17.3 — UCB: optimismo ante la incertidumbre
“In the face of ambiguity, refuse the temptation to guess.” — Tim Peters, The Zen of Python
Del problema de ε-greedy a la solución UCB
En la sección anterior vimos que ε-greedy explora a ciegas: cuando decide explorar, elige cualquier brazo con igual probabilidad, incluso aquellos que ya sabemos que son malos. ¿Qué necesitamos en su lugar?
Necesitamos una exploración dirigida: explorar más donde tenemos más incertidumbre. Si hemos jalado el brazo A 100 veces y su media es 0.3, estamos bastante seguros de que A es malo. Pero si hemos jalado el brazo B solo 2 veces y su media es 0.6, esa estimación es ruidosa — B podría ser mucho mejor (o mucho peor) de lo que parece.
La idea de UCB1 (Upper Confidence Bound) es elegantemente simple: actúa como si cada brazo tuviera su valor más optimista plausible, y jala el brazo con el mayor optimismo.
La desigualdad de Hoeffding
Para cuantificar “qué tan lejos puede estar $\hat{\mu}_i$ de $\mu_i$”, necesitamos una herramienta probabilística. La desigualdad de Hoeffding nos dice que para $N$ observaciones independientes en $[0, 1]$:
$$P(\hat\mu - \mu \geq \epsilon) \leq e^{-2N\epsilon^2}$$
Paso 1: invertir la desigualdad. Queremos una cota que falle con probabilidad a lo más $\delta$. Igualamos el lado derecho a $\delta$ y despejamos $\epsilon$:
$$e^{-2N\epsilon^2} = \delta \implies -2N\epsilon^2 = \ln \delta \implies \epsilon = \sqrt{\frac{\ln(1/\delta)}{2N}}$$
Esto nos da un intervalo de confianza: con probabilidad $\geq 1 - \delta$,
$$\mu \leq \hat\mu + \sqrt{\frac{\ln(1/\delta)}{2N}}$$
Paso 2: elegir $\delta$. Necesitamos que $\delta$ dependa del tiempo $t$ porque UCB1 aplica esta cota en cada ronda para cada brazo. Si $\delta$ es constante, los errores se acumulan y la garantía se pierde. Elegimos $\delta = 1/t^2$ porque:
- La serie $\sum_{t=1}^{\infty} 1/t^2 = \pi^2/6 < \infty$ converge, lo que permite aplicar una cota de la unión sobre todas las rondas $t = 1, 2, \ldots$ sin que la probabilidad total de error diverja.
- Cualquier $\delta = 1/t^p$ con $p > 1$ funcionaría (la serie $\sum 1/t^p$ converge para $p > 1$). Se elige $p = 2$ por simplicidad.
Sustituyendo $\delta = 1/t^2$ en la expresión de $\epsilon$:
$$\epsilon = \sqrt{\frac{\ln(t^2)}{2N}} = \sqrt{\frac{2 \ln t}{2N}} = \sqrt{\frac{2 \ln t}{N}}$$
Resultado. Para cada brazo $i$ con $N_i(t)$ observaciones en la ronda $t$, con probabilidad $\geq 1 - 1/t^2$:
$$\mu_i \leq \hat\mu_i + \sqrt{\frac{2 \ln t}{N_i(t)}}$$
El lado derecho es el Upper Confidence Bound (UCB) — una cota superior de la media real con alta confianza. La idea de UCB1 es: si elegimos siempre el brazo con el UCB más alto, estamos eligiendo el brazo que podría ser el mejor dada nuestra incertidumbre.
La fórmula de UCB1
En cada ronda $t$, el algoritmo debe decidir qué brazo jalar. Llamamos $A_t$ al brazo elegido en la ronda $t$ (es decir, $A_t \in {1, \ldots, K}$). UCB1 elige el brazo que maximiza la cota superior de confianza que acabamos de derivar:
$$A_t = \arg\max_i \left[ \hat\mu_i(t) + \sqrt{\frac{2 \ln t}{N_i(t)}} \right]$$
donde $\hat\mu_i(t)$ es la media muestral del brazo $i$ hasta la ronda $t$, y $N_i(t)$ es el número de veces que hemos jalado el brazo $i$. Para cada brazo, calculamos su UCB y elegimos el mayor. Desglosando los dos términos:
- $\hat\mu_i(t)$ es la explotación: nuestra mejor estimación de la media real. Favorece brazos que han dado buenas recompensas.
- $\sqrt{2 \ln t / N_i(t)}$ es la exploración (bonus de confianza): mide nuestra incertidumbre sobre el brazo $i$. Es grande cuando $N_i$ es pequeño (pocas observaciones → mucha incertidumbre) y pequeño cuando $N_i$ es grande (mucha confianza). El $\ln t$ en el numerador crece lentamente con el tiempo, asegurando que ningún brazo sea ignorado para siempre.
¿Pero cómo explora si siempre toma el argmax?
A primera vista parece que argmax solo explotaría — siempre elige “el mejor”. La trampa es que el argmax no es sobre $\hat\mu_i$ sino sobre $\hat\mu_i + \text{bonus}$. El bonus cambia quién es “el mejor”:
Ejemplo concreto. Supongamos que en la ronda $t = 100$ tenemos dos brazos:
| Brazo | $\hat\mu_i$ | $N_i$ | Bonus $\sqrt{2\ln 100 / N_i}$ | UCB |
|---|---|---|---|---|
| A | 0.6 | 80 | 0.24 | 0.84 |
| B | 0.3 | 3 | 1.75 | 2.05 |
El brazo A tiene mejor media estimada (0.6 vs 0.3), pero el brazo B tiene un bonus enorme porque solo lo hemos jalado 3 veces. El argmax elige B — ¡el brazo con peor media! Esto es exploración, pero no por azar (como ε-greedy) sino por una razón concreta: B tiene tanta incertidumbre que podría ser mejor que A.
Después de jalar B, su $N_B$ sube a 4, el bonus baja, y la próxima ronda B necesitará competir de nuevo. Si B resulta ser malo, su $\hat\mu_B$ baja y su UCB deja de ganar. Si resulta ser bueno, su $\hat\mu_B$ sube y lo seguimos jalando — ahora por explotación.
El mecanismo: el $\ln t$ en el numerador crece con cada ronda, inflando gradualmente el bonus de todos los brazos. Pero al jalar un brazo, su $N_i$ sube y su bonus baja. Esto crea una tensión: los brazos ignorados acumulan bonus hasta que eventualmente ganan el argmax. Ningún brazo puede ser ignorado para siempre — su bonus crecerá hasta forzar su selección. UCB1 no separa exploración y explotación como ε-greedy (con un coin flip). En cambio, las unifica en un solo criterio: el brazo con el UCB más alto es el que más vale la pena jalar, ya sea porque tiene buena media o porque no lo conocemos bien.
Interpretación geométrica
Cada brazo tiene un “intervalo de confianza”. UCB1 elige el brazo con el borde superior más alto:
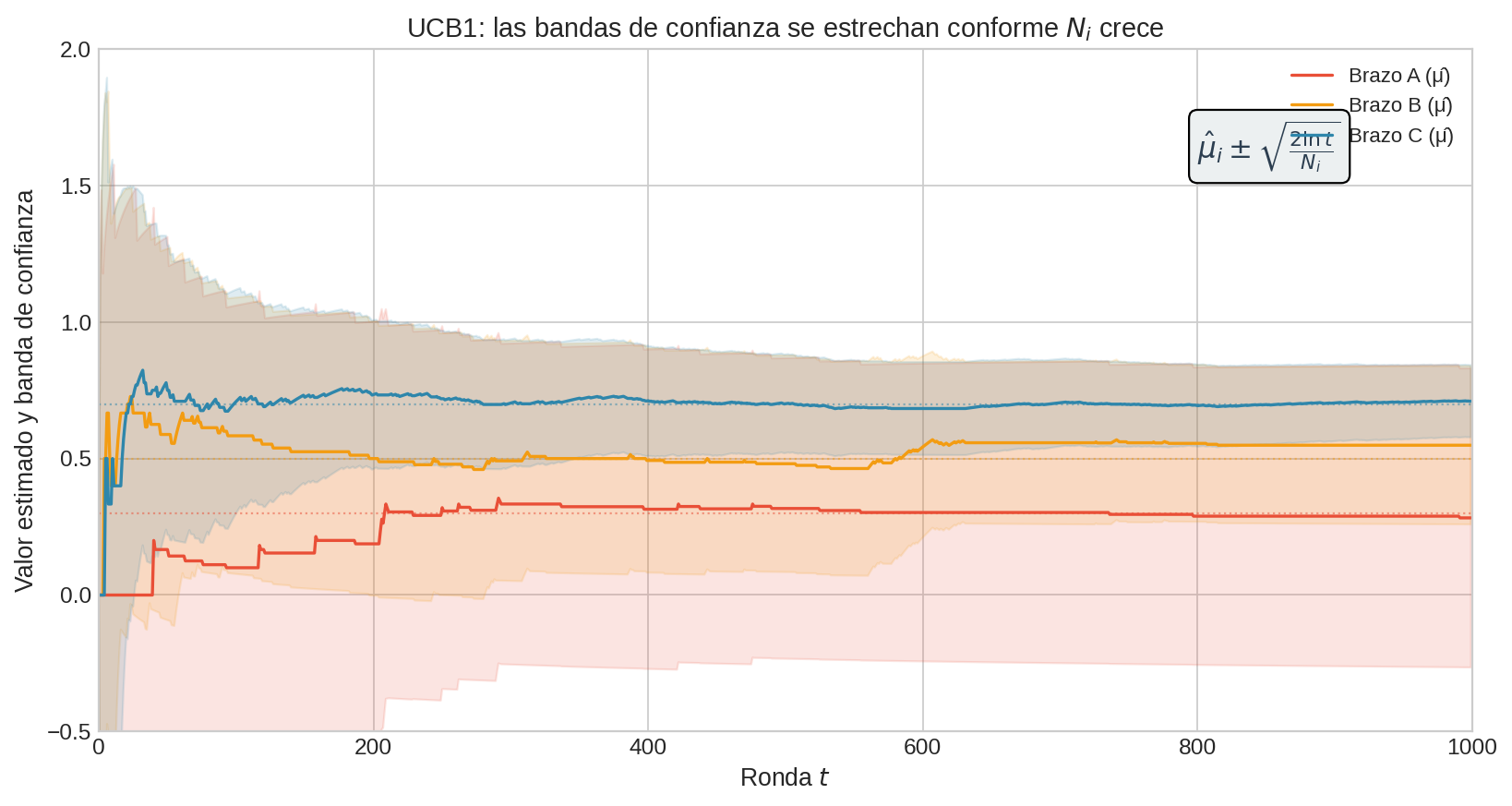
Un brazo con media baja pero mucha incertidumbre (pocas observaciones) puede tener un borde superior más alto que un brazo con media alta pero poca incertidumbre. Esto es exactamente lo que vimos en el ejemplo numérico: el principio de optimismo ante la incertidumbre — “tal vez este brazo es excelente, no hemos mirado lo suficiente para descartarlo”.
Pseudocódigo: tres cambios respecto a ε-greedy
función UCB1(K, T):
# ── Inicialización: jalar cada brazo una vez ──────────
para i = 1, …, K: # [C1] sin parámetro ε
r ← JALAR(i)
Q[i] ← r
N[i] ← 1
# ── Bucle principal ───────────────────────────────────
para t = K+1, …, T:
# ── Selección: optimismo ──────────────────────────
para i = 1, …, K:
UCB[i] ← Q[i] + sqrt(2 · ln(t) / N[i]) # [C2] bonus de confianza
A ← argmax_i UCB[i] # [C3] determinista, no aleatorio
# ── Observar y aprender ───────────────────────────
r ← JALAR(A)
N[A] ← N[A] + 1
Q[A] ← Q[A] + (r − Q[A]) / N[A]
retornar Q, N
Comparado con ε-greedy, solo hay tres cambios:
| Cambio | ε-Greedy | UCB1 |
|---|---|---|
[C1] Parámetro |
Requiere ε (sensible al ajuste) | Ningún parámetro (libre de ajuste) |
[C2] Criterio |
Coin flip aleatorio | Bonus de confianza $\sqrt{2\ln t / N_i}$ |
[C3] Selección |
Aleatorio (si explora) | Determinista: siempre argmax del UCB |
Traza manual: Problema Canónico A (Bernoulli, seed=42)
| $t$ | $\hat{\mu}_A$ | $c_A$ | UCB$_A$ | $\hat{\mu}_B$ | $c_B$ | UCB$_B$ | $\hat{\mu}_C$ | $c_C$ | UCB$_C$ | $A_t$ | $r_t$ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | — | — | — | — | — | — | — | — | — | A | 0 |
| 2 | — | — | — | — | — | — | — | — | — | B | 0 |
| 3 | — | — | — | — | — | — | — | — | — | C | 0 |
| 4 | 0.000 | 1.67 | 1.67 | 0.000 | 1.67 | 1.67 | 0.000 | 1.67 | 1.67 | A | 0 |
| 5 | 0.000 | 1.27 | 1.27 | 0.000 | 1.79 | 1.79 | 0.000 | 1.79 | 1.79 | B | 1 |
| 6 | 0.000 | 1.34 | 1.34 | 0.500 | 1.34 | 1.84 | 0.000 | 1.89 | 1.89 | C | 1 |
| 7 | 0.000 | 1.39 | 1.39 | 0.500 | 1.39 | 1.89 | 0.500 | 1.39 | 1.89 | B | 1 |
| 8 | 0.000 | 1.44 | 1.44 | 0.667 | 1.18 | 1.84 | 0.500 | 1.44 | 1.94 | C | 0 |
| 9 | 0.000 | 1.48 | 1.48 | 0.667 | 1.21 | 1.88 | 0.333 | 1.21 | 1.54 | B | 0 |
| 10 | 0.000 | 1.52 | 1.52 | 0.500 | 1.07 | 1.57 | 0.333 | 1.24 | 1.57 | B | 0 |
Observaciones clave:
- En $t=1{-}3$: cada brazo se jala una vez (inicialización obligatoria). Los tres obtienen $r=0$ por mala suerte
- En $t=4$: los tres empatan en UCB (todos 1.67 — misma $\hat{\mu}$ y mismo $N$). Se jala A para desempatar
- En $t=5$: A fue jalado 2 veces ($c_A = 1.27$, bajo) mientras B y C solo 1 vez ($c = 1.79$, alto). UCB1 explora B porque tiene alta incertidumbre, no al azar
- En $t=6$: B acaba de obtener éxito ($\hat{\mu}_B = 0.5$) pero C nunca ha sido explorado después de la inicialización ($c_C = 1.89$ es el mayor bonus) → UCB1 explora C
- Contraste con ε-greedy: UCB1 nunca depende de un coin flip. Cada decisión está justificada por la incertidumbre
Extensión a recompensas sub-Gaussianas
La derivación usó la desigualdad de Hoeffding para recompensas en $[0, 1]$. Pero la misma fórmula funciona para cualquier distribución $\sigma$-sub-Gaussiana (que incluye a las Gaussianas con varianza conocida):
$$A_t = \arg\max_i \left[ \hat{\mu}_i + \sigma\sqrt{\frac{2 \ln t}{N_i(t)}} \right]$$
Para Bernoulli: $\sigma = 1/2$ (recompensas en [0,1]). Para Gaussianas con varianza $\sigma^2$ conocida: usar esa $\sigma$. Esto significa que UCB1 funciona directamente en nuestro Problema Canónico B (Gaussiano) sin modificación de la lógica — solo cambia la constante.
KL-UCB: usando la estructura de la distribución
UCB1 usa la desigualdad de Hoeffding, que es independiente de la distribución. ¿Podemos hacer mejor si sabemos que las recompensas son Bernoulli?
Sí. KL-UCB reemplaza el bonus de Hoeffding por una cota basada en la divergencia KL (Módulo 06):
$$A_t = \arg\max_i \left\lbrace q \in [0, 1] : \text{KL}(\hat\mu_i, q) \leq \frac{\ln t}{N_i(t)} \right\rbrace$$
donde $\text{KL}(p, q) = p \ln \frac{p}{q} + (1-p) \ln \frac{1-p}{1-q}$ es la divergencia KL entre $\text{Bernoulli}(p)$ y $\text{Bernoulli}(q)$.
En lugar de sumar un bonus aditivo, KL-UCB encuentra el mayor $q$ tal que la distancia KL entre la media empírica y $q$ no exceda un umbral. Esto da cotas más ajustadas que Hoeffding, especialmente cuando $\hat{\mu}_i$ está cerca de 0 o 1.
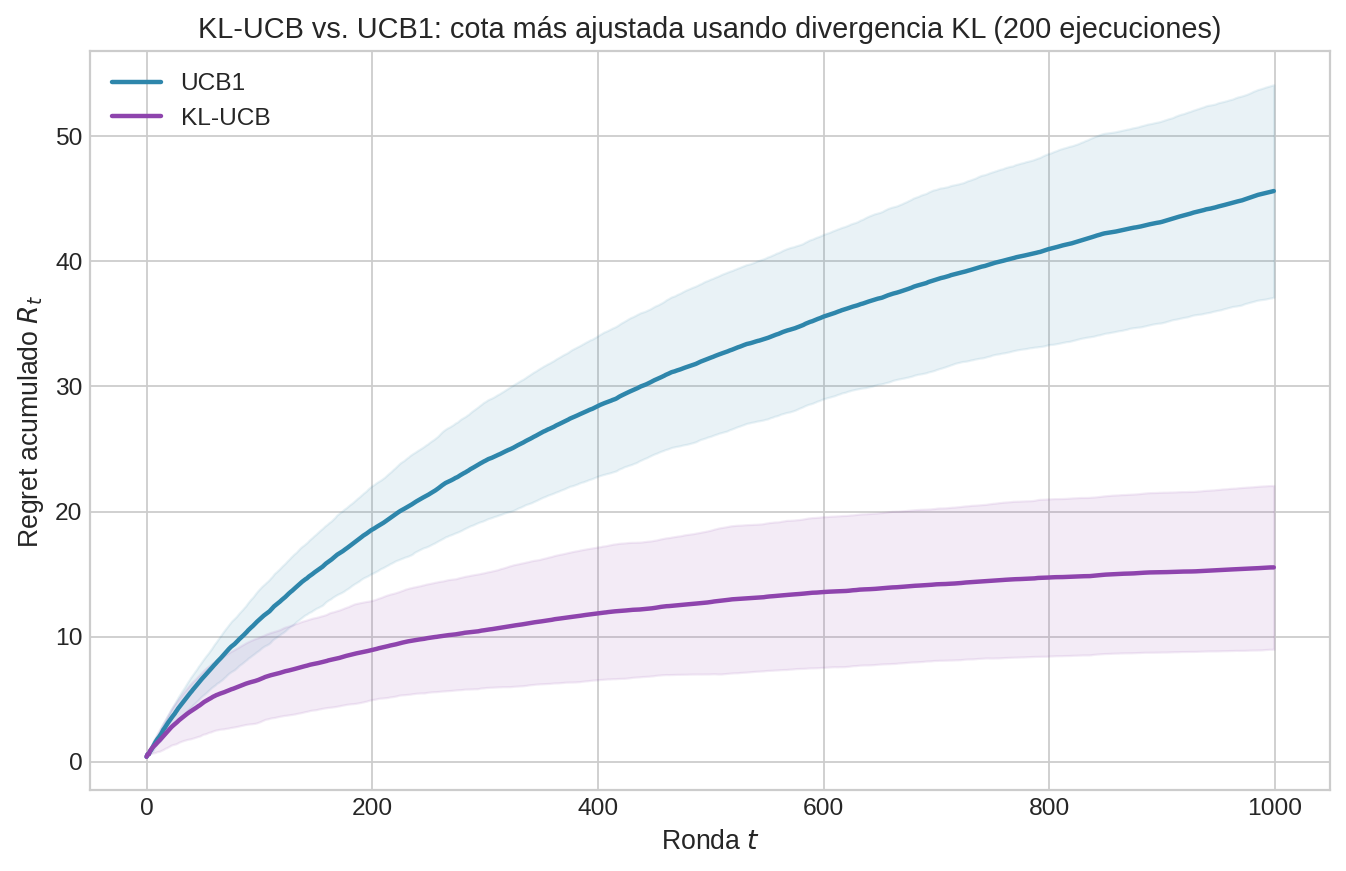
Variantes de UCB
| Variante | Término de exploración | Propiedad clave |
|---|---|---|
| UCB1 | $\sqrt{2 \ln t / N_i}$ | Independiente de la distribución, simple |
| UCB1-Tuned | $\sqrt{\frac{\ln t}{N_i} \min\left(\frac{1}{4}, V_i\right)}$ | Usa la varianza empírica $V_i$ |
| UCB-V | Cota basada en varianza | Más ajustada para distribuciones de baja varianza |
| KL-UCB | Cota de divergencia KL | Asintóticamente óptimo para Bernoulli |
| MOSS | $\sqrt{\frac{4}{N_i} \ln \frac{T}{KN_i}}$ | Minimax-óptimo: $O(\sqrt{KT})$ |
Análisis de regret
Teorema (Auer et al., 2002): El regret de UCB1 satisface:
$$R_T \leq 8 \sum_{i: \mu_i < \mu^{∗}} \frac{\ln T}{\Delta_i} + \left(1 + \frac{\pi^2}{3}\right) \sum_{i=1}^{K} \Delta_i$$
Esto es $O\left(\sum_i \frac{\log T}{\Delta_i}\right) = O\left(\frac{K \log T}{\Delta_{\min}}\right)$ — logarítmico en $T$.
Comparación con ε-greedy:
| ε-Greedy (ε constante) | UCB1 | |
|---|---|---|
| Regret | $O(\varepsilon T)$ — lineal | $O(K \log T / \Delta)$ — logarítmico |
| Exploración | Ciega (aleatoria) | Dirigida (por incertidumbre) |
| Parámetros | ε (requiere ajuste) | Ninguno |
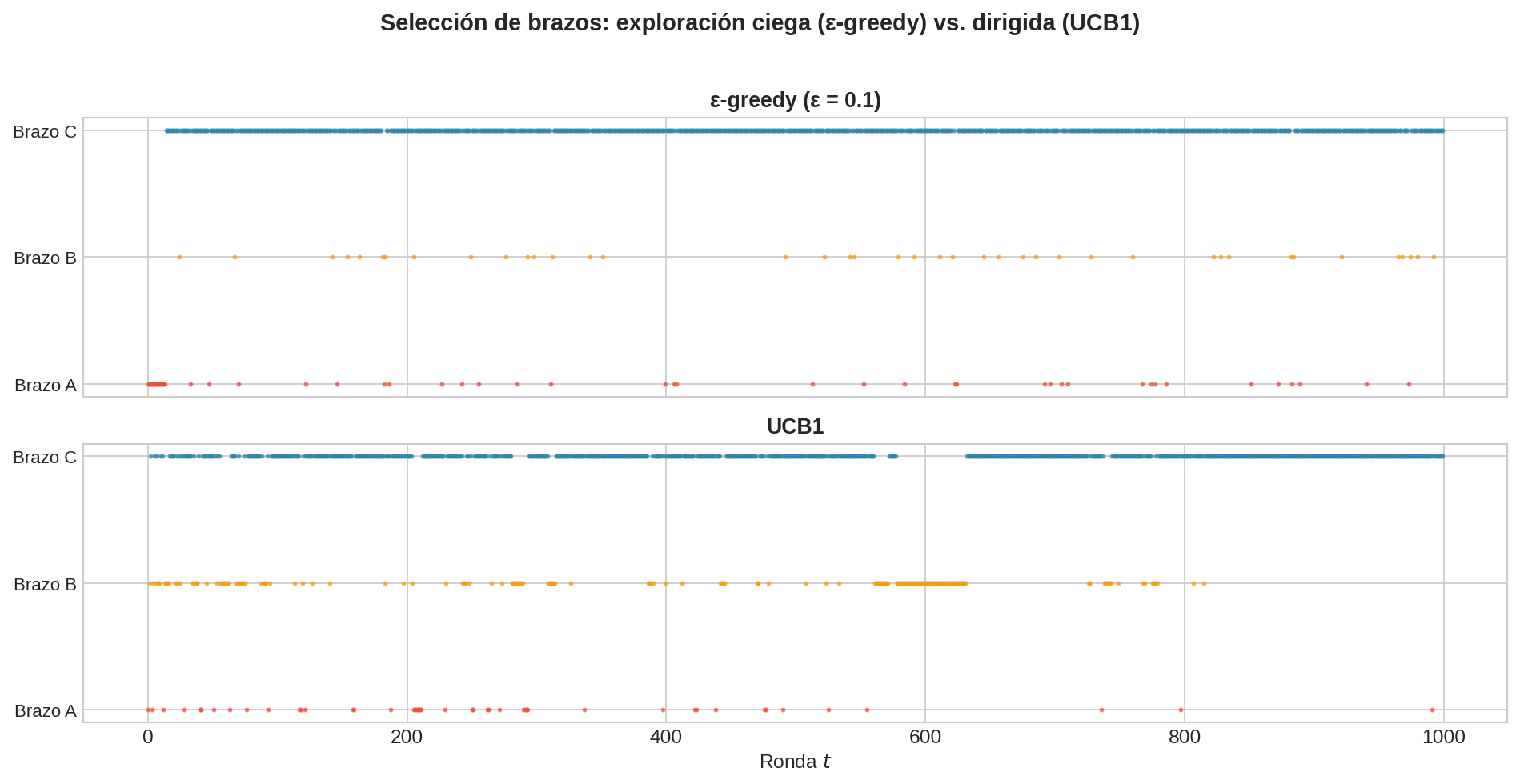
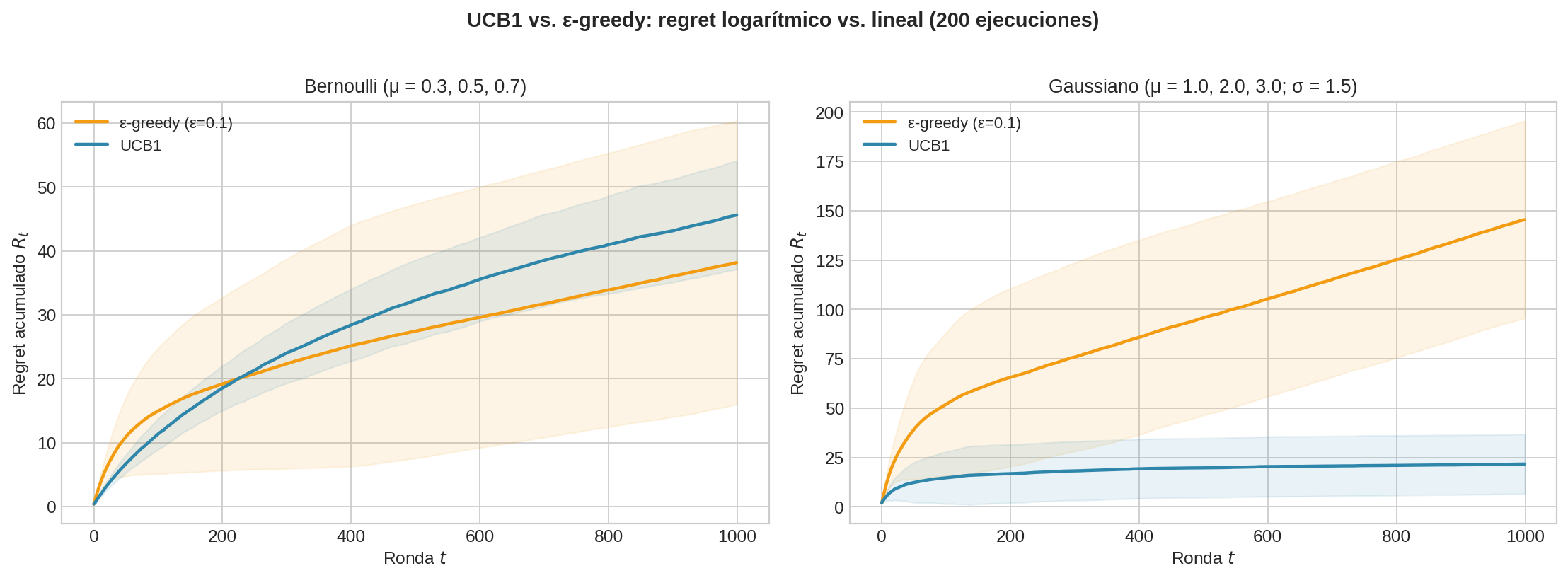
Conexión con MCTS
La misma idea — seleccionar acciones por cota superior de confianza — es la base de UCT (Upper Confidence bounds for Trees), la política de selección en Monte Carlo Tree Search (MCTS). En MCTS, cada nodo del árbol de juego (Módulo 15) se trata como un problema de bandidos: los “brazos” son las acciones posibles, y las “recompensas” provienen de simulaciones aleatorias (Módulo 12). UCB1 guía qué ramas explorar. Desarrollaremos MCTS en un módulo futuro.
Resumen
| Propiedad | UCB1 |
|---|---|
| Idea | Actuar como si cada brazo tuviera su valor optimista (cota superior) |
| Fórmula | $\hat{\mu}_i + \sqrt{2 \ln t / N_i}$ |
| Parámetros | Ninguno (libre de ajuste) |
| Regret | $O(K \log T / \Delta)$ — logarítmico |
| Ventaja | Exploración dirigida, sin hiperparámetros |
| Desventaja | Determinista; no usa información distribucional completa |
| Cuándo usar | Cuando se necesitan garantías de peor caso sin ajuste |
¿Qué falta? UCB1 es determinista y frecuentista: no mantiene una distribución de creencias sobre cada brazo. En la siguiente sección veremos cómo Thompson Sampling toma un enfoque bayesiano: mantener un posterior sobre la media de cada brazo y muestrear de él para decidir.