22.5 — Desafíos y motivación para el aprendizaje profundo
“En dimensión alta, la distancia euclidiana deja de significar lo que creemos.”
La maldición de la dimensionalidad
Los algoritmos clásicos de ML — k-NN, kernels, árboles de decisión — funcionan bien en dimensión baja. Pero a medida que $d$ crece, enfrentan un problema fundamental: el espacio se vacía exponencialmente.
Resultado 1: El hipercubo se vacía
La fracción del volumen del hipercubo unitario $[0,1]^d$ que está dentro de la hiperesfera inscrita de radio $0.5$ es:
$$ \frac{V_d(0.5)}{1^d} = \frac{\pi^{d/2} \cdot (0.5)^d}{\Gamma(d/2 + 1)} $$
| $d$ | Fracción |
|---|---|
| 1 | 1.00 |
| 2 | 0.785 |
| 3 | 0.524 |
| 5 | 0.164 |
| 10 | 0.0025 |
| 20 | $\approx 10^{-8}$ |
Para $d = 20$, casi todo el volumen del hipercubo está en las esquinas — lejos del centro. Los puntos de entrenamiento se concentran en regiones periféricas y dejan enormes “huecos” en el espacio.
Resultado 2: La densidad de muestras colapsa
Para que un vecino más cercano esté a distancia $\leq \varepsilon$ de un punto de consulta, necesitamos que la cuadrícula de $\varepsilon$-celdas esté razonablemente cubierta. El número de celdas en $[0,1]^d$ con resolución $\varepsilon$ es $(1/\varepsilon)^d$. Si queremos al menos 1 punto por celda:
$$ m \sim \left(\frac{1}{\varepsilon}\right)^d $$
Con $\varepsilon = 0.1$ (resolución del 10%):
| $d$ | $m$ necesario |
|---|---|
| 1 | 10 |
| 3 | $10^3 = 1{,}000$ |
| 6 | $10^6 = 1{,}000{,}000$ |
| 12 | $10^{12}$ |
| 20 | $10^{20}$ |
El crecimiento es exponencial en $d$. Ningún dataset realista puede cubrir uniformemente el espacio en dimensión alta.
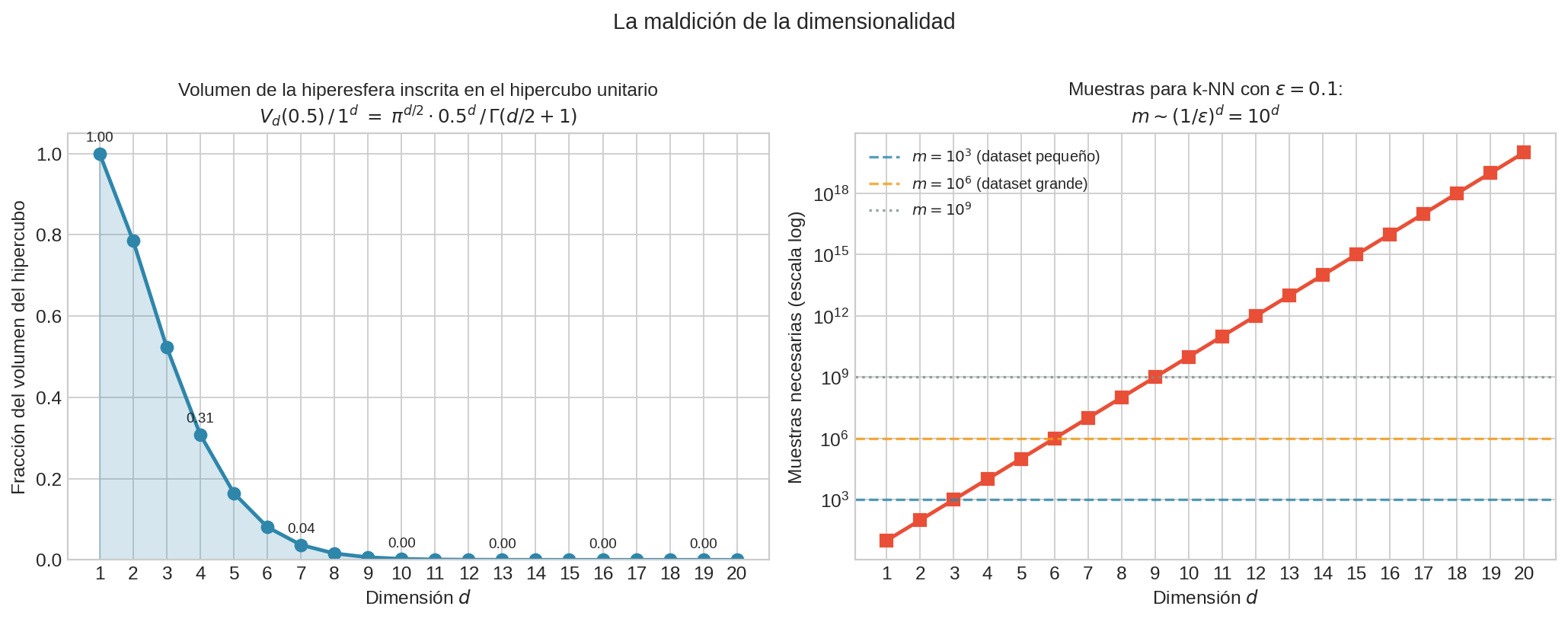
El panel izquierdo muestra el colapso de la fracción de volumen. El panel derecho muestra $10^d$ muestras necesarias en escala log — con líneas de referencia en $m = 10^3, 10^6, 10^9$, vemos que para $d > 9$ necesitamos más de mil millones de puntos.
Falla de la suposición de constancia local
Los métodos clásicos asumen implícitamente que $f^{∗}$ es localmente constante: $f^{∗}(x) \approx f^{∗}(x + \epsilon)$ para $|\epsilon|$ pequeño. Esta es la hipótesis que justifica k-NN (usa los vecinos más cercanos como representantes locales de $f^{∗}$).
El problema: en dimensión alta, “cercano en distancia euclidiana” deja de implicar “similar en valor de $f^{∗}$”. Para funciones con variaciones de escala fina, k-NN falla incluso en 1D cuando la muestra es pequeña:
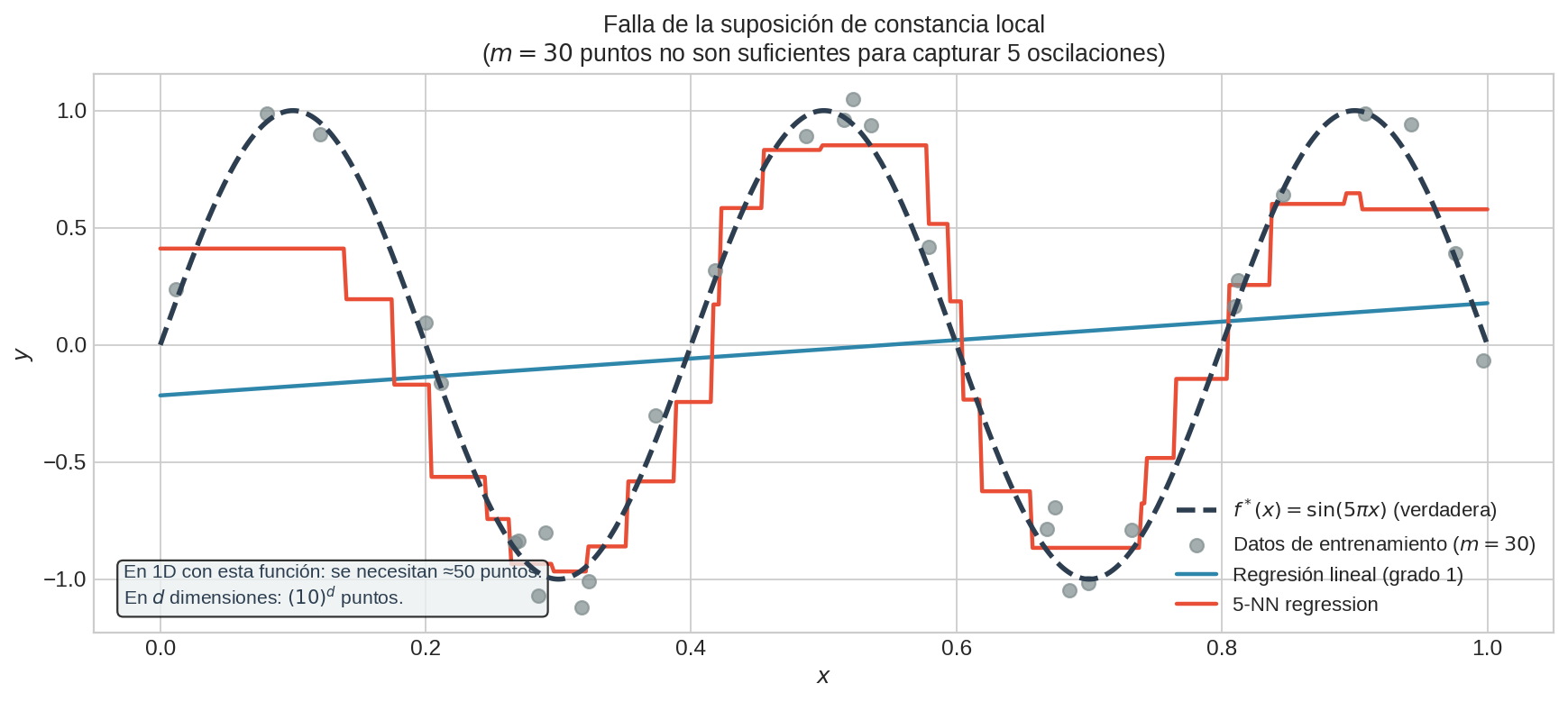
Con 30 puntos de entrenamiento en $[0,1]$, la función $\sin(5\pi x)$ tiene 5 ciclos completos — cada vecindad euclidiana contiene múltiples oscilaciones. Tanto el ajuste lineal como el 5-NN no recuperan las oscilaciones.
Para que un método local recupere $f^{∗}$ con error $\leq \epsilon$ en $d$ dimensiones, el número de muestras necesario escala como:
$$ m = O\left(\epsilon^{-d}\right) $$
Con $d = 100$ y $\epsilon = 0.01$: $m = 10^{200}$. Completamente intractable.
La hipótesis del manifold
¿Por qué el aprendizaje profundo funciona en visión, audio y lenguaje, a pesar de que las imágenes viven en $\mathbb{R}^{d}$ con $d \sim 10^6$?
Hipótesis del manifold (Goodfellow et al., §5.11.3): Los datos de alta dimensión se concentran cerca de una variedad (manifold) de dimensión intrínseca $d_{\text{int}} \ll d$.
Una imagen de $256 \times 256$ pixels tiene $d = 65{,}536$ dimensiones. Pero las imágenes naturales no llenan ese espacio — viven cerca de una variedad de dimensión intrínseca estimada en $d_{\text{int}} \sim 10$–$100$. La inmensa mayoría del espacio ambient está vacía de imágenes naturales.
Consecuencia: si podemos aprender una representación que “aplane” la variedad, la estimación de $f^{∗}$ se vuelve un problema de dimensión efectiva $d_{\text{int}}$, no $d$.
Ilustración: vecindad euclidiana vs. vecindad en el manifold
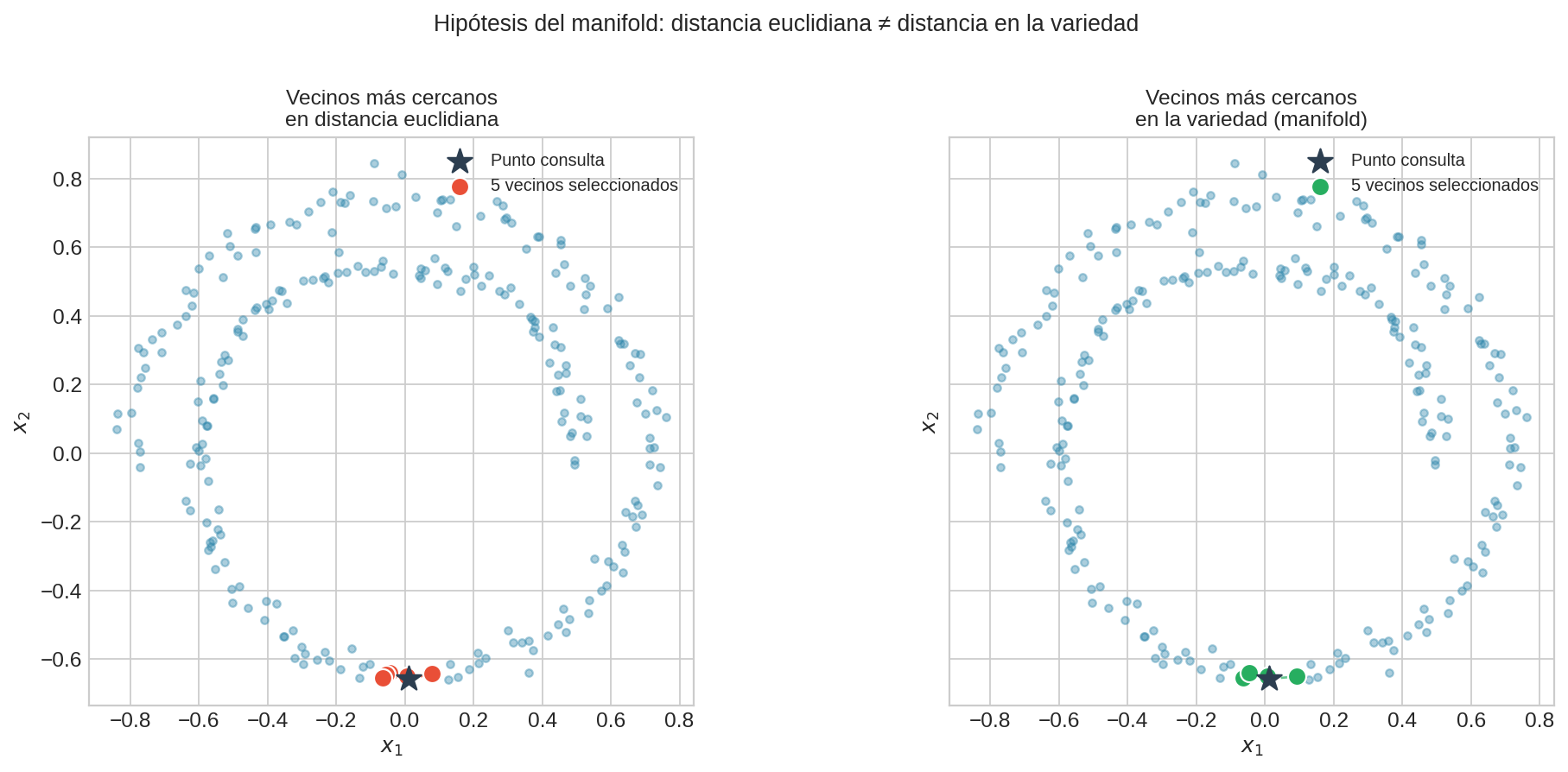
En el panel izquierdo, los 5 vecinos euclidianos del punto de consulta incluyen puntos de otra vuelta de la espiral — cerca en distancia euclidiana, pero lejanos en la variedad. En el panel derecho, los 5 vecinos del manifold (siguiendo la parametrización de la curva) están todos en el arco local correcto.
La distancia relevante para $f^{∗}$ no es la distancia euclidiana sino la distancia geodésica sobre el manifold. Estimarla requiere aprender la estructura de la variedad — algo que las redes neuronales hacen implícitamente mediante composición de funciones no lineales.
Puente hacia el aprendizaje profundo
Los desafíos anteriores motivan una solución unificada: redes neuronales profundas.
El marco general no cambia. Seguimos resolviendo:
$$ \hat{\theta} = \arg\min_\theta \hat{R}(\theta; \mathcal{D}) + \lambda \Omega(\theta) $$
Lo que cambia es la clase de hipótesis $\mathcal{H}$. En lugar de funciones lineales o polinomios:
$$ f_\theta(x) = W_L \cdot \phi_{L-1}(\cdots \phi_1(W_1 x + b_1) \cdots) + b_L $$
Las composiciones de funciones no lineales $\phi_\ell$ permiten que la red aprenda una representación de los datos antes de predecir. Cada capa “aplana” progresivamente el manifold — transformando la geometría del espacio de features para que $f^{∗}$ sea aproximadamente lineal en el último layer.
El resultado: la $d_{\text{VC}}$ efectiva crece en términos de $d_{\text{int}}$ (la dimensión del manifold), no en términos de $d$ (la dimensión ambient). Esto rompe la maldición de la dimensionalidad para los datos que siguen la hipótesis del manifold.
En la próxima clase exploraremos en detalle cómo diseñar, entrenar y analizar estas redes — armados ahora con el marco completo de error de Bayes, sesgo-varianza, regularización y estimación estadística que construimos en este módulo.
Siguiente: Módulo 23 — Redes Neuronales →