Algoritmo Forward
Problema 1 — Evaluación: ¿Con qué probabilidad generó este modelo la secuencia $O$?
1. ¿Para qué sirve $P(O \mid \lambda)$?
Antes de calcular nada, conviene entender para qué necesitamos $P(O \mid \lambda)$.
Comparar modelos. Supón que tienes dos HMMs entrenados: $\lambda_1$ para reconocer la palabra “hola” y $\lambda_2$ para “adiós”. Llega una nueva grabación de audio $O$. ¿Qué palabra es? Calculas $P(O \mid \lambda_1)$ y $P(O \mid \lambda_2)$ y eliges la mayor. Así funciona el núcleo del reconocimiento de voz clásico.
Detectar anomalías. Si $P(O \mid \lambda)$ es muy pequeño, la secuencia observada es improbable bajo el modelo entrenado — señal de que algo inusual ocurrió (fraude, falla de hardware, etc.).
Subroutine de aprendizaje. El algoritmo Baum-Welch (sección 20.5) necesita $P(O \mid \lambda)$ en cada iteración para actualizar los parámetros.
En todos los casos la pregunta es la misma: dado el modelo $\lambda = (\pi, A, B)$ y la secuencia observada $O = (O_1, \ldots, O_T)$, calcula $P(O \mid \lambda)$.
2. La probabilidad que queremos calcular
$O = (O_1, \ldots, O_T)$ es la secuencia completa que observamos. Cada $O_t$ es un entero en ${0, \ldots, M-1}$ — el valor concreto de la observación en el instante $t$, usado como índice de columna en $B$. Lo que queremos es $P(O \mid \lambda)$: la probabilidad de ver exactamente esa secuencia.
¿De dónde viene $P(O \mid \lambda)$?
$O$ se generó junto con una secuencia de estados ocultos $q = (q_1, \ldots, q_T)$ que no vemos. Para eliminar esos estados ocultos y quedarnos solo con $P(O \mid \lambda)$, aplicamos marginación: sumamos sobre todas las trayectorias ocultas posibles.
$$P(O \mid \lambda) = \sum_{q_1} \sum_{q_2} \cdots \sum_{q_T} P(O,, q_1, \ldots, q_T \mid \lambda)$$
Ley de probabilidad total: si no conocemos los estados ocultos, sumamos sobre todos sus valores posibles.
Cada término $P(O, q \mid \lambda)$ es la probabilidad conjunta de una trayectoria específica de estados Y las observaciones. Por la regla del producto, la propiedad de Markov y la independencia de emisión del HMM, factoriza como:
$$P(O, q \mid \lambda) = \pi_{q_1} \cdot B_{q_1,O_1} \cdot A_{q_1,q_2} \cdot B_{q_2,O_2} \cdots A_{q_{T-1},q_T} \cdot B_{q_T,O_T}$$
Cada factor tiene su origen: $\pi_{q_1}$ arranca el proceso en $q_1$; $B_{q_t,O_t}$ emite la observación $O_t$ desde el estado $q_t$ (donde $O_t$ es el índice de columna); $A_{q_t,q_{t+1}}$ transita al estado siguiente.
El problema: $N^T$ trayectorias
Con $N$ estados y $T$ pasos hay $N^T$ trayectorias. Para $N=2$, $T=3$ son $2^3 = 8$ — manejable. Para $N=10$, $T=100$ son $10^{100}$ — imposible.
El algoritmo Forward evita esta explosión con programación dinámica: observa que muchos de esos $N^T$ términos comparten sub-trayectorias y reutiliza los cálculos. La siguiente sección muestra exactamente cómo emerge esa estructura.
3. Construyendo $\alpha$ — del caso simple a la recursión
Antes de dar la fórmula general, la vamos a descubrir trabajando con el ejemplo de Lain: $N=2$ estados ${S, R}$, $O = (0, 1, 1)$.
3.1 Caso $T = 1$: una sola observación
Con $O_1 = 0$ y dos estados, hay exactamente 2 trayectorias posibles: $q_1 = S$ y $q_1 = R$. La marginación es trivial:
$$P(O_1 \mid \lambda) = P(O_1,, q_1=S \mid \lambda) + P(O_1,, q_1=R \mid \lambda)$$
Cada término se descompone por la regla del producto más la independencia de emisión del HMM ($O_1$ depende solo de $q_1$, no de nada más):
$$P(O_1,, q_1 = i \mid \lambda) = P(q_1 = i) \cdot P(O_1 \mid q_1 = i) = \pi_i \cdot B_{i,O_1}$$
Con $O_1 = 0$ (seleccionamos la columna 0 de $B$):
$$\pi_S \cdot B_{S,0} = 0.6 \times 0.9 = 0.540$$ $$\pi_R \cdot B_{R,0} = 0.4 \times 0.2 = 0.080$$ $$P(O_1=0 \mid \lambda) = 0.540 + 0.080 = 0.620$$
Le damos nombre a cada término: $\alpha_1(i) = \pi_i \cdot B_{i,O_1}$. Así $\alpha_1(S) = 0.540$, $\alpha_1(\mathrm{R}) = 0.080$ y $P(O_1 \mid \lambda) = \sum_i \alpha_1(i)$.
3.2 Caso $T = 2$: cuatro caminos, una factorización clave
Con $O = (O_1, O_2) = (0, 1)$ y $N = 2$ hay $N^2 = 4$ trayectorias. Las listamos todas explícitamente:
| Trayectoria | Cálculo | Valor |
|---|---|---|
| $(S, S)$ | $\pi_S \cdot B_{S,0} \cdot A_{SS} \cdot B_{S,1}$ | $0.6 \times 0.9 \times 0.7 \times 0.1 = 0.0378$ |
| $(S, R)$ | $\pi_S \cdot B_{S,0} \cdot A_{SR} \cdot B_{R,1}$ | $0.6 \times 0.9 \times 0.3 \times 0.8 = 0.1296$ |
| $(R, S)$ | $\pi_R \cdot B_{R,0} \cdot A_{RS} \cdot B_{S,1}$ | $0.4 \times 0.2 \times 0.4 \times 0.1 = 0.0032$ |
| $(R, R)$ | $\pi_R \cdot B_{R,0} \cdot A_{RR} \cdot B_{R,1}$ | $0.4 \times 0.2 \times 0.6 \times 0.8 = 0.0384$ |
Suma: $P(O \mid \lambda) = 0.0378 + 0.1296 + 0.0032 + 0.0384 = 0.2090$.
Ahora observamos la estructura algebraica: agrupemos los caminos que terminan en el mismo estado en $t=2$.
Caminos que terminan en $S$: $(S,S)$ y $(R,S)$. Factorizamos $B_{S,1}$:
$$(\pi_S \cdot B_{S,0} \cdot A_{SS} + \pi_R \cdot B_{R,0} \cdot A_{RS}) \cdot B_{S,1}$$
Caminos que terminan en $R$: $(S,R)$ y $(R,R)$. Factorizamos $B_{R,1}$:
$$(\pi_S \cdot B_{S,0} \cdot A_{SR} + \pi_R \cdot B_{R,0} \cdot A_{RR}) \cdot B_{R,1}$$
Reconocemos $\pi_S \cdot B_{S,0} = \alpha_1(S)$ y $\pi_R \cdot B_{R,0} = \alpha_1(\mathrm{R})$:
$$P(O \mid \lambda) = [\alpha_1(S) \cdot A_{SS} + \alpha_1(\mathrm{R}) \cdot A_{RS}] \cdot B_{S,1} + [\alpha_1(S) \cdot A_{SR} + \alpha_1(\mathrm{R}) \cdot A_{RR}] \cdot B_{R,1}$$
Definimos los nuevos acumuladores:
$$\alpha_2(S) = [\alpha_1(S) \cdot A_{SS} + \alpha_1(\mathrm{R}) \cdot A_{RS}] \cdot B_{S,1} = [0.540 \times 0.7 + 0.080 \times 0.4] \times 0.1 = 0.041$$
$$\alpha_2(\mathrm{R}) = [\alpha_1(S) \cdot A_{SR} + \alpha_1(\mathrm{R}) \cdot A_{RR}] \cdot B_{R,1} = [0.540 \times 0.3 + 0.080 \times 0.6] \times 0.8 = 0.168$$
Y entonces $P(O \mid \lambda) = \alpha_2(S) + \alpha_2(\mathrm{R}) = 0.041 + 0.168 = 0.209$.
Acabamos de descubrir la recursión: en lugar de enumerar los $N^t$ caminos desde cero, reutilizamos los $N$ valores $\alpha_{t-1}$ ya calculados.
3.3 La recursión general — y su fundamento probabilístico
El mismo patrón aparece a cada paso. Para el instante $t$ y el estado destino $j$, la definición de $\alpha_t(j)$ es:
$$\alpha_t(j) = P(O_1, O_2, \ldots, O_t,, q_t = j \mid \lambda)$$
Aplicamos la ley de probabilidad total sobre el estado en $t-1$ (toda trayectoria hasta $(t, j)$ pasa por algún estado $i$ en $t-1$):
$$\alpha_t(j) = \sum_{i=1}^{N} P(O_1, \ldots, O_t,, q_{t-1}=i,, q_t=j \mid \lambda)$$
Descomponemos cada término por la regla del producto, más dos propiedades del HMM:
$$= \sum_{i=1}^{N} P(O_1, \ldots, O_{t-1},, q_{t-1}=i \mid \lambda) \cdot P(q_t=j \mid q_{t-1}=i) \cdot P(O_t \mid q_t=j)$$
donde:
- $P(q_t=j \mid q_{t-1}=i,, O_1,\ldots,O_{t-1}) = P(q_t=j \mid q_{t-1}=i) = A_{ij}$ — propiedad de Markov: el siguiente estado depende solo del estado actual, no del historial de observaciones.
- $P(O_t \mid q_t=j,, q_{t-1}=i,, O_1,\ldots,O_{t-1}) = P(O_t \mid q_t=j) = B_{j,O_t}$ — independencia de emisión del HMM: $O_t$ depende solo del estado oculto en ese instante.
- $P(O_1, \ldots, O_{t-1},, q_{t-1}=i \mid \lambda) = \alpha_{t-1}(i)$ — definición recursiva: lo que ya calculamos en el paso anterior.
Sustituyendo:
$$\alpha_t(j) = \left[\sum_{i=1}^{N} \alpha_{t-1}(i) \cdot A_{ij}\right] \cdot B_{j,O_t}$$
Cada factor tiene su papel:
- $\alpha_{t-1}(i)$: información pasada comprimida — probabilidad conjunta de observaciones hasta $t-1$ y del estado $i$.
- $A_{ij}$: transición de $i$ a $j$ (propiedad de Markov).
- $\sum_i$: ley de probabilidad total — marginamos sobre todos los estados de origen.
- $B_{j,O_t}$: emisión del valor $O_t$ desde el estado $j$ (independencia del HMM).
4. La variable forward $\alpha_t(i)$
La clave del DP es que $\alpha_t(i)$ es el subproblema exacto que necesitamos en cada paso:
$$\alpha_t(i) = P(O_1, O_2, \ldots, O_t, q_t = i \mid \lambda)$$
En palabras: la probabilidad de que, al llegar al instante $t$, se hayan observado exactamente $O_1, \ldots, O_t$ y el sistema esté en el estado $i$.
Intuición operacional: $\alpha_t(i)$ es un acumulador. En vez de recordar las $N^{t-1}$ trayectorias que llegan a $(t, i)$, comprime toda esa información en un único número. Cuando calculamos $\alpha_t$, ya no necesitamos $\alpha_{t-2}, \alpha_{t-3}, \ldots$ — solo $\alpha_{t-1}$.
Nota: $\alpha_t(i)$ es una probabilidad conjunta (observaciones + estado), no condicional. En particular $\sum_i \alpha_t(i) \neq 1$ en general — solo en $t=T$ la suma da $P(O \mid \lambda)$.
5. Los tres pasos del algoritmo
[P1] Inicialización ($t = 1$):
$$\alpha_1(i) = \pi_i \cdot B_{i,O_1} \qquad \text{para todo } i = 1, \ldots, N$$
- $\pi_i$: probabilidad de que el estado inicial sea $i$.
- $B_{i,O_1}$: probabilidad de emitir la primera observación desde el estado $i$. Aquí $O_1$ es el valor de la primera observación (por ejemplo, si $O_1 = 0$, entonces $B_{i,O_1} = B_{i,0}$, la columna 0 de la fila $i$ de la matriz $B$).
[P2] Recursión ($t = 2, 3, \ldots, T$):
$$\alpha_t(j) = \left[\sum_{i=1}^{N} \alpha_{t-1}(i) \cdot A_{ij}\right] \cdot B_{j,O_t} \qquad \text{para todo } j = 1, \ldots, N$$
Desglose para el estado destino $j$ en el instante $t$:
- Desde cada estado de origen $i$ en $t-1$, tomo la probabilidad acumulada $\alpha_{t-1}(i)$.
- La pondero por la probabilidad de transitar de $i$ a $j$: $A_{ij}$.
- Sumo sobre todos los posibles estados de origen $i$ — no hay que elegir, todas las rutas contribuyen.
- Multiplico por $B_{j,O_t}$: la probabilidad de emitir la observación $O_t$ desde $j$.
[P3] Terminación:
$$P(O \mid \lambda) = \sum_{i=1}^{N} \alpha_T(i)$$
En el último instante el sistema puede estar en cualquier estado. La probabilidad total de toda la secuencia es la suma sobre todos los estados finales posibles.
6. El trellis: cómo visualizar el cómputo
El trellis (enrejado) es la estructura de datos del algoritmo. Entenderlo hace que la recursión sea obvia.
Estructura del trellis:
t=1 t=2 t=3
┌──────┐ ┌──────┐ ┌──────┐
S ── │α₁(S) │ ──→ │α₂(S) │ ──→ │α₃(S) │
└──────┘ ↘ └──────┘ ↘ └──────┘
↘ ↗ ↘ ↗
┌──────┐ ↗ ┌──────┐ ↗ ┌──────┐
R ── │α₁(R) │ ──→ │α₂(R) │ ──→ │α₃(R) │
└──────┘ └──────┘ └──────┘
O₁=0 O₂=1 O₃=1
Qué significa cada elemento:
- Columna = un instante de tiempo $t$.
- Fila = un estado oculto (S o R en nuestro ejemplo).
- Nodo $(t, i)$ = almacena el valor $\alpha_t(i)$.
- Flecha de $(t-1, i)$ a $(t, j)$ = la contribución $\alpha_{t-1}(i) \cdot A_{ij}$ que el nodo anterior aporta al nodo actual. Hay $N \times N$ flechas entre cada par de columnas — todos los estados anteriores contribuyen a todos los estados siguientes.
Cómo se calcula cada nodo:
El nodo $\alpha_t(j)$ recibe contribuciones de todos los nodos de la columna anterior (eso es la suma $\sum_i \alpha_{t-1}(i) \cdot A_{ij}$), y luego multiplica por la emisión $B_{j,O_t}$ de ese instante. Las flechas que “cruzan” (S→R y R→S) representan las transiciones $A_{SR}$ y $A_{RS}$ — también se suman.
Dirección del cómputo: siempre de izquierda a derecha (pasado → futuro). Cada columna depende solo de la columna inmediatamente anterior.
Por qué se llama trellis: su forma de rejilla recuerda a una celosía (trellis en inglés) — una estructura periódica con cruces entre filas.
Con valores del ejemplo de Lain:
Estado │ t=1 t=2 t=3
───────┼────────────────────────────────────────────
S │ 0.54000 ────→ 0.04100 ────→ 0.00959
│ ╲ ↗ ╲ ↗
│ ╲╱ ╲ ╱
│ ╱╲ ╲ ╱
R │ 0.08000 ────→ 0.16800 ────→ 0.09048
│ (también hay flechas cruzadas)
O_t │ O₁=0 O₂=1 O₃=1
────────────────────────────────────→ tiempo
Resultado final: $P(O \mid \lambda) = 0.00959 + 0.09048 = 0.10007$
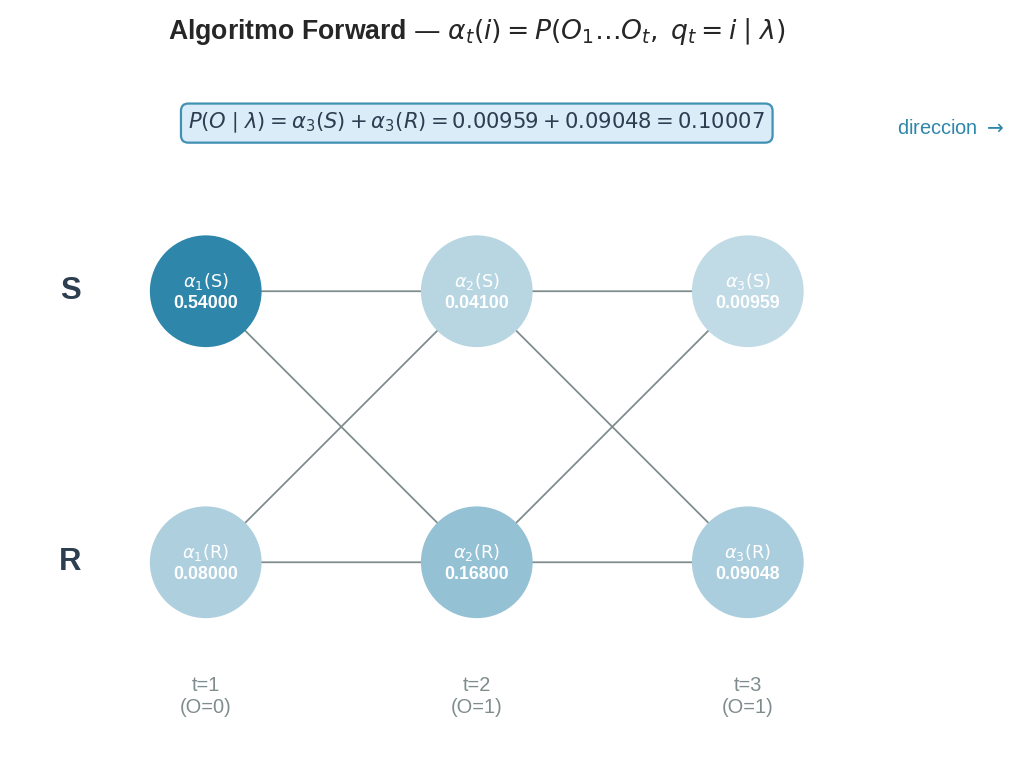
7. Traza completa: el ejemplo de Lain
Parámetros: $\pi = (0.6, 0.4)$, $O = (0, 1, 1)$
Las matrices con sus entradas etiquetadas explícitamente:
$$A = \begin{pmatrix} A_{SS} & A_{SR} \\ A_{RS} & A_{RR} \end{pmatrix} = \begin{pmatrix} 0.7 & 0.3 \\ 0.4 & 0.6 \end{pmatrix}, \qquad B = \begin{pmatrix} B_{S,0} & B_{S,1} \\ B_{R,0} & B_{R,1} \end{pmatrix} = \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix}$$
Paso 1 — Inicialización ($O_1 = 0$, usamos la columna 0 de $B$):
$$\alpha_1(S) = \pi_S \cdot B_{S,0} = 0.6 \times 0.9 = 0.540$$ $$\alpha_1(\mathrm{R}) = \pi_R \cdot B_{R,0} = 0.4 \times 0.2 = 0.080$$
Intuición: el día 1 no hay paraguas ($O_1=0$). Alta probabilidad en “Soleado” porque $\pi_S=0.6$ y $B_{S,0}=0.9$ son ambos altos.
Paso 2 — Recursión ($O_2 = 1$, usamos la columna 1 de $B$):
Para el estado $S$ en $t=2$ — ¿de qué estados anteriores puedo venir?
$$\alpha_2(S) = [\alpha_1(S) \cdot A_{SS} + \alpha_1(\mathrm{R}) \cdot A_{RS}] \cdot B_{S,1}$$ $$= [0.540 \times 0.7 + 0.080 \times 0.4] \times 0.1 = [0.378 + 0.032] \times 0.1 = 0.041$$
Para el estado $R$ en $t=2$:
$$\alpha_2(\mathrm{R}) = [\alpha_1(S) \cdot A_{SR} + \alpha_1(\mathrm{R}) \cdot A_{RR}] \cdot B_{R,1}$$ $$= [0.540 \times 0.3 + 0.080 \times 0.6] \times 0.8 = [0.162 + 0.048] \times 0.8 = 0.168$$
Intuición: el día 2 hay paraguas ($O_2=1$). “Lluvioso” toma ventaja: $\alpha_2(\mathrm{R}) = 0.168 \gg \alpha_2(S) = 0.041$.
Paso 3 — Recursión ($O_3 = 1$, columna 1 de $B$ otra vez):
$$\alpha_3(S) = [\alpha_2(S) \cdot A_{SS} + \alpha_2(\mathrm{R}) \cdot A_{RS}] \cdot B_{S,1}$$ $$= [0.041 \times 0.7 + 0.168 \times 0.4] \times 0.1 = [0.0287 + 0.0672] \times 0.1 = 0.00959$$
$$\alpha_3(\mathrm{R}) = [\alpha_2(S) \cdot A_{SR} + \alpha_2(\mathrm{R}) \cdot A_{RR}] \cdot B_{R,1}$$ $$= [0.041 \times 0.3 + 0.168 \times 0.6] \times 0.8 = [0.0123 + 0.1008] \times 0.8 = 0.09048$$
Terminación:
$$P(O \mid \lambda) = \alpha_3(S) + \alpha_3(\mathrm{R}) = 0.00959 + 0.09048 = \mathbf{0.10007}$$
Tabla resumen:
| $t$ | $O_t$ | $\alpha_t(S)$ | $\alpha_t(\mathrm{R})$ | Suma |
|---|---|---|---|---|
| 1 | 0 | 0.54000 | 0.08000 | 0.62000 |
| 2 | 1 | 0.04100 | 0.16800 | 0.20900 |
| 3 | 1 | 0.00959 | 0.09048 | 0.10007 |
La suma por fila no tiene por qué ser 1 — los $\alpha_t$ son probabilidades conjuntas (estado + observaciones hasta $t$). Solo en $t=T$ la suma da exactamente $P(O \mid \lambda)$.
8. Pseudocódigo
función FORWARD(O, π, A, B):
T ← longitud(O) # número de observaciones en la secuencia
N ← número de estados ocultos posibles
# ── [P1] Inicialización ────────────────────────────────────────────────────
# Caso base: en t=1 no hay estado anterior.
# α[1][i] = prob. de iniciar en estado i × prob. de emitir O[1] desde i.
para i = 1 hasta N:
α[1][i] ← π[i] × B[i][O[1]]
# ↑ ↑
# prob. inicio B indexada por el VALOR de la observación O[1]
# ── [P2] Recursión ─────────────────────────────────────────────────────────
# Avanzamos columna por columna, de t=2 hasta T.
# Para cada estado destino j, acumulamos las contribuciones de TODOS
# los estados de origen i (bucle interno), ponderadas por A[i][j].
# Luego multiplicamos por la emisión B[j][O[t]].
para t = 2 hasta T:
para j = 1 hasta N: # j = estado destino en t
suma ← 0
para i = 1 hasta N: # i = estado de origen en t-1
suma ← suma + α[t-1][i] × A[i][j]
# ↑ α pasado ↑ transición i→j
α[t][j] ← suma × B[j][O[t]]
# ↑ emitir O[t] desde j
# Nota: B[j][O[t]] usa el VALOR de la observación como índice de columna
# ── [P3] Terminación ───────────────────────────────────────────────────────
# Sumamos sobre todos los estados finales posibles.
# El sistema puede terminar en cualquier estado, así que sumamos todo.
P_obs ← 0
para i = 1 hasta N:
P_obs ← P_obs + α[T][i]
retornar α, P_obs # α contiene todos los valores; P_obs = P(O | λ)
9. Complejidad
| Método | Tiempo | Espacio |
|---|---|---|
| Ingenuo — enumerar las $N^T$ trayectorias | $O(N^T \cdot T)$ | $O(N^T)$ |
| Forward — programación dinámica | $O(N^2 T)$ | $O(N T)$ |
El ahorro es exponencial: para $N=10$, $T=100$, el método ingenuo requiere $\sim 10^{102}$ operaciones; Forward solo $100{,}000$.
De dónde viene $N^2 T$: en cada uno de los $T$ pasos de tiempo, para cada uno de los $N$ estados destino $j$, sumamos sobre los $N$ estados de origen $i$. Eso es $N \times N$ operaciones por paso de tiempo → $N^2 T$ en total.