17.5 — Comparación de algoritmos
“All models are wrong, but some are useful.” — George E. P. Box
5.1 Diseño experimental
Hasta ahora hemos analizado cada algoritmo de forma aislada: ε-greedy (§17.2), UCB1 y KL-UCB (§17.3), Thompson Sampling (§17.4). Pero las trazas manuales y los teoremas asintóticos no responden la pregunta más práctica: ¿cuánto importan estas diferencias en la práctica?
Para responderla, usamos simulación Monte Carlo:
| Parámetro | Valor | Justificación |
|---|---|---|
| Runs independientes | 200 | Suficiente para estimar media y desviación estándar del regret con baja varianza |
| Horizonte $T$ | 1000 | Largo suficiente para separar comportamiento transitorio del asintótico |
| Semilla base | 42 | Run $j$ usa semilla $42 + j$, garantizando reproducibilidad total |
| Problemas | A (Bernoulli) y B (Gaussiano) | Los dos problemas canónicos del módulo |
| Algoritmos | ε-greedy ($\varepsilon=0.1$), UCB1, KL-UCB, Thompson Sampling, EXP3 | Cadena progresiva del módulo |
¿Por qué 200 runs y no uno solo? Un solo run es ruidoso — la varianza de las recompensas hace que un algoritmo “gane” o “pierda” por casualidad. Al promediar sobre 200 trayectorias independientes, obtenemos la tendencia central del regret y podemos visualizar su dispersión (bandas de ± 1 desviación estándar). Esto es exactamente el principio Monte Carlo del Módulo 12, aplicado a la evaluación de políticas de bandidos.
5.2 Regret acumulado: Problema Canónico A (Bernoulli)
Recordemos el Problema A: 3 brazos Bernoulli con $\mu_A = 0.3$, $\mu_B = 0.5$, $\mu_C = 0.7$. Brechas $\Delta_A = 0.4$, $\Delta_B = 0.2$.
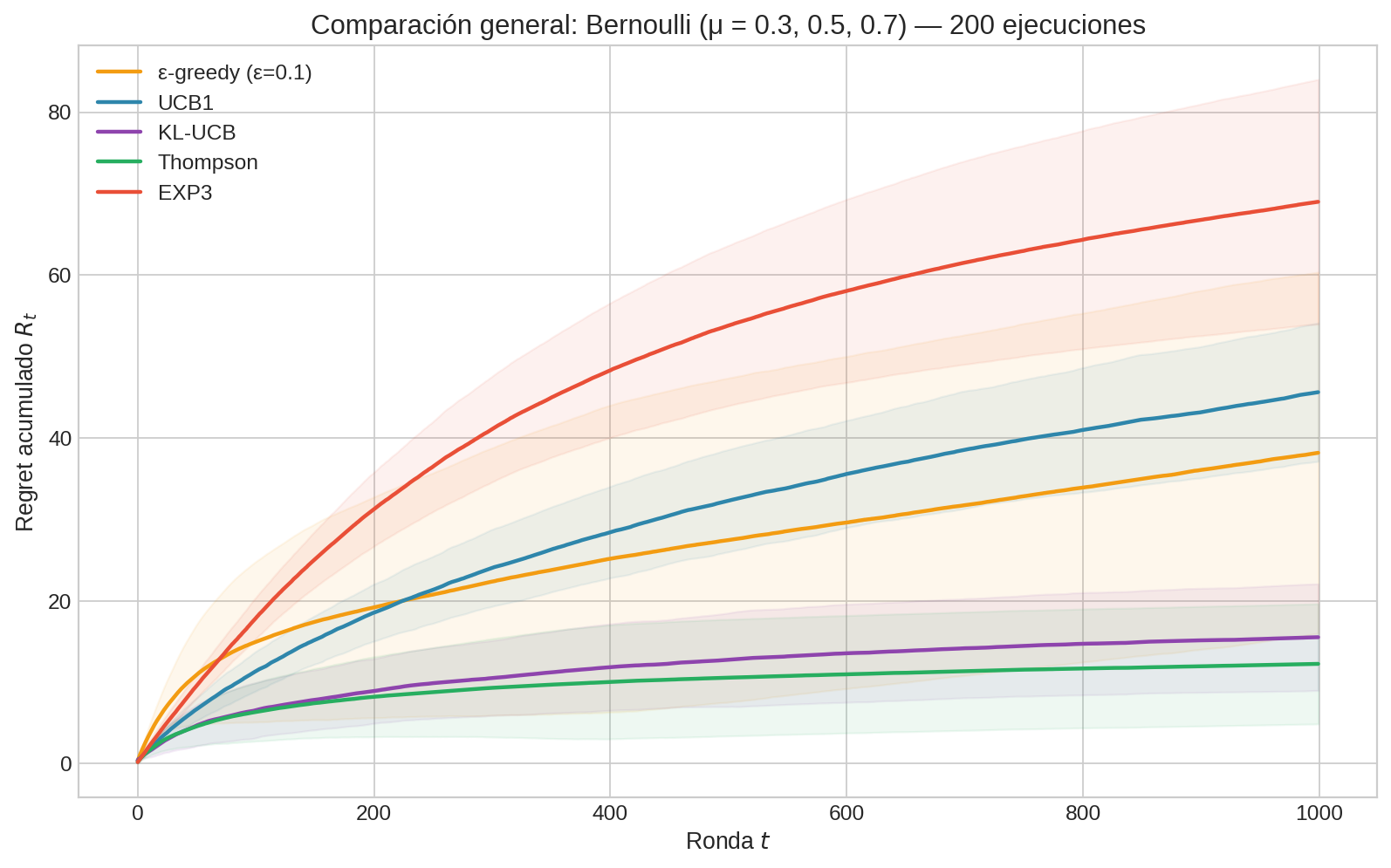
La figura muestra el regret acumulado promedio (líneas sólidas) con bandas de ± 1 desviación estándar (sombreado). Varias observaciones:
1. La jerarquía a $T = 1000$. Thompson Sampling y KL-UCB dominan, seguidos de ε-greedy, luego UCB1, y EXP3 al final. Puede sorprender que ε-greedy supere a UCB1 — el punto 3 explica por qué.
2. Thompson y KL-UCB son casi indistinguibles. Ambos alcanzan el regret asintóticamente óptimo (cota de Lai-Robbins). La diferencia está en las constantes: Thompson tiende a tener menor regret en horizontes finitos porque su exploración bayesiana es más eficiente que el bonus de confianza.
3. UCB1 pierde contra ε-greedy en este horizonte. Esto parece contradecir la teoría: UCB1 tiene regret $O(\log T)$ mientras ε-greedy tiene regret $O(\varepsilon T)$ — lineal. ¿Cómo puede un algoritmo logarítmico perder contra uno lineal?
La clave es que la notación asintótica esconde las constantes. Cuando decimos $O(\log T)$ vs $O(\varepsilon T)$, estamos diciendo que existe un $T_0$ a partir del cual el logarítmico gana. Pero $T_0$ puede ser grande. Computemos las constantes para nuestro problema:
- UCB1: $\sum_i \frac{2 \log T}{\Delta_i} = \frac{2 \log T}{0.4} + \frac{2 \log T}{0.2} = 15 \log T$. A $T = 1{,}000$: $15 \times 6.9 \approx 104$.
- ε-greedy: $\varepsilon \cdot \bar\Delta \cdot T = 0.1 \times 0.2 \times T = 0.02T$. A $T = 1{,}000$: $0.02 \times 1{,}000 = 20$.
UCB1 paga 5 veces más a $T = 1{,}000$ (las constantes teóricas sobreestiman un poco, pero la dirección es correcta). Igualando $15 \log T = 0.02T$, el cruce ocurre alrededor de $T \approx 2{,}700$. Verificamos con simulación (50 runs):
| $T$ | Thompson | KL-UCB | ε-greedy | UCB1 | EXP3 |
|---|---|---|---|---|---|
| 1,000 | 12 | 14 | 37 | 44 | 69 |
| 5,000 | 16 | 24 | 118 | 82 | 161 |
| 10,000 | 18 | — | 218 | 98 | 228 |
A $T = 5{,}000$, UCB1 ya gana (82 vs 118). A $T = 10{,}000$, la diferencia es dramática (98 vs 218). La curva de ε-greedy sigue subiendo linealmente mientras UCB1 se aplana.
Lección: la notación $O(\cdot)$ describe la forma de la curva, no dónde se ubica. Un algoritmo con mejor tasa asintótica puede tener peor rendimiento en horizontes finitos si su constante es grande. Para este problema, el cruce ocurre relativamente pronto ($T \approx 2{,}700$), pero hay problemas donde el cruce puede ser mucho más tardío (cuando las brechas $\Delta_i$ son muy pequeñas).
¿Por qué la constante de UCB1 es tan grande? Porque el bonus de Hoeffding es una cota universal (vale para cualquier distribución en $[0,1]$), así que es más ancho de lo necesario para Bernoulli. El factor $1/\Delta_i$ castiga especialmente los brazos con brecha pequeña (B con $\Delta_B = 0.2$ contribuye $10 \log T$ al regret). KL-UCB y Thompson usan la estructura de la distribución para calibrar mejor la exploración, logrando constantes cercanas al óptimo de Lai-Robbins.
4. ε-greedy tiene buena constante pero mala tasa. Con $\varepsilon = 0.1$, el regret crece como $0.02T$ — pendiente leve pero constante. El 10% de exploración uniforme se mantiene incluso cuando ya sabemos cuál es el mejor brazo. En la gráfica se ve que la curva de ε-greedy es prácticamente una recta, mientras las demás se aplanan.
5. Las bandas de dispersión importan. Thompson tiene no solo menor media sino también menor varianza que UCB1. Esto se traduce en mayor predictibilidad del rendimiento — valioso en aplicaciones como ensayos clínicos donde un run desafortunado tiene consecuencias reales.
5.3 Regret acumulado: Problema Canónico B (Gaussiano)
Ahora el Problema B: 3 brazos Gaussianos con $\mu_A = 1.0$, $\mu_B = 2.0$, $\mu_C = 3.0$ y $\sigma = 1.5$. Brechas $\Delta_A = 2.0$, $\Delta_B = 1.0$.
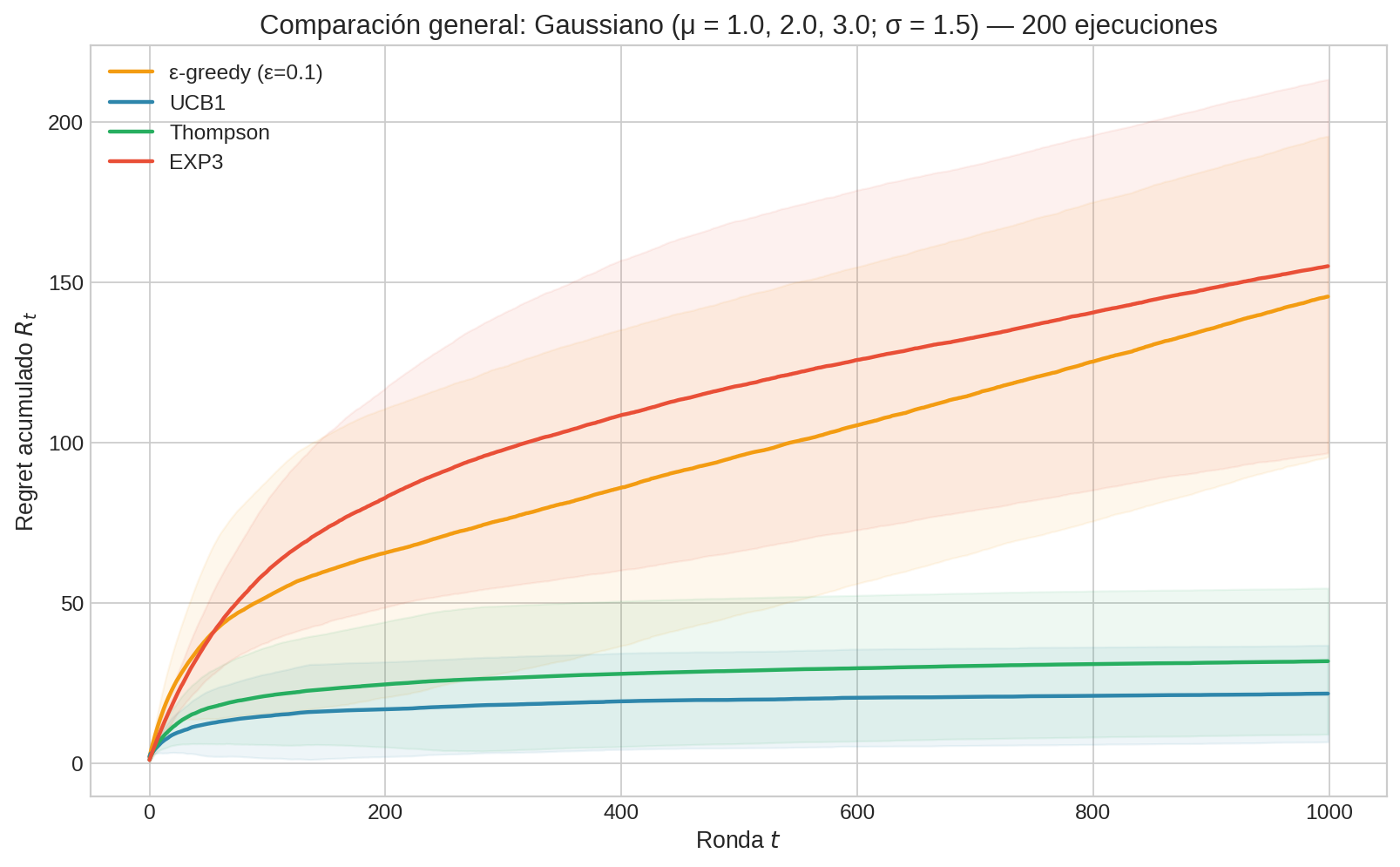
El problema Gaussiano revela dinámicas distintas:
Las distribuciones se solapan mucho. Con $\sigma = 1.5$ y $\Delta_B = 1.0$, las distribuciones de los brazos B y C se superponen considerablemente. Un pull del brazo B puede dar recompensa 4.0 (alto) mientras C da 1.5 (bajo). Esto dificulta la identificación del mejor brazo y ralentiza la convergencia de todos los algoritmos.
UCB1 es más competitivo aquí. La cota de Hoeffding fue derivada para recompensas en $[0, 1]$, pero la implementación se adapta al rango observado. Con distribuciones Gaussianas, la diferencia entre Hoeffding y KL se reduce porque la concentración gaussiana es más fuerte.
El regret absoluto es mayor. Las brechas son más grandes ($\Delta_A = 2.0$ vs. $0.4$ en Bernoulli), así que cada pull subóptimo cuesta más. Pero la tasa de convergencia (qué tan rápido el algoritmo encuentra el mejor brazo) sigue siendo logarítmica para UCB1, KL-UCB y Thompson.
EXP3 sufre más. En el caso Gaussiano, no explotar la estructura de la distribución tiene un costo mayor porque las brechas son absolutamente más grandes. Cada exploración innecesaria cuesta $\Delta = 1.0$ o $2.0$ unidades de regret.
5.4 Evolución de la selección de brazos
El regret acumulado nos dice cuánto pierde cada algoritmo, pero no cómo distribuye su atención. La siguiente figura muestra la fracción de pulls por brazo en tres momentos: $T = 50$, $T = 200$ y $T = 1000$.
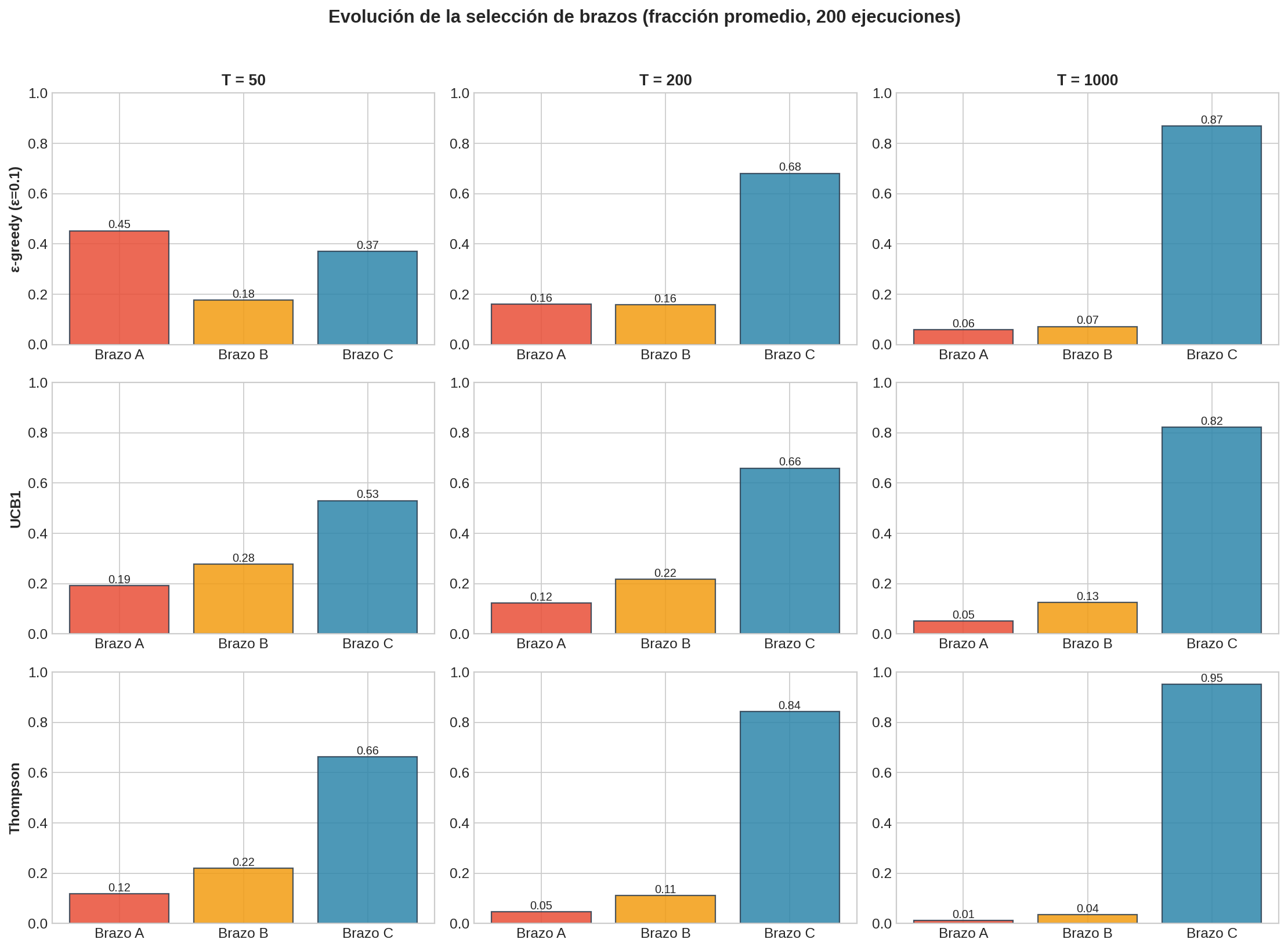
Lectura por algoritmo
ε-greedy ($\varepsilon = 0.1$): A $T = 1000$, aproximadamente el 93% de los pulls van al brazo óptimo C — pero un 3-4% sigue yendo a cada brazo subóptimo. Esto es mecánico: el 10% de exploración se reparte uniformemente entre los 3 brazos ($\approx$ 3.3% cada uno), sin importar lo que hemos aprendido. Este es el “techo” de ε-greedy con $\varepsilon$ constante.
UCB1: La transición es más drástica. A $T = 50$, la distribución es relativamente uniforme (los bonuses de confianza son grandes con pocos datos). A $T = 1000$, C domina con más del 95% de los pulls. La exploración residual es decreciente: como el bonus crece como $\sqrt{\log T / N_i}$ y $N_i$ del brazo óptimo crece linealmente, los subóptimos solo se exploran cuando su bonus supera la brecha — cada vez con menor frecuencia.
Thompson Sampling: A $T = 50$, ya concentra más del 60% en C — la exploración bayesiana es más eficiente desde el inicio. A $T = 1000$, prácticamente el 100% de los pulls van a C. La clave: Thompson no tiene una “tasa mínima de exploración” como ε-greedy. Conforme los posteriores se estrechan, la probabilidad de que un brazo subóptimo “gane” el muestreo tiende a cero.
Patrón común
Los tres algoritmos estocásticos convergen al mismo punto (explotación casi total de C), pero la velocidad de convergencia es: Thompson > UCB1 > ε-greedy. La diferencia en regret acumulado viene directamente de cuántas rondas “desperdician” en exploración innecesaria durante la fase transitoria.
5.5 Porcentaje de pulls óptimos
Una métrica complementaria es el porcentaje de pulls óptimos (pulls al brazo C) como función del tiempo. Mientras el regret mide la pérdida acumulada, esta métrica mide la tasa de acierto instantánea.
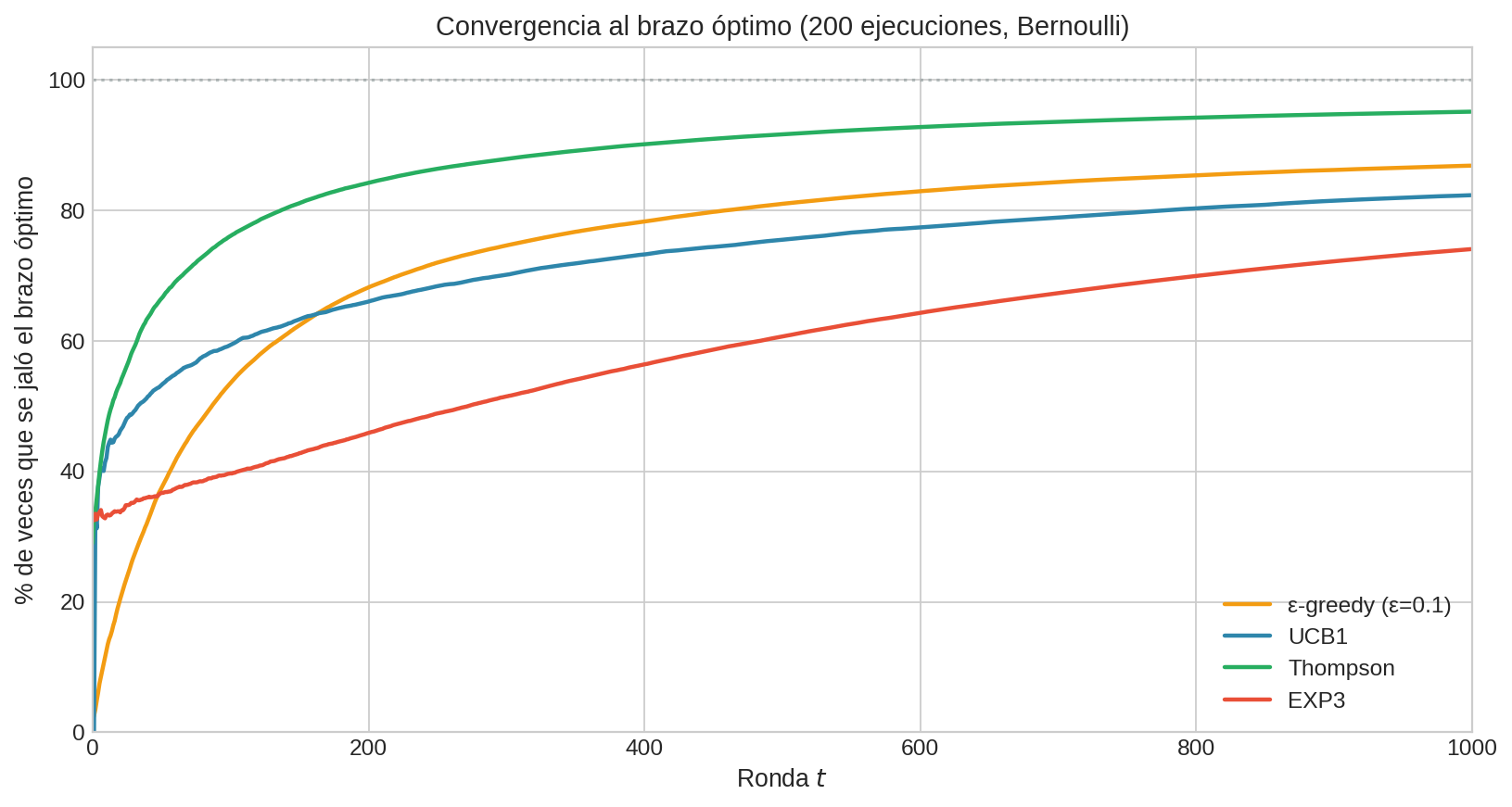
Thompson Sampling converge más rápido al 100%, consistente con su menor regret. UCB1 lo sigue de cerca pero con una meseta ligeramente más baja. ε-greedy se estabiliza en $\approx$ 93.3%: el techo teórico es $1 - \varepsilon + \varepsilon/K = 1 - 0.1 + 0.1/3 \approx 0.933$. KL-UCB se comporta como Thompson en esta métrica. EXP3 converge más lentamente porque mantiene pesos positivos sobre todos los brazos.
Esta figura es especialmente útil para decidir entre algoritmos en aplicaciones con horizontes cortos. Si $T$ es pequeño (e.g., solo 100 rondas), la velocidad de convergencia importa más que las propiedades asintóticas. Thompson y KL-UCB tienen ventaja clara en horizontes finitos.
5.6 Tabla comparativa
La siguiente tabla sintetiza las propiedades teóricas y prácticas de los cinco algoritmos:
| Propiedad | ε-greedy ($\varepsilon = 0.1$) | UCB1 | KL-UCB | Thompson Sampling | EXP3 |
|---|---|---|---|---|---|
| Supuesto | Estocástico (i.i.d.) | Estocástico (i.i.d.) | Estocástico (i.i.d.) | Estocástico (i.i.d.) | Ninguno (adversarial) |
| Marco teórico | Frecuentista | Frecuentista | Frecuentista | Bayesiano | Frecuentista |
| Mecanismo de exploración | Aleatorio uniforme con prob. $\varepsilon$ | Bonus de confianza (Hoeffding) | Bonus de confianza (KL) | Muestreo del posterior | Pesos exponenciales |
| Parámetros | $\varepsilon$ | Ninguno | Ninguno | Prior ($\alpha_0, \beta_0$) | $\gamma$ (tasa de mezcla) |
| Regret | $O(\varepsilon T)$ — lineal | $O\left(\sum_i \frac{\log T}{\Delta_i}\right)$ | $O\left(\sum_i \frac{\Delta_i \log T}{\text{KL}(\mu_i, \mu^{∗})}\right)$ | $O\left(\sum_i \frac{\Delta_i \log T}{\text{KL}(\mu_i, \mu^{∗})}\right)$ | $O(\sqrt{KT \log K})$ |
| Asintóticamente óptimo | No | No (constante subóptima) | Sí | Sí | N/A (distinto régimen) |
| Cómputo por paso | $O(1)$ | $O(K)$ | $O(K)$ — requiere resolver ecuación KL | $O(K)$ — requiere muestreo | $O(K)$ |
| Determinista | No (coin flip) | Sí | Sí | No (muestreo posterior) | No (pesos probabilísticos) |
| Robusto a adversario | No | No | No | No | Sí |
5.7 La cota de Lai-Robbins: ¿quién la alcanza?
La cota inferior de Lai-Robbins (1985) establece el regret mínimo que cualquier política consistente puede alcanzar en el caso estocástico:
$$\liminf_{T \to \infty} \frac{\mathbb{E}[R_T]}{\log T} \geq \sum_{i: \mu_i < \mu^{∗}} \frac{\Delta_i}{\text{KL}(\mu_i, \mu^{∗})}$$
donde $\text{KL}(\mu_i, \mu^{∗})$ es la divergencia de Kullback-Leibler entre las distribuciones del brazo $i$ y el brazo óptimo.
¿Qué algoritmos la igualan?
| Algoritmo | ¿Iguala Lai-Robbins? | Comentario |
|---|---|---|
| ε-greedy ($\varepsilon$ fijo) | No | Regret lineal; no es ni siquiera sublineal |
| ε-greedy ($\varepsilon_t \to 0$) | Depende del schedule | Con $\varepsilon_t = c / t$ adecuado puede ser $O(\log T)$, pero no necesariamente con constante óptima |
| UCB1 | No | Logarítmico pero con constante $2/\Delta_i$ en vez de $\Delta_i / \text{KL}$ |
| KL-UCB | Sí | Diseñado explícitamente para igualar la cota (Cappé et al., 2013) |
| Thompson Sampling | Sí | Demostrado por Kaufmann, Korda & Munos (2012) para Bernoulli |
| EXP3 | N/A | La cota de Lai-Robbins aplica al caso estocástico; EXP3 está diseñado para el adversarial |
¿De dónde viene la ventaja de KL sobre Hoeffding?
La divergencia KL entre dos Bernoulli con parámetros $p$ y $q$ es:
$$\text{KL}(p, q) = p \ln \frac{p}{q} + (1-p) \ln \frac{1-p}{1-q}$$
Para el Problema A, los valores relevantes son:
| Par | $\Delta_i$ | $\text{KL}(\mu_i, \mu^{∗})$ | $\Delta_i / \text{KL}$ (Lai-Robbins) | $1 / \Delta_i$ (UCB1-style) |
|---|---|---|---|---|
| A vs C | 0.4 | $\text{KL}(0.3, 0.7) \approx 0.339$ | $\approx 1.18$ | 2.5 |
| B vs C | 0.2 | $\text{KL}(0.5, 0.7) \approx 0.087$ | $\approx 2.29$ | 5.0 |
UCB1 sobreexplora el brazo A (le asigna constante 2.5 cuando bastaría 1.18) y subexplora el brazo B relativo a lo necesario. KL-UCB y Thompson calibran la exploración según la verdadera dificultad de distinguir cada brazo del óptimo.
5.8 ¿Qué algoritmo usar? Guía práctica
No existe un algoritmo universalmente mejor — la elección depende del contexto. Aquí una guía de decisión:
Paso 1: ¿Las recompensas son estocásticas o adversariales?
- Estocásticas (cada brazo tiene una distribución fija): sigue al paso 2
- Adversariales (un adversario puede cambiar las recompensas): usa EXP3 (§17.6)
- No estás seguro: EXP3 es la opción segura; el costo es $O(\sqrt{T})$ en vez de $O(\log T)$
Paso 2: ¿Tienes información previa sobre las distribuciones?
- Sí (e.g., de un estudio previo, datos históricos): usa Thompson Sampling — el prior codifica esa información y acelera la convergencia
- No: sigue al paso 3
Paso 3: ¿Cuál es tu prioridad?
| Prioridad | Recomendación | Razón |
|---|---|---|
| Máximo rendimiento teórico | KL-UCB | Asintóticamente óptimo, determinista, sin hiperparámetros |
| Mejor rendimiento práctico | Thompson Sampling | Competitivo o superior a KL-UCB en horizontes finitos; más fácil de implementar |
| Simplicidad de implementación | ε-greedy | 5 líneas de código; aceptable si $T$ es grande y la suboptimalidad del 10% es tolerable |
| Interpretabilidad | UCB1 | El bonus de confianza tiene significado estadístico claro |
| Sistema en producción | Thompson Sampling | Paralelizable, robusto a priors razonables, rendimiento consistente |
Paso 4: Consideraciones adicionales
- Horizonte corto ($T < 100$): Thompson > KL-UCB > UCB1 (la constante del transitorio domina)
- Muchos brazos ($K > 100$): Thompson escala bien; ε-greedy desperdicia demasiado en exploración ($\varepsilon / K$ por brazo)
- Restricciones computacionales: ε-greedy es $O(1)$ por paso; los demás son $O(K)$
- Recompensas no acotadas: UCB1 requiere adaptación; Thompson con prior Normal-Normal funciona directamente
5.9 Vista previa: el escenario adversarial
Todos los resultados de esta sección asumen recompensas estocásticas — cada brazo tiene una distribución fija e independiente del comportamiento del agente. Pero hay escenarios donde esta suposición es peligrosamente incorrecta:
- Mercados financieros: los retornos cambian en respuesta a las acciones de los participantes
- Juegos: el oponente adapta su estrategia a la nuestra
- Redes de anuncios: las tasas de clic varían con la hora del día, la competencia, las tendencias
En estos casos, un adversario (real o implícito) puede elegir las recompensas después de ver nuestra política. Los algoritmos estocásticos pueden sufrir regret lineal en el peor caso adversarial.
La sección 17.6 introduce EXP3 (Exponential-weight algorithm for Exploration and Exploitation), que garantiza $O(\sqrt{KT \log K})$ regret contra cualquier secuencia de recompensas, incluyendo las elegidas por un adversario omnisciente. El costo: peor rendimiento en el caso estocástico. El beneficio: robustez — funciona siempre.