| Notebook | Colab |
|---|---|
| Notebook 02 — MCTS paso a paso |
18.3 — MCTS: las cuatro fases
“MCTS does not require a position evaluation function. Instead, it estimates position values using random simulations.” — Cameron Browne et al. (2012)
En la sección anterior vimos que los rollouts puros tienen dos problemas: no reutilizan información y no enfocan el esfuerzo. MCTS resuelve ambos construyendo un árbol de forma incremental y almacenando estadísticas en cada nodo. En vez de evaluar cada posición desde cero con $N$ rollouts, MCTS acumula experiencia: cada simulación contribuye a la comprensión global del árbol.
1. Intuición
Imagina que estás en la raíz del árbol y tienes un presupuesto de 1000 simulaciones. Podrías repartirlas equitativamente (200 por cada una de las 5 acciones legales), pero eso desperdicia rollouts en acciones claramente malas. Mejor: empieza probando todas, y conforme acumulas evidencia, dedica más simulaciones a las acciones prometedoras.
MCTS hace exactamente esto. Mantiene un árbol parcial — mucho más pequeño que el árbol completo del juego — y en cada iteración:
- Baja por el árbol usando las estadísticas acumuladas
- Expande el árbol añadiendo un nodo nuevo
- Simula una partida aleatoria desde el nodo nuevo
- Sube actualizando las estadísticas de todos los nodos visitados
Después de muchas iteraciones, la raíz tiene buenas estadísticas sobre cada acción, y elegimos la más visitada.
2. Los datos en cada nodo
Cada nodo $v$ del árbol almacena dos números:
| Dato | Símbolo | Significado |
|---|---|---|
| Visitas | $N(v)$ | Cuántas simulaciones han pasado por este nodo |
| Valor acumulado | $Q(v)$ | Suma de los resultados ($+1$ o $-1$) de esas simulaciones |
La tasa de éxito del nodo es $\bar{X}_v = Q(v) / N(v)$ — el promedio de los resultados de las simulaciones que pasaron por $v$. Es el estimador Monte Carlo del módulo 12, pero ahora cada nodo lleva el suyo.
3. Las cuatro fases
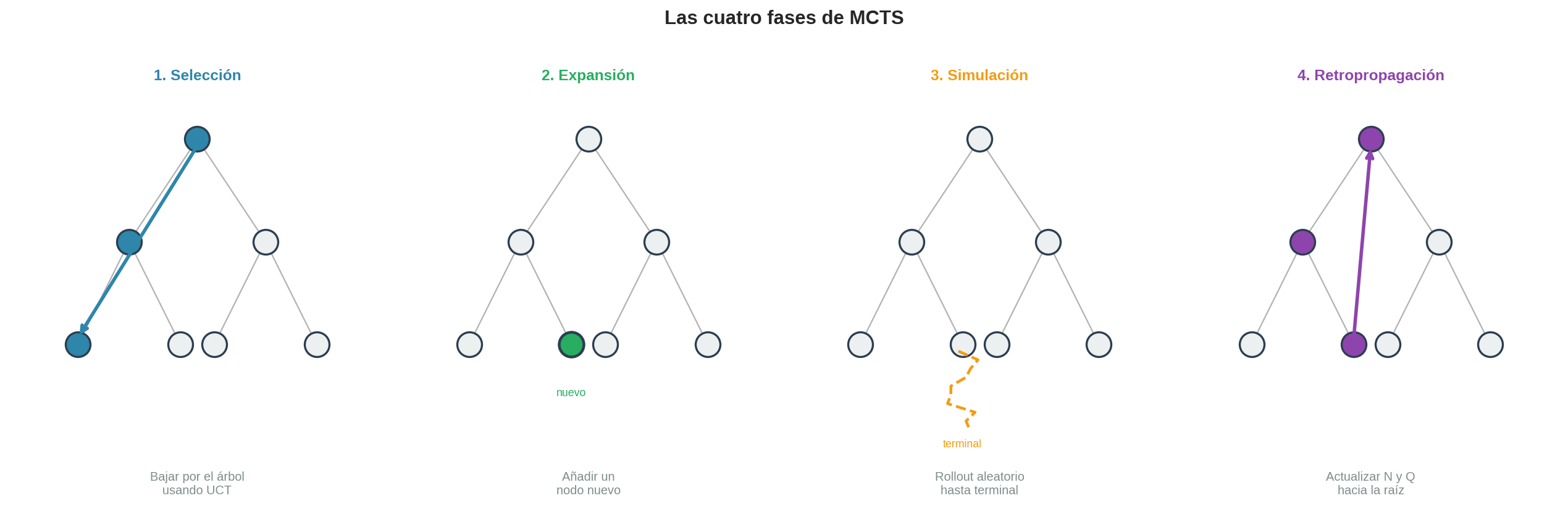
Fase 1: Selección [M1]
Desde la raíz, baja por el árbol eligiendo en cada nodo interno el hijo con mejor puntuación según alguna política de selección. En esta sección usaremos la política más simple: elegir el hijo con mayor tasa de éxito $Q(v)/N(v)$. (En §18.4 la reemplazaremos por UCT.)
La selección termina cuando llegas a un nodo que tiene hijos no explorados — acciones legales que aún no están en el árbol.
Fase 2: Expansión [M2]
Añade un nodo hijo al árbol para una de las acciones no exploradas. El nuevo nodo empieza con $N = 0$ y $Q = 0$.
Fase 3: Simulación [M3]
Desde el nodo recién añadido, juega una partida aleatoria completa hasta un estado terminal. Este es exactamente el ROLLOUT de §18.1 — movimientos uniformemente aleatorios hasta que alguien gana.
Fase 4: Retropropagación [M4]
Sube desde el nodo nuevo hasta la raíz, actualizando cada nodo en el camino:
- $N(v) \leftarrow N(v) + 1$ (una visita más)
- $Q(v) \leftarrow Q(v) + \text{resultado}$ (sumar $+1$ o $-1$ según quién ganó, desde la perspectiva del jugador en $v$)
4. En lenguaje natural
El algoritmo completo:
- Repetir $M$ veces (presupuesto de iteraciones):
- Seleccionar: bajar por el árbol desde la raíz, en cada nodo elegir el hijo con mejor $Q/N$, hasta encontrar un nodo con hijos no expandidos
- Expandir: añadir un hijo nuevo al árbol
- Simular: jugar al azar desde el hijo nuevo hasta el final
- Retropropagar: actualizar $N$ y $Q$ de todos los nodos en el camino
- Elegir la acción de la raíz con mayor $N$ (no mayor $Q/N$ — la más visitada es más robusta)
¿Por qué elegir por $N$ y no por $Q/N$? El nodo más visitado es aquel donde MCTS invirtió más tiempo — señal de que lo considera prometedor. Un nodo con $Q/N$ alto pero pocas visitas podría ser un artefacto de pocos rollouts.
5. Pseudocódigo
# ── MCTS ─────────────────────────────────────────────────────────────────────
# Ejecuta M iteraciones de Monte Carlo Tree Search.
# Retorna la mejor acción desde el estado actual.
#
# Cada nodo v del árbol almacena:
# v.estado : estado del juego en ese nodo
# v.padre : nodo padre (None para la raíz)
# v.hijos : diccionario {acción: nodo_hijo}
# v.N : número de visitas
# v.Q : suma de resultados (desde perspectiva del jugador en v)
# v.no_expandidos : acciones legales que aún no tienen nodo hijo
función MCTS(juego, estado, M):
raíz ← crear_nodo(estado)
para i = 1, …, M:
# ── [M1] Selección ───────────────────────────────────────────────
v ← raíz
mientras v.no_expandidos está vacío y v.hijos no está vacío:
v ← MEJOR_HIJO(v) # baja por el árbol
# ── [M2] Expansión ───────────────────────────────────────────────
si v.no_expandidos no está vacío:
a ← sacar_uno(v.no_expandidos) # elige una acción no explorada
hijo ← crear_nodo(juego.resultado(v.estado, a))
hijo.padre ← v
v.hijos[a] ← hijo
v ← hijo # nos movemos al nodo nuevo
# ── [M3] Simulación ─────────────────────────────────────────────
resultado ← ROLLOUT(juego, v.estado, juego.turno(raíz.estado))
# ── [M4] Retropropagación ────────────────────────────────────────
mientras v ≠ None:
v.N ← v.N + 1
v.Q ← v.Q + resultado_para(v, resultado) # +1 o -1 según perspectiva
v ← v.padre
retornar acción en raíz.hijos con mayor raíz.hijos[acción].N
# ── MEJOR_HIJO (política simple) ────────────────────────────────────────────
# Elige el hijo con mayor tasa de éxito.
# En §18.4 reemplazaremos esto por UCT.
función MEJOR_HIJO(v):
retornar argmax sobre hijo en v.hijos.valores() de hijo.Q / hijo.N
Marcadores clave:
| Marcador | Fase | Qué hace |
|---|---|---|
[M1] |
Selección | Baja por el árbol usando la política (aquí: mayor $Q/N$) |
[M2] |
Expansión | Añade un nodo nuevo al árbol |
[M3] |
Simulación | Rollout aleatorio desde el nodo nuevo |
[M4] |
Retropropagación | Actualiza $N$ y $Q$ hacia arriba hasta la raíz |
6. Implementación en Python
import math, random, copy
class MCTSNode:
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = {} # {action: MCTSNode}
self.N = 0 # visitas
self.Q = 0.0 # valor acumulado
self.unexpanded = state.actions() # acciones sin nodo hijo
def mcts(game_state, iterations, player):
root = MCTSNode(game_state)
for _ in range(iterations):
node = root
# [M1] Selección
while not node.unexpanded and node.children:
node = max(node.children.values(), key=lambda c: c.Q / c.N)
# [M2] Expansión
if node.unexpanded:
action = node.unexpanded.pop()
child_state = node.state.result(action)
child = MCTSNode(child_state, parent=node)
node.children[action] = child
node = child
# [M3] Simulación (rollout)
sim_state = copy.deepcopy(node.state)
while not sim_state.is_terminal():
sim_state = sim_state.result(random.choice(sim_state.actions()))
reward = sim_state.utility(player)
# [M4] Retropropagación
while node is not None:
node.N += 1
node.Q += reward
node = node.parent
# Elegir acción más visitada
return max(root.children, key=lambda a: root.children[a].N)
Nota sobre la perspectiva: en esta implementación simplificada, reward siempre se mide desde la perspectiva de player (el jugador de la raíz). En la versión UCT (§18.4) ajustaremos esto para manejar la alternancia de turnos correctamente.
7. Traza paso a paso: Hex 3×3
Consideremos un tablero Hex 3×3 vacío. Le toca a Negro. MCTS debe decidir dónde jugar.
Las 9 acciones legales son las celdas $(0,0)$ a $(2,2)$. Tracemos las primeras iteraciones:
| # | Fase | Nodo | Acción | Rollout | $N$ | $Q$ | Nota |
|---|---|---|---|---|---|---|---|
| 1 | M2 | raíz | $(1,1)$ | — | — | — | Expande centro |
| 1 | M3 | $(1,1)$ | — | Negro gana | — | — | Rollout aleatorio |
| 1 | M4 | $(1,1)$→raíz | — | — | 1, 1 | +1, +1 | Actualiza ambos |
| 2 | M2 | raíz | $(0,0)$ | — | — | — | Expande esquina |
| 2 | M3 | $(0,0)$ | — | Blanco gana | — | — | Rollout aleatorio |
| 2 | M4 | $(0,0)$→raíz | — | — | 1, 2 | −1, 0 | $(0,0)$: N=1,Q=−1; raíz: N=2,Q=0 |
| 3 | M2 | raíz | $(0,1)$ | — | — | — | Expande otro |
| 3 | M3 | $(0,1)$ | — | Negro gana | — | — | Rollout |
| 3 | M4 | $(0,1)$→raíz | — | — | 1, 3 | +1, +1 | raíz: N=3,Q=+1 |
| 4 | M2 | raíz | $(0,2)$ | — | — | — | Expande |
| 4 | M3 | $(0,2)$ | — | Negro gana | — | — | Rollout |
| 4 | M4 | $(0,2)$→raíz | — | — | 1, 4 | +1, +2 | |
| 5 | M2 | raíz | $(1,0)$ | — | — | — | Expande |
| 5 | M3 | $(1,0)$ | — | Blanco gana | — | — | Rollout |
| 5 | M4 | $(1,0)$→raíz | — | — | 1, 5 | −1, +1 |
Después de 9 iteraciones (una por cada acción legal), todos los hijos de la raíz tienen $N = 1$. A partir de la iteración 10, [M1] empieza a funcionar: selecciona el hijo con mayor $Q/N$ y expande su subárbol.
| # | Fase | Nodo | Acción | Rollout | Nota |
|---|---|---|---|---|---|
| 10 | M1 | raíz→$(1,1)$ | — | — | Selecciona $(1,1)$ (Q/N = 1.0) |
| 10 | M2 | $(1,1)$ | Blanco en $(0,0)$ | — | Expande hijo de $(1,1)$ |
| 10 | M3 | $(1,1)→(0,0)_B$ | — | Negro gana | Rollout desde profundidad 2 |
| 10 | M4 | subida | — | — | Actualiza 3 nodos |
Después de 50 iteraciones, el árbol se ve así:
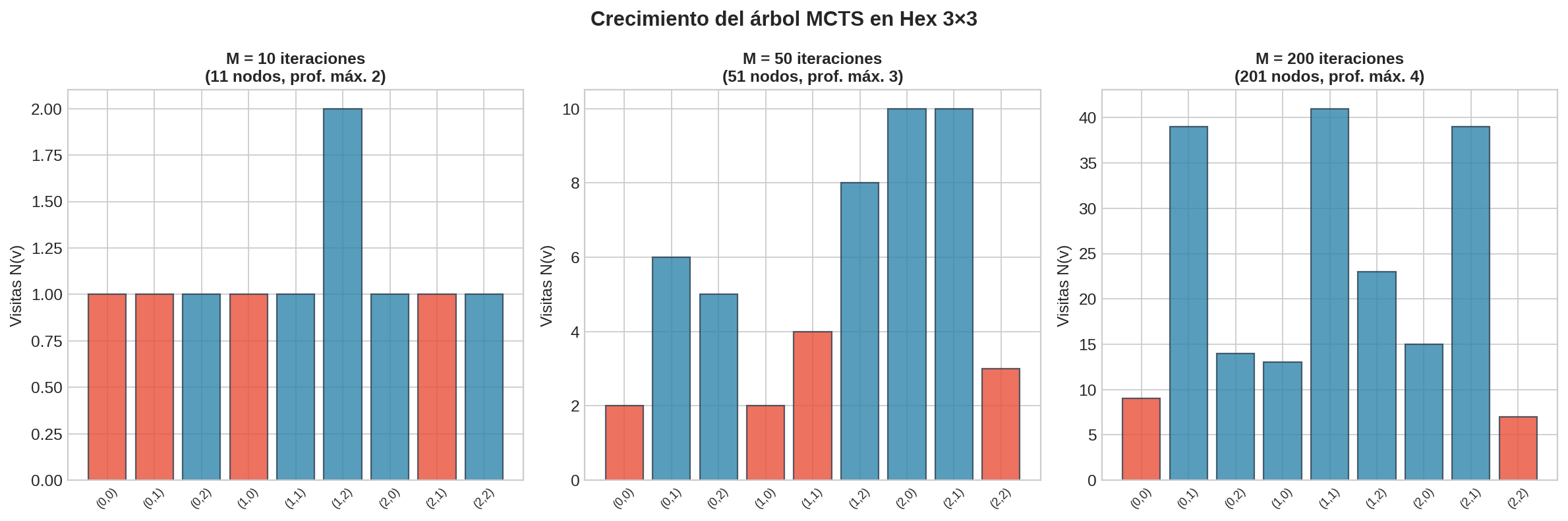
El árbol crece de forma asimétrica: las ramas con mejores resultados reciben más visitas y se expanden más profundamente. Las ramas con malos resultados quedan poco desarrolladas — MCTS no pierde tiempo explorándolas en detalle.
8. Propiedades de MCTS
| Propiedad | MCTS | Minimax (§15.3) |
|---|---|---|
| Exploración | Selectiva (más donde hay potencial) | Uniforme (visita todo) |
| Requiere eval(s) | No — usa rollouts | No (exacto) o Sí (con límite) |
| Anytime | Sí — más iteraciones = mejor resultado | No — necesita completar la búsqueda |
| Asintóticamente óptimo | Sí (con UCT, §18.4) | Sí (por definición) |
| Complejidad por iteración | $O(m)$ (bajar + subir por el camino) | — |
| Memoria | $O(\text{nodos expandidos})$ | $O(b \cdot m)$ |
| Dominio necesario | Solo las reglas | Solo las reglas (o + eval) |
La propiedad anytime es especialmente valiosa en la práctica: si tienes 100ms para decidir, MCTS da una respuesta razonable. Si tienes 10 segundos, da una respuesta mucho mejor. Minimax, en cambio, no retorna nada hasta que completa la búsqueda (o una profundidad completa).
9. ¿Qué falta?
La política de selección MEJOR_HIJO que usamos (mayor $Q/N$) tiene un problema fundamental: es pura explotación. Una vez que un nodo tiene buen $Q/N$, lo visitamos repetidamente — y podemos perder un nodo que con más rollouts sería aún mejor.
Esto es exactamente el dilema de exploración vs explotación del módulo 17. La solución fue UCB1: añadir un término de exploración que favorece nodos poco visitados. En la siguiente sección aplicaremos esa misma idea a MCTS — obteniendo UCT.
Anterior → Hex: el juego | Siguiente → UCT: la conexión con bandidos