22.4 — Fundamentos estadísticos
“Bias² + Var + σ² = MSE. Tres términos, tres enemigos distintos.”
Descomposición MSE: Bias², Varianza y ruido
Sea $\hat{f}_{\mathcal{D}}$ el estimador obtenido entrenando con dataset $\mathcal{D}$, y sea $x_0$ un punto de prueba fijo con $y_0 = f^{∗}(x_0) + \varepsilon$, $\varepsilon \sim (0, \sigma^2)$.
Teorema (descomposición bias-varianza). El MSE en $x_0$ sobre múltiples realizaciones de $\mathcal{D}$ se descompone como:
$$ \mathbb{E}_{\mathcal{D}, \varepsilon}[(y_0 - \hat{f}_{\mathcal{D}}(x_0))^2] = \sigma^2 + \text{Bias}^2(\hat{f}, x_0) + \text{Var}(\hat{f}, x_0) $$
donde: $$ \text{Bias}(\hat{f}, x_0) = \mathbb{E}_{\mathcal{D}}[\hat{f}_{\mathcal{D}}(x_0)] - f^{∗}(x_0) $$ $$ \text{Var}(\hat{f}, x_0) = \mathbb{E}_{\mathcal{D}}\left[(\hat{f}_{\mathcal{D}}(x_0) - \mathbb{E}_{\mathcal{D}}[\hat{f}_{\mathcal{D}}(x_0)])^2\right] $$
Prueba. Sea $\bar{f}(x_0) = \mathbb{E}_{\mathcal{D}}[\hat{f}_{\mathcal{D}}(x_0)]$. Expandiendo y agrupando:
$$ \mathbb{E}[(y_0 - \hat{f})^2] = \mathbb{E}[(y_0 - f^{∗} + f^{∗} - \bar{f} + \bar{f} - \hat{f})^2] $$
Los tres sumandos son: $\varepsilon = y_0 - f^{∗}$, $\text{Bias} = f^{∗} - \bar{f}$, y $\hat{f} - \bar{f}$. El término cruzado $\mathbb{E}[\varepsilon \cdot (\bar{f} - \hat{f})] = 0$ porque $\varepsilon$ es independiente de $\mathcal{D}$. El término $\mathbb{E}[\varepsilon \cdot \text{Bias}] = 0$ porque el Bias no depende de $\varepsilon$. Entonces:
$$ \mathbb{E}[(y_0 - \hat{f})^2] = \mathbb{E}[\varepsilon^2] + (\bar{f}(x_0) - f^{∗}(x_0))^2 + \mathbb{E}[(\hat{f} - \bar{f})^2] = \sigma^2 + \text{Bias}^2 + \text{Var} \qquad \square $$
Importante: $\sigma^2$ es el piso de Bayes — ruido irreducible en $y$ dado $x$. No es parte del Bias ni de la Varianza. Todo algoritmo de aprendizaje tiene $\text{MSE} \geq \sigma^2$.
Conexión con la regularización
La regularización $\lambda$ controla la tensión Bias-Var directamente:
| $\lambda$ | Bias | Varianza | MSE |
|---|---|---|---|
| Grande | Alto (modelo demasiado simple) | Baja | Puede ser alto |
| Óptimo | Moderado | Moderada | Mínimo |
| $\approx 0$ | Bajo | Alta (memoriza ruido) | Puede ser alto |
Ridge regression con $\lambda$ óptimo minimiza el MSE total, aceptando algo de Bias a cambio de reducir la Varianza.
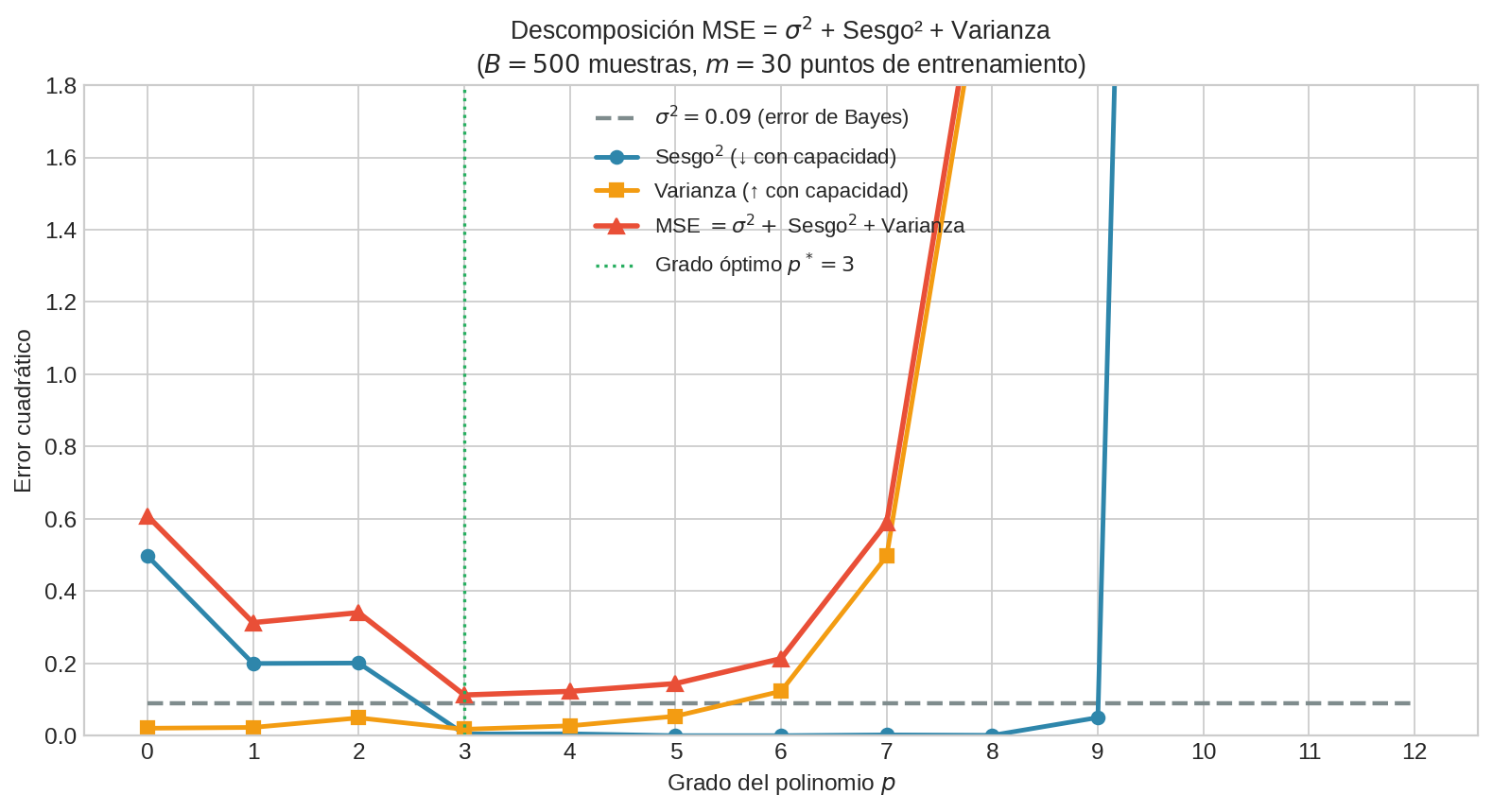
La descomposición empírica ($B=500$ datasets, $m=30$) confirma la teoría: Bias² decrece con la capacidad, Varianza crece, MSE forma una U por encima del piso $\sigma^2 = 0.09$.
Efecto del tamaño de muestra $m$
Para un modelo de capacidad fija:
- Bias² es aproximadamente constante en $m$ (el sesgo estructural del modelo no desaparece con más datos).
- Varianza decae como $\sim C/m$ (ley de los grandes números).
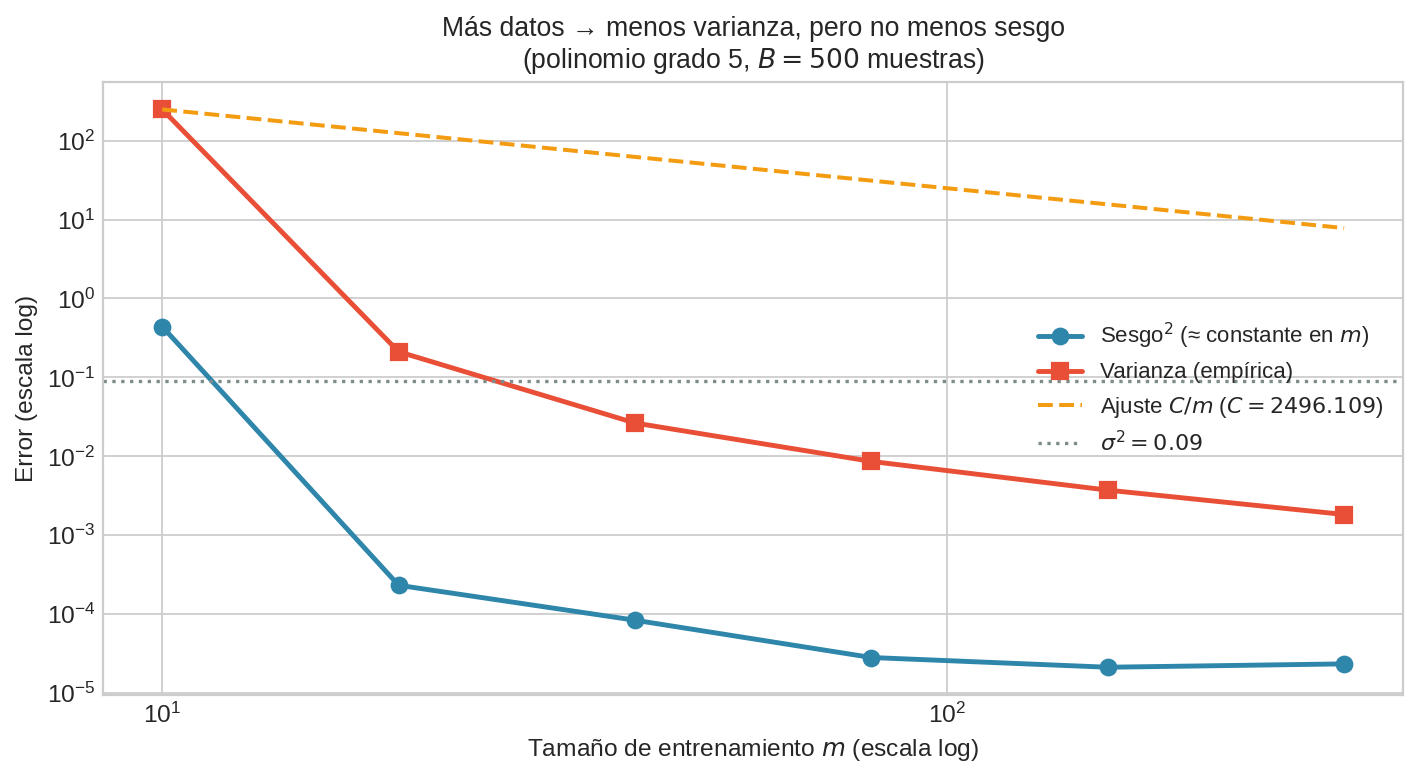
La curva $C/m$ ajustada confirma la tasa de decaimiento. Con más datos, la varianza desaparece y el MSE converge al Bias² + $\sigma^2$.
Máxima verosimilitud como minimización de KL
Definición
Dado un modelo paramétrico $p_\theta(y \mid x)$, el estimador de máxima verosimilitud (MLE) es:
$$ \hat{\theta}_{\text{MLE}} = \arg\max_\theta \prod_{i=1}^m p_\theta(y^{(i)} \mid x^{(i)}) = \arg\max_\theta \sum_{i=1}^m \log p_\theta(y^{(i)} \mid x^{(i)}) $$
MLE = minimizar KL con la distribución empírica
Sea $\hat{p}_{\text{data}}$ la distribución empírica: $\hat{p}_{\text{data}}(x, y) = \frac{1}{m}\sum_{i=1}^m \delta(x-x^{(i)})\delta(y-y^{(i)})$. Entonces:
$$ \hat{\theta}_{\text{MLE}} = \arg\min_\theta D_{\text{KL}}(\hat{p}_{\text{data}} | p_\theta) = \arg\min_\theta -\mathbb{E}_{\hat{p}}[\log p_\theta(y \mid x)] $$
El MLE busca la distribución en ${p_\theta}$ más cercana a la empírica en términos de KL. Esto conecta con el Módulo 6 (Entropía y KL-divergence).
Caso Gaussiano: MLE = MSE
Si asumimos $p_\theta(y \mid x) = \mathcal{N}(f_\theta(x), \sigma^2)$ con $\sigma^2$ conocida:
$$ \log p_\theta(y \mid x) = -\frac{(y - f_\theta(x))^2}{2\sigma^2} - \frac{1}{2}\log(2\pi\sigma^2) $$
Maximizar la log-verosimilitud equivale a:
$$ \hat{\theta}_{\text{MLE}} = \arg\min_\theta \frac{1}{m}\sum_{i=1}^m (y^{(i)} - f_\theta(x^{(i)}))^2 = \arg\min_\theta \hat{R}_{\text{MSE}}(\theta) $$
La pérdida MSE es exactamente el negativo de la log-verosimilitud gaussiana (salvo constantes). Usar MSE implica asumir ruido gaussiano aditivo i.i.d.
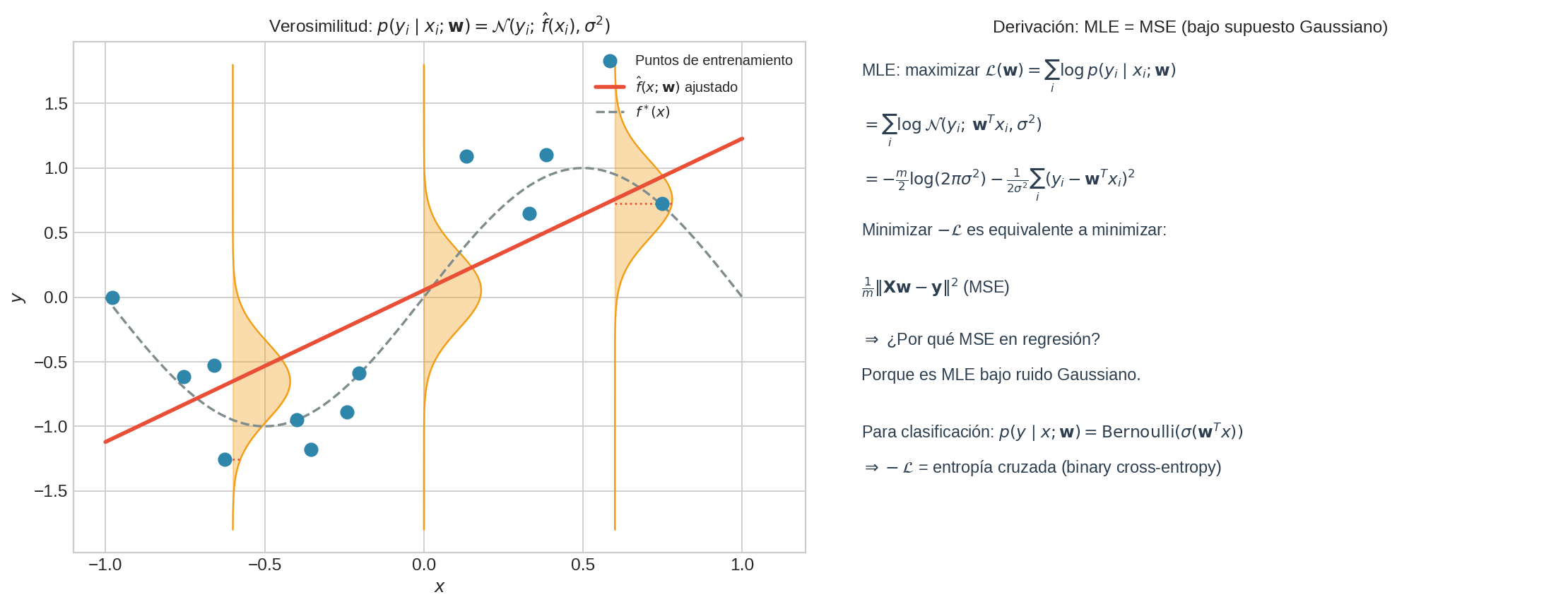
El panel izquierdo muestra las campanas de Gauss centradas en $\hat{f}(x_i)$ con los puntos observados $y_i$. El panel derecho muestra la derivación algebraica: NLL = MSE + constante.
Caso Bernoulli: MLE = entropía cruzada
Si asumimos $p_\theta(y=1 \mid x) = \sigma(f_\theta(x)) \in (0,1)$:
$$ \log p_\theta(y \mid x) = y \log \sigma(f_\theta(x)) + (1-y)\log(1-\sigma(f_\theta(x))) $$
$$ \hat{\theta}_{\text{MLE}} = \arg\min_\theta -\frac{1}{m}\sum_{i=1}^m \left[y^{(i)}\log f_\theta(x^{(i)}) + (1-y^{(i)})\log(1-f_\theta(x^{(i)}))\right] $$
La pérdida cross-entropy es el negativo de la log-verosimilitud Bernoulli. Usar cross-entropy implica modelar las probabilidades de clase directamente — esto es regresión logística.
Consistencia del MLE
Teorema (consistencia del MLE, informal). Bajo condiciones de regularidad, $\hat{\theta}_{\text{MLE}} \xrightarrow{p} \theta^{∗}$ cuando $m \to \infty$, donde $\theta^{∗} = \arg\min_\theta D_{\text{KL}}(p_{\text{data}} | p_\theta)$.
Si el modelo está bien especificado ($p_{\text{data}} \in {p_\theta}$), entonces $p_{\theta^{∗}} = p_{\text{data}}$ y el MLE recupera los parámetros verdaderos. Además, la distribución de muestreo del MLE:
$$ \sqrt{m}(\hat{\theta}_{\text{MLE}} - \theta^{∗}) \xrightarrow{d} \mathcal{N}(0, \mathbf{I}(\theta^{∗})^{-1}) $$
donde $\mathbf{I}(\theta^{∗})$ es la matriz de información de Fisher. El MLE es asintóticamente eficiente: alcanza la cota de Cramér-Rao.
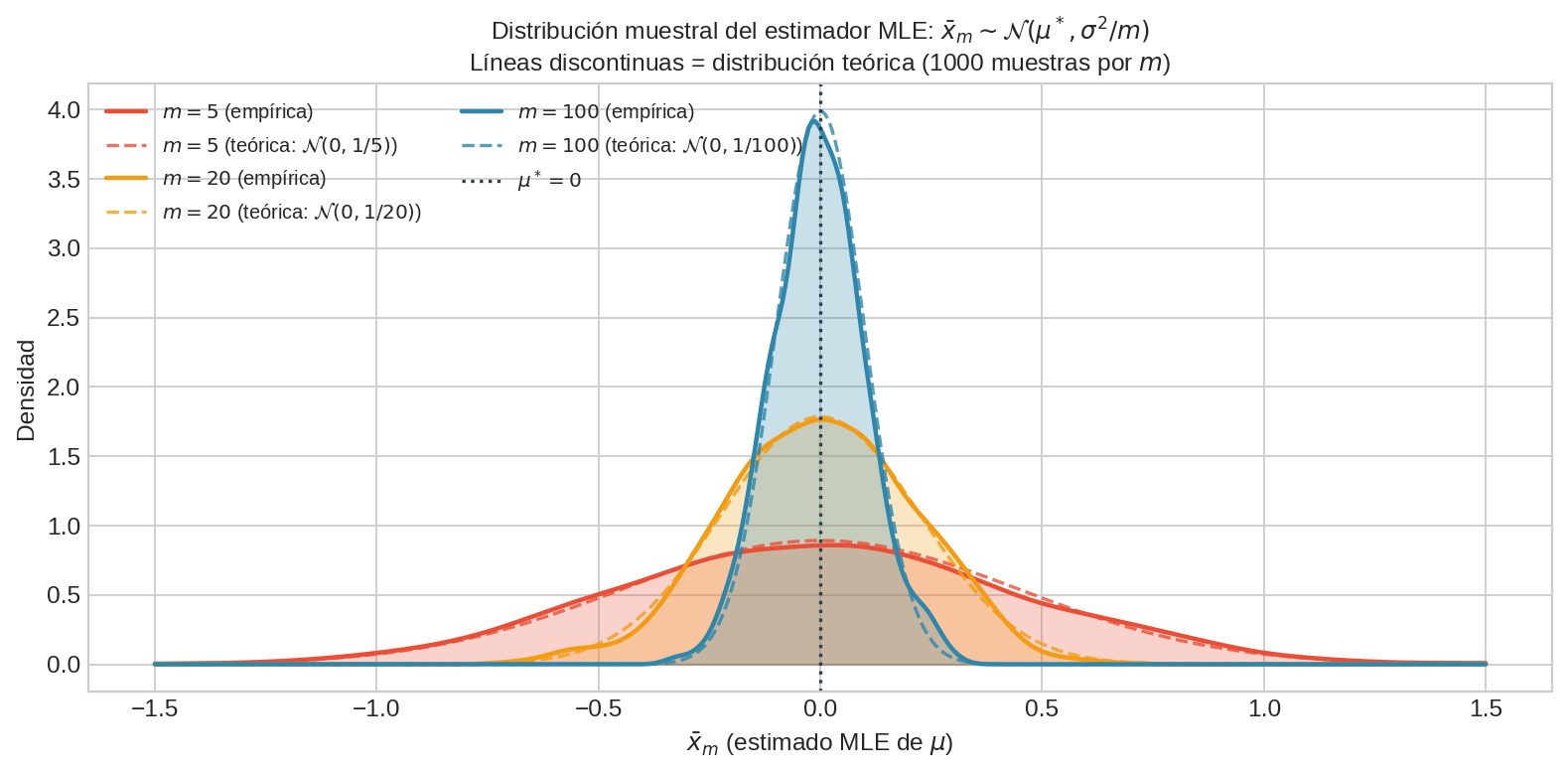
Para $m=5$, la distribución de $\bar{x}_m$ es ancha; para $m=100$, es casi puntual. Las curvas teóricas $\mathcal{N}(0, 1/m)$ (punteadas) coinciden con las distribuciones empíricas — confirmando la consistencia y normalidad asintótica.
Siguiente: Desafíos y motivación para deep learning →