Baum-Welch: Aprender los Parámetros del HMM
Problema 3 — Aprendizaje: ¿Cómo encontrar $\lambda = (\pi, A, B)$ si solo vemos las observaciones?
1. El problema de aprendizaje
En los módulos anteriores asumimos que los parámetros $\pi$, $A$ y $B$ eran conocidos. Pero en la práctica nadie nos da esos parámetros — tenemos que aprenderlos de los datos.
Los datos que tenemos son secuencias de observaciones: $O = (O_1, O_2, \ldots, O_T)$. Nunca vemos los estados ocultos. La tarea es encontrar $\lambda^∗ = \arg\max_\lambda P(O \mid \lambda)$: los parámetros que maximizan la verosimilitud de lo que observamos.
Este es un problema de optimización con variables latentes (los estados ocultos). La solución es el algoritmo Expectation-Maximization (EM), que en el contexto de los HMMs se llama Baum-Welch.
2. Idea intuitiva: conteos suaves
Si conociéramos los estados ocultos, actualizar los parámetros sería trivial: bastaría con contar frecuencias. Por ejemplo, la probabilidad de transición de $i$ a $j$ sería simplemente:
$$A_{ij} = \frac{\text{número de veces que } i \to j}{\text{número de veces que salimos de } i}$$
Pero no conocemos los estados ocultos. La idea clave de Baum-Welch es sustituir los conteos enteros por conteos esperados (ponderados por probabilidad). En lugar de un 1 o un 0 por cada instante, aportamos $\gamma_t(i)$ o $\xi_t(i,j)$ — la probabilidad de que ese evento ocurriera:
| Escenario | Con estados observados | Con estados ocultos |
|---|---|---|
| ¿Estuve en el estado $i$ en $t$? | $\mathbf{1}[q_t = i] \in {0, 1}$ | $\gamma_t(i) \in (0,1)$ |
| ¿Pasé de $i$ a $j$ en $t$? | $\mathbf{1}[q_t=i,, q_{t+1}=j] \in {0,1}$ | $\xi_t(i,j) \in (0,1)$ |
Sustituyendo estos conteos suaves en las mismas fórmulas de frecuencia obtenemos las actualizaciones del M-paso.
Mini-ejemplo: En el ejemplo de Lain, $\gamma_1(S) = 0.79$ y $\gamma_1(\mathrm{R}) = 0.21$. Si los estados fueran observados y $q_1 = S$, añadiríamos un 1 exacto al conteo de visitas a $S$ en $t=1$ (y un 0 a $\mathrm{R}$). Con estados ocultos, en cambio, añadimos $0.79$ al conteo de $S$ y $0.21$ al conteo de $\mathrm{R}$ — distribuyendo la masa de probabilidad suavemente entre todos los estados en cada instante. Este proceso se repite para cada $t$ y cada par $(i,j)$, acumulando conteos fraccionarios a lo largo de toda la secuencia.
El algoritmo alterna dos pasos:
- E-paso (Expectation): Dado el modelo actual $\lambda$, calcula $\gamma_t(i)$ y $\xi_t(i,j)$ usando Forward y Backward.
- M-paso (Maximization): Dadas esas probabilidades esperadas, actualiza $\pi$, $A$, $B$ como si fueran conteos ponderados.
3. El obstáculo: $N^T$ caminos
Para encontrar $\lambda^∗$ quisiéramos maximizar directamente:
$$P(O \mid \lambda) = \sum_{q_1,, q_2,, \ldots,, q_T} P(O, Q \mid \lambda)$$
Esta suma recorre todos los caminos posibles de estados ocultos. Con $N$ estados y una secuencia de longitud $T$, hay $N^T$ caminos.
Con $N=2$ y $T=3$ (nuestro ejemplo de Lain) hay $2^3 = 8$ caminos — perfectamente manejable. Pero con $T=100$:
$$2^{100} \approx 10^{30} \text{ caminos}$$
Enumerar $10^{30}$ términos es completamente inviable. La optimización directa de $P(O \mid \lambda)$ es intractable para secuencias de longitud realista.
La solución es que no necesitamos enumerar los caminos: el algoritmo Forward-Backward calcula las marginales $\gamma_t(i)$ y $\xi_t(i,j)$ exactamente, en tiempo $O(N^2 T)$, sin recorrer ningún camino explícitamente (ver secciones 20.2 y 20.3). Esas marginales son todo lo que necesita el M-paso.
4. Variables del E-paso: γ y ξ
Necesitamos dos cantidades:
$\gamma_t(i)$ — nodo posterior: probabilidad de estar en el estado $i$ en el instante $t$, dado toda la secuencia:
$$\gamma_t(i) = P(q_t = i \mid O, \lambda) = \frac{\alpha_t(i) \cdot \beta_t(i)}{\sum_{k} \alpha_t(k) \cdot \beta_t(k)} = \frac{\alpha_t(i) \cdot \beta_t(i)}{P(O \mid \lambda)}$$
Sumada sobre el tiempo, $\gamma_t(i)$ acumula el número esperado de visitas al estado $i$:
$$\sum_{t=1}^{T} \gamma_t(i) = \text{número esperado de visitas al estado } i$$
Nodo vs. arco en el trellis
Piensa en el trellis de Viterbi. $\gamma_t(i)$ es la probabilidad de ocupar un nodo; $\xi_t(i,j)$ es la probabilidad de recorrer un arco entre dos nodos:
γ_t(i) γ_{t+1}(j)
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│ q_t=i │ ───────────────▶ │q_{t+1}=j│
└─────────┘ └─────────┘
ξ_t(i,j)
Para $t < T$, la probabilidad de estar en el nodo $i$ es exactamente la suma de las probabilidades de todos los arcos que salen de él:
$$\gamma_t(i) = \sum_{j} \xi_t(i,j) \qquad (t = 1, \ldots, T-1)$$
Esto se lee directamente del diagrama: estar en un nodo equivale a partir por alguno de los arcos salientes. En $t=T$ no hay arcos salientes, así que $\xi$ solo se define para $t < T$.
$\xi_t(i,j)$ — arco posterior: probabilidad de estar en el estado $i$ en $t$ y en el estado $j$ en $t+1$, dado toda la secuencia.
La fórmula se construye factor a factor:
| Factor | Expresión | Significado |
|---|---|---|
| (1) | $\alpha_t(i)$ | Probabilidad de llegar al estado $i$ en $t$ (toda la evidencia pasada) |
| (2) | $A_{ij}$ | Probabilidad de transición de $i$ a $j$ |
| (3) | $B_{j,O_{t+1}}$ | Probabilidad de emitir la observación $O_{t+1}$ desde el estado $j$ |
| (4) | $\beta_{t+1}(j)$ | Probabilidad de toda la evidencia futura desde $j$ en adelante |
Multiplicando los cuatro factores y normalizando por $P(O \mid \lambda)$:
$$\xi_t(i,j) = P(q_t = i,, q_{t+1} = j \mid O, \lambda) = \frac{\alpha_t(i) \cdot A_{ij} \cdot B_{j,O_{t+1}} \cdot \beta_{t+1}(j)}{P(O \mid \lambda)}$$
Sumada sobre el tiempo, $\xi_t(i,j)$ acumula el número esperado de transiciones $i \to j$:
$$\sum_{t=1}^{T-1} \xi_t(i,j) = \text{número esperado de transiciones } i \to j$$
Fórmula mental del M-paso
Toda actualización tiene la misma forma:
$$\text{parámetro nuevo} = \frac{\text{conteo esperado del evento}}{\text{conteo esperado del contexto}}$$
Específicamente:
- $\hat\pi_i$: conteo suave de empezar en $i$ = $\gamma_1(i)$
- $\hat A_{ij}$: conteo suave de transición $i \to j$ / conteo suave de salidas de $i$
- $\hat B_{ik}$: conteo suave de emitir $k$ estando en $i$ / conteo suave de visitas a $i$
5. La función auxiliar EM (para completitud)
Nota: Esta sección desarrolla la justificación teórica del M-paso. No es necesaria para aplicar el algoritmo.
El algoritmo EM maximiza iterativamente la función auxiliar:
$$Q(\lambda, \lambda^{\mathrm{old}}) = \mathbb E_{Q \mid O,, \lambda^{\mathrm{old}}} \bigl[ \log P(O, Q \mid \lambda) \bigr]$$
donde la expectativa se toma sobre todas las secuencias de estados $Q$, usando $\lambda^{\mathrm{old}}$ para definir la distribución, pero evaluando el logaritmo bajo el modelo nuevo $\lambda$.
Descomposición de $\log P(O,Q \mid \lambda)$
Para un camino de estados fijo $Q = (q_1, \ldots, q_T)$:
$$\log P(O, Q \mid \lambda) = \log \pi_{q_1} + \sum_{t=1}^{T-1} \log A_{q_t,, q_{t+1}} + \sum_{t=1}^{T} \log B_{q_t,, O_t}$$
Los tres términos dependen de $\pi$, $A$ y $B$ por separado — son independientes entre sí. Al tomar la expectativa, $Q(\lambda, \lambda^{\mathrm{old}})$ se descompone en tres sumas independientes:
$$Q = \sum_i \gamma_1(i) \log \pi_i + \sum_{t=1}^{T-1} \sum_i \sum_j \xi_t(i,j) \log A_{ij} + \sum_{t=1}^{T} \sum_j \gamma_t(j) \log B_{j,, O_t}$$
Cada término puede maximizarse por separado, y eso produce exactamente las fórmulas del M-paso de la §6.
Garantía de monotonicidad
Cada iteración de EM garantiza:
$$P(O \mid \lambda^{\mathrm{new}}) \geq P(O \mid \lambda^{\mathrm{old}})$$
La log-verosimilitud es no decreciente en cada paso. El algoritmo converge a un óptimo local (no necesariamente global), como se ilustra en el gráfico de convergencia de la §9.
6. Fórmulas del M-paso
Cada parámetro se actualiza como un ratio de conteos esperados. Para cada fórmula se muestra primero qué miden el numerador y el denominador, y luego la ecuación compacta.
Distribución inicial $\hat\pi_i$
$$\hat\pi_i = \frac{\text{número esperado de inicios en el estado } i}{\text{número de secuencias}} = \gamma_1(i)$$
Solo hay un instante inicial ($t=1$). La probabilidad esperada de haber empezado en $i$, dada la secuencia observada, es directamente $\gamma_1(i)$.
Probabilidades de transición $\hat A_{ij}$
$$\hat A_{ij} = \frac{\text{número esperado de transiciones } i \to j}{\text{número esperado de salidas desde } i \text{ (a cualquier estado)}}$$
$$\hat A_{ij} = \frac{\displaystyle\sum_{t=1}^{T-1} \xi_t(i,j)}{\displaystyle\sum_{t=1}^{T-1} \gamma_t(i)}$$
El numerador acumula los arcos $i \to j$ esperados a lo largo de la secuencia. El denominador acumula todos los arcos que salen de $i$ (hacia cualquier estado), que por la relación $\gamma_t(i) = \sum_j \xi_t(i,j)$ equivale a sumar sobre todos los destinos posibles. Ambas sumas van solo hasta $T-1$ porque en $t=T$ no hay transición siguiente.
Probabilidades de emisión $\hat B_{ik}$
$$\hat B_{ik} = \frac{\text{número esperado de veces en estado } i \text{ y observando } k}{\text{número esperado de veces en estado } i \text{ (con cualquier observación)}}$$
$$\hat B_{ik} = \frac{\displaystyle\sum_{\substack{t=1 \ O_t=k}}^{T} \gamma_t(i)}{\displaystyle\sum_{t=1}^{T} \gamma_t(i)}$$
El numerador suma $\gamma_t(i)$ solo en los instantes donde se observó $k$ (los demás instantes no contribuyen). El denominador suma $\gamma_t(i)$ en todos los $T$ instantes, independientemente de la observación. El cociente da la fracción del tiempo esperado en $i$ durante la cual se emitió $k$.
7. Traza completa del E-paso: el ejemplo de Lain
Usamos los valores ya calculados de Forward y Backward (secciones 20.2 y 20.3):
$$P(O \mid \lambda) = 0.10007$$
Valores $\gamma$:
| $t$ | $\gamma_t(S)$ | $\gamma_t(\mathrm{R})$ |
|---|---|---|
| 1 | $\frac{0.540 \times 0.1465}{0.10007} = 0.7906$ | $\frac{0.080 \times 0.2620}{0.10007} = 0.2094$ |
| 2 | $\frac{0.041 \times 0.310}{0.10007} = 0.1270$ | $\frac{0.168 \times 0.520}{0.10007} = 0.8730$ |
| 3 | $\frac{0.00959 \times 1.0}{0.10007} = 0.0958$ | $\frac{0.09048 \times 1.0}{0.10007} = 0.9042$ |
Verificación: $\gamma_t(S) + \gamma_t(\mathrm{R}) = 1$ para todo $t$. ✓
Valores $\xi$ en $t=1$ (observación futura $O_2 = 1$):
$$\xi_1(S,S) = \frac{0.540 \times 0.7 \times 0.1 \times 0.31}{0.10007} = \frac{0.011718}{0.10007} = 0.1171$$
$$\xi_1(S,R) = \frac{0.540 \times 0.3 \times 0.8 \times 0.52}{0.10007} = \frac{0.067392}{0.10007} = 0.6735$$
$$\xi_1(R,S) = \frac{0.080 \times 0.4 \times 0.1 \times 0.31}{0.10007} = \frac{0.000992}{0.10007} = 0.0099$$
$$\xi_1(R,R) = \frac{0.080 \times 0.6 \times 0.8 \times 0.52}{0.10007} = \frac{0.019968}{0.10007} = 0.1995$$
Verificación: $\sum_{i,j} \xi_1(i,j) = 0.1171 + 0.6735 + 0.0099 + 0.1995 = 1.0$ ✓
Valores $\xi$ en $t=2$ (observación futura $O_3 = 1$):
$$\xi_2(S,S) = \frac{0.041 \times 0.7 \times 0.1 \times 1.0}{0.10007} = \frac{0.00287}{0.10007} = 0.0287$$
$$\xi_2(S,R) = \frac{0.041 \times 0.3 \times 0.8 \times 1.0}{0.10007} = \frac{0.009840}{0.10007} = 0.0983$$
$$\xi_2(R,S) = \frac{0.168 \times 0.4 \times 0.1 \times 1.0}{0.10007} = \frac{0.00672}{0.10007} = 0.0672$$
$$\xi_2(R,R) = \frac{0.168 \times 0.6 \times 0.8 \times 1.0}{0.10007} = \frac{0.080640}{0.10007} = 0.8058$$
8. Traza completa del M-paso
Actualización de $\pi$:
$$\hat\pi_S = \gamma_1(S) = 0.791, \qquad \hat\pi_R = \gamma_1(\mathrm{R}) = 0.209$$
Actualización de $A$: (denominadores usan $t=1$ y $t=2$, es decir, $T-1=2$ términos)
$$\hat A_{SS} = \frac{\xi_1(S,S) + \xi_2(S,S)}{\gamma_1(S) + \gamma_2(S)} = \frac{0.1171 + 0.0287}{0.7906 + 0.1270} = \frac{0.1458}{0.9176} = 0.159$$
$$\hat A_{SR} = \frac{\xi_1(S,R) + \xi_2(S,R)}{\gamma_1(S) + \gamma_2(S)} = \frac{0.6735 + 0.0983}{0.9176} = \frac{0.7718}{0.9176} = 0.841$$
$$\hat A_{RS} = \frac{\xi_1(R,S) + \xi_2(R,S)}{\gamma_1(\mathrm{R}) + \gamma_2(\mathrm{R})} = \frac{0.0099 + 0.0672}{0.2094 + 0.8730} = \frac{0.0771}{1.0824} = 0.071$$
$$\hat A_{RR} = \frac{\xi_1(R,R) + \xi_2(R,R)}{\gamma_1(\mathrm{R}) + \gamma_2(\mathrm{R})} = \frac{0.1995 + 0.8058}{1.0824} = \frac{1.0053}{1.0824} = 0.929$$
Verificación: $\hat A_{SS} + \hat A_{SR} = 0.159 + 0.841 = 1.000$ ✓ y $\hat A_{RS} + \hat A_{RR} = 0.071 + 0.929 = 1.000$ ✓
Actualización de $B$: (denominadores usan los 3 instantes $t=1,2,3$)
Observaciones: $O_1=0$, $O_2=1$, $O_3=1$. Solo $t=1$ tiene $O_t=0$; $t=2$ y $t=3$ tienen $O_t=1$.
$$\hat B_{S,0} = \frac{\gamma_1(S)}{\gamma_1(S)+\gamma_2(S)+\gamma_3(S)} = \frac{0.7906}{0.7906+0.1270+0.0958} = \frac{0.7906}{1.0134} = 0.780$$
$$\hat B_{S,1} = \frac{\gamma_2(S)+\gamma_3(S)}{1.0134} = \frac{0.1270+0.0958}{1.0134} = \frac{0.2228}{1.0134} = 0.220$$
$$\hat B_{R,0} = \frac{\gamma_1(\mathrm{R})}{\gamma_1(\mathrm{R})+\gamma_2(\mathrm{R})+\gamma_3(\mathrm{R})} = \frac{0.2094}{0.2094+0.8730+0.9042} = \frac{0.2094}{1.9866} = 0.105$$
$$\hat B_{R,1} = \frac{\gamma_2(\mathrm{R})+\gamma_3(\mathrm{R})}{1.9866} = \frac{0.8730+0.9042}{1.9866} = \frac{1.7772}{1.9866} = 0.895$$
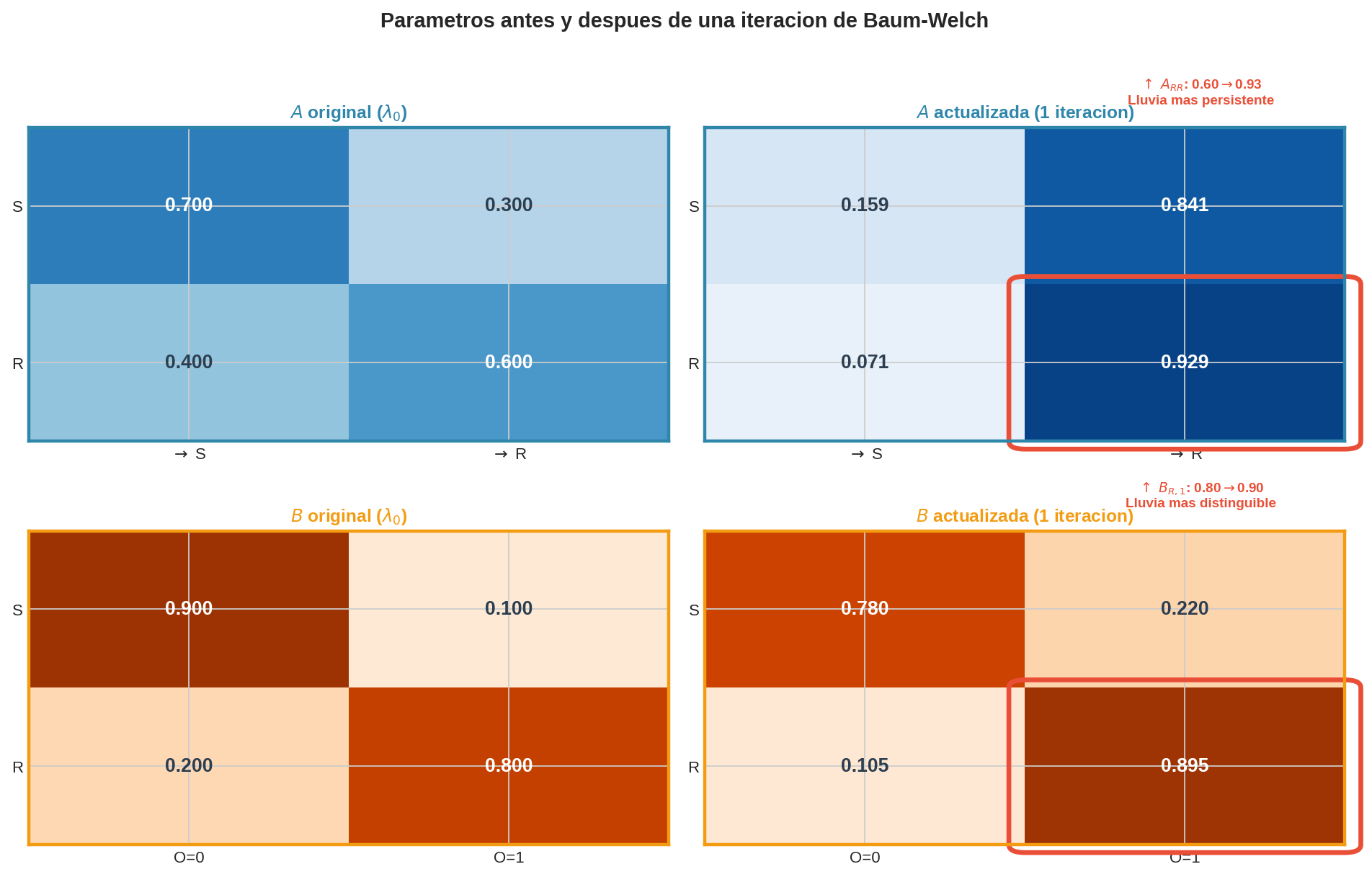
Tabla comparativa — antes y después de una iteración:
| Parámetro | Antes | Después | Cambio |
|---|---|---|---|
| $\pi_S$ | 0.600 | 0.791 | ↑ |
| $\pi_R$ | 0.400 | 0.209 | ↓ |
| $A_{SS}$ | 0.700 | 0.159 | ↓↓ |
| $A_{SR}$ | 0.300 | 0.841 | ↑↑ |
| $A_{RS}$ | 0.400 | 0.071 | ↓↓ |
| $A_{RR}$ | 0.600 | 0.929 | ↑↑ |
| $B_{S,0}$ | 0.900 | 0.780 | ↓ |
| $B_{S,1}$ | 0.100 | 0.220 | ↑ |
| $B_{R,0}$ | 0.200 | 0.105 | ↓ |
| $B_{R,1}$ | 0.800 | 0.895 | ↑ |
¿Tiene sentido? La secuencia $(0,1,1)$ tiene dos días con paraguas. Después de una iteración:
- El modelo aprendió que la lluvia es más “pegajosa” ($A_{RR}$: 0.60 → 0.93) — los dos últimos días son casi con certeza lluviosos y se siguen uno al otro.
- $A_{SS}$ bajó (0.70 → 0.16): no es que el sol sea menos persistente en general, sino que en esta secuencia corta el único día soleado (t=1, con $\gamma_1(S)=0.79$) es seguido inmediatamente de lluvia (t=2, con $\gamma_2(\mathrm{R})=0.87$). Esa única transición S→R eleva $A_{SR}$ y hunde $A_{SS}$.
- La lluvia es más distinguible ($B_{R,1}$: 0.80 → 0.895) — los dos días con paraguas son casi seguramente lluviosos, lo que refuerza la asociación lluvia↔paraguas.
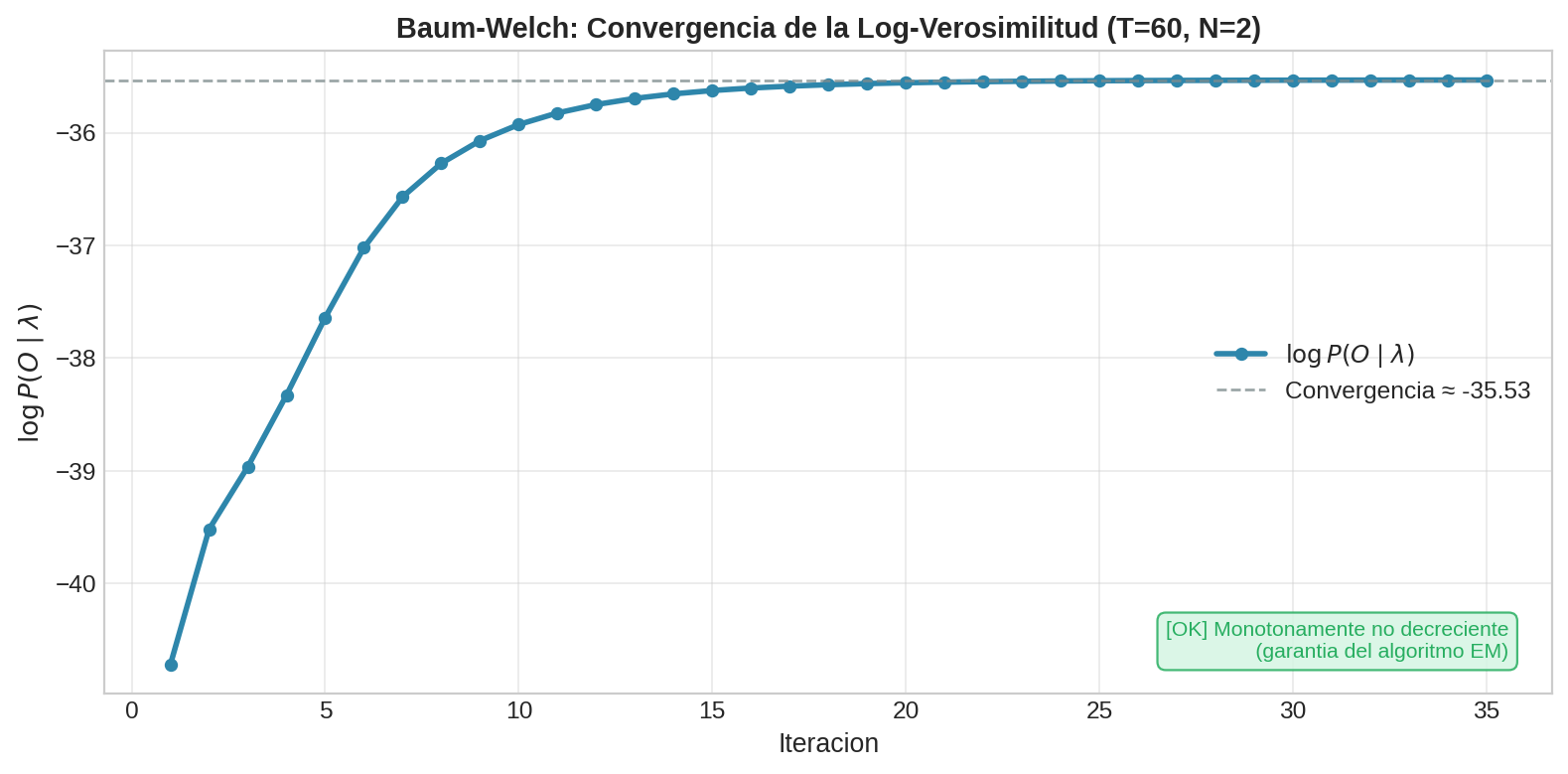
9. Convergencia
Con una sola secuencia corta ($T=3$), los parámetros aprendidos no son muy confiables. En la práctica se usa una secuencia larga (o muchas secuencias) y se itera hasta que la log-verosimilitud converge.
La log-verosimilitud $\log P(O \mid \lambda)$ aumenta monotónicamente con cada iteración de EM (esto es una garantía teórica del algoritmo). La convergencia se detecta cuando el aumento entre iteraciones es menor que un umbral $\varepsilon$ (por ejemplo, $10^{-6}$).
10. Problema de underflow numérico
Para secuencias largas, los valores $\alpha_t(i)$ y $\beta_t(i)$ se vuelven extremadamente pequeños. Con $T=100$ observaciones, $\alpha_{100}(i)$ puede ser del orden de $10^{-100}$, que cae por debajo del mínimo representable en punto flotante de 64 bits ($\approx 10^{-308}$).
Con $N=2$ estados, $T=100$ pasos, y probabilidades de emisión típicas de $\sim 0.5$:
$$\alpha_{100}(i) \approx (0.5)^{100} \approx 10^{-30}$$
En secuencias más largas o con más estados, fácilmente llegamos a $10^{-300}$ o menos. El resultado: Python/NumPy retorna 0.0 en lugar del valor correcto, y todo el cálculo se corrompe silenciosamente.
Solución: trabajar en log-espacio
En lugar de calcular $\alpha_t(i)$ directamente, calculamos $\log \alpha_t(i)$. La recursión requiere calcular $\log(\sum_i e^{a_i})$, lo que se hace numéricamente estable con el truco log-sum-exp:
$$\log\left(\sum_i e^{a_i}\right) = a_{\max} + \log\left(\sum_i e^{a_i - a_{\max}}\right)$$
donde $a_{\max} = \max_i a_i$. El término $e^{a_i - a_{\max}} \leq 1$ nunca produce overflow, y los términos pequeños no causan underflow (contribuyen poco a la suma).
Los notebooks implementan la versión en log-espacio y verifican que coincide con la versión directa para secuencias cortas.
11. Pseudocódigo — Una iteración de Baum-Welch
función BAUM_WELCH_PASO(O, π, A, B):
T ← longitud(O)
N ← número de estados
# E-paso
α, P_obs ← FORWARD(O, π, A, B)
β ← BACKWARD(O, A, B)
# γ[t][i] = α[t][i] × β[t][i] / P_obs
para t = 1 hasta T:
para i = 1 hasta N:
γ[t][i] ← α[t][i] × β[t][i] / P_obs
# ξ[t][i][j] para t = 1 hasta T-1
para t = 1 hasta T-1:
para i = 1 hasta N:
para j = 1 hasta N:
ξ[t][i][j] ← α[t][i] × A[i][j] × B[j][O[t+1]] × β[t+1][j] / P_obs
# M-paso
para i = 1 hasta N:
π̂[i] ← γ[1][i]
para i = 1 hasta N:
para j = 1 hasta N:
num ← Σ_{t=1}^{T-1} ξ[t][i][j]
den ← Σ_{t=1}^{T-1} γ[t][i]
Â[i][j] ← num / den
para i = 1 hasta N:
para k = 0 hasta M-1:
num ← Σ_{t: O[t]=k} γ[t][i]
den ← Σ_{t=1}^{T} γ[t][i]
B̂[i][k] ← num / den
retornar π̂, Â, B̂, log(P_obs)
# Bucle principal:
inicializar π, A, B aleatoriamente (o con heurística)
repetir:
π, A, B, log_p ← BAUM_WELCH_PASO(O, π, A, B)
si |log_p - log_p_anterior| < ε: parar
log_p_anterior ← log_p