17.4 — Thompson Sampling: el enfoque bayesiano
“Probability is the very guide of life.” — Cicero
4.1 Intuición: muestrear de lo que crees
Thompson Sampling (1933) — el algoritmo de bandidos más antiguo — tiene una idea extraordinariamente simple:
- Mantén creencias (distribución posterior) sobre la media real de cada brazo
- Muestrea un valor de cada posterior
- Jala el brazo cuyo valor muestreado sea mayor
- Actualiza la creencia del brazo jalado con la recompensa observada
¿Por qué funciona? Si un brazo tiene alta incertidumbre (posterior ancho), sus muestras variarán mucho — a veces será el “ganador” por casualidad, forzando exploración. Conforme acumulamos datos, los posteriores se estrechan: las muestras se concentran cerca del valor real, y el mejor brazo gana casi siempre — explotación automática.
No hay parámetro $\varepsilon$. No hay bonus de confianza. La exploración emerge naturalmente de la incertidumbre bayesiana.
4.2 Probabilidad bayesiana: la idea
Hasta ahora hemos usado probabilidad frecuentista: la media $\mu_i$ de un brazo es un número fijo (desconocido) y la estimamos con la media muestral $\hat\mu_i$. No decimos “la probabilidad de que $\mu_i = 0.7$” — eso no tiene sentido en el enfoque frecuentista, porque $\mu_i$ no es aleatorio.
La probabilidad bayesiana cambia la perspectiva: como nosotros no conocemos $\mu_i$, modelamos nuestra incertidumbre sobre su valor como una distribución de probabilidad. Esta distribución no describe aleatoriedad en el mundo — describe lo que nosotros creemos dado lo que hemos observado.
El marco bayesiano tiene tres ingredientes:
-
Prior (creencia inicial): antes de observar datos, ¿qué creemos sobre $\mu_i$? Si no sabemos nada, decimos “cualquier valor entre 0 y 1 es igualmente plausible” — una distribución uniforme.
-
Likelihood (verosimilitud): dado un valor concreto de $\mu_i$, ¿qué tan probable es observar los datos que vimos? Para un brazo Bernoulli con probabilidad de éxito $\theta$, la probabilidad de observar $r = 1$ es $\theta$ y la de $r = 0$ es $1 - \theta$.
-
Posterior (creencia actualizada): después de observar datos, combinamos prior y likelihood para obtener una nueva distribución sobre $\mu_i$. Esto es el teorema de Bayes:
$$\underset{\text{posterior}}{p(\theta \mid \text{datos})} \propto \underset{\text{likelihood}}{p(\text{datos} \mid \theta)} \cdot \underset{\text{prior}}{p(\theta)}$$
Cada nueva observación actualiza el posterior, que se vuelve el prior para la siguiente observación. Con pocos datos, el posterior es ancho (mucha incertidumbre). Con muchos datos, se estrecha alrededor del valor real.
4.3 La distribución Beta
Para usar el marco bayesiano necesitamos elegir una distribución para representar nuestra creencia sobre $\theta \in [0, 1]$ (la probabilidad de éxito de un brazo Bernoulli). La distribución Beta es la elección natural.
¿Qué es $\theta$?
Cada brazo $i$ tiene una probabilidad de éxito $\theta_i$ que desconocemos (es lo que antes llamábamos $\mu_i$). En el enfoque bayesiano, $\theta_i$ no es un número fijo sino una variable aleatoria que representa nuestra incertidumbre. La distribución Beta describe qué valores de $\theta_i$ consideramos plausibles.
Definición
La distribución $\text{Beta}(\alpha, \beta)$ tiene dos parámetros y soporte en $[0, 1]$:
$$p(\theta \mid \alpha, \beta) = \frac{\theta^{\alpha-1}(1-\theta)^{\beta-1}}{B(\alpha, \beta)}$$
donde $B(\alpha, \beta) = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)}$ es una constante de normalización (para que integre a 1). No necesitas memorizar esta fórmula — lo importante es la interpretación de los parámetros.
Parámetros como conteos
La forma más útil de pensar en $\alpha$ y $\beta$:
- $\alpha = \text{éxitos observados} + 1$
- $\beta = \text{fracasos observados} + 1$
El “+1” viene del prior. Si empezamos con $\alpha = 1, \beta = 1$ (cero éxitos, cero fracasos), obtenemos $\text{Beta}(1, 1)$, que es exactamente la distribución $\text{Uniforme}(0, 1)$ — “cualquier $\theta$ es igualmente plausible”, la máxima ignorancia.
Propiedades
| Propiedad | Fórmula | Interpretación |
|---|---|---|
| Media | $\frac{\alpha}{\alpha + \beta}$ | Fracción de éxitos (suavizada por el prior) |
| Moda | $\frac{\alpha - 1}{\alpha + \beta - 2}$ (si $\alpha, \beta > 1$) | Valor más probable |
| Varianza | $\frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}$ | Decrece con más datos |
Observa que la media $\alpha/(\alpha + \beta)$ converge a la frecuencia de éxitos conforme acumulamos datos (los “+1” del prior se vuelven despreciables).
Cómo cambia la forma
| Parámetros | Forma | Interpretación |
|---|---|---|
| Beta(1, 1) | Plana (uniforme) | “No sé nada” |
| Beta(2, 5) | Sesgada a la izquierda | “Probablemente bajo (~0.3)” |
| Beta(10, 10) | Campana centrada en 0.5 | “Bastante seguro de ~0.5” |
| Beta(30, 70) | Pico estrecho en 0.3 | “Muy seguro de ~0.3” |
Conjugación con Bernoulli
Aquí está la conexión clave. Si nuestro prior sobre $\theta$ es $\text{Beta}(\alpha, \beta)$ y observamos una recompensa Bernoulli $r \in {0, 1}$, el posterior es:
$$\text{Posterior} = \begin{cases} \text{Beta}(\alpha + 1, \beta) & \text{si } r = 1 \text{ (éxito)} \ \text{Beta}(\alpha, \beta + 1) & \text{si } r = 0 \text{ (fracaso)} \end{cases}$$
El posterior es otra Beta — solo sumamos 1 al parámetro correspondiente. Esto se llama conjugación: la familia Beta es el prior conjugado de la likelihood Bernoulli. La actualización es computacionalmente trivial: no hay que calcular integrales ni resolver ecuaciones, solo incrementar un contador.
¿Por qué funciona? Si sustituimos el prior $\text{Beta}(\alpha, \beta)$ y la likelihood Bernoulli en el teorema de Bayes:
$$p(\theta \mid r=1) \propto \theta \cdot \theta^{\alpha-1}(1-\theta)^{\beta-1} = \theta^{\alpha}(1-\theta)^{\beta-1}$$
que tiene la forma de $\text{Beta}(\alpha+1, \beta)$. El mismo argumento con $r=0$ da $\text{Beta}(\alpha, \beta+1)$.
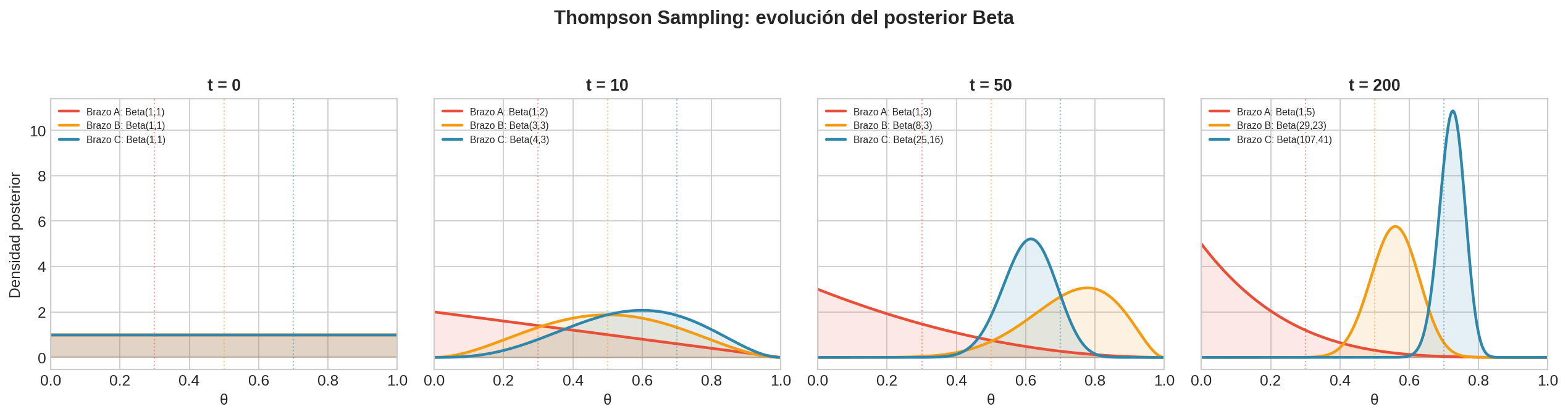
Observa cómo los posteriores pasan de planos (Beta(1,1) en $t=0$) a concentrados (cerca del $\theta$ real en $t=200$). El brazo C (azul, $\theta=0.7$) tiene su posterior centrado alrededor de 0.7 con poca varianza.
4.4 Thompson Sampling para Bernoulli
Pseudocódigo
función THOMPSON_SAMPLING_BERNOULLI(K, T):
# ── Inicialización: prior no informativo ──────────────
para i = 1, …, K:
α[i] ← 1 # [T1] prior Beta(1,1) = Uniforme
β[i] ← 1
# ── Bucle principal ───────────────────────────────────
para t = 1, …, T:
# ── Muestrear de las creencias ────────────────────
para i = 1, …, K:
θ[i] ← muestra de Beta(α[i], β[i]) # [T2] ¡el paso bayesiano!
A ← argmax_i θ[i] # [T3] actuar según la muestra
# ── Observar y actualizar posterior ────────────────
r ← JALAR(A) # r ∈ {0, 1}
si r == 1:
α[A] ← α[A] + 1 # [T4] éxito: incrementar α
sino:
β[A] ← β[A] + 1 # [T5] fracaso: incrementar β
retornar α, β
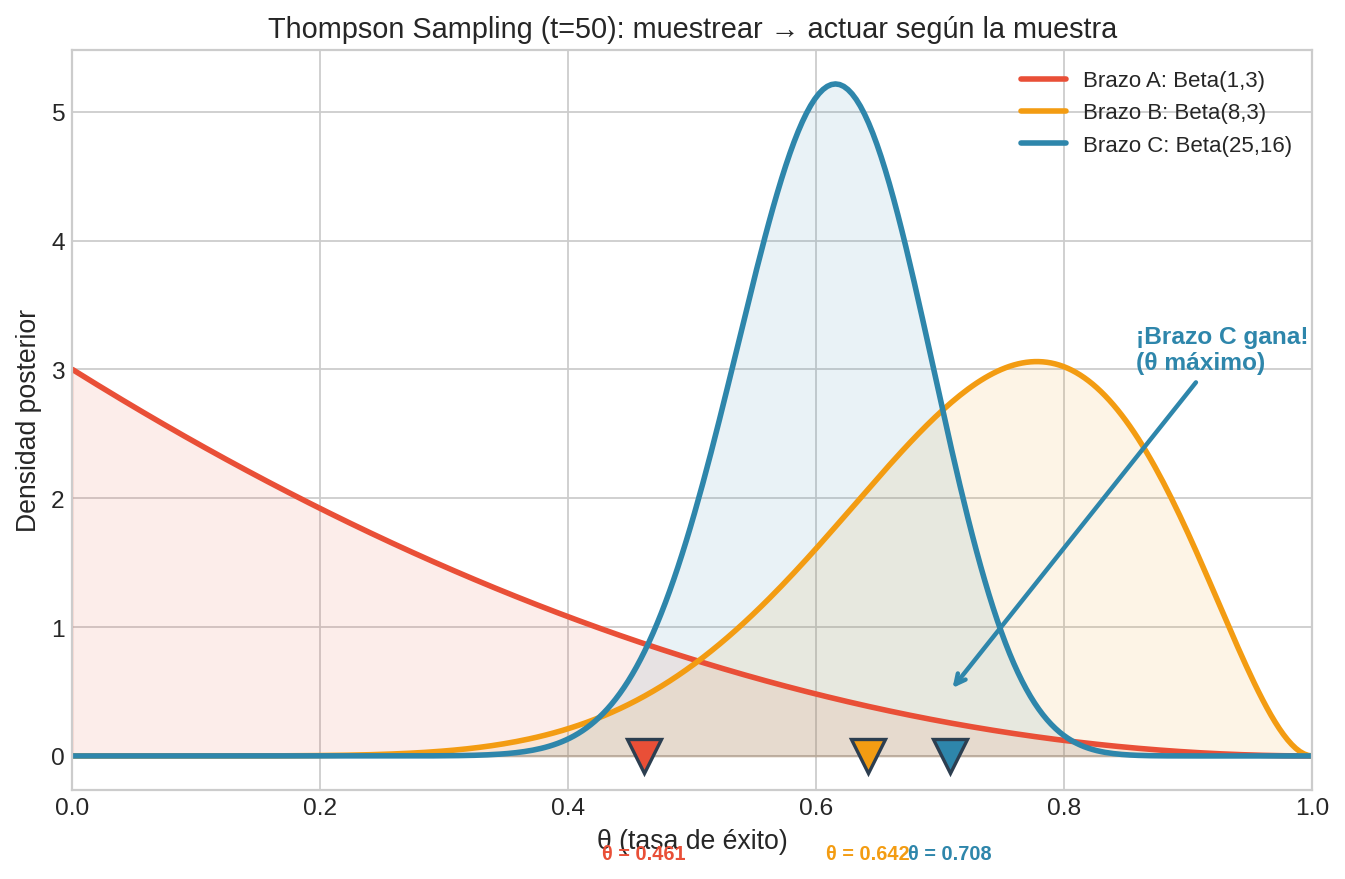
Traza manual: Problema Canónico A (seed=42)
| $t$ | Beta$_A$ | $\theta_A$ | Beta$_B$ | $\theta_B$ | Beta$_C$ | $\theta_C$ | $A_t$ | $r_t$ |
|---|---|---|---|---|---|---|---|---|
| 1 | (1,1) | 0.500 | (1,1) | 0.063 | (1,1) | 0.021 | A | 0 |
| 2 | (1,2) | 0.173 | (1,1) | 0.549 | (1,1) | 0.322 | B | 1 |
| 3 | (1,2) | 0.233 | (2,1) | 0.858 | (1,1) | 0.927 | C | 1 |
| 4 | (1,2) | 0.118 | (2,1) | 0.466 | (2,1) | 0.961 | C | 1 |
| 5 | (1,2) | 0.025 | (2,1) | 0.752 | (3,1) | 0.409 | B | 0 |
| 6 | (1,2) | 0.538 | (2,2) | 0.662 | (3,1) | 0.870 | C | 0 |
| 7 | (1,2) | 0.092 | (2,2) | 0.266 | (3,2) | 0.598 | C | 1 |
| 8 | (1,2) | 0.055 | (2,2) | 0.843 | (4,2) | 0.536 | B | 0 |
Observaciones:
- En $t=1$: todas las distribuciones son Uniforme. Los valores muestreados son aleatorios — A gana con $\theta_A = 0.500$. Esto es exploración pura al inicio
- En $t=2$: A falló ($r=0$), su posterior es ahora Beta(1,2), sesgada abajo. B gana la muestra ($\theta_B = 0.549$) y obtiene $r=1$
- En $t=3{-}4$: C gana las muestras con $\theta_C > 0.9$ y acumula éxitos. Su posterior pasa de Beta(1,1) a Beta(3,1)
- En $t=5$: C tiene Beta(3,1), pero su muestra sale baja ($\theta_C = 0.409$). B gana momentáneamente — Thompson explora porque la incertidumbre del posterior permite muestras bajas
- En $t=6{-}7$: C se recupera y sigue dominando. La explotación emerge sin parámetro
- A solo se jala 1 vez (es el peor brazo), B recibe atención intermitente, C domina
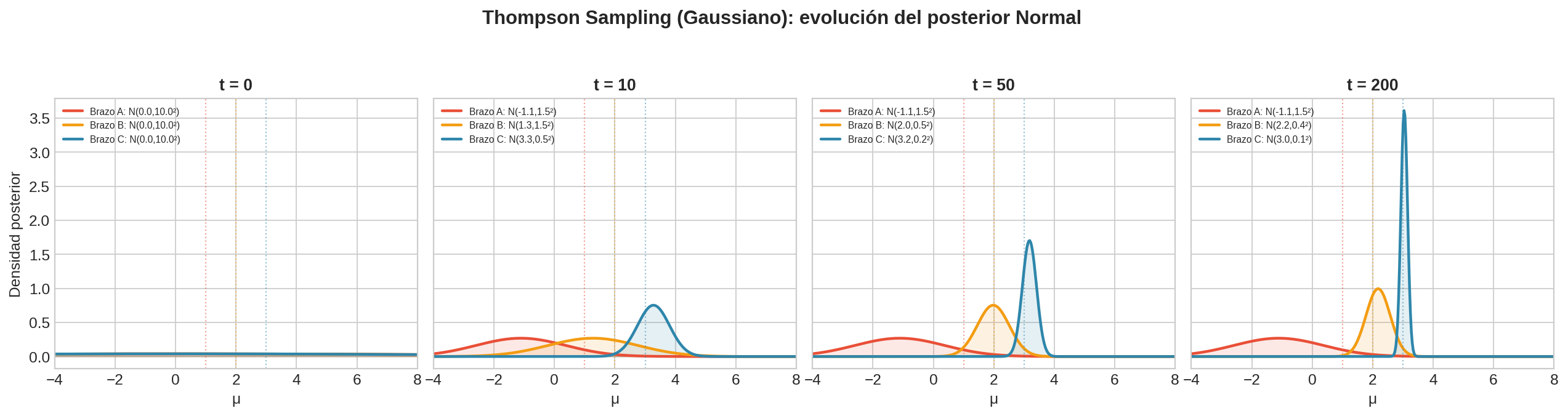
4.5 Thompson Sampling para Gaussianas (Normal-Normal)
Para el Problema Canónico B (recompensas $r \sim \mathcal{N}(\mu_i, \sigma^2)$ con $\sigma$ conocida), usamos la conjugación Normal-Normal.
Prior y posterior
- Prior: $\mu_i \sim \mathcal{N}(\mu_0, \sigma_0^2)$ (típicamente $\mu_0 = 0$, $\sigma_0 = 10$ para prior vago)
- Después de $n$ observaciones con suma $S = \sum r_j$:
$$\mu_i \mid \text{datos} \sim \mathcal{N}\left(\mu_n, \sigma_n^2\right)$$
donde:
$$\sigma_n^2 = \frac{1}{\frac{1}{\sigma_0^2} + \frac{n}{\sigma^2}} \qquad \mu_n = \sigma_n^2 \left(\frac{\mu_0}{\sigma_0^2} + \frac{S}{\sigma^2}\right)$$
Intuición: media ponderada por precisión
La precisión es el inverso de la varianza: $\tau = 1/\sigma^2$. Entonces:
$$\mu_n = \frac{\tau_0 \cdot \mu_0 + n \cdot \tau_\text{datos} \cdot \bar{r}}{\tau_0 + n \cdot \tau_\text{datos}}$$
La media posterior es un promedio ponderado entre el prior ($\mu_0$) y los datos ($\bar{r}$), con pesos proporcionales a sus precisiones. Con pocas observaciones, el prior domina. Con muchas, los datos dominan.
Actualización incremental
Al observar un nuevo $r$:
$$\tau_\text{post} = \tau_\text{prev} + \tau_\text{datos} \qquad \mu_\text{post} = \frac{\tau_\text{prev} \cdot \mu_\text{prev} + \tau_\text{datos} \cdot r}{\tau_\text{post}}$$
donde $\tau_\text{datos} = 1/\sigma^2$.
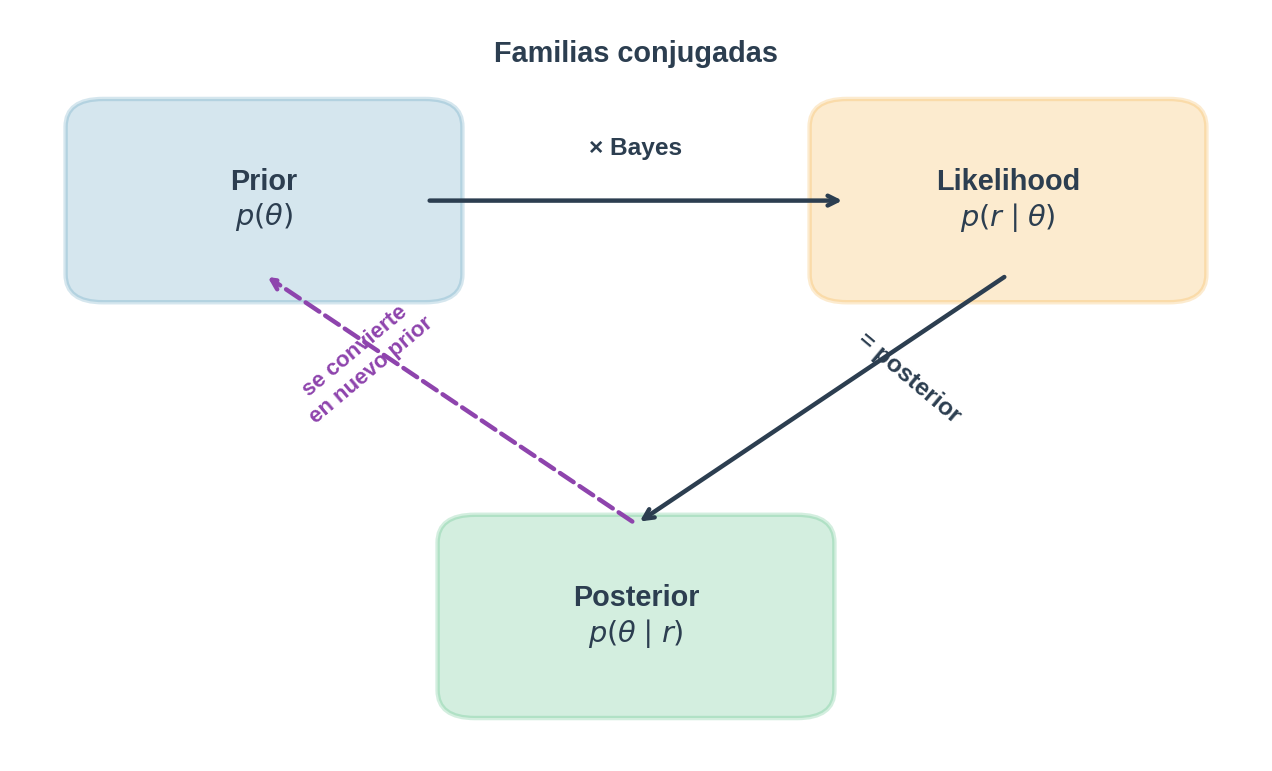
4.6 El patrón general: familias conjugadas
Thompson Sampling funciona con cualquier familia conjugada. El patrón es siempre el mismo:
- Elegir un prior conjugado para la distribución de recompensas
- Muestrear del posterior
- Actualizar el posterior con la recompensa observada
| Tipo de recompensa | Likelihood | Prior | Posterior | Actualización |
|---|---|---|---|---|
| Binaria (0/1) | Bernoulli($\theta$) | Beta($\alpha, \beta$) | Beta($\alpha+r, \beta+1-r$) | Sumar 1 a $\alpha$ o $\beta$ |
| Continua | Normal($\mu, \sigma^2$) | Normal($\mu_0, \sigma_0^2$) | Normal($\mu_n, \sigma_n^2$) | Media ponderada por precisión |
| Conteo | Poisson($\lambda$) | Gamma($\alpha, \beta$) | Gamma($\alpha+r, \beta+1$) | Sumar conteo a $\alpha$, incrementar $\beta$ |
| Duración | Exponencial($\lambda$) | Gamma($\alpha, \beta$) | Gamma($\alpha+1, \beta+r$) | Incrementar $\alpha$, sumar tiempo a $\beta$ |
Ejemplo: anuncios con conteos. Si cada “brazo” es un anuncio y la recompensa es el número de clics (Poisson), usamos un prior Gamma. Cada clic observado actualiza $\alpha \leftarrow \alpha + \text{clics}$ y $\beta \leftarrow \beta + 1$.
4.7 ¿Por qué funciona? Probability matching
Thompson Sampling satisface una propiedad elegante llamada probability matching:
$$P(A_t = i) \approx P(\mu_i = \mu^{∗} \mid \text{historial}_t)$$
La probabilidad de seleccionar un brazo es (aproximadamente) igual a la probabilidad posterior de que ese brazo sea el mejor. Esto tiene consecuencias directas:
- Al inicio: los posteriores son anchos → la probabilidad de que cualquier brazo sea el mejor es ~$1/K$ → exploración aproximadamente uniforme
- Conforme se acumulan datos: el posterior del mejor brazo se concentra → $P(\mu_{i^{∗}} = \mu^{∗}) \to 1$ → explotación casi total
- La transición es suave: no hay cambio abrupto entre exploración y explotación
Esta es la diferencia clave con UCB1: UCB1 es determinista dado el historial. Thompson Sampling es estocástico — la aleatorización proviene del muestreo del posterior, no de un coin flip externo.
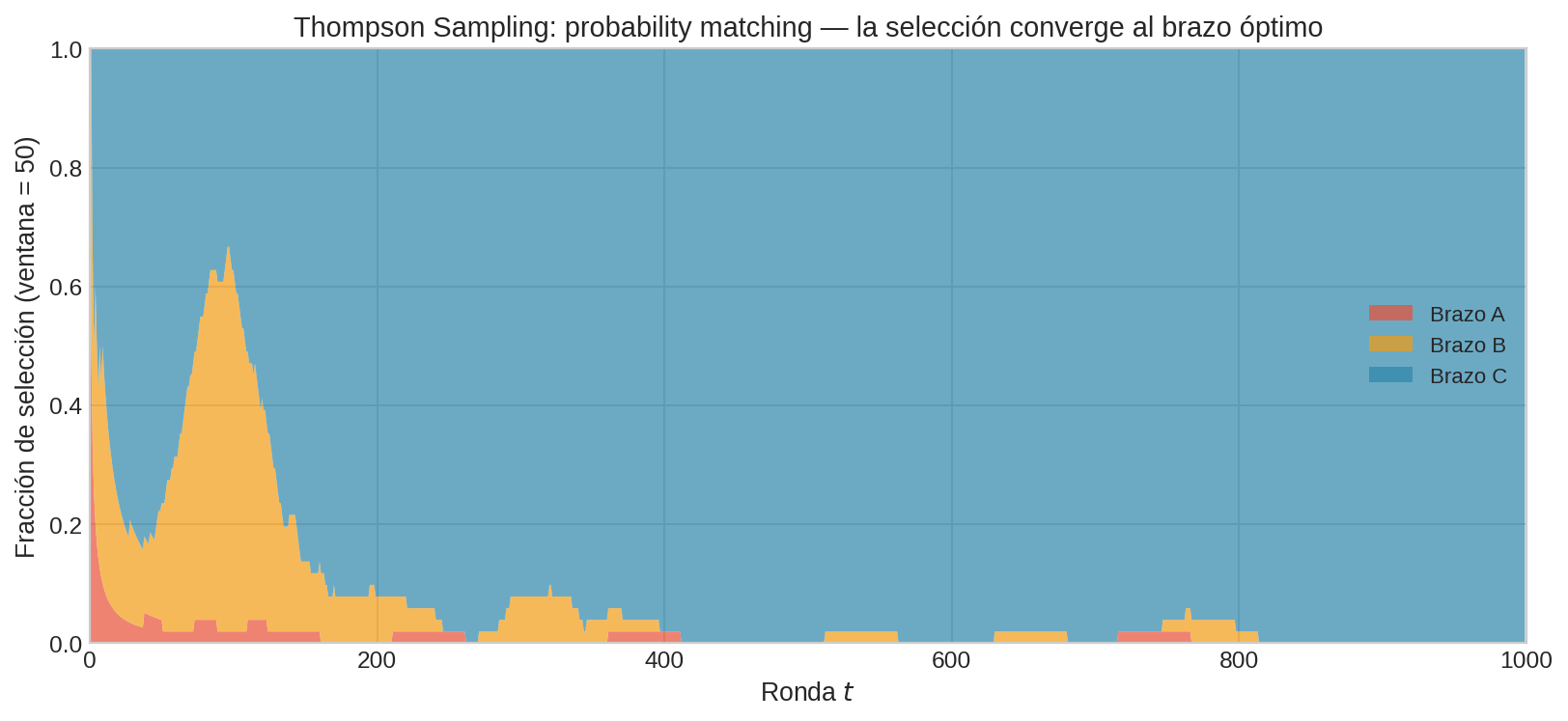
4.8 Análisis de regret
Teorema (Kaufmann, Korda & Munos, 2012): Para bandidos Bernoulli, Thompson Sampling con prior Beta(1,1) satisface:
$$\limsup_{T \to \infty} \frac{\mathbb{E}[R_T]}{\log T} \leq \sum_{i: \mu_i < \mu^{∗}} \frac{\Delta_i}{\text{KL}(\mu_i, \mu^{∗})}$$
Esto iguala la cota inferior de Lai-Robbins: Thompson Sampling es asintóticamente óptimo.
Comparación con UCB1:
| UCB1 | Thompson | |
|---|---|---|
| Cota de regret | $O\left(\sum \frac{\log T}{\Delta_i}\right)$ | $O\left(\sum \frac{\Delta_i \log T}{\text{KL}(\mu_i, \mu^{∗})}\right)$ |
| Optimal? | No (constante subóptima) | Sí (asintóticamente) |
| Incorpora prior? | No | Sí |
| Empírico | Bueno | A menudo mejor que UCB1 |
Resumen
| Propiedad | Thompson Sampling |
|---|---|
| Idea | Muestrear del posterior, actuar según la muestra |
| Fórmula | $\theta_i \sim \text{posterior}_i$, $A_t = \arg\max_i \theta_i$ |
| Parámetros | Prior ($\alpha_0, \beta_0$ para Bernoulli) — típicamente (1,1) |
| Regret | $O\left(\sum \frac{\Delta_i \log T}{\text{KL}}\right)$ — asintóticamente óptimo |
| Ventaja | Naturalmente balancea exploración/explotación; incorpora información previa |
| Desventaja | Asume recompensas estocásticas (distribución fija) |
| Cuándo usar | Caso general; especialmente valioso cuando se tiene información previa |
¿Qué pasa cuando las recompensas no provienen de una distribución fija? En la sección 17.6 veremos el escenario adversarial y el algoritmo EXP3, que no asume estructura estocástica alguna. Pero primero, en la sección 17.5 comparamos todos los algoritmos vistos.