22.3 — Evaluación y selección de modelos
“El error de entrenamiento es una estimación sesgada del error de generalización. Siempre.”
El sesgo del error de entrenamiento
Proposición. Para cualquier modelo $\hat{f}$ ajustado a $\mathcal{D}_{\text{train}}$,
$$ \mathbb{E}_{\mathcal{D}}[\hat{R}(\hat{f}; \mathcal{D}_{\text{train}})] \leq R(\hat{f}) $$
Prueba. Sea $\hat{f} = \arg\min_{f \in \mathcal{H}} \hat{R}(f; \mathcal{D}_{\text{train}})$. Para cualquier $f_0 \in \mathcal{H}$ fija (que no depende de $\mathcal{D}$):
$$ \hat{R}(\hat{f}; \mathcal{D}_{\text{train}}) \leq \hat{R}(f_0; \mathcal{D}_{\text{train}}) $$
por definición de $\hat{f}$ como minimizador. Tomando esperanza:
$$ \mathbb{E}[\hat{R}(\hat{f}; \mathcal{D}_{\text{train}})] \leq \mathbb{E}[\hat{R}(f_0; \mathcal{D}_{\text{train}})] = R(f_0) $$
el último paso usa que $f_0$ no depende de $\mathcal{D}$, así que la esperanza del riesgo empírico es el riesgo verdadero. Como esto vale para cualquier $f_0$, también vale para $\hat{f}_0 = \arg\min R(f)$, y en particular $\mathbb{E}[\hat{R}(\hat{f}; \mathcal{D}_{\text{train}})] \leq R(\hat{f})$. $\square$
Consecuencia: el error de entrenamiento sistemáticamente subestima el error de generalización. El grado de sesgo crece con la capacidad de $\mathcal{H}$ — con $d_{\text{VC}}$ grande, el optimizador puede hacer $\hat{R}$ arbitrariamente pequeño aunque $R$ permanezca grande.
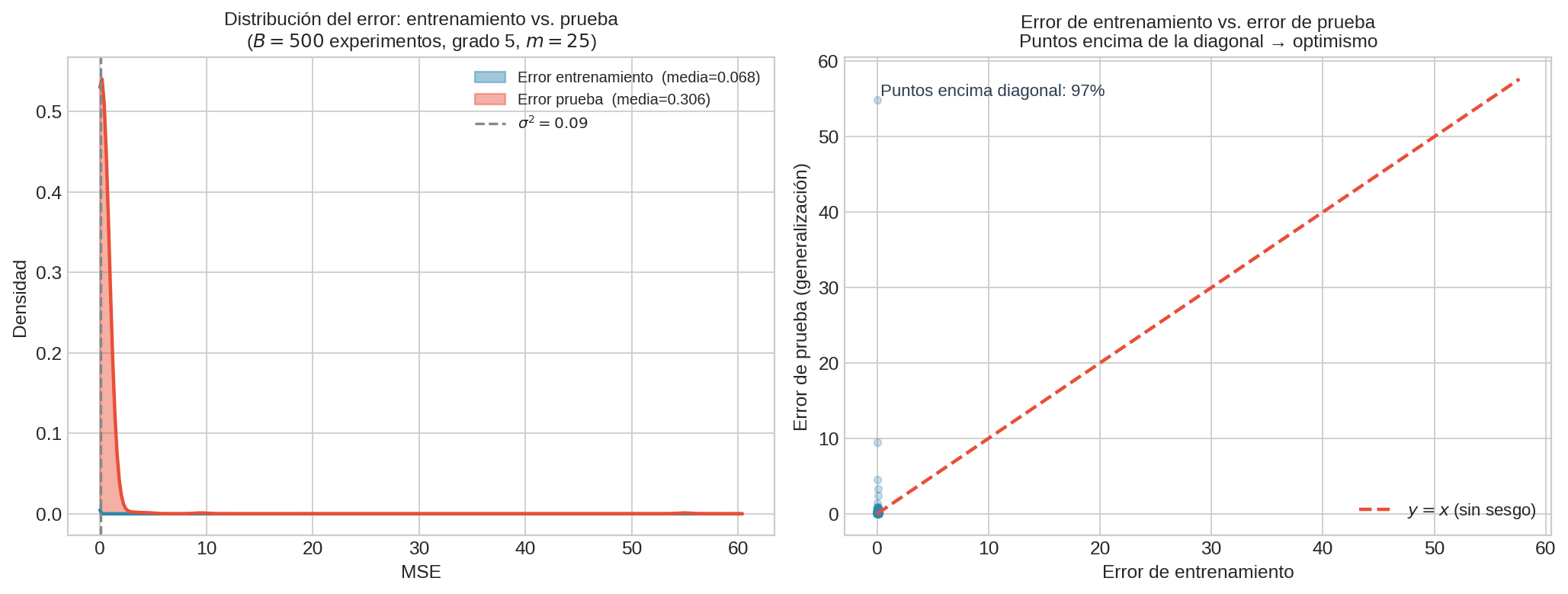
El panel izquierdo muestra que la distribución de error de entrenamiento (sobre $B=500$ experimentos) está desplazada sistemáticamente hacia la izquierda respecto al test. El panel derecho muestra que casi todos los puntos caen por encima de la diagonal $y = x$ — el error de test supera al de train en casi todos los casos.
Los tres conjuntos de datos
Dado el sesgo del error de entrenamiento, necesitamos datos no usados en el ajuste para estimar $R(\hat{f})$. Pero también necesitamos datos separados para elegir hiperparámetros — porque usar $\mathcal{D}_{\text{test}}$ para eso contamina la estimación final.
| Conjunto | Propósito | Puede ver |
|---|---|---|
| $\mathcal{D}_{\text{train}}$ | Ajustar $\theta$ | Sí, repetidamente |
| $\mathcal{D}_{\text{val}}$ | Elegir hiperparámetros ($\lambda$, grado, …) | Una vez por configuración |
| $\mathcal{D}_{\text{test}}$ | Reportar $R(\hat{f})$ final | Una sola vez, al final |
Por qué $\mathcal{D}_{\text{val}} \neq \mathcal{D}_{\text{test}}$. Si usamos $\mathcal{D}_{\text{test}}$ para seleccionar $\lambda^{∗}$, el procedimiento completo ha hecho búsqueda sobre $\mathcal{D}_{\text{test}}$. El error reportado ya no es una estimación insesgada de $R$ — es tan optimista como el error de entrenamiento. Esto invalida cualquier garantía de generalización.
Algoritmo 22.1 — Protocolo train/test
Algoritmo 22.1: Evaluación train/test
──────────────────────────────────────
Entrada: D = {(x^(i), y^(i))}_{i=1}^n, fracción α ∈ (0,1)
1. Mezclar D aleatoriamente
2. m_train ← ⌊α · n⌋
3. D_train ← D[1 : m_train]
4. D_test ← D[m_train+1 : n]
5. θ̂ ← arg min_{θ} R̂(θ; D_train) # ajustar modelo
6. ê_test ← R̂(θ̂; D_test) # estimar riesgo
7. Retornar θ̂, ê_test
──────────────────────────────────────
Limitación: usa solo $\alpha \cdot n$ puntos para entrenamiento. Con datasets pequeños, esta pérdida de datos reduce la calidad del modelo.
Algoritmo 22.2 — Protocolo train/val/test
Algoritmo 22.2: Selección de hiperparámetros + evaluación
───────────────────────────────────────────────────────────
Entrada: D, fracciones α_tr, α_val, Λ (cuadrícula de hiperparámetros)
1. Mezclar D aleatoriamente
2. D_train, D_val, D_test ← split(D, α_tr, α_val, 1-α_tr-α_val)
3. Para cada λ ∈ Λ:
a. θ̂_λ ← arg min_θ R̂(θ; D_train) + λ Ω(θ)
b. ê_val(λ) ← R̂(θ̂_λ; D_val)
4. λ* ← arg min_{λ ∈ Λ} ê_val(λ)
5. θ̂_final ← arg min_θ R̂(θ; D_train) + λ* Ω(θ)
6. ê_test ← R̂(θ̂_final; D_test) # reportar solo esto
7. Retornar θ̂_final, ê_test
───────────────────────────────────────────────────────────
Nota: el paso 5 puede re-entrenar con $\mathcal{D}_{\text{train}} \cup \mathcal{D}_{\text{val}}$ y $\lambda^{∗}$ fijo, aprovechando todos los datos para el modelo final. El error reportado sigue siendo $\hat{R}(\hat{\theta}; \mathcal{D}_{\text{test}})$.
Algoritmo 22.3 — Validación cruzada k-fold
Cuando $n$ es pequeño, la partición fija en Alg. 22.2 desperdicia datos. La validación cruzada k-fold rota el rol de validación:
Algoritmo 22.3: k-fold cross-validation
─────────────────────────────────────────
Entrada: D de tamaño n, número de folds k
1. Mezclar D aleatoriamente
2. Partir D en k bloques iguales: D_1, D_2, …, D_k
3. Para j = 1, …, k:
a. D_val^(j) ← D_j
b. D_train^(j) ← D \ D_j # todos los otros bloques
c. θ̂_j ← arg min_θ R̂(θ; D_train^(j))
d. e_j ← R̂(θ̂_j; D_val^(j))
4. ê_CV ← (1/k) Σ_{j=1}^k e_j
5. Retornar ê_CV
─────────────────────────────────────────
Este es el Algoritmo 5.1 de Goodfellow et al. (2016). Para $k = n$ se llama leave-one-out (LOO).
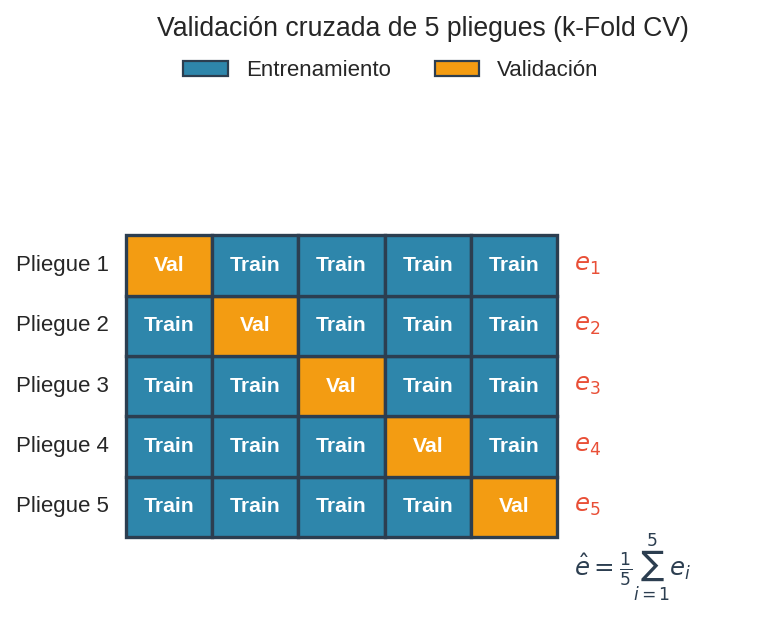
Cada fila es un fold: la celda naranja es el bloque de validación, las azules son entrenamiento. Los errores $e_1, \ldots, e_5$ se promedian para obtener $\hat{e}_{\text{CV}}$.
Varianza del estimador k-fold
El error $\hat{e}_{\text{CV}}$ es un estimador de $R(\hat{f})$, pero tiene varianza. Esta varianza depende de $k$ de forma no monótona:
| $k$ | Sesgo | Varianza entre datasets |
|---|---|---|
| 2 | Alto (solo 50% de datos para train) | Alta |
| 5–10 | Moderado | Baja (recomendado en práctica) |
| $n$ (LOO) | Muy bajo | Alta (cada estimado usa casi los mismos datos) |
La varianza de LOO es alta porque los $n$ modelos entrenados se solapan en $n-1$ puntos — sus errores están altamente correlacionados y el promedio no reduce la varianza tanto como lo haría con $k$ pequeño.
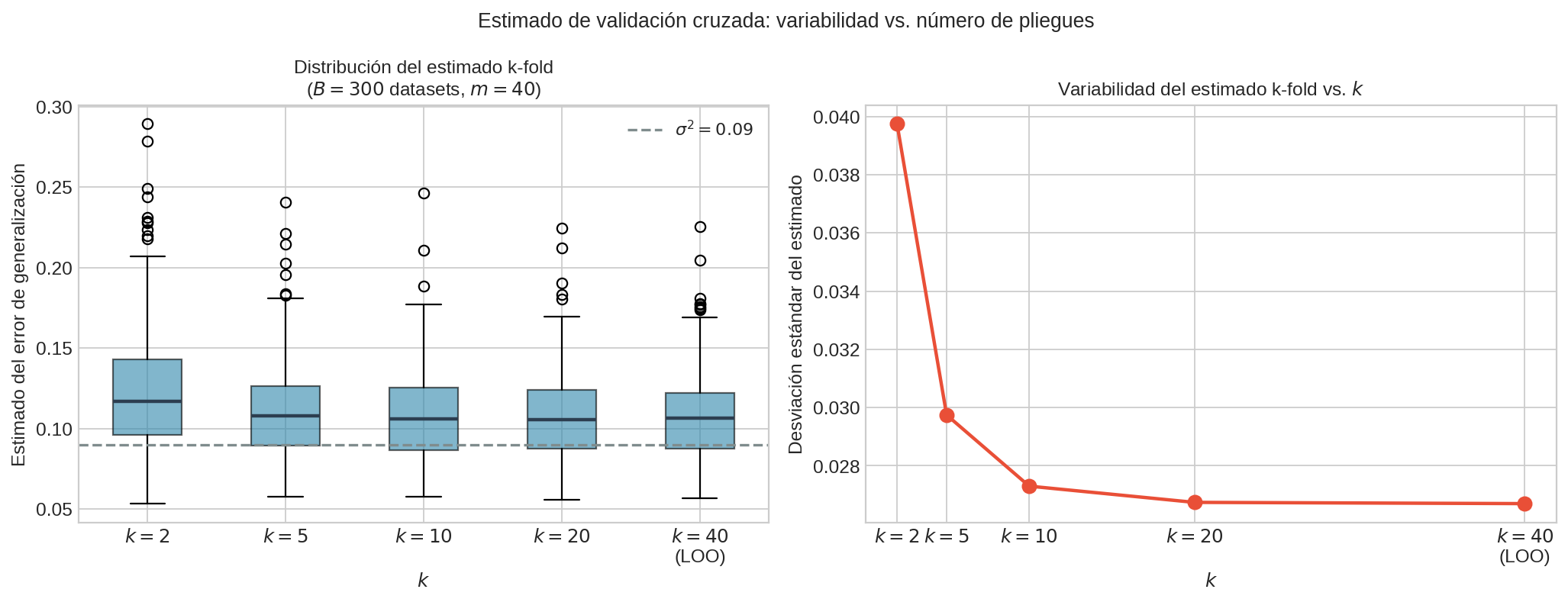
La U-curva empírica confirma que $k \in {5, 10}$ minimiza la varianza del estimador k-fold sobre múltiples datasets independientes. LOO ($k=40$ para $m=40$) tiene varianza más alta — coincide con el análisis teórico.
Siguiente: Estimadores estadísticos →