17.7 — Aplicaciones y variantes
“In theory, there is no difference between theory and practice. In practice, there is.” — Jan L. A. van de Snepscheut
7.1 A/B Testing: bandidos en producción
La aplicación más directa de los bandidos multibrazo es el A/B testing — la práctica de comparar variantes de un producto para determinar cuál funciona mejor. La correspondencia es exacta:
| Concepto A/B Testing | Concepto Bandidos | Ejemplo |
|---|---|---|
| Variantes (A, B, C, …) | Brazos ($i = 1, \ldots, K$) | Dos diseños de botón de compra |
| Conversión (clic, compra, registro) | Recompensa $r_t \in {0, 1}$ | Usuario compra ($r=1$) o no ($r=0$) |
| Usuarios que llegan | Rondas $t = 1, \ldots, T$ | 10,000 visitantes por día |
| Tasa de conversión | Media del brazo $\mu_i$ | Botón rojo: $\mu_A = 0.03$; azul: $\mu_B = 0.05$ |
| Costo de oportunidad | Regret acumulado $R_T$ | Usuarios que vieron el peor diseño |
El enfoque tradicional
El A/B testing clásico funciona así:
- Dividir el tráfico 50/50 entre las variantes
- Esperar hasta alcanzar significancia estadística (típicamente $p < 0.05$)
- Desplegar la variante ganadora al 100% del tráfico
¿Cuáles son los problemas?
- Desperdicio de tráfico: durante toda la prueba, exactamente la mitad de los usuarios ve la variante inferior. Si la prueba dura 2 semanas con 100,000 usuarios, 50,000 reciben la peor experiencia
- Tamaño de muestra fijo: hay que decidir de antemano cuántos usuarios incluir. Si se mira el resultado antes de tiempo y se toma una decisión, se infla la tasa de falsos positivos (peeking problem)
- Sin adaptación: si una variante es claramente superior desde el día 3, el test sigue asignando 50/50 hasta completar el tamaño planificado
El enfoque adaptativo: Thompson Sampling
En lugar de asignación fija, usamos Thompson Sampling para decidir qué variante mostrar a cada usuario:
- Mantener un posterior $\text{Beta}(\alpha_i, \beta_i)$ para cada variante
- Cuando llega un usuario, muestrear $\theta_i \sim \text{Beta}(\alpha_i, \beta_i)$ para cada variante
- Mostrar la variante con mayor $\theta_i$
- Si el usuario convierte: $\alpha_i \leftarrow \alpha_i + 1$; si no: $\beta_i \leftarrow \beta_i + 1$
Beneficios:
- Reduce el regret durante la prueba: conforme se acumula evidencia, más tráfico va a la variante superior. Si $\mu_B \gg \mu_A$, rápidamente ~90% del tráfico irá a B
- Adapta a comportamiento no estacionario: si las preferencias de los usuarios cambian (por temporada, día de la semana), el posterior se ajusta
- Sin tamaño de muestra fijo: no hay compromiso previo — se puede monitorear continuamente sin inflar falsos positivos (el problema de peeking no aplica de la misma forma)
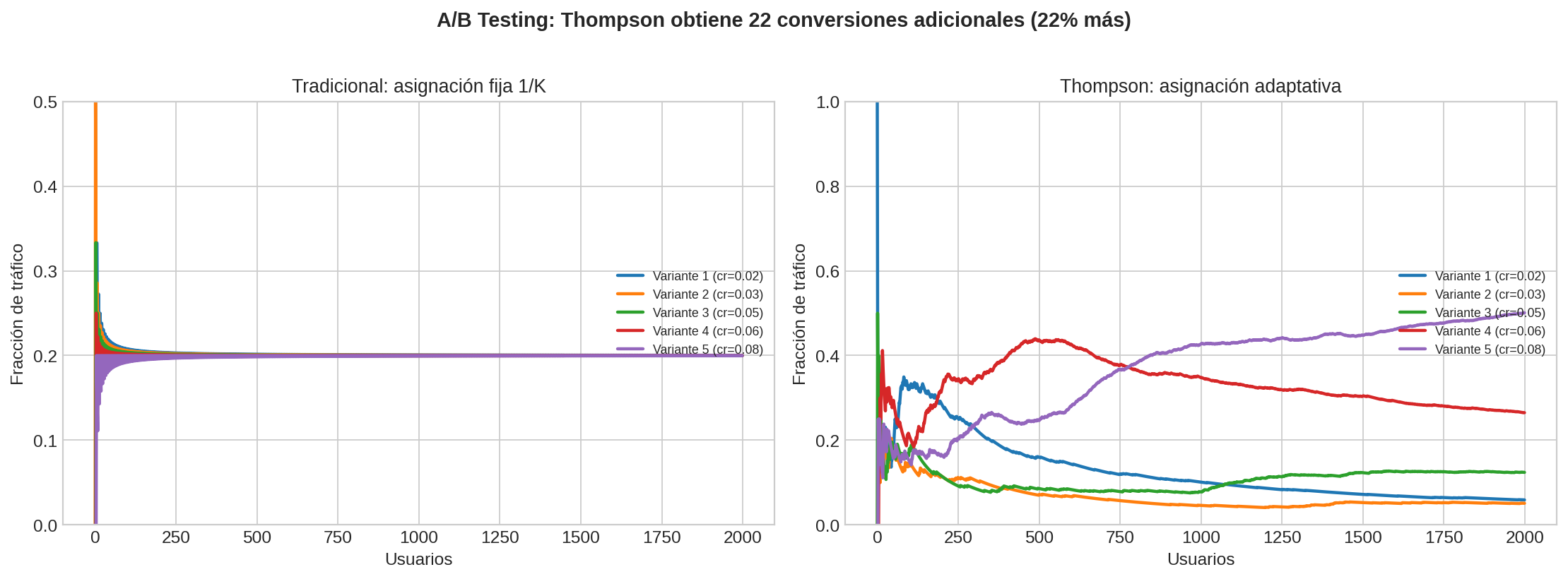
La figura muestra la diferencia fundamental: en el enfoque tradicional, la asignación es constante (50/50) durante toda la prueba. En el enfoque adaptativo con Thompson Sampling, la asignación converge hacia la variante con mayor tasa de conversión, reduciendo la cantidad de usuarios expuestos al diseño inferior.
Consideraciones prácticas
| Aspecto | Recomendación |
|---|---|
| Muestra mínima | Asignar al menos $\sim$100 observaciones por variante antes de que la adaptación domine, para evitar convergencia prematura por ruido |
| Cuándo declarar ganador | Cuando $P(\mu_A > \mu_B \mid \text{datos}) > 0.95$ (calculable directamente de los posteriores Beta) |
| Restricciones regulatorias | Algunos sectores (finanzas, salud) requieren aleatorización fija por ley — los bandidos no siempre son aplicables |
| Múltiples métricas | Conversión inmediata vs retención a 30 días: la recompensa debe capturar el objetivo real, no un proxy |
Empresas como Google, Netflix, Microsoft y Spotify usan variantes de bandidos para optimización continua de sus productos. Google reportó que en 2010 realizó más de 7,000 A/B tests solo para el buscador — muchos de ellos con asignación adaptativa.
7.2 Ensayos clínicos: la dimensión ética
En un ensayo clínico, cada “brazo” es un tratamiento y cada “recompensa” es la recuperación (o no) de un paciente. La estructura matemática es idéntica al A/B testing, pero las consecuencias son radicalmente diferentes: cada paciente asignado al tratamiento inferior sufre un daño real.
El enfoque tradicional
Los ensayos clásicos (Fase I/II/III) usan asignación fija — típicamente 1:1 entre tratamiento y control. Esto tiene justificación estadística (máxima potencia para detectar diferencias) pero un costo humano: si el tratamiento es claramente superior, la mitad de los pacientes recibe el control hasta que el ensayo termina.
La alternativa adaptativa
Los ensayos adaptativos usan Thompson Sampling (u otros algoritmos de bandidos) para asignar más pacientes al tratamiento que está mostrando mejores resultados. La idea es la misma que en A/B testing, pero con una motivación ética directa: minimizar el número de pacientes que reciben un tratamiento inferior.
Caso real: REMAP-CAP durante COVID-19. El ensayo REMAP-CAP (Randomized, Embedded, Multifactorial Adaptive Platform for Community-Acquired Pneumonia) usó aleatorización adaptativa durante la pandemia de COVID-19. Conforme se acumulaba evidencia sobre la efectividad de distintos tratamientos (corticosteroides, antivirales, anticoagulantes), el ensayo ajustaba automáticamente la probabilidad de asignación. Esto permitió identificar tratamientos efectivos más rápido que un ensayo tradicional de asignación fija, y redujo el número de pacientes asignados a tratamientos que se mostraban inferiores.
La tensión fundamental
| Objetivo | Favorece |
|---|---|
| Bienestar del paciente | Asignación adaptativa (más pacientes al mejor tratamiento) |
| Validez estadística | Asignación fija (potencia máxima, sin sesgos de asignación) |
| Aceptación regulatoria | Asignación fija (la FDA y la EMA tienen protocolos establecidos) |
| Velocidad de conclusión | Asignación adaptativa (puede alcanzar significancia antes) |
No hay una respuesta simple. Los reguladores médicos aceptan cada vez más los diseños adaptativos, pero con restricciones. La FDA publicó en 2019 una guía específica para ensayos adaptativos, reconociendo su potencial pero exigiendo transparencia en las reglas de adaptación.
7.3 Publicidad y sistemas de recomendación
Publicidad en línea
Cada vez que un usuario visita una página web, el sistema debe decidir qué anuncio mostrar. Cada anuncio es un brazo; el clic del usuario es la recompensa ($r = 1$ si hace clic, $r = 0$ si no). El objetivo: maximizar la tasa de clics (CTR, click-through rate) acumulada.
Empresas como Google Ads, Meta y Amazon enfrentan este problema a una escala masiva: millones de anuncios posibles, miles de millones de impresiones por día. A esta escala, la formulación básica de $K$ brazos independientes es insuficiente — se necesitan las variantes que veremos en la sección 7.4.
Sistemas de recomendación
Netflix, Spotify, YouTube y otros sistemas de recomendación enfrentan un problema análogo: ¿qué contenido recomendar a un usuario? Cada recomendación es una acción; el engagement del usuario (clic, tiempo de visualización, valoración) es la recompensa.
Los desafíos específicos incluyen:
- Millones de brazos: Netflix tiene miles de títulos; YouTube, miles de millones de videos. Las soluciones clásicas ($K$ brazos independientes) no escalan
- Cold-start: ¿cómo recomendar un contenido nuevo del que no tenemos datos? Es el equivalente a un brazo sin observaciones
- Contexto: la mejor recomendación depende del usuario, la hora, el dispositivo, el historial. Esto lleva a los bandidos contextuales (sección 7.4)
7.4 Más allá del bandido clásico: variantes
El problema de $K$ brazos con recompensas i.i.d. que estudiamos en este módulo es el caso base. En la práctica, muchas aplicaciones requieren extensiones. La siguiente tabla presenta las variantes más importantes:
| Variante | Idea clave | Algoritmo(s) | Caso de uso | Conexión en el curso |
|---|---|---|---|---|
| Bandidos contextuales | La recompensa depende de un vector de contexto $x_t$ (features del usuario, del item, etc.). El agente aprende $\mu_i(x)$ en lugar de $\mu_i$ | LinUCB, Thompson contextual | Recomendaciones personalizadas, publicidad dirigida | Módulo 08 (predicción) — regresión como modelo de recompensa |
| Bandidos no estacionarios | Las distribuciones $\nu_i$ cambian con el tiempo. Las observaciones recientes importan más | Discounted UCB, Sliding-window UCB, EXP3.S | Precios dinámicos, preferencias cambiantes de usuarios | Sección 17.6 (EXP3 para el caso adversarial) |
| Bandidos combinatoriales | El agente selecciona un subconjunto de brazos (“super-brazo”) en cada ronda | CUCB, Thompson combinatorial | Ruteo en redes, selección de features, asignación de recursos | — |
| Identificación del mejor brazo | El objetivo es identificar el brazo óptimo con alta probabilidad, no minimizar regret. Exploración pura | Successive Elimination, LUCB | Ajuste de hiperparámetros, A/B testing (fase de exploración) | — |
| Optimización bayesiana | Espacio continuo de brazos; se usa un Gaussian Process como modelo del posterior | GP-UCB, Expected Improvement | Optimización de hiperparámetros, diseño experimental | Módulo 07 (optimización) — búsqueda en espacios continuos |
| Bandidos de duelo | Solo se observan comparaciones por pares (no recompensas absolutas): “¿A es mejor que B?” | RUCB, DTS (Double Thompson) | Ranking, aprendizaje de preferencias | — |
| Bandidos inquietos (restless) | Los brazos evolucionan incluso cuando no se jalan. El estado de cada brazo cambia en cada ronda | Whittle index policy | Asignación de canales, scheduling de sensores, mantenimiento predictivo | — |
Cada variante merece un estudio propio. Lo importante para este curso es reconocer que el problema fundamental — balancear exploración y explotación bajo incertidumbre — aparece en formas cada vez más complejas, y las ideas centrales (optimismo, muestreo bayesiano, asignación basada en pesos exponenciales) se adaptan a cada caso.
7.5 Hacia adelante: UCT y árboles de búsqueda Monte Carlo
Una de las aplicaciones más impactantes de UCB1 no involucra bandidos per se, sino árboles de juego. El algoritmo UCT (Upper Confidence bounds applied to Trees) — propuesto por Kocsis y Szepesvári en 2006 — fue un ingrediente clave en la revolución de AlphaGo.
La idea es tratar cada nodo de un árbol de búsqueda como un problema de bandidos independiente:
- Las acciones disponibles en un nodo son los brazos
- La recompensa de un brazo es el resultado de una simulación aleatoria (rollout) desde el nodo hijo
- La fórmula de selección es exactamente UCB1:
$$\text{UCT}(v) = \bar{X}_v + c\sqrt{\frac{\ln N(\text{parent})}{N(v)}}$$
donde $\bar{X}_v$ es la recompensa media de las simulaciones que pasaron por el nodo $v$, $N(v)$ es el número de visitas al nodo $v$, y $N(\text{parent})$ es el número de visitas al nodo padre.
El ciclo de Monte Carlo Tree Search (MCTS) repite cuatro fases: selección (bajar por el árbol usando UCT), expansión (añadir un nodo nuevo), simulación (rollout aleatorio hasta un estado terminal), y retropropagación (actualizar las estadísticas de todos los nodos visitados).
Esta conexión es profunda: en el Módulo 15 (búsqueda adversarial) vimos minimax y poda alfa-beta como métodos exactos para árboles de juego. MCTS con UCT es la alternativa aproximada que escala a juegos donde la búsqueda exhaustiva es imposible — como Go, donde el factor de ramificación es ~250. Los bandidos multibrazo proporcionan la teoría que fundamenta la fase de selección.
Este tema se desarrollará en un módulo futuro dedicado a MCTS.
Resumen del módulo
A lo largo de este módulo recorrimos el problema del bandido multibrazo desde sus fundamentos hasta sus aplicaciones:
| Sección | Tema | Idea central |
|---|---|---|
| 17.1 | El dilema | Exploración vs explotación: aprender y decidir simultáneamente |
| 17.2 | $\varepsilon$-Greedy | La solución más simple: explorar al azar con probabilidad $\varepsilon$ |
| 17.3 | UCB1 | Optimismo ante la incertidumbre: explorar donde la cota superior es alta |
| 17.4 | Thompson Sampling | El enfoque bayesiano: muestrear del posterior y actuar según la muestra |
| 17.5 | Comparación | Ningún algoritmo domina universalmente; cada uno tiene su nicho |
| 17.6 | EXP3 | El caso adversarial: pesos exponenciales sin asumir distribuciones fijas |
| 17.7 | Aplicaciones y variantes | Del modelo a la práctica: A/B testing, ensayos clínicos, MCTS |
Las tres ideas fundamentales que recorren todo el módulo son:
- El regret como métrica: medir el costo acumulado de no saber cuál es la mejor opción, en lugar de simplemente medir la recompensa
- La cota inferior de Lai-Robbins: ningún algoritmo puede tener regret mejor que $\Omega(\log T)$ — y UCB1 y Thompson Sampling alcanzan este orden
- La transición de exploración a explotación: todo buen algoritmo explora mucho al inicio y explota al final, pero los mecanismos varían — aleatoriedad ($\varepsilon$-greedy), optimismo (UCB1), incertidumbre bayesiana (Thompson), o pesos adaptativos (EXP3)
Estos conceptos no son exclusivos de los bandidos. Aparecen en aprendizaje por refuerzo (donde el agente explora un espacio de estados), en optimización bayesiana (donde la función objetivo es costosa de evaluar), y en árboles de búsqueda Monte Carlo (donde la exploración del árbol debe balancearse con la explotación del conocimiento acumulado). El bandido multibrazo es el laboratorio mínimo donde todas estas ideas se ven con claridad.