad $1 - \varepsilon$: elegir el brazo con mejor media estimada (explotar)
$$A_t = \begin{cases} \text{brazo aleatorio en } 1, \ldots, K & \text{con prob. } \varepsilon \ \arg\max_i \hat{\mu}_i & \text{con prob. } 1 - \varepsilon \end{cases}$$
donde $\hat{\mu}_i$ es la media muestral del brazo $i$: el promedio de todas las recompensas que hemos observado al jalar ese brazo.
Actualización incremental de la media
No necesitamos almacenar todas las recompensas pasadas. Podemos actualizar la media incrementalmente. Si acabamos de jalar el brazo $i$ y observamos una recompensa $r$ (un número: 0 o 1 en Bernoulli, un valor real en Gaussiano), actualizamos:
$$\hat{\mu}_i \leftarrow \hat{\mu}_i + \frac{1}{N_i}\left(r - \hat{\mu}_i\right)$$
Aquí $r$ es la recompensa que acabamos de observar en esta ronda, $\hat{\mu}_i$ es nuestra estimación actual de la media del brazo $i$, y $N_i$ es el número total de veces que hemos jalado ese brazo (incluyendo esta vez).
La fórmula dice: ajustar la estimación en la dirección del error $(r - \hat{\mu}_i)$, ponderado por $\frac{1}{N_i}$. Si $r > \hat{\mu}_i$, la estimación sube; si $r < \hat{\mu}_i$, baja. Conforme $N_i$ crece, los ajustes son más pequeños (la estimación se estabiliza).
Derivación: si la media de $n$ observaciones es $\hat{\mu}^{(n)} = \frac{1}{n}\sum_{j=1}^{n} r_j$, al agregar una nueva observación $r_{n+1}$:
$$\hat{\mu}^{(n+1)} = \frac{1}{n+1}\sum_{j=1}^{n+1} r_j = \frac{1}{n+1}\left(n \cdot \hat{\mu}^{(n)} + r_{n+1}\right) = \hat{\mu}^{(n)} + \frac{1}{n+1}(r_{n+1} - \hat{\mu}^{(n)})$$
Esta es exactamente la misma fórmula del estimador Monte Carlo incremental del Módulo 12. La diferencia: en Monte Carlo estimamos una sola cantidad; aquí mantenemos $K$ estimadores en paralelo, uno por brazo.
Pseudocódigo
función EPSILON_GREEDY(K, T, ε):
# ── Inicialización ────────────────────────────────────
para i = 1, …, K:
Q[i] ← 0 # [P1] media estimada del brazo i (sin datos aún)
N[i] ← 0 # [P2] contador: cuántas veces se ha jalado el brazo i
# ── Bucle principal ───────────────────────────────────
para t = 1, …, T:
# ── Decisión: explorar o explotar ─────────────────
si random() < ε: # [P3] con probabilidad ε: explorar
A ← brazo aleatorio uniforme en {1, …, K}
sino:
A ← argmax_i Q[i] # [P4] con probabilidad 1−ε: explotar
# ── Observar y aprender ───────────────────────────
r ← JALAR(A) # recibir recompensa del brazo A
N[A] ← N[A] + 1
Q[A] ← Q[A] + (r − Q[A]) / N[A] # [P5] actualización incremental de la media
retornar Q, N
Notar lo simple que es: solo 5 líneas esenciales (marcadas [P1]–[P5]). No hay hiperparámetros complicados, no hay distribuciones, no hay cálculos de confianza. Solo un coin flip y una media.
Traza manual: Problema Canónico A (Bernoulli, seed=7, ε=0.1)
¿Por qué $\hat{\mu}$ empieza en 0? Inicializamos $Q[i] = 0$ porque no tenemos ninguna observación. La media de cero muestras no está definida, así que 0 es un valor convencional de “no sé nada”. Podríamos inicializar en 0.5 (máxima entropía para Bernoulli) o en 1.0 (optimista), pero no importa: la primera vez que jalamos un brazo, la fórmula incremental da $Q[i] = 0 + (r - 0)/1 = r$, sobrescribiendo completamente la inicialización. Lo único que afecta $Q[i] = 0$ es el desempate en argmax antes de tener datos: con todos en 0, argmax siempre elige el primer brazo. Pero si la primera ronda es exploración (como aquí), la inicialización ni siquiera se usa.
Veamos exactamente qué hace ε-greedy en las primeras 10 rondas:
| $t$ | $\varepsilon$-flip | $A_t$ | $r_t$ | $\hat{\mu}_A$ | $\hat{\mu}_B$ | $\hat{\mu}_C$ | $N_A$ | $N_B$ | $N_C$ | $R_t$ |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | explore | B | 1 | 0.000 | 1.000 | 0.000 | 0 | 1 | 0 | 0.2 |
| 2 | exploit | B | 1 | 0.000 | 1.000 | 0.000 | 0 | 2 | 0 | 0.4 |
| 3 | exploit | B | 1 | 0.000 | 1.000 | 0.000 | 0 | 3 | 0 | 0.6 |
| 4 | explore | C | 1 | 0.000 | 1.000 | 1.000 | 0 | 3 | 1 | 0.6 |
| 5 | exploit | B | 0 | 0.000 | 0.750 | 1.000 | 0 | 4 | 1 | 0.8 |
| 6 | exploit | C | 1 | 0.000 | 0.750 | 1.000 | 0 | 4 | 2 | 0.8 |
| 7 | explore | C | 1 | 0.000 | 0.750 | 1.000 | 0 | 4 | 3 | 0.8 |
| 8 | exploit | C | 1 | 0.000 | 0.750 | 1.000 | 0 | 4 | 4 | 0.8 |
| 9 | exploit | C | 1 | 0.000 | 0.750 | 1.000 | 0 | 4 | 5 | 0.8 |
| 10 | exploit | C | 1 | 0.000 | 0.750 | 1.000 | 0 | 4 | 6 | 0.8 |
Observaciones:
- En $t=1$: la moneda dice “explorar” y elige B al azar. B obtiene $r=1$ → $\hat{\mu}_B = 1.0$, así que ε-greedy se fija en B
- En $t=2{-}3$: B sigue siendo explotado ($\hat{\mu}_B = 1.0$) y sigue ganando. Aunque B no es el mejor brazo ($\mu_B = 0.5$), tiene suerte inicial
- En $t=4$: la moneda dice “explorar” y elige C al azar. C obtiene $r=1$ → ahora $\hat{\mu}_C = 1.0 = \hat{\mu}_B$, empatados
- En $t=5$: exploit elige B (desempate por índice). B fracasa ($r=0$) → $\hat{\mu}_B = 0.75 < \hat{\mu}_C = 1.0$, así que C toma el control
- En $t=6{-}10$: C domina la explotación. En $t=7$ cae otra exploración que por azar elige C — ¡exploración desperdiciada en el brazo que ya estaba explotando!
- El brazo A ($\mu_A = 0.3$, el peor) nunca ha sido jalado en 10 rondas — en este caso es bueno. Pero si A fuera el mejor, ε-greedy nunca lo descubriría
- Moraleja: la exploración es ciega — no se dirige hacia brazos con alta incertidumbre, sino que elige al azar. Incluso puede “explorar” un brazo que ya conoce bien ($t=7$)
Esquemas de decaimiento de ε
El ε constante tiene un problema fundamental: nunca deja de explorar. Incluso en $t=10{,}000$, sigue jalando brazos malos con probabilidad $\varepsilon$. Existen tres estrategias comunes:
| Variante | Fórmula | Regret | Propiedad |
|---|---|---|---|
| Constante | $\varepsilon_t = \varepsilon$ | $O(\varepsilon T)$ — lineal | Nunca converge; explora para siempre |
| Decaimiento lineal | $\varepsilon_t = \varepsilon_0 \left(1 - \frac{t}{T}\right)$ | Sublineal si se ajusta bien | Requiere conocer $T$ de antemano |
| Decaimiento $1/t$ | $\varepsilon_t = \frac{c}{c + t}$ | $O(\sqrt{T})$ | Automático; no necesita $T$; $c > 0$ controla qué tan rápido decae (e.g. $c = 10$) |
Cota inferior: el regret es al menos lineal
Queremos demostrar que ε-greedy con $\varepsilon$ constante tiene regret al menos $\Omega(\varepsilon T)$. La prueba es corta y no requiere herramientas de concentración.
Paso 1: regret por ronda
El regret esperado en una ronda $t$ es:
$$\mathbb{E}[r_t] = \sum_{i=1}^{K} P(A_t = i) \cdot \Delta_i$$
donde $A_t$ es el brazo elegido en la ronda $t$, $\Delta_i = \mu^{∗} - \mu_i$ es la brecha del brazo $i$, y la suma pondera cada brecha por la probabilidad de elegir ese brazo.
Paso 2: cota inferior de la probabilidad de selección
En ε-greedy, la probabilidad de elegir el brazo $i$ tiene dos componentes:
$$P(A_t = i) = \underset{\text{exploración}}{\frac{\varepsilon}{K}} + \underset{\text{explotación}}{(1 - \varepsilon) \cdot \mathbf{1}[\hat\mu_i = \max_j \hat\mu_j]}$$
El segundo término es $0$ o $(1-\varepsilon)$ dependiendo de si el brazo $i$ tiene la estimación más alta en ese momento. Como este término es siempre $\geq 0$:
$$P(A_t = i) \geq \frac{\varepsilon}{K}$$
La desigualdad es estricta ($>$) para el brazo que la explotación elige, e igualdad ($=$) para los demás.
Paso 3: regret por ronda acotado inferiormente
Sustituyendo esta cota inferior en la expresión del regret por ronda:
$$\mathbb{E}[r_t] = \sum_{i=1}^{K} P(A_t = i) \cdot \Delta_i \geq \sum_{i=1}^{K} \frac{\varepsilon}{K} \cdot \Delta_i = \varepsilon \cdot \frac{1}{K}\sum_{i=1}^{K} \Delta_i = \varepsilon \cdot \bar\Delta$$
La desigualdad $\geq$ viene de reemplazar cada $P(A_t = i)$ por su cota inferior $\varepsilon/K$, descartando la probabilidad adicional que la explotación asigna a algún brazo. Definimos $\bar\Delta = \frac{1}{K}\sum_{i=1}^{K} \Delta_i$, la brecha promedio de todos los brazos (incluyendo el óptimo, que contribuye $\Delta_{i^{∗}} = 0$).
Paso 4: sumar sobre $T$ rondas
Como la cota vale para toda ronda $t$ (la exploración nunca se detiene), sumamos:
$$\mathbb{E}[R_T] = \sum_{t=1}^{T} \mathbb{E}[r_t] \geq \sum_{t=1}^{T} \varepsilon \cdot \bar\Delta = \varepsilon \cdot \bar\Delta \cdot T$$
Como $\varepsilon$ y $\bar\Delta$ son constantes independientes de $T$:
$$\boxed{\mathbb{E}[R_T] = \Omega(\varepsilon T)}$$
El regret crece linealmente con $T$. Esto es inevitable mientras $\varepsilon > 0$ sea constante: el algoritmo nunca deja de explorar, así que en cada ronda paga al menos $\varepsilon \cdot \bar\Delta$ de regret en expectativa. Para nuestro Problema Canónico A con $\varepsilon = 0.1$: $\bar\Delta = (0.4 + 0.2 + 0)/3 = 0.2$, así que $\mathbb{E}[R_T] \geq 0.02 \cdot T$.
Nota sobre cotas e igualdades. Tanto la cota inferior como la superior parten de la misma expresión exacta $\mathbb{E}[R_T]$. La diferencia es la dirección en la que relajamos:
- Cota inferior: reemplazamos términos por algo menor (descartamos la probabilidad de explotación) → obtenemos $\mathbb{E}[R_T] \geq f(T)$.
- Cota superior: reemplazamos términos por algo mayor (acotamos los errores de explotación por arriba) → obtenemos $\mathbb{E}[R_T] \leq g(T)$.
Juntas, las dos cotas encierran el regret verdadero: $f(T) \leq \mathbb{E}[R_T] \leq g(T)$.
Cota superior
Para demostrar la cota superior del regret de ε-greedy, analizamos cómo evoluciona $\mathbb{E}[R_T]$ según el esquema de exploración $\varepsilon_t$ elegido.
Paso 1: la fórmula del regret
El regret esperado acumulado después de $T$ rondas es la suma del regret en cada ronda $t$:
$$\mathbb{E}[R_T] = \sum_{t=1}^{T} \sum_{i=1}^{K} \Delta_i \cdot P(A_t = i)$$
donde:
- $t$: la ronda actual.
- $\Delta_i = \mu^{∗} - \mu_i$: la brecha del brazo $i$.
- $P(A_t = i)$: la probabilidad de jalar el brazo subóptimo $i$ en la ronda $t$.
Paso 2: descomposición de $P(A_t = i)$
En una ronda cualquiera $t$, el algoritmo jala un brazo subóptimo $i$ por una de dos razones:
A. Exploración. El algoritmo decide explorar (con probabilidad $\varepsilon_t$) y le toca el brazo $i$ al azar entre los $K$ brazos:
$$P(\text{jalar } i \mid \text{explorar}) = \frac{\varepsilon_t}{K}$$
B. Error de explotación. El algoritmo decide explotar (con probabilidad $1 - \varepsilon_t$), pero la estimación del brazo $i$ es incorrectamente más alta que la del óptimo ($\hat\mu_i(t) > \hat\mu^{∗}(t)$). Llamemos a esta probabilidad $P(\text{error}_t)$.
Combinando ambas:
$$P(A_t = i) = \frac{\varepsilon_t}{K} + (1 - \varepsilon_t) \cdot P(\text{error}_t)$$
El regret en cada ronda tiene dos fuentes: la exploración forzada y los errores al explotar.
¿Por qué $P(\text{error}_t) \to 0$? Para que la explotación elija erróneamente el brazo $i$ sobre el óptimo, necesitamos $\hat\mu_i(t) > \hat\mu^{∗}(t)$. La media real del óptimo es $\mu^{∗} = \mu_i + \Delta_i$, así que los estimadores deben “cruzarse” — lo cual requiere que al menos uno se desvíe de su media real por más de $\Delta_i/2$. Para acotar esta probabilidad usamos la desigualdad de Chebyshev:
Desigualdad de Chebyshev. Sea $X$ una variable aleatoria con media $\mathbb{E}[X] = \mu$ y varianza $\text{Var}(X) = \sigma^2 < \infty$. Para todo $\delta > 0$:
$$P(\lvert X - \mu \rvert \geq \delta) \leq \frac{\sigma^2}{\delta^2}$$
La intuición: si la varianza es pequeña relativa a $\delta^2$, es improbable que $X$ se aleje más de $\delta$ de su media. No asume nada sobre la forma de la distribución — solo necesita que la varianza exista.
Nuestro estimador $\hat\mu_i$ (la media muestral tras $n_i$ observaciones) tiene varianza $\sigma_i^2/n_i$. Aplicando Chebyshev con $\delta = \Delta_i/2$:
$$P\left(\lvert \hat\mu_i - \mu_i \rvert \geq \frac{\Delta_i}{2}\right) \leq \frac{\sigma_i^2 / n_i}{(\Delta_i/2)^2} = \frac{4\sigma_i^2}{n_i \cdot \Delta_i^2}$$
A medida que $n_i$ crece, esta probabilidad decrece como $1/n_i$. Combinando ambos estimadores (el del brazo $i$ y el del óptimo) por union bound: $P(\text{error}_t) = O(1/n_i)$. Esto es lo que garantiza que los errores de explotación eventualmente desaparezcan — entre más datos, menos errores.
Paso 3: el efecto del esquema de $\varepsilon_t$
La cota superior depende completamente de cómo se comporta $\varepsilon_t$ conforme crece $t$.
Caso 1: $\varepsilon$ constante → regret lineal.
Si $\varepsilon_t = \varepsilon$ para toda ronda (por ejemplo, $\varepsilon = 0.1$):
- El término $\varepsilon/K$ nunca desaparece — en cada ronda pagamos al menos $\varepsilon \cdot \Delta_i / K$ de regret por exploración.
- Sumando sobre todas las rondas:
$$\mathbb{E}[R_T] \geq \sum_{t=1}^{T} \frac{\varepsilon}{K} \sum_{i:\Delta_i > 0} \Delta_i = \varepsilon \cdot \bar\Delta \cdot T$$
- Por Chebyshev (Paso 2), $P(\text{error}_t) = O(1/n_i) \to 0$ conforme acumulamos observaciones. El error de explotación se vuelve despreciable y el término dominante es la exploración:
$$\boxed{\mathbb{E}[R_T] = O(\varepsilon T)}$$
Resultado: regret lineal. El algoritmo nunca deja de cometer errores porque nunca deja de explorar.
Caso 2: $\varepsilon_t$ decreciente → regret logarítmico.
Para lograr una cota superior eficiente, usamos $\varepsilon_t = \frac{c \cdot K}{d^2 \cdot t}$, donde $c > 0$ es una constante y $d$ es la brecha mínima entre brazos. Al sustituir en la suma del regret:
$$\mathbb{E}[R_T] \leq \sum_{t=1}^{T} \left(\frac{c}{d^2 \cdot t} \cdot \Delta_i + \text{error de explotación}\right)$$
Dos observaciones clave:
- La serie armónica. La suma $\sum_{t=1}^{T} \frac{1}{t} \approx \ln(T)$. Este es el origen del crecimiento logarítmico.
- El término de error. Por Chebyshev (Paso 2), $P(\text{error}_t) = O(1/n_i)$. Con exploración suficiente ($c > 5$), cada brazo acumula $n_i = \Omega(\ln t)$ observaciones, así que $P(\text{error}_t) \to 0$ y la suma de errores converge a una constante $O(1)$.
Paso 4: la cota superior final
Sumando los componentes $1/t$ sobre todas las rondas y todos los brazos subóptimos:
$$\boxed{\mathbb{E}[R_T] \leq \left(\sum_{i:\Delta_i > 0} \frac{c}{d^2 \cdot \Delta_i}\right) \ln(T) + O(1)}$$
El primer término crece logarítmicamente: conforme $T \to \infty$, el regret crece solo como $\ln(T)$. El segundo término $O(1)$ captura el costo inicial mientras los estimadores aún son imprecisos.
En palabras simples: con $\varepsilon_t$ decreciente, el algoritmo aprende cuál es el brazo óptimo y dedica la gran mayoría de su tiempo a explotarlo. Los “errores” ocurren con frecuencia cada vez menor — la tasa de errores decrece como $1/t$, y la suma de $1/t$ crece como $\ln(T)$.
Interpretación y $\varepsilon$ óptimo
Juntando la cota inferior $\Omega(\varepsilon T)$ con la cota superior, el panorama es:
| Esquema | Cota superior | Comportamiento |
|---|---|---|
| $\varepsilon$ constante | $O(\varepsilon T)$ | Lineal — nunca deja de explorar |
| $\varepsilon_t = c \cdot K/(d^2 \cdot t)$ | $O(\ln T)$ | Logarítmico — aprende y converge |
Con $\varepsilon$ fijo (por ejemplo, $\varepsilon = 0.1$), el regret es $\Theta(\varepsilon T)$ — fundamentalmente peor que la cota de Lai-Robbins $\Omega(\log T)$.
Con $\varepsilon_t$ decreciente como $1/t$, alcanzamos regret $O(\log T)$, que es óptimo en orden. Pero hay un problema práctico: el esquema $\varepsilon_t = c \cdot K/(d^2 \cdot t)$ requiere conocer $d$ (la brecha mínima entre brazos), que en la práctica no conocemos. Si elegimos $d$ demasiado grande, exploramos de menos; si $d$ es demasiado pequeño, exploramos de más.
La siguiente gráfica muestra el regret empírico de ε-greedy simulado en nuestro Problema Canónico A (Bernoulli, $\mu = 0.3, 0.5, 0.7$) para distintos valores de $\varepsilon$, promediado sobre 200 ejecuciones. No es una curva teórica general — es el comportamiento concreto para este problema, pero la forma lineal del regret es universal para $\varepsilon$ constante.
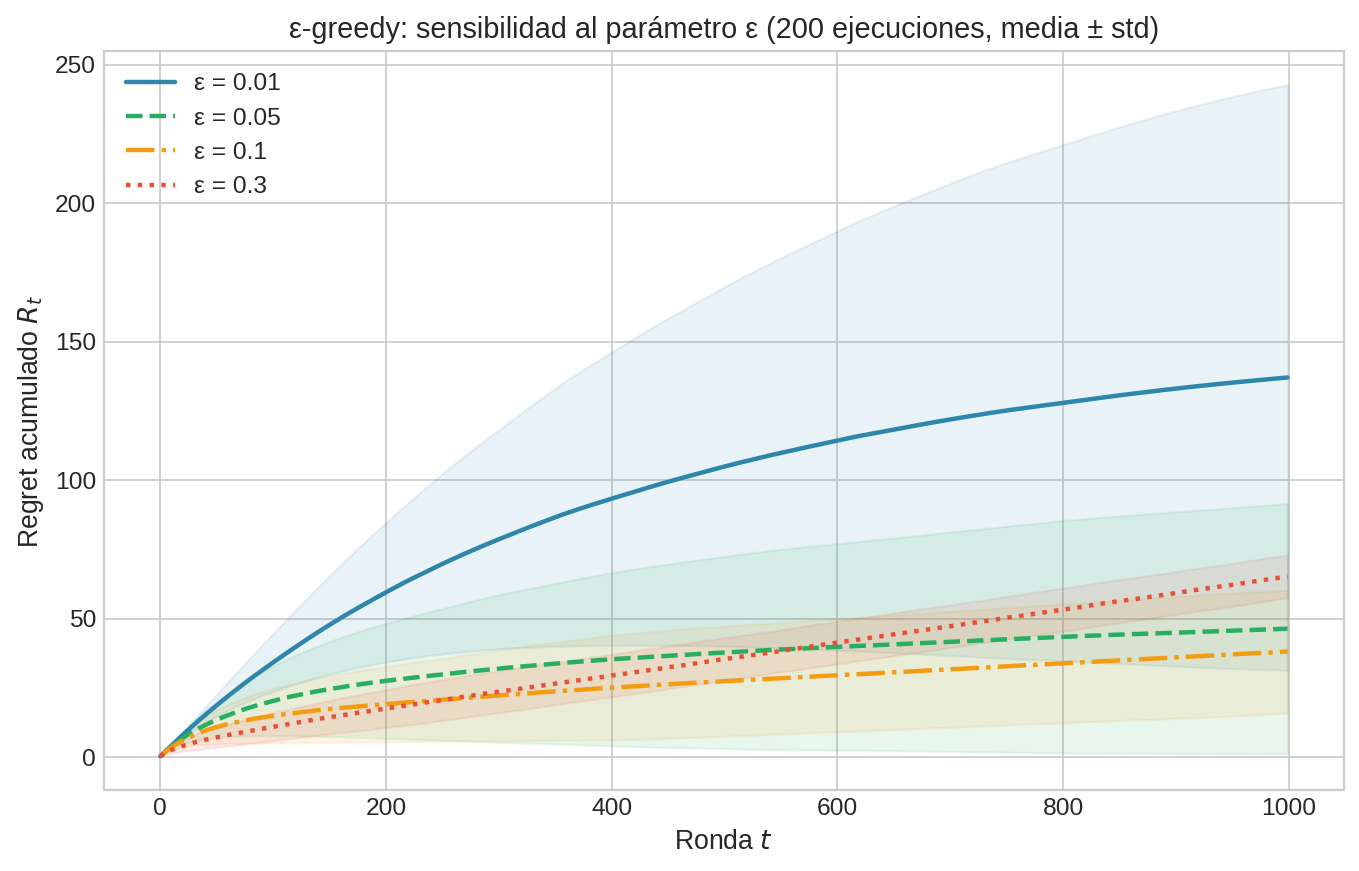
El defecto fundamental: exploración ciega
El problema de ε-greedy no es que explore — es que explora sin criterio. Cuando decide explorar, elige un brazo uniformemente al azar, sin considerar:
- ¿Cuántas veces ya hemos jalado ese brazo? (tal vez ya sabemos que es malo)
- ¿Cuánta incertidumbre tenemos sobre su media? (tal vez necesitamos más datos)
- ¿Cuánto podría mejorar nuestra situación? (tal vez su potencial es bajo)
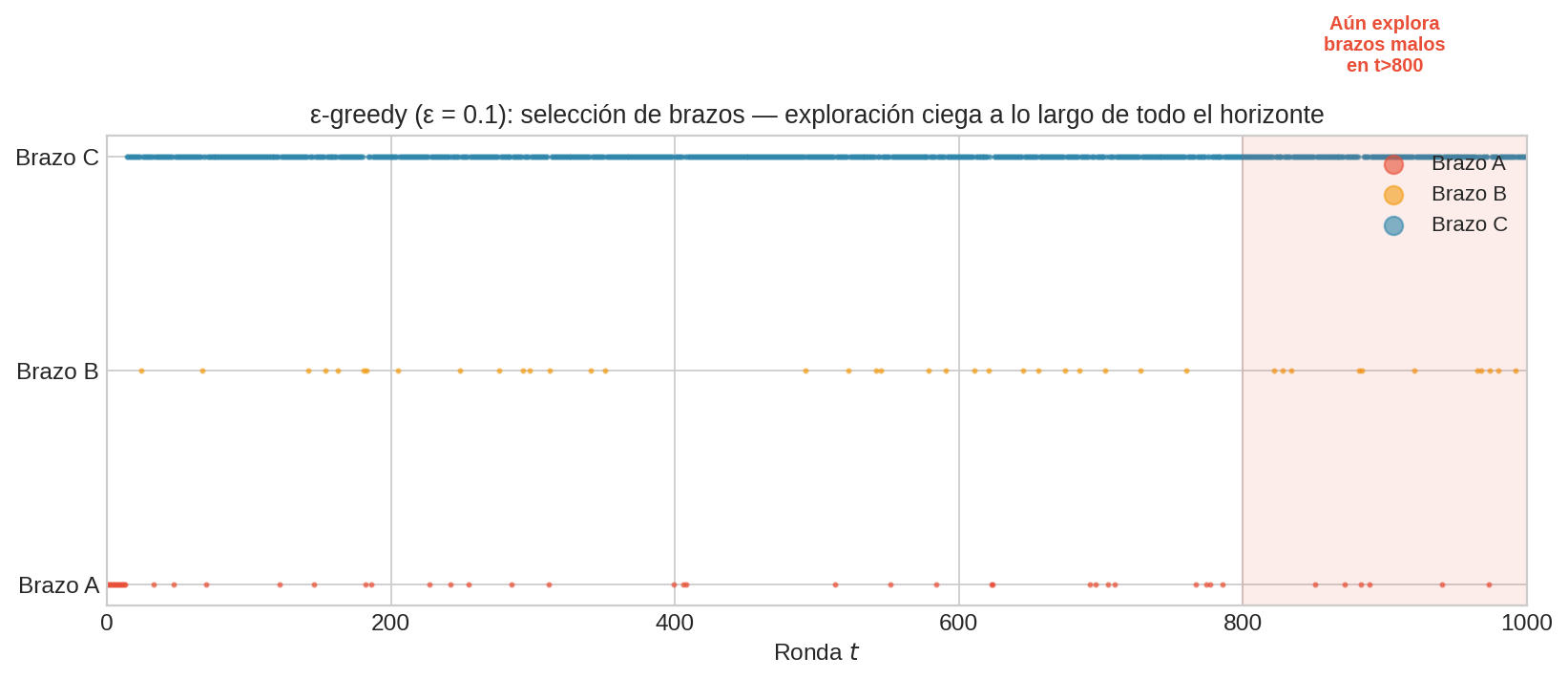
Observa cómo el brazo A (rojo) sigue apareciendo incluso después de $t=800$. Con $\hat{\mu}_A \approx 0.3$ y decenas de observaciones, ya sabemos con alta confianza que A es inferior. Pero ε-greedy sigue desperdiciando pulls en él.
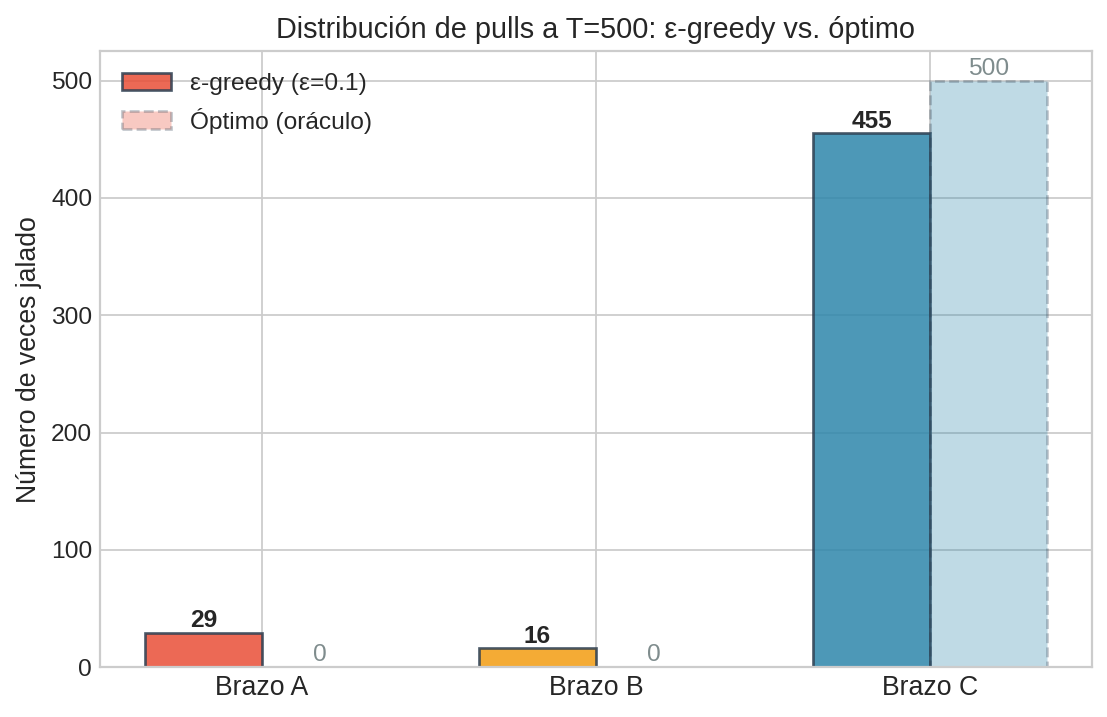
En la sección siguiente veremos cómo UCB1 resuelve este problema: en lugar de explorar a ciegas, explora donde hay más incertidumbre, dirigiendo la exploración hacia donde puede ser útil.
Resumen
| Propiedad | ε-Greedy |
|---|---|
| Idea | Con probabilidad ε, explorar al azar; sino, explotar |
| Parámetros | ε (sensible al ajuste) |
| Regret (ε constante) | $O(\varepsilon T)$ — lineal |
| Regret (ε decreciente) | $O(\ln T)$ con esquema óptimo (requiere conocer $d$) |
| Ventaja | Extremadamente simple de implementar |
| Desventaja | Exploración ciega: no usa la información acumulada |
| Cuándo usar | Prototipo rápido, baseline de comparación |