22.2 — Generalización
“Un modelo que memoriza el ruido no ha aprendido nada.”
A — Descomposición del error de generalización
El error de generalización $R(\hat{f})$ mide el desempeño del modelo sobre datos nuevos no vistos durante el entrenamiento. Para entender de dónde viene el exceso de error, introducimos un elemento de referencia.
El oráculo $f_{\mathcal{H}}^{∗}$. Dentro de la clase de hipótesis $\mathcal{H}$, existe un predictor ideal: el que minimizaría el error de generalización si conociéramos $p_{\text{data}}$:
$$ f_{\mathcal{H}}^{∗} = \arg\min_{f \in \mathcal{H}} R(f) $$
Este oráculo es inalcanzable en la práctica (requiere conocer $p_{\text{data}}$), pero sirve como pivote teórico para separar dos causas de error completamente distintas.
Derivación. Partimos del exceso $R(\hat{f}) - R^{∗}$ y sumamos y restamos $R(f_{\mathcal{H}}^{∗})$ — un cero algebraico:
$$ R(\hat{f}) - R^{∗} = \bigl[R(f_{\mathcal{H}}^{∗}) - R^{∗}\bigr] + \bigl[R(\hat{f}) - R(f_{\mathcal{H}}^{∗})\bigr] $$
Nombrar cada brecha da la descomposición exacta:
$$ \boxed{R(\hat{f}) - R^{∗} = \underbrace{(R(f_{\mathcal{H}}^{∗}) - R^{∗})}_{\varepsilon_{\text{approx}}} + \underbrace{(R(\hat{f}) - R(f_{\mathcal{H}}^{∗}))}_{\varepsilon_{\text{estim}}}} $$
| Componente | Qué mide | Controlado por |
|---|---|---|
| $\varepsilon_{\text{approx}}$ | Capacidad de la clase $\mathcal{H}$ | Tamaño/complejidad de $\mathcal{H}$ |
| $\varepsilon_{\text{estim}}$ | Muestras finitas, búsqueda en $\mathcal{H}$ | Tamaño $m$ del dataset |
| $R^{∗}$ | Ruido irreducible | Naturaleza del problema |
El dilema de capacidad
- $\mathcal{H}$ pequeño (poca capacidad): $\varepsilon_{\text{approx}}$ grande (underfitting), $\varepsilon_{\text{estim}}$ pequeño.
- $\mathcal{H}$ grande (mucha capacidad): $\varepsilon_{\text{approx}}$ pequeño, $\varepsilon_{\text{estim}}$ grande (overfitting).
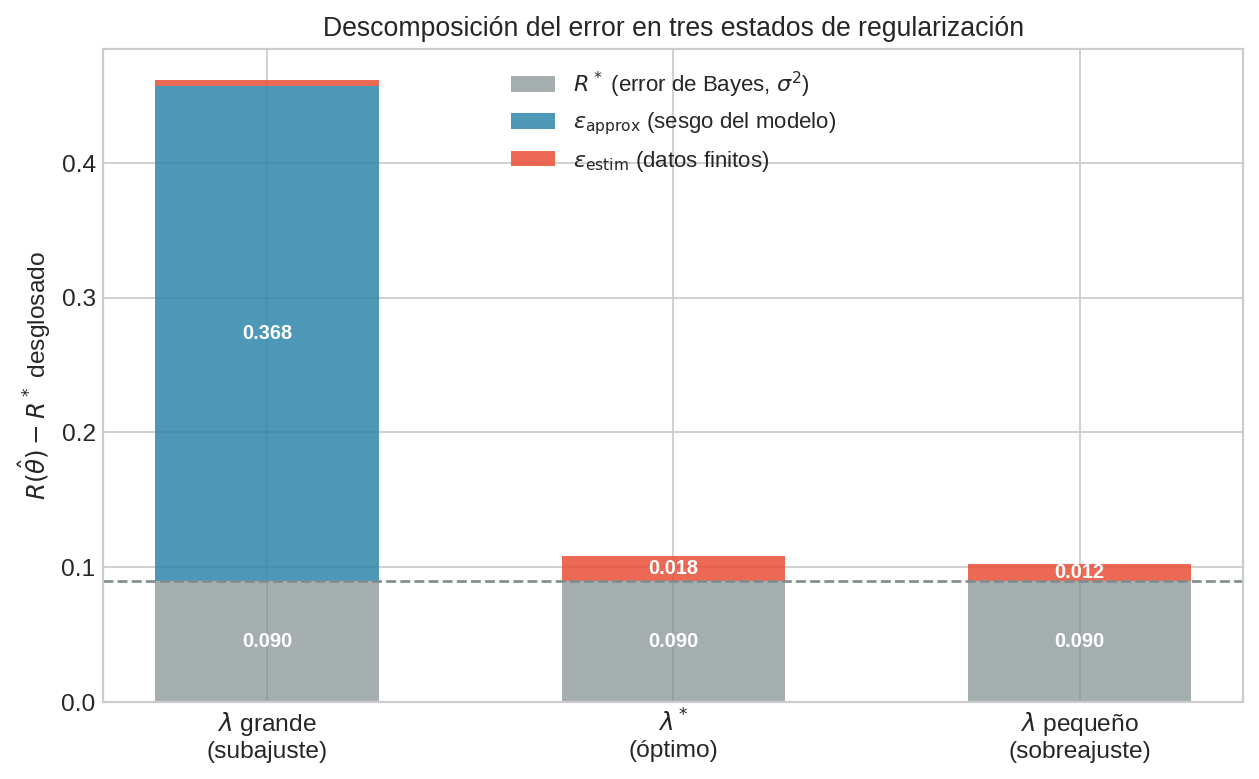
Las barras muestran valores reales del ejemplo polinomial: para grado 1 (underfitting), $\varepsilon_{\text{approx}}$ domina; para grado 14 sin regularización (overfitting), $\varepsilon_{\text{estim}}$ domina; con regularización óptima, ambos se equilibran.
B — Dimensión VC y cota de generalización
¿Cuánto puede crecer $\varepsilon_{\text{estim}}$ con la complejidad de $\mathcal{H}$? La respuesta formal viene de la dimensión VC (Vapnik-Chervonenkis).
Definición (informal). La dimensión VC de $\mathcal{H}$, $d_{\text{VC}}(\mathcal{H})$, es el tamaño del conjunto más grande que $\mathcal{H}$ puede clasificar perfectamente de todas las formas posibles (“romper”).
Ejemplos concretos:
- Clasificador lineal en $\mathbb{R}^d$: $d_{\text{VC}} = d + 1$
- Polinomio de grado $p$ en $\mathbb{R}$: $d_{\text{VC}} = p + 1$
- Red neuronal con $W$ pesos: $d_{\text{VC}} \approx O(W \log W)$
Cota de generalización (informal)
Con probabilidad $\geq 1 - \delta$ sobre la elección de $\mathcal{D}$:
$$ \boxed{R(\hat{f}) \leq \hat{R}(\hat{f}; \mathcal{D}) + C \sqrt{\frac{d_{\text{VC}}}{m}}} $$
La cota dice: el error de generalización no puede superar el error empírico más un término de penalización de complejidad que crece con $d_{\text{VC}}$ y decrece con $m$.
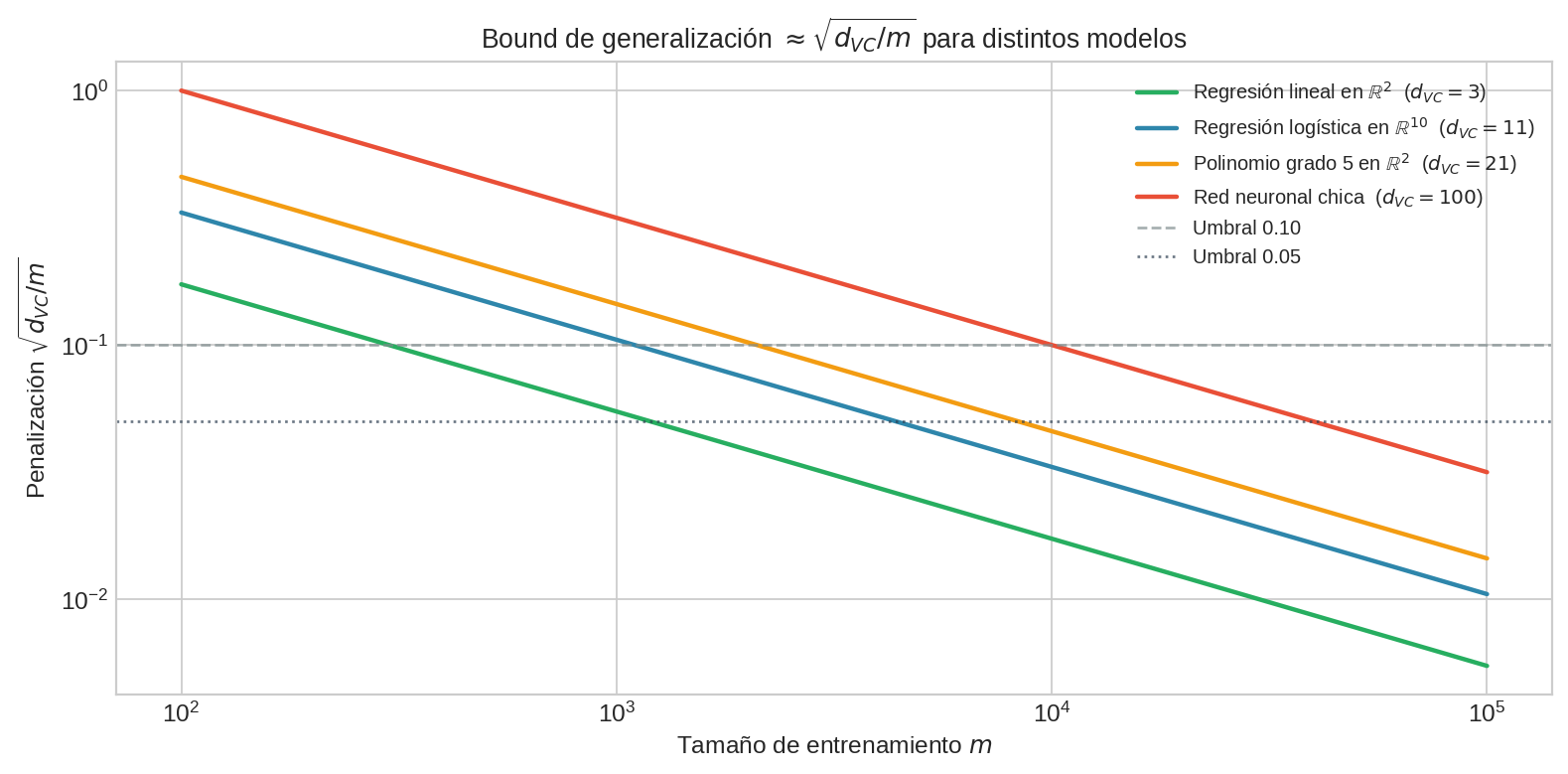
La figura muestra que para tener un margen de generalización $< 0.1$, un clasificador lineal en $\mathbb{R}^{10}$ ($d_{\text{VC}} = 11$) necesita $m \sim 1100$ ejemplos, mientras que una red con $d_{\text{VC}} = 100$ necesita $m \sim 10^4$.
C — ERM restringida, Lagrangiano y regularización
El problema de ERM restringida
En lugar de minimizar $\hat{R}$ libremente (lo que conduce a overfitting), restringimos la norma de los parámetros:
$$ \min_\theta \hat{R}(\theta; \mathcal{D}) \quad \text{s.t.} \quad \Omega(\theta) \leq s $$
donde $\Omega(\theta) = |\theta|^2$ es una medida de complejidad del modelo. Reducir $s$ restringe la capacidad efectiva de búsqueda — equivale a reducir $\varepsilon_{\text{estim}}$.
Relajación Lagrangiana
Por dualidad de Lagrange, el problema restringido es equivalente (para $\lambda \geq 0$ apropiado) a:
$$ \min_\theta \hat{R}(\theta; \mathcal{D}) + \lambda \Omega(\theta) $$
El multiplicador de Lagrange $\lambda \geq 0$ controla el intercambio entre ajuste a los datos y complejidad del modelo.
- $\lambda \to 0$: ERM sin restricción → overfitting.
- $\lambda \to \infty$: $\theta \to 0$ → underfitting.
- $\lambda$ óptimo: equilibra $\varepsilon_{\text{approx}}$ y $\varepsilon_{\text{estim}}$.
Definición. Los hiperparámetros son parámetros como $\lambda$ que controlan la capacidad o regularización del modelo. No pueden fijarse minimizando $\hat{R}(\theta; \mathcal{D}_{\text{train}})$ — hacerlo daría $\lambda = 0$ (la restricción siempre se relaja con más parámetros). Requieren datos separados de entrenamiento. Esto motiva directamente la sección 22.3.
$$ \boxed{\lambda \text{ es un hiperparámetro}: \quad \lambda^{∗} = \arg\min_{\lambda \geq 0} R(\hat{\theta}_\lambda) \quad \text{estimado con } \mathcal{D}_{\text{val}}} $$
Ridge regression: solución cerrada
Para regresión lineal con $\Omega(\theta) = |\theta|^2$ y $L = $ MSE, el Lagrangiano es:
$$ \mathcal{L}(\theta, \lambda) = \frac{1}{m}|\mathbf{X}\theta - \mathbf{y}|^2 + \lambda|\theta|^2 $$
Condición KKT de estacionaridad ($\nabla_\theta \mathcal{L} = 0$):
$$ \frac{2}{m}\mathbf{X}^\top(\mathbf{X}\theta - \mathbf{y}) + 2\lambda\theta = 0 $$
$$ \left(\frac{1}{m}\mathbf{X}^\top\mathbf{X} + \lambda\mathbf{I}\right)\theta = \frac{1}{m}\mathbf{X}^\top\mathbf{y} $$
$$ \boxed{\theta^{∗} = \left(\frac{1}{m}\mathbf{X}^\top\mathbf{X} + \lambda\mathbf{I}\right)^{-1} \frac{1}{m}\mathbf{X}^\top\mathbf{y}} $$
La adición de $\lambda\mathbf{I}$ garantiza que la matriz sea invertible para todo $\lambda > 0$, incluso cuando $\mathbf{X}^\top\mathbf{X}$ es singular (caso $m < d$). Esto es ridge regression.
Underfitting y overfitting en acción
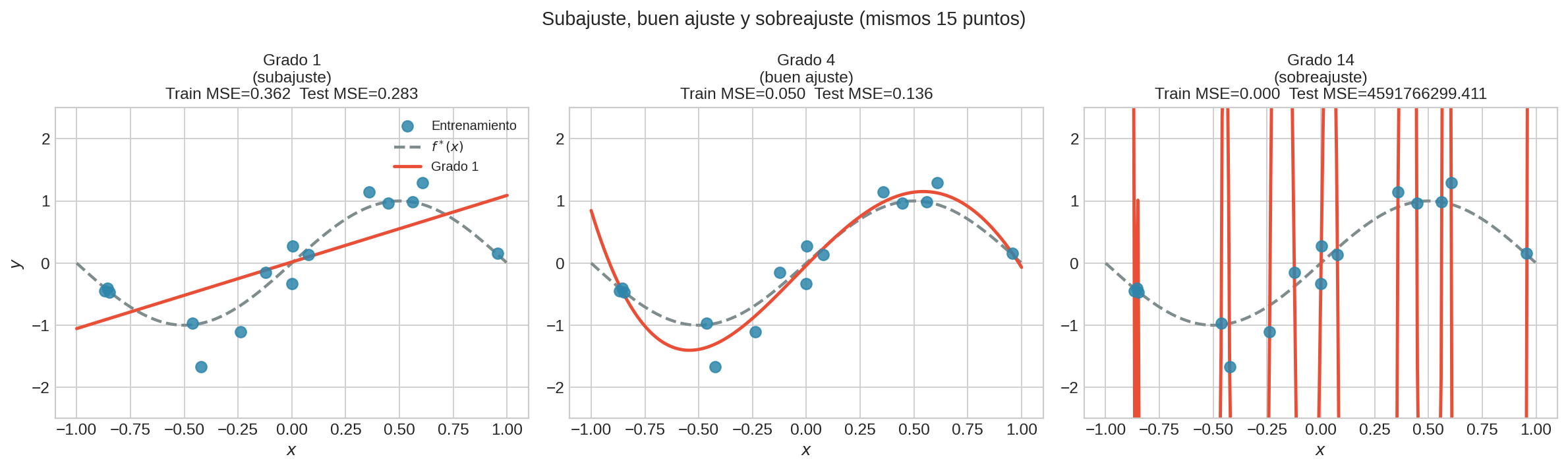
- Grado 1: $\varepsilon_{\text{approx}}$ grande — $\mathcal{H}$ no puede representar $\sin(\pi x)$.
- Grado 4: equilibrio — ajusta bien, generaliza bien.
- Grado 14: $\varepsilon_{\text{estim}}$ grande — memoriza el ruido, MSE de test explota.
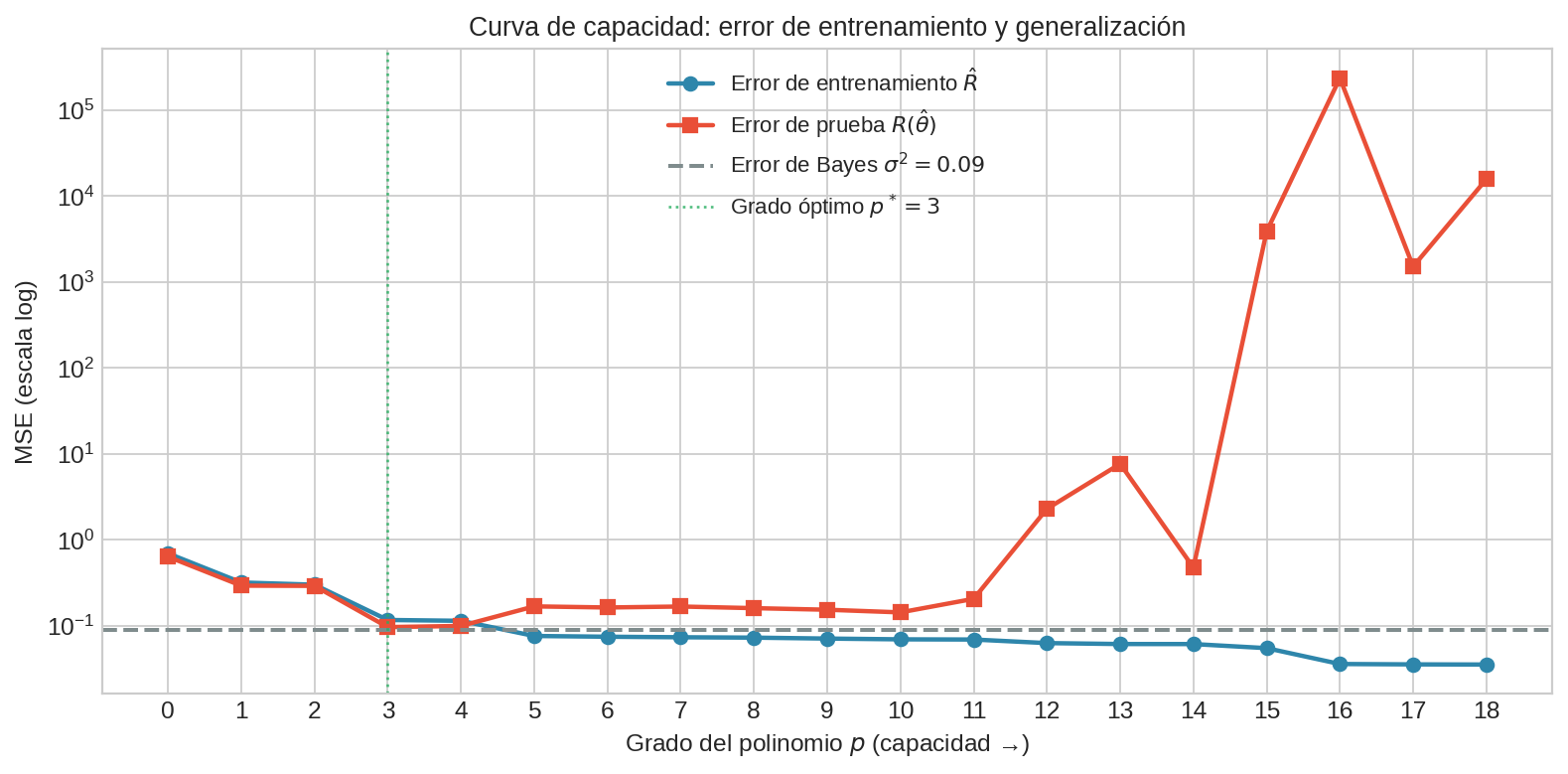
La línea punteada en $\sigma^2 = 0.09$ es el error de Bayes — el piso irreducible. Con grado óptimo, el test MSE se aproxima a $\sigma^2$ desde arriba.
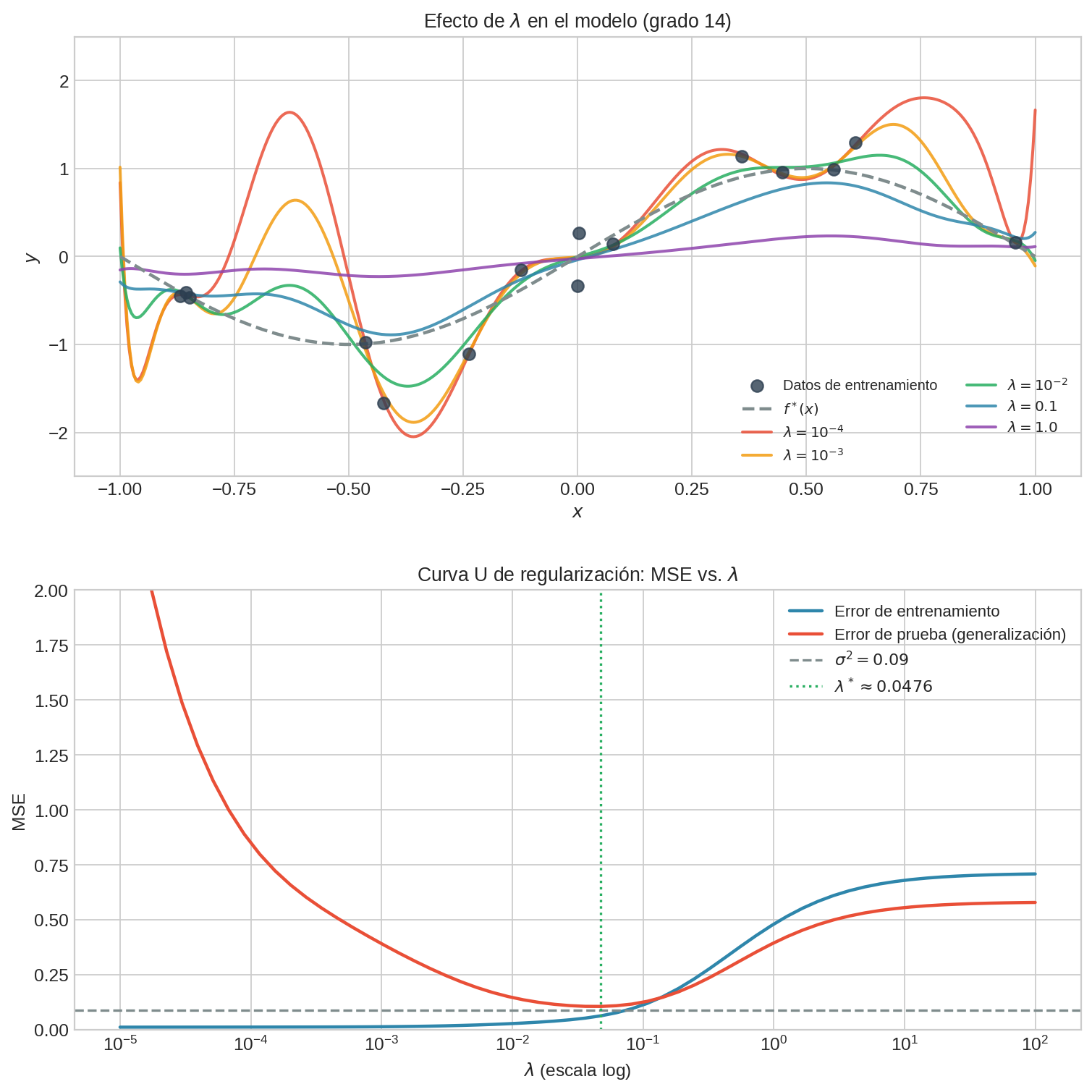
El panel superior muestra cómo $\lambda$ grande “aplana” la curva de grado 14. El panel inferior muestra la U-curva característica: existe un $\lambda^{∗}$ que minimiza el test MSE.
Tabla comparativa: sin regularización vs. ridge
| Característica | ERM pura ($\lambda = 0$) | Ridge ($\lambda > 0$) |
|---|---|---|
| Sesgo | Bajo | Mayor (si $\lambda$ grande) |
| Varianza | Alta | Menor |
| Invertibilidad | Falla si $m < d$ | Siempre invertible |
| $\lambda$ elegido por | — | $\mathcal{D}_{\text{val}}$ |
D — No Free Lunch y MAP
Teorema NFL (Wolpert, 1996)
Promediando sobre todas las distribuciones de datos posibles, ningún algoritmo de aprendizaje es mejor que ningún otro. Formalmente: para cualquier algoritmo $\mathcal{A}$ y cualquier métrica de desempeño $P$,
$$ \sum_{f} \mathbb{E}[P(\mathcal{A}, f)] = \text{constante independiente de } \mathcal{A} $$
Implicación práctica: el aprendizaje requiere supuestos. No existe el algoritmo universal. Cada método incorpora un sesgo inductivo — una preferencia implícita por cierto tipo de funciones. La pregunta correcta no es “¿cuál es el mejor algoritmo?” sino “¿cuáles son los supuestos de este algoritmo y son razonables para mi problema?”.
MAP como regularización bayesiana
Desde la perspectiva bayesiana, la regularización ridge corresponde a imponer un prior gaussiano sobre los parámetros:
$$ p(\theta) = \mathcal{N}(0, \tfrac{1}{2\lambda}\mathbf{I}) $$
El estimador MAP (Maximum A Posteriori) maximiza $p(\theta \mid \mathcal{D}) \propto p(\mathcal{D} \mid \theta) p(\theta)$, que equivale exactamente a minimizar:
$$ -\log p(\mathcal{D} \mid \theta) - \log p(\theta) = \frac{1}{m}|\mathbf{X}\theta - \mathbf{y}|^2 + \lambda|\theta|^2 $$
El Lagrangiano de regularización es el negativo del log-posterior MAP. El hiperparámetro $\lambda$ codifica la precisión del prior — cuánto creemos que los parámetros deben ser pequeños antes de ver datos.
Siguiente: Evaluación →