17.6 — EXP3: bandidos adversariales
“The art of war teaches us to rely not on the likelihood of the enemy’s not coming, but on our own readiness to receive him.” — Sun Tzu
6.1 ¿Por qué cuestionar el supuesto estocástico?
Todos los algoritmos vistos hasta ahora — ε-greedy, UCB1, Thompson Sampling — comparten un supuesto fundamental: las recompensas de cada brazo provienen de una distribución fija (Bernoulli, Gaussiana, etc.). El entorno es estacionario y “honesto”.
¿Cuándo falla este supuesto?
- Publicidad competitiva: si dos empresas usan bandidos para elegir anuncios, las recompensas de cada anuncio dependen de lo que muestra el competidor — un objetivo móvil
- Oponentes adaptativos: en seguridad informática, un atacante puede cambiar de estrategia al observar las defensas desplegadas
- Preferencias cambiantes: los usuarios de una plataforma cambian de gustos — lo que funcionaba en enero puede fallar en marzo
- Mercados financieros: los retornos de un activo no son i.i.d.; dependen de la dinámica global del mercado
En estos escenarios, modelar al entorno como un adversario que elige las recompensas (o pérdidas) de forma deliberada resulta más robusto que asumir estocasticidad.
6.2 El modelo adversarial
¿Por qué pérdidas en vez de recompensas?
Hasta ahora hemos hablado de recompensas (el brazo paga $r_t$ y queremos maximizar). En el modelo adversarial, la convención es usar pérdidas $\ell_t \in [0, 1]$ que queremos minimizar. La relación es simple: $\ell_t = 1 - r_t$. Un brazo con recompensa alta tiene pérdida baja y viceversa.
¿Por qué el cambio? Por tradición de la teoría de juegos y optimización online, donde el problema se plantea como minimización. No cambia la matemática — solo la dirección. Cuando veamos que EXP3 “penaliza” un brazo con pérdida alta, es equivalente a decir que “favorece” brazos con recompensa alta.
Protocolo
En el modelo estocástico, las recompensas vienen de una distribución fija — el entorno es “pasivo”. En el modelo adversarial, imaginamos un oponente que elige activamente las pérdidas. El juego se desarrolla así en cada ronda $t = 1, \ldots, T$:
- El adversario elige un vector de pérdidas $\ell_t = (\ell_{t,1}, \ldots, \ell_{t,K}) \in [0, 1]^K$ — una pérdida para cada brazo (el agente no ve este vector completo)
- El agente elige un brazo $A_t$ muestreando de una distribución $p_t$ sobre los $K$ brazos
- El agente observa solo $\ell_{t, A_t}$ — la pérdida del brazo que eligió, no la de los demás
El punto crucial del paso 2: el agente debe aleatorizar. Si fuera determinista (como UCB1), el adversario podría predecir su elección y castigarlo siempre.
Regret adversarial
En el caso estocástico, el benchmark era simple: el brazo con mayor $\mu_i$ (que nunca cambia). Aquí las pérdidas cambian cada ronda, así que no hay un “mejor brazo” obvio. El benchmark que usamos es el mejor brazo fijo en retrospectiva: imaginemos que después de jugar las $T$ rondas, miramos hacia atrás y preguntamos “¿qué brazo debería haber jalado todas las rondas?” Es el brazo $i$ que minimiza $\sum_{t=1}^T \ell_{t,i}$.
¿Por qué “fijo”? ¿Por qué no comparar contra la mejor estrategia que puede cambiar de brazo cada ronda? Porque esa estrategia elegiría siempre el brazo con menor pérdida en cada ronda — tendría pérdida casi cero. Ningún algoritmo puede competir con alguien que conoce el futuro, así que el regret sería siempre $\Omega(T)$ y el problema no tendría solución.
El “mejor brazo fijo” es un benchmark más débil pero alcanzable: un brazo que, comprometido de antemano a una sola elección para todas las rondas, minimiza su pérdida total. Es como calificar con curva: no comparamos contra un estudiante que sabía todas las respuestas (benchmark imposible), sino contra el que siempre eligió la misma estrategia y resultó ser la mejor en promedio. EXP3 demuestra que se puede competir con este benchmark, logrando regret $R_T/T \to 0$ conforme $T \to \infty$.
El regret mide cuánto peor lo hicimos comparado con esa estrategia:
$$R_T = \underset{\text{pérdida del agente}}{\sum_{t=1}^{T} \ell_{t, A_t}} - \underset{\text{pérdida del mejor brazo fijo}}{\min_{i \in {1,\ldots,K}} \sum_{t=1}^{T} \ell_{t,i}}$$
Ejemplo. Supongamos $T = 4$ rondas, 2 brazos, y las pérdidas fueron:
| Ronda | $\ell_{t,A}$ | $\ell_{t,B}$ | Agente elige | Pérdida del agente |
|---|---|---|---|---|
| 1 | 0.2 | 0.8 | A | 0.2 |
| 2 | 0.9 | 0.3 | A | 0.9 |
| 3 | 0.1 | 0.7 | B | 0.7 |
| 4 | 0.8 | 0.4 | A | 0.8 |
Pérdida total del agente: $0.2 + 0.9 + 0.7 + 0.8 = 2.6$. Pérdida total si hubiéramos elegido siempre A: $0.2 + 0.9 + 0.1 + 0.8 = 2.0$. Pérdida total si siempre B: $0.8 + 0.3 + 0.7 + 0.4 = 2.2$. El mejor brazo fijo es A (pérdida 2.0). Regret: $2.6 - 2.0 = 0.6$.
¿Por qué el adversario no elige pérdida máxima para todos?
Esta pregunta toca la filosofía detrás del modelo. El adversario no es un agente que quiere “destruirnos” — es una abstracción matemática que modela el peor caso posible. Viene de la teoría de juegos: pensamos en el problema como un juego de suma cero entre el agente y la naturaleza (o un oponente). El regret mide quién gana.
¿Por qué no elige $\ell_t = (1, 1, 1)$ — pérdida máxima para todos? Porque eso no genera regret. Si todos los brazos tienen pérdida 1, nuestra pérdida total es $T$ pero la del mejor brazo fijo también es $T$: el regret es $T - T = 0$. El adversario nos lastimó, pero también lastimó al benchmark por igual — no ganó nada.
El objetivo del adversario es maximizar el regret — la diferencia entre nuestra pérdida y la del mejor brazo fijo. Para lograrlo necesita asimetría: darle pérdida alta al brazo que vamos a elegir y pérdida baja a algún otro brazo. Así, existe un brazo fijo que acumula poca pérdida (el benchmark baja) mientras nosotros acumulamos mucha (nuestra pérdida sube).
Históricamente, esta formulación surge de la teoría de decisión minimax de Von Neumann y Wald (1940s): diseñar estrategias que funcionen bien incluso bajo el peor escenario posible. No asumimos que existe un adversario real — pero si nuestro algoritmo funciona contra el peor caso, funcionará contra cualquier entorno, incluyendo los estocásticos.
¿Por qué esto hace vulnerables a los algoritmos deterministas? Si el adversario sabe qué brazo elegiremos (porque la selección es determinista dado el historial), puede asignarle pérdida 1 y darle pérdida 0 a otro brazo. Cada ronda genera regret 1, y el regret total es $T$ — lineal. Contra un algoritmo aleatorio como EXP3, el adversario no sabe cuál brazo elegiremos en esta ronda, así que no puede dirigir el castigo sin también afectar al benchmark.
Contraste con el modelo estocástico
| Aspecto | Estocástico | Adversarial |
|---|---|---|
| Recompensas | $r_{t,i} \sim F_i$ (distribución fija) | $\ell_{t,i}$ elegida por adversario |
| Benchmark | Brazo con mayor $\mu_i$ | Mejor brazo fijo en retrospectiva |
| Información | Feedback de bandidos | Feedback de bandidos |
| Regret alcanzable | $O(K \log T / \Delta)$ | $O(\sqrt{KT \ln K})$ |
6.3 ¿Por qué fallan UCB1 y Thompson?
UCB1 es determinista — el adversario lo predice
UCB1 selecciona $A_t = \arg\max_i \text{UCB}_i(t)$. Dado el historial, la selección es completamente determinista. Un adversario adaptativo puede calcular qué brazo elegirá UCB1 y asignarle la pérdida máxima:
Ejemplo concreto (3 brazos): Supongamos que UCB1 ha convergido a explotar el brazo C. El adversario hace:
$$\ell_{t,C} = 1, \quad \ell_{t,A} = 0, \quad \ell_{t,B} = 0$$
UCB1 sufre pérdida 1 en cada ronda. Eventualmente UCB1 cambia a otro brazo (digamos B), y el adversario simplemente reasigna $\ell_{t,B} = 1$. El adversario siempre castiga al brazo que UCB1 va a elegir.
Thompson Sampling también concentra
Aunque Thompson es estocástico, su posterior se concentra con el tiempo. Después de muchas observaciones, $P(A_t = i^{∗}) \to 1$ para algún brazo $i^{∗}$. El adversario puede explotar esta concentración: basta observar qué brazo domina las elecciones y castigarlo.
La defensa: aleatorización sostenida
La clave para sobrevivir a un adversario es nunca volverse predecible. El agente debe mantener una distribución sobre los brazos que no colapse a un solo brazo, pero que tampoco sea uniformemente aleatoria (eso sería no aprender nada).
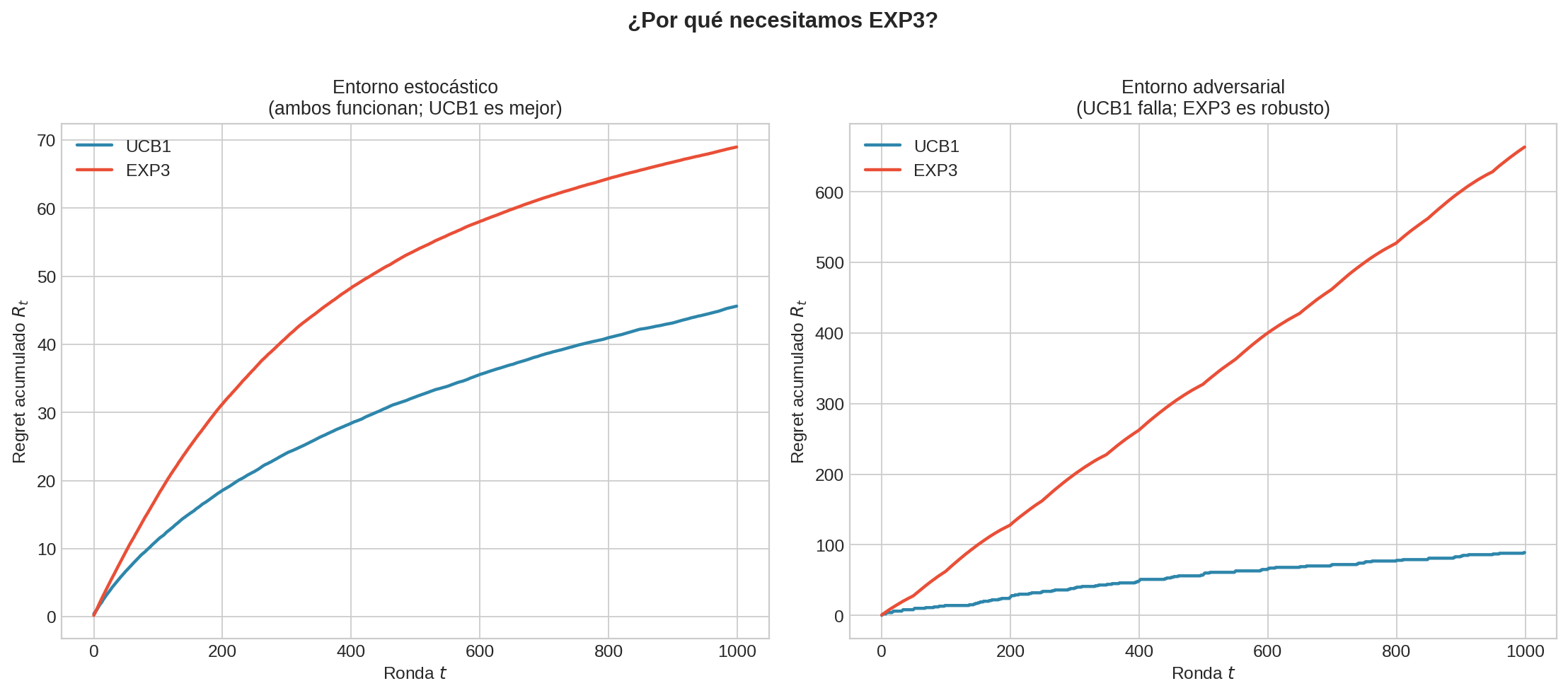
En el panel izquierdo (entorno estocástico), tanto UCB1 como EXP3 funcionan. En el panel derecho (entorno adversarial), UCB1 sufre regret lineal mientras EXP3 mantiene regret sublineal.
6.4 El algoritmo EXP3
EXP3 (Exponential-weight algorithm for Exploration and Exploitation) fue propuesto por Auer et al. (2002). Antes de ver el pseudocódigo, construyamos la intuición paso a paso.
El problema fundamental: solo vemos un brazo
En UCB1 y Thompson, estimamos $\mu_i$ para cada brazo. Pero eso asume que $\mu_i$ es constante — si el adversario cambia las pérdidas cada ronda, no hay “media real” que estimar.
¿Qué podemos hacer entonces? En vez de estimar medias, mantenemos pesos que resumen qué tan bien le ha ido a cada brazo hasta ahora. Brazos con bajas pérdidas acumulan peso alto; brazos con altas pérdidas lo pierden.
Pero hay un obstáculo: en cada ronda solo observamos la pérdida del brazo que elegimos. No sabemos qué habría pasado con los otros brazos. ¿Cómo actualizamos sus pesos?
Importance weighting: corregir el sesgo de muestreo
Queremos actualizar los pesos de todos los brazos, pero solo observamos la pérdida del brazo que elegimos. Para los demás, no tenemos información directa. ¿Qué hacemos?
La idea con una analogía. Imagina una encuesta electoral donde encuestas a personas al azar, pero tu muestreo está sesgado: visitas la zona norte (60% de tus encuestas) mucho más que la zona sur (10%). Si solo cuentas votos crudos, sobrerepresentas al norte. La corrección es simple: cada voto del sur lo cuentas como $1/0.1 = 10$ votos (porque lo muestreaste con probabilidad 0.1), y cada voto del norte como $1/0.6 \approx 1.7$. Así, en promedio, cada zona contribuye proporcionalmente a su tamaño real. Esto es importance weighting: dividir cada observación por su probabilidad de ser observada.
Aplicación a EXP3. Elegimos el brazo $i$ con probabilidad $p_{t,i}$ y observamos pérdida $\ell_{t,i}$. Definimos el estimador:
$$\hat\ell_{t,i} = \begin{cases} \ell_{t,i} / p_{t,i} & \text{si } A_t = i \text{ (lo elegimos)} \ 0 & \text{si } A_t \neq i \text{ (no lo elegimos)} \end{cases}$$
¿Qué hace la división por $p_{t,i}$? Si un brazo se elige con poca frecuencia ($p_{t,i} = 0.1$), solo lo observamos el 10% de las veces. Cuando sí lo observamos, “amplificamos” su pérdida por $1/0.1 = 10$ para compensar todas las veces que no lo vimos. Si un brazo se elige frecuentemente ($p_{t,i} = 0.9$), lo observamos casi siempre y la amplificación es mínima ($1/0.9 \approx 1.1$).
¿Es correcto en promedio? Sí — el estimador es insesgado:
$$\mathbb{E}[\hat\ell_{t,i}] = \underset{\text{prob. de observarlo}}{p_{t,i}} \cdot \underset{\text{valor si lo observamos}}{\frac{\ell_{t,i}}{p_{t,i}}} + \underset{\text{prob. de no observarlo}}{(1 - p_{t,i})} \cdot \underset{\text{valor si no}}{0} = \ell_{t,i}$$
El estimador es insesgado — en expectativa, recupera la pérdida real. Esto se llama importance weighting: corregir el sesgo de muestreo dividiendo por la probabilidad de observación.
Pesos multiplicativos: la idea central
Cada brazo tiene un peso $w_i$ que empieza en 1 (sin preferencia). Después de estimar la pérdida $\hat\ell_{t,i}$, actualizamos:
$$w_i \leftarrow w_i \cdot \exp(-\eta \cdot \hat\ell_{t,i})$$
Si $\hat\ell_{t,i}$ es grande (brazo malo), $\exp(-\eta \cdot \hat\ell_{t,i})$ es menor que 1, así que el peso baja. Si $\hat\ell_{t,i} = 0$ (no lo observamos), el peso no cambia. Los pesos normalizados ($w_i / \sum_j w_j$) dan la probabilidad de selección.
¿Por qué multiplicativo (exponencial) en vez de aditivo? Porque la actualización multiplicativa es más agresiva con los brazos malos y más estable numéricamente. Es la misma idea detrás del algoritmo AdaBoost en machine learning.
Mezcla con exploración uniforme
Si solo usáramos los pesos normalizados, un brazo con peso muy bajo tendría probabilidad casi cero de ser elegido. Esto es peligroso: el adversario podría darle pérdida baja (hacerlo bueno) y nunca lo detectaríamos. Para evitarlo, mezclamos los pesos con una componente uniforme:
$$p_i = (1 - \gamma) \cdot \frac{w_i}{\sum_j w_j} + \frac{\gamma}{K}$$
El parámetro $\gamma \in (0, 1)$ controla cuánta exploración forzamos. Con $\gamma = 0$, solo explotamos los pesos. Con $\gamma = 1$, exploramos uniformemente. El valor óptimo balancea ambos.
Pseudocódigo
función EXP3(K, T, γ):
# ── Inicialización ────────────────────────────────────
para i = 1, …, K:
w[i] ← 1 # [E1] pesos iniciales iguales
# ── Bucle principal ───────────────────────────────────
para t = 1, …, T:
# ── Calcular distribución de selección ───────────
W ← Σ_i w[i] # suma total de pesos
para i = 1, …, K:
p[i] ← (1 − γ) · w[i] / W + γ / K # [E2] mezcla: pesos + uniforme
# ── Seleccionar brazo y observar ─────────────────
A ← muestrear de Categorical(p)
ℓ_A ← OBSERVAR_PÉRDIDA(A) # solo vemos ℓ_{t,A}
# ── Estimar pérdidas por importance weighting ────
para i = 1, …, K:
si i == A:
ℓ̂[i] ← ℓ_A / p[i] # [E3] importance weighting
sino:
ℓ̂[i] ← 0 # no observamos los demás
# ── Actualizar pesos multiplicativamente ─────────
η ← γ / K # tasa de aprendizaje
para i = 1, …, K:
w[i] ← w[i] · exp(−η · ℓ̂[i]) # [E4] penalizar brazos con alta pérdida
retornar w
Los cuatro pasos clave
| Paso | Marcador | Operación | Intuición |
|---|---|---|---|
| Inicializar pesos | [E1] |
$w_i = 1$ para todo $i$ | Sin preferencia inicial |
| Mezclar probabilidades | [E2] |
$p_i = (1-\gamma)\frac{w_i}{\sum_j w_j} + \frac{\gamma}{K}$ | Explotar pesos pero garantizar exploración mínima |
| Importance weighting | [E3] |
$\hat{\ell}{t,i} = \frac{\ell \cdot \mathbb{1}[A_t = i]}{p_{t,i}}$ | Estimar pérdida corrigiendo sesgo de muestreo |
| Actualización multiplicativa | [E4] |
$w_i \leftarrow w_i \cdot \exp(-\eta \hat{\ell}_{t,i})$ | Reducir peso de brazos con alta pérdida estimada |
Parámetros
Con horizonte $T$ conocido, la elección óptima es:
$$\gamma = \eta = \sqrt{\frac{K \ln K}{T}}$$
Cuando $T$ es desconocido, se puede usar el truco del “doubling”: ejecutar EXP3 con $T=1, 2, 4, 8, \ldots$ y reiniciar pesos en cada fase.
6.5 Traza manual: 3 brazos, adversario cíclico
Consideremos un adversario que rota cuál brazo es bueno (pérdida baja) en un patrón cíclico. Esto es algo que UCB1 no puede manejar.
Patrón del adversario (pérdidas):
- Rondas 1, 4: brazo A bueno → $\ell = (0.1, 0.9, 0.9)$
- Rondas 2, 5: brazo B bueno → $\ell = (0.9, 0.1, 0.9)$
- Rondas 3, 6: brazo C bueno → $\ell = (0.9, 0.9, 0.1)$
Usamos $\gamma = 0.3$, $\eta = \gamma / K = 0.1$, seed=42.
| $t$ | $\ell_t$ | $w_A$ | $w_B$ | $w_C$ | $p_A$ | $p_B$ | $p_C$ | $A_t$ | $\ell_{t,A_t}$ | $\hat{\ell}_{A_t}$ | Actualización |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | (0.1, 0.9, 0.9) | 1.00 | 1.00 | 1.00 | 0.333 | 0.333 | 0.333 | C | 0.9 | 2.70 | $w_C \cdot e^{-0.27}$ |
| 2 | (0.9, 0.1, 0.9) | 1.00 | 1.00 | 0.76 | 0.353 | 0.353 | 0.294 | A | 0.9 | 2.55 | $w_A \cdot e^{-0.255}$ |
| 3 | (0.9, 0.9, 0.1) | 0.77 | 1.00 | 0.76 | 0.314 | 0.376 | 0.310 | B | 0.9 | 2.39 | $w_B \cdot e^{-0.239}$ |
| 4 | (0.1, 0.9, 0.9) | 0.77 | 0.79 | 0.76 | 0.332 | 0.338 | 0.330 | A | 0.1 | 0.30 | $w_A \cdot e^{-0.030}$ |
| 5 | (0.9, 0.1, 0.9) | 0.75 | 0.79 | 0.76 | 0.327 | 0.341 | 0.332 | B | 0.1 | 0.29 | $w_B \cdot e^{-0.029}$ |
| 6 | (0.9, 0.9, 0.1) | 0.75 | 0.77 | 0.76 | 0.330 | 0.337 | 0.334 | C | 0.1 | 0.30 | $w_C \cdot e^{-0.030}$ |
Observaciones:
- En $t=1$: pesos iguales → distribución uniforme. C es elegido (seed=42) y sufre pérdida 0.9. Su importance-weighted loss es $0.9 / 0.333 = 2.70$. El peso de C baja
- En $t=2$–$3$: el adversario castiga al brazo elegido, pero EXP3 distribuye sus elecciones — ningún brazo domina
- En $t=4$–$6$: los pesos se han estabilizado cerca de la uniformidad. Ahora el agente empieza a “atrapar” al brazo bueno de cada ronda
- Contraste con UCB1: UCB1 habría convergido a un solo brazo y el adversario lo castigaría ronda tras ronda con regret lineal
6.6 Garantía de regret
Teorema (Auer et al., 2002). EXP3 con parámetro $\gamma = \sqrt{K \ln K / T}$ satisface, para cualquier secuencia de pérdidas elegida por el adversario:
$$\mathbb{E}[R_T] \leq 2\sqrt{KT \ln K}$$
Interpretación
- El regret es $O(\sqrt{KT \ln K})$ — sublineal en $T$. El regret promedio por ronda $R_T / T \to 0$ cuando $T \to \infty$
- Comparado con el $O(\log T)$ de UCB1 en el caso estocástico, esto es significativamente peor. Es el precio de no asumir estocasticidad
- La cota vale para cualquier adversario — incluso el peor posible. No hay supuesto sobre la estructura de las pérdidas
- La dependencia $\sqrt{K}$ en $K$ es inevitable: más brazos implica más pérdida de información (solo observamos uno por ronda)
Optimalidad minimax
La cota inferior para bandidos adversariales es $\Omega(\sqrt{KT})$. EXP3 logra $O(\sqrt{KT \ln K})$ — óptimo salvo un factor $\sqrt{\ln K}$. El algoritmo EXP3-IX (Implicit eXploration) de Neu (2015) cierra esta brecha y logra $O(\sqrt{KT})$ exacto.
6.7 El espectro de supuestos
Los algoritmos de bandidos se ubican en un espectro según qué tan fuerte es su supuesto sobre el entorno:
| Supuesto | Algoritmos | Regret | Cuándo aplica |
|---|---|---|---|
| Estocástico fuerte (distribución conocida) | KL-UCB, Thompson | $O\left(\sum \frac{\Delta_i \log T}{\text{KL}(\mu_i, \mu^{∗})}\right)$ | Recompensas i.i.d., familia conocida |
| Estocástico (sub-Gaussiano) | UCB1, ε-greedy | $O(K \log T / \Delta)$ | Recompensas i.i.d., cotas de concentración |
| Adversarial | EXP3, EXP3-IX | $O(\sqrt{KT \ln K})$ | Sin supuestos sobre las pérdidas |
Observación clave: no hay almuerzo gratis. Los algoritmos estocásticos logran regret $O(\log T)$ — exponencialmente mejor que $O(\sqrt{T})$ — pero solo cuando su supuesto se cumple. Si el entorno es adversarial, su regret puede ser lineal. EXP3 es más conservador: garantiza $O(\sqrt{T})$ siempre, pero nunca logra $O(\log T)$ incluso si el entorno resulta ser estocástico.
Existe investigación activa en algoritmos “best-of-both-worlds” que logran $O(\log T)$ en entornos estocásticos y $O(\sqrt{T})$ en adversariales automáticamente — lo mejor de ambos mundos.
6.8 Guía práctica: ¿cuándo usar EXP3?
Usar EXP3 cuando:
- El entorno puede ser no estacionario o adversarial
- Hay competidores que reaccionan a tus decisiones
- Las recompensas dependen de factores externos impredecibles
- Necesitas garantías de peor caso sin supuestos distribucionales
Usar algoritmos estocásticos (UCB1, Thompson) cuando:
- Las recompensas son razonablemente estacionarias
- No hay adversario adaptativo
- Se necesita convergencia rápida ($O(\log T)$ vs $O(\sqrt{T})$)
- Hay información previa (prior bayesiano para Thompson)
Regla general: la mayoría de los problemas reales de A/B testing, recomendación y optimización de parámetros son más cercanos al caso estocástico. EXP3 es un seguro contra lo inesperado — su valor está en las garantías de peor caso, no en el rendimiento típico.
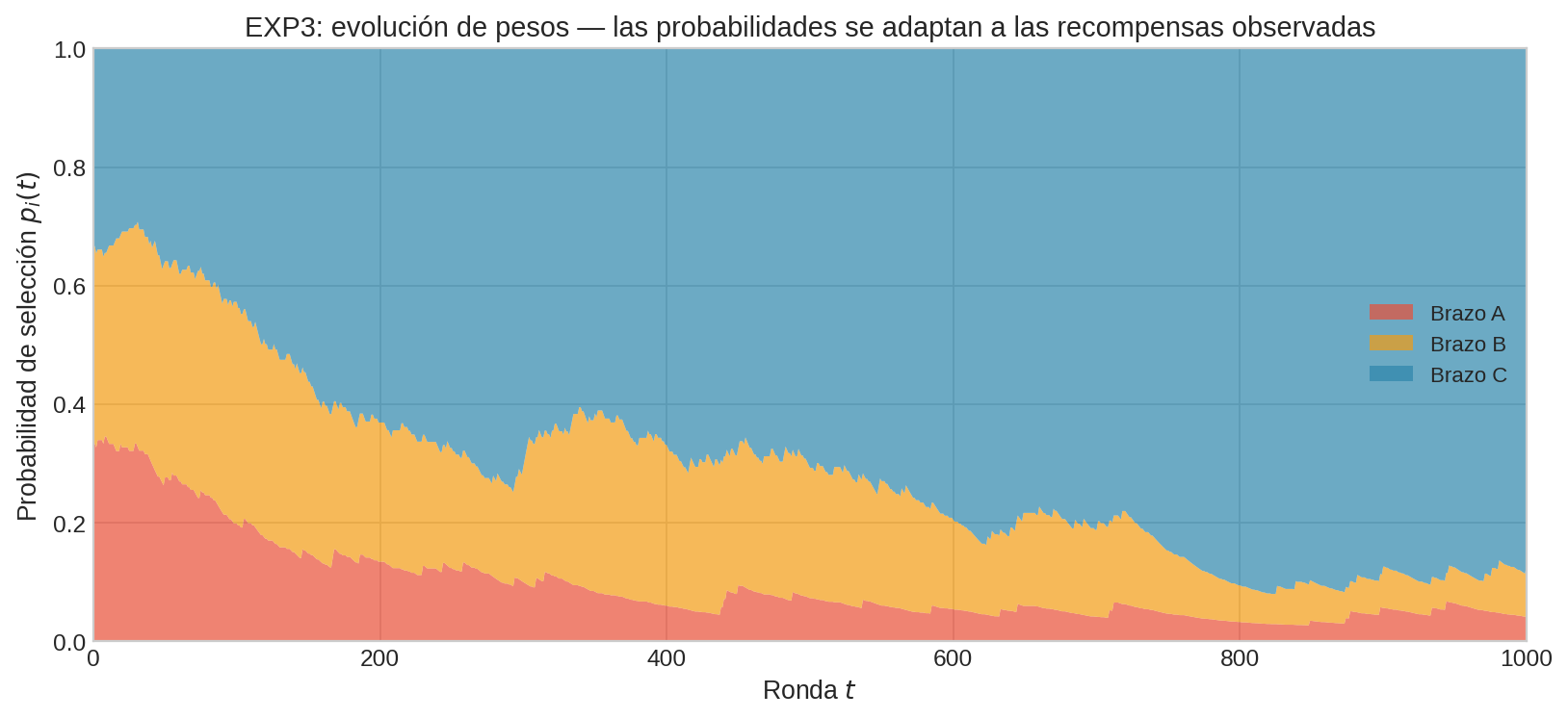
En la figura se observa cómo los pesos de EXP3 evolucionan: a diferencia de UCB1 o Thompson, las probabilidades nunca colapsan a un solo brazo. La componente uniforme $\gamma / K$ garantiza exploración perpetua.
Resumen
| Propiedad | EXP3 |
|---|---|
| Idea | Pesos multiplicativos + exploración uniforme + importance weighting |
| Fórmula | $p_i = (1-\gamma)\frac{w_i}{\sum w_j} + \frac{\gamma}{K}$; $w_i \leftarrow w_i \exp(-\eta \hat{\ell}_i)$ |
| Parámetros | $\gamma = \sqrt{K \ln K / T}$ (requiere conocer $T$) |
| Regret | $O(\sqrt{KT \ln K})$ — sublineal, minimax-óptimo (salvo $\sqrt{\ln K}$) |
| Ventaja | Garantías contra cualquier adversario; no asume estocasticidad |
| Desventaja | Regret $O(\sqrt{T})$ incluso en entornos estocásticos (vs $O(\log T)$) |
| Cuándo usar | Entornos no estacionarios, adversariales, o cuando se necesitan garantías de peor caso |
En la sección 17.7 veremos aplicaciones concretas de bandidos — A/B testing, sistemas de recomendación, redes de comunicación — y variantes que extienden el framework básico a problemas del mundo real.