| Notebook | Colab |
|---|---|
| Notebook 03 — UCT y experimentos |
18.4 — UCT: la conexión con bandidos
“The crucial idea is to treat each node of the search tree as an independent bandit problem.” — Levente Kocsis & Csaba Szepesvári (2006)
En §18.3 usamos una política de selección simple: elegir el hijo con mayor $Q/N$. Eso es pura explotación — repite lo que ya funcionó, sin explorar alternativas. En el módulo 17 aprendimos que eso es un error: un brazo con pocos jalones puede tener una media real superior a la estimada. La solución fue UCB1: añadir un bonus de exploración a los brazos poco visitados.
UCT (Upper Confidence bounds applied to Trees) aplica exactamente la misma idea a los nodos del árbol de MCTS. Propuesto por Kocsis y Szepesvári en 2006, fue un ingrediente clave en la revolución de AlphaGo.
1. Cada nodo es un bandido
La observación central es que cada nodo interno del árbol de MCTS es un problema de bandidos independiente:
| Concepto bandidos (§17) | Concepto en MCTS |
|---|---|
| Brazos $i = 1, \ldots, K$ | Acciones legales desde el nodo |
| Jalar el brazo $i$ | Elegir la acción $i$ y expandir/simular |
| Recompensa $r_t$ | Resultado del rollout ($+1$ o $-1$) |
| Jalones $N_i(t)$ | Visitas al hijo $N(v_i)$ |
| Media estimada $\hat\mu_i$ | Tasa de éxito $Q(v_i)/N(v_i)$ |
| Regret | Rollouts invertidos en acciones subóptimas |
En el módulo 17, UCB1 resolvió este problema con la fórmula:
$$A_t = \arg\max_i \left[ \hat\mu_i(t) + \sqrt{\frac{2 \ln t}{N_i(t)}} \right]$$
UCT usa la misma estructura para elegir qué hijo visitar.
2. La fórmula UCT
En cada nodo durante la fase de selección [M1], elegimos el hijo $v$ que maximiza:
$$\text{UCT}(v) = \underbrace{\frac{Q(v)}{N(v)}}{\text{explotación}} + \underbrace{c \sqrt{\frac{\ln N(\text{padre})}{N(v)}}}{\text{exploración}}$$
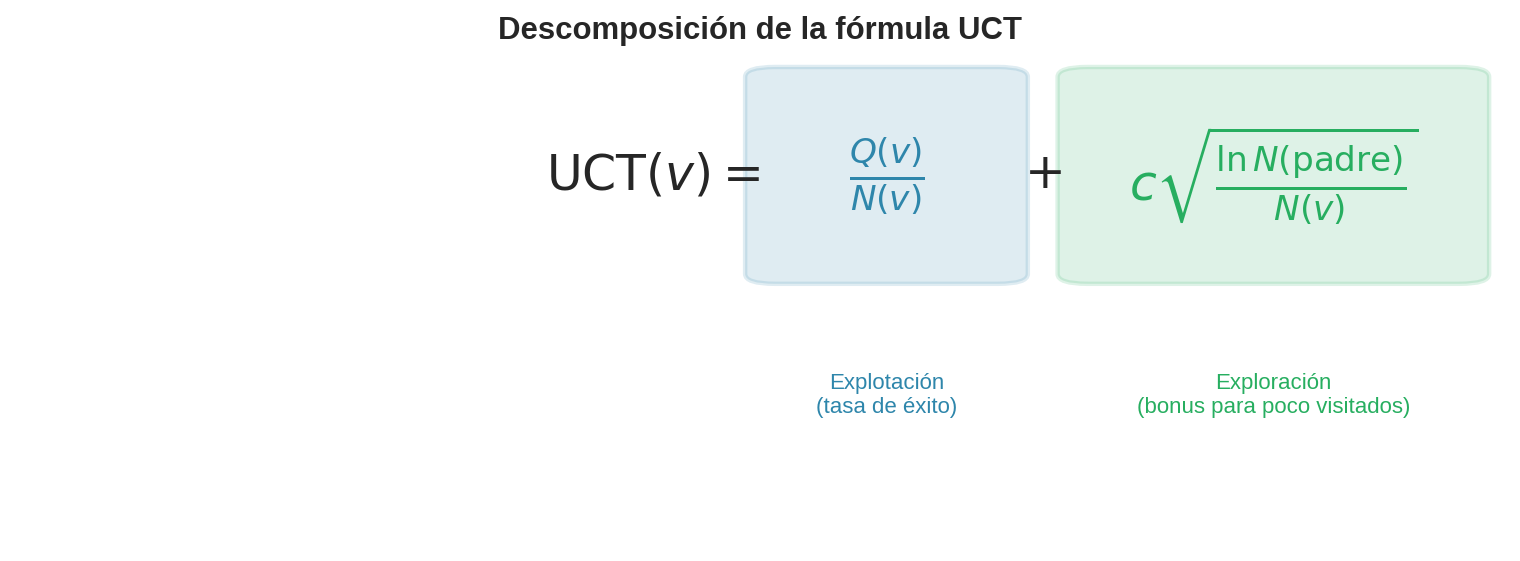
Término de explotación $Q(v)/N(v)$: la tasa de éxito promedio del nodo. Favorece nodos con buenos resultados — los que han ganado más rollouts.
Término de exploración $c\sqrt{\ln N(\text{padre}) / N(v)}$: crece cuando $N(v)$ es pequeño relativo a $N(\text{padre})$. Un hijo que ha sido poco visitado recibe un bonus que lo hace más atractivo. El logaritmo en el numerador asegura que la exploración nunca se detiene completamente, pero crece cada vez más lento.
La constante $c$: controla el balance entre explotación y exploración. Es exactamente el mismo rol que $\varepsilon$ jugaba en $\varepsilon$-greedy (§17.2) — pero de forma más elegante:
| Valor de $c$ | Efecto |
|---|---|
| $c \to 0$ | Pura explotación (como $\varepsilon = 0$): siempre elige el mejor $Q/N$ |
| $c = \sqrt{2}$ | Valor teórico óptimo (derivado de Hoeffding, §17.3) |
| $c$ grande | Exceso de exploración: visita todos los nodos casi por igual |
En la práctica, $c$ se ajusta empíricamente. Para recompensas en $[0, 1]$, valores de $c$ entre 0.5 y 1.5 suelen funcionar bien.
3. Comparación con UCB1
Pongamos las fórmulas lado a lado para ver que son la misma idea:
| UCB1 (§17.3) | UCT (§18.4) | |
|---|---|---|
| Fórmula | $\hat\mu_i + \sqrt{\frac{2 \ln t}{N_i(t)}}$ | $\frac{Q(v)}{N(v)} + c\sqrt{\frac{\ln N(\text{padre})}{N(v)}}$ |
| Media estimada | $\hat\mu_i = \frac{1}{N_i}\sum r$ | $\frac{Q(v)}{N(v)}$ |
| Exploración | $\sqrt{\frac{2 \ln t}{N_i(t)}}$ | $c\sqrt{\frac{\ln N(\text{padre})}{N(v)}}$ |
| $t$ (tiempo total) | Rondas totales | $N(\text{padre})$ = visitas al nodo padre |
| $N_i$ (visitas) | Jalones del brazo $i$ | Visitas al hijo $v$ |
La única diferencia es que en bandidos hay un solo nivel ($t$ rondas, $K$ brazos), mientras que en MCTS hay muchos niveles — cada nodo es su propio bandido, con su propio “reloj” $N(\text{padre})$.
En §17.3 demostramos que UCB1 alcanza regret $O(\sqrt{K \ln T})$. Esto es exactamente por qué UCT explora eficientemente: en cada nodo, el regret de la selección crece solo logarítmicamente.
4. Pseudocódigo: solo cambia [M1]
El cambio de MCTS vanilla a MCTS con UCT es mínimo — solo la función MEJOR_HIJO:
# ── MEJOR_HIJO_UCT ───────────────────────────────────────────────────────────
# Reemplaza MEJOR_HIJO de §18.3.
# La ÚNICA diferencia con MCTS vanilla. [U1]
función MEJOR_HIJO_UCT(v, c):
retornar argmax sobre hijo en v.hijos.valores() de:
hijo.Q / hijo.N + c × √(ln(v.N) / hijo.N) # [U1] UCB1
El resto del algoritmo — expansión [M2], simulación [M3], retropropagación [M4] — es idéntico al de §18.3. Solo cambia la línea marcada [U1].
# ── MCTS con UCT ─────────────────────────────────────────────────────────────
# Idéntico a MCTS de §18.3, excepto por [U1].
función MCTS_UCT(juego, estado, M, c = √2):
raíz ← crear_nodo(estado)
para i = 1, …, M:
# ── [M1] Selección (MODIFICADA) ──────────────────────────────────
v ← raíz
mientras v.no_expandidos está vacío y v.hijos no está vacío:
v ← MEJOR_HIJO_UCT(v, c) # [U1] UCT en lugar de Q/N
# ── [M2] Expansión (sin cambios) ────────────────────────────────
si v.no_expandidos no está vacío:
a ← sacar_uno(v.no_expandidos)
hijo ← crear_nodo(juego.resultado(v.estado, a))
hijo.padre ← v
v.hijos[a] ← hijo
v ← hijo
# ── [M3] Simulación (sin cambios) ───────────────────────────────
resultado ← ROLLOUT(juego, v.estado, juego.turno(raíz.estado))
# ── [M4] Retropropagación (sin cambios) ─────────────────────────
mientras v ≠ None:
v.N ← v.N + 1
v.Q ← v.Q + resultado_para(v, resultado)
v ← v.padre
retornar acción en raíz.hijos con mayor raíz.hijos[acción].N
5. Implementación en Python
import math, random, copy
class MCTSNode:
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = {}
self.N = 0
self.Q = 0.0
self.unexpanded = list(state.actions())
def uct_value(child, parent_visits, c):
"""Fórmula UCT: explotación + exploración."""
if child.N == 0:
return float('inf') # nodo no visitado → prioridad máxima
return child.Q / child.N + c * math.sqrt(math.log(parent_visits) / child.N)
def mcts_uct(game_state, iterations, player, c=1.41):
root = MCTSNode(game_state)
for _ in range(iterations):
node = root
# [M1] Selección con UCT [U1]
while not node.unexpanded and node.children:
node = max(node.children.values(),
key=lambda ch: uct_value(ch, node.N, c))
# [M2] Expansión
if node.unexpanded:
action = node.unexpanded.pop()
child_state = node.state.result(action)
child = MCTSNode(child_state, parent=node)
node.children[action] = child
node = child
# [M3] Simulación
sim = copy.deepcopy(node.state)
while not sim.is_terminal():
sim = sim.result(random.choice(sim.actions()))
reward = sim.utility(player)
# [M4] Retropropagación
while node is not None:
node.N += 1
node.Q += reward
node = node.parent
return max(root.children, key=lambda a: root.children[a].N)
La única diferencia con la versión de §18.3 es la función uct_value en [U1]. Tres líneas de código cambian el rendimiento radicalmente.
6. UCT vs selección naive
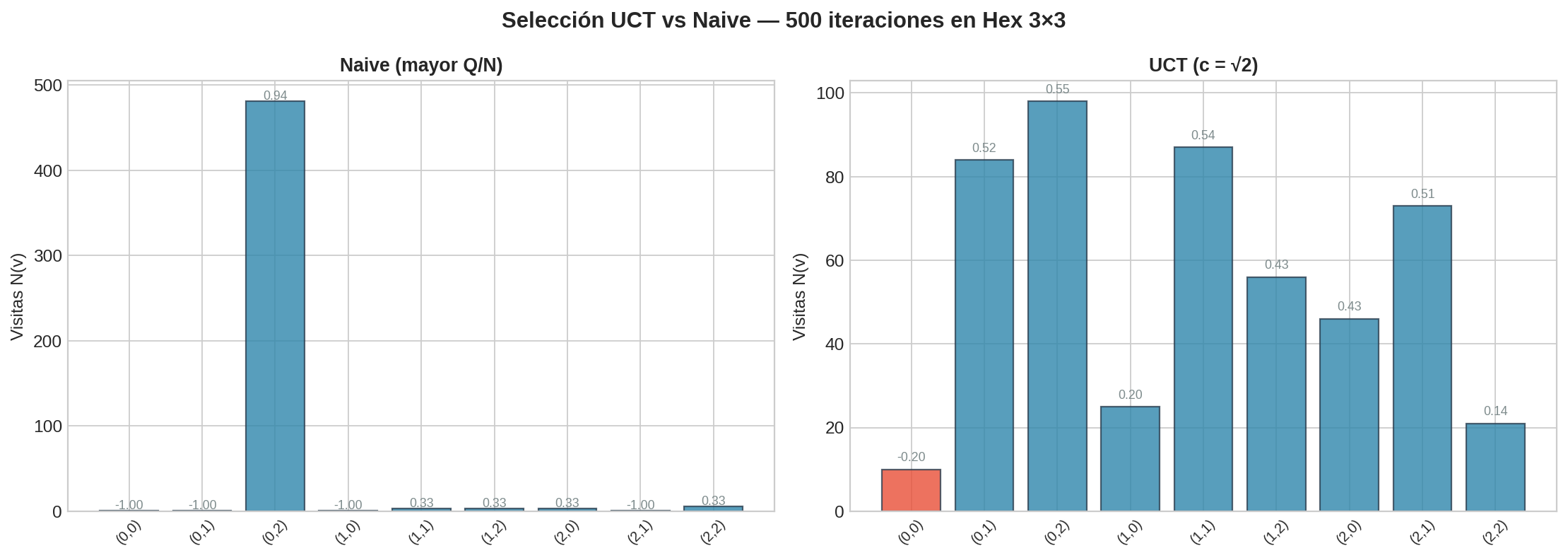
La figura muestra el mismo presupuesto de iteraciones (500) en la misma posición de Hex 3×3, con dos políticas de selección:
- Naive (mayor $Q/N$): las visitas se concentran en los primeros nodos que tuvieron buen rollout. Ramas prometedoras descubiertas tarde quedan sub-exploradas
- UCT ($c = \sqrt{2}$): las visitas se distribuyen de forma más inteligente. Nodos poco visitados reciben un bonus que garantiza exploración. Conforme acumulan visitas, el bonus decrece y la explotación domina
El resultado: UCT converge más rápido a la acción óptima porque evita tanto el error de explorar demasiado poco (perder la mejor acción) como el de explorar demasiado (desperdiciar rollouts).
7. El efecto de $c$
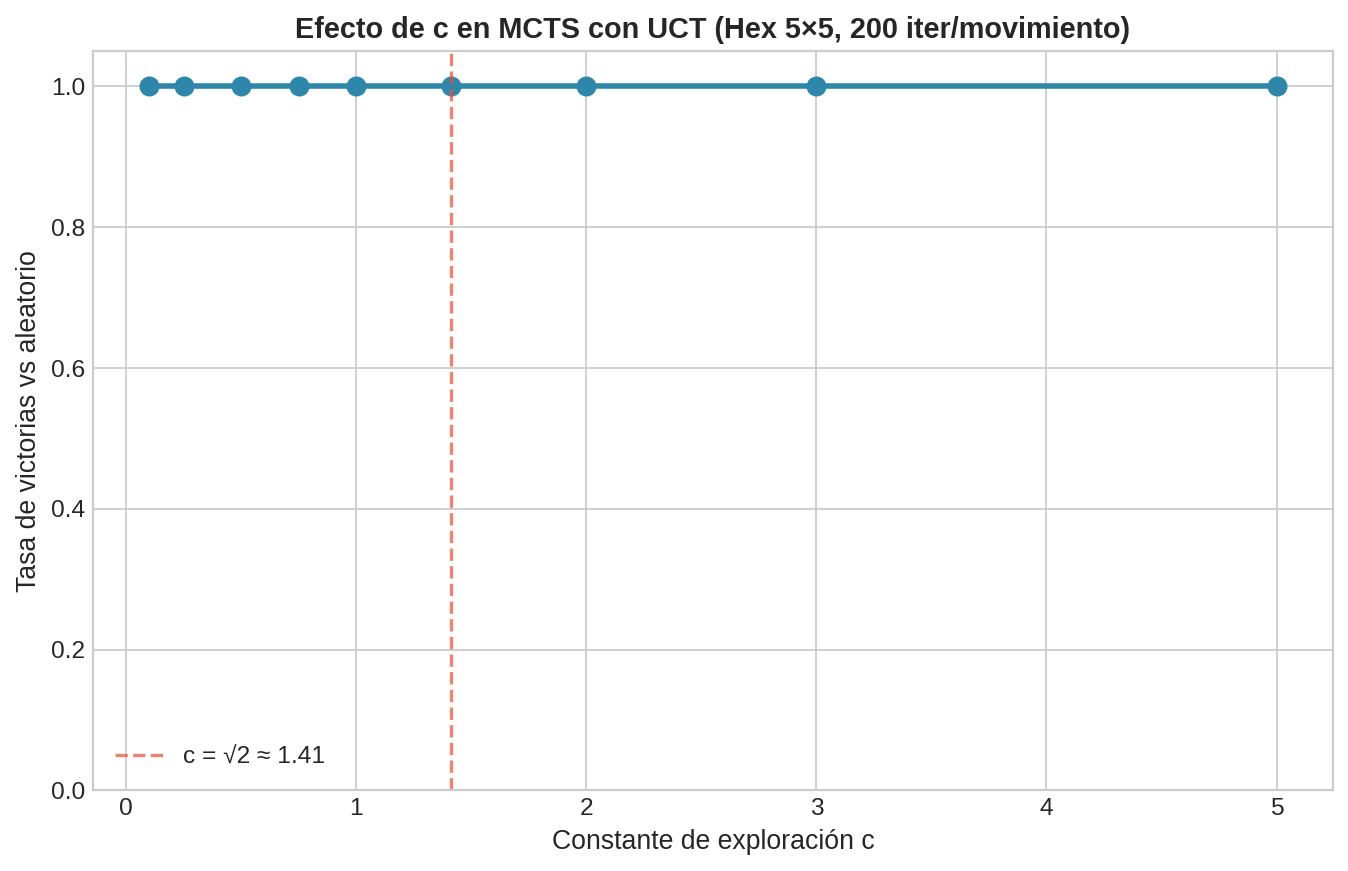
La figura muestra la tasa de victorias de MCTS con UCT contra un jugador aleatorio en Hex 7×7, variando $c$:
- $c$ muy bajo ($< 0.1$): pura explotación. MCTS se aferra a la primera acción que parece buena y pierde acciones superiores → mala tasa de victorias
- $c$ óptimo ($\approx 0.5$–$1.5$): buen balance. Explora lo suficiente para encontrar buenas acciones, explota lo suficiente para invertir rollouts donde importa
- $c$ muy alto ($> 5$): demasiada exploración. MCTS visita todos los nodos casi por igual, como si hiciera rollouts puros → pierde la ventaja del árbol
En la práctica, $c = \sqrt{2} \approx 1.41$ es un buen punto de partida. Para juegos específicos, se puede ajustar experimentalmente.
8. Convergencia: UCT → Minimax
Teorema (Kocsis & Szepesvári, 2006). Cuando el número de iteraciones $M \to \infty$, la acción elegida por MCTS con UCT converge a la acción óptima de minimax.
No demostraremos el teorema formalmente, pero la intuición es clara:
- UCB1 garantiza que cada brazo se jala infinitas veces cuando $t \to \infty$ (§17.3). Por lo tanto, en cada nodo, cada hijo es visitado infinitamente
- Si cada hijo es visitado infinitamente, los rollouts desde cada posición convergen al valor verdadero (por LLN, §12.2)
- Si los valores de los hijos convergen a los valores verdaderos, la propagación hacia arriba reproduce minimax
El resultado práctico: MCTS con UCT es asintóticamente óptimo — con suficientes iteraciones, encuentra la misma respuesta que minimax. Pero a diferencia de minimax, es anytime: con pocas iteraciones ya da una respuesta razonable.
9. Resumen: la cadena completa
El módulo 18 une tres ideas de módulos anteriores:
| Módulo | Idea | Rol en MCTS |
|---|---|---|
| 12 — Monte Carlo | $\hat\mu_n = \frac{1}{n}\sum f(X_i)$ converge a $\mu$ | Los rollouts [M3] son el estimador |
| 15 — Búsqueda adversarial | Árbol de juego + propagación de valores | La estructura del árbol [M2] + [M4] |
| 17 — Bandidos multibrazo | UCB1: $\hat\mu + c\sqrt{\ln t / N}$ | La selección [M1] con UCT [U1] |
MCTS con UCT no es un algoritmo nuevo desconectado de lo anterior — es la síntesis natural de tres herramientas que ya teníamos.
Anterior → MCTS: las cuatro fases | Siguiente → MCTS en acción