La escalera como puente
La escalera ya tiene su $Q^∗$ — la calculamos con programación dinámica en el módulo 21 y la recuperamos con Q-learning en las páginas anteriores. Ahora podemos plantear la misma pregunta desde otro ángulo: ¿podría una red neuronal $Q_\theta(s,a)$ aprender la misma tabla?
La respuesta es sí — y el resultado es idéntico. Para la escalera (5 estados, 2 acciones → 10 celdas), la tabla es claramente mejor: más simple, exacta, sin hiperparámetros de red. El punto no es reemplazar algo que funciona. El punto es entender cuándo la tabla deja de funcionar — porque ese momento llega muy rápido.
CartPole: cuando la tabla explota
CartPole-v1 es el entorno de prueba estándar para RL continuo. El objetivo es mantener un poste vertical empujando un carro hacia la izquierda o la derecha.
El MDP de CartPole
| Símbolo | Nombre | Descripción |
|---|---|---|
| $S$ | Espacio de estados | Vector continuo 4D: $(x,\ \dot{x},\ \theta,\ \dot{\theta})$ |
| $x$ | Posición del carro | Metros, $[-4.8,\ 4.8]$ |
| $\dot{x}$ | Velocidad del carro | m/s, continuo |
| $\theta$ | Ángulo del poste | Radianes, $[-24°,\ 24°]$ |
| $\dot{\theta}$ | Velocidad angular | rad/s, continuo |
| $A(s)$ | Acciones | ${0=\text{izquierda},\ 1=\text{derecha}}$ |
| $R(s,a,s’)$ | Recompensa | $+1$ por cada paso que el poste no cae |
| Terminal | Condición de fin | $\lvert\theta\rvert > 12°$ o $\lvert x \rvert > 2.4$ o $t > 500$ |
| Resuelto | Criterio oficial | Media $\geq 475$ sobre 100 episodios consecutivos |
El problema de la discretización
Para usar una tabla $Q$, hay que discretizar el espacio continuo. Si dividimos cada dimensión en 10 intervalos (bins):
$$10 \times 10 \times 10 \times 10 = 10{,}000 \text{ estados}$$
Parece manejable — pero los problemas aparecen rápido:
| Problema | Estados | Acciones | Celdas $Q$ |
|---|---|---|---|
| Escalera | 5 | 2 | 10 |
| CartPole (10 bins por dim.) | 10,000 | 2 | 20,000 |
| CartPole (20 bins por dim.) | 160,000 | 2 | 320,000 |
| Atari (píxeles) | $256^{33600}$ | 18 | imposible |
El problema más profundo no es el tamaño — es la falta de generalización. En una tabla, dos celdas vecinas tienen valores completamente independientes. Si el ángulo es $12.4°$ (un bin) y $12.6°$ (el bin siguiente), la tabla los trata como estados sin relación. Una red neuronal, en cambio, puede interpolar: estados similares producen salidas similares porque comparten los mismos pesos $\theta$.
La sustitución
El cambio fundamental es reemplazar la tabla por una red:
$$\boxed{Q[s,a] \to Q_\theta(s, a)}$$
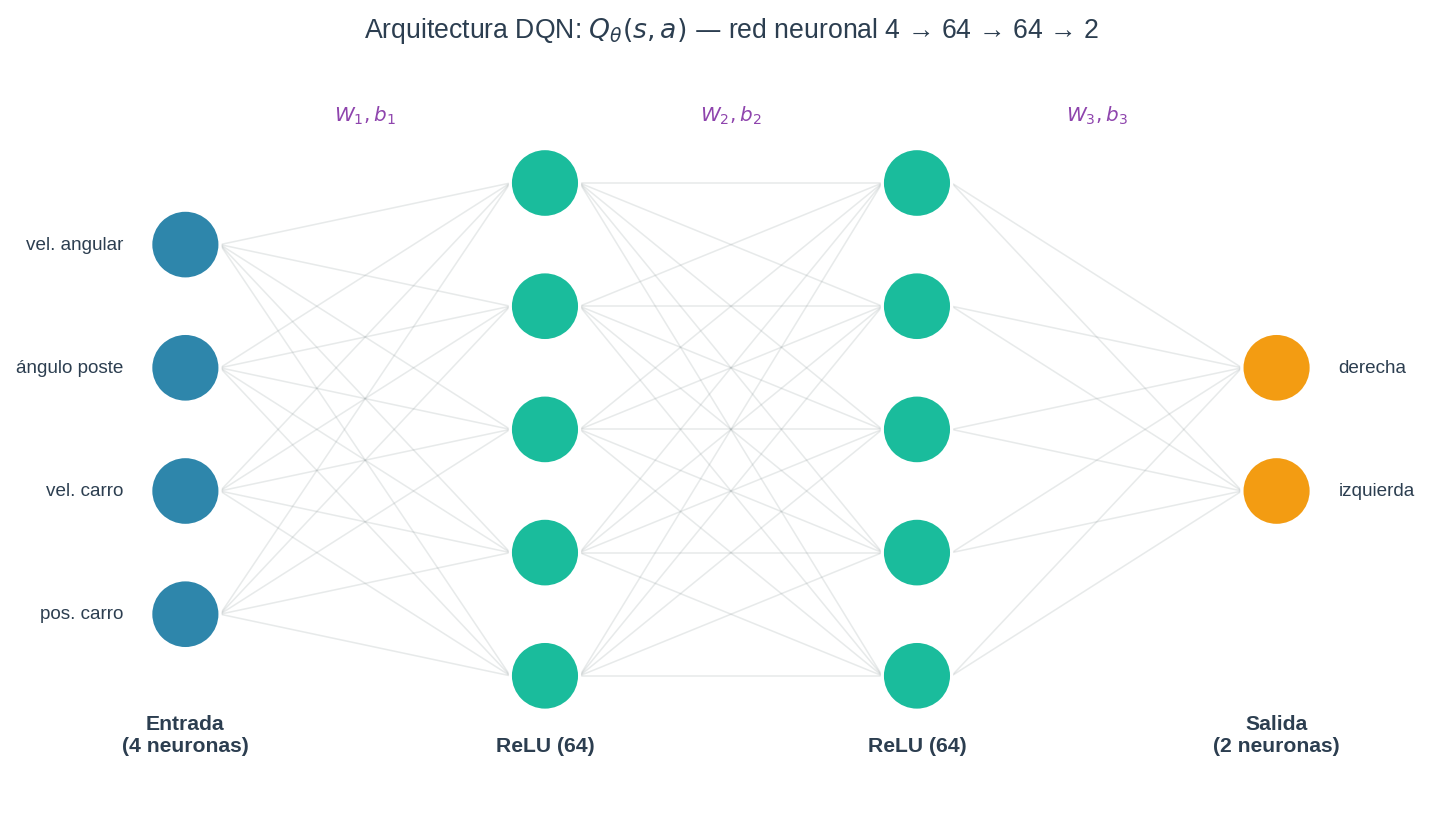
La red recibe como entrada el vector de estado completo (los 4 valores continuos de CartPole) y produce como salida un valor $Q$ por cada acción posible. No hay discretización: el espacio continuo se procesa directamente.
La política $\varepsilon$-greedy sigue siendo exactamente la misma:
$$a^∗ = \arg\max_a Q_\theta(s, a)$$
La única diferencia es que ahora $Q_\theta$ es una red neuronal en vez de una tabla.
Problema 1: muestras correlacionadas
El problema
La idea más directa para entrenar la red sería aplicar un paso de gradiente cada vez que ocurre una transición $(s_t, a_t, r_t, s_{t+1})$:
- El agente ejecuta una acción y observa el resultado.
- Calcula el error TD: $\delta_t = r_t + \gamma \max_b Q_\theta(s_{t+1}, b) - Q_\theta(s_t, a_t)$.
- Hace un paso de gradiente para reducir ese error.
- Avanza al siguiente paso y repite.
El problema no es el algoritmo — es el orden en que llegan los datos.
Dentro de un episodio, las transiciones forman una cadena:
$$s_0 \xrightarrow{a_0} s_1 \xrightarrow{a_1} s_2 \xrightarrow{a_2} s_3 \xrightarrow{a_3} \cdots$$
Cada estado surge directamente del anterior. Si el carro se está inclinando a la derecha en $s_t$, es casi seguro que también se incline a la derecha en $s_{t+1}$ y $s_{t+2}$ — son variaciones del mismo momento físico, no observaciones independientes del espacio de estados.
Por qué esto rompe SGD: El descenso de gradiente estocástico asume que cada muestra es independiente de las anteriores — así, cada gradiente apunta en una dirección distinta y la media de muchos pasos converge al gradiente verdadero. Si todas las muestras de un mini-lote provienen del mismo episodio (y por tanto del mismo fragmento de trayectoria), los gradientes son casi paralelos. La red recibe el mismo “empuje” repetido muchas veces seguidas y sobreajusta a esa trayectoria particular, olvidando lo aprendido en episodios anteriores.
Lectura: Es como intentar aprender a manejar entrenando exclusivamente en la misma calle, en la misma dirección, durante horas seguidas. Técnicamente estás acumulando pasos de gradiente, pero todos describen la misma situación. La primera vez que enfrentes una curva hacia la izquierda, habrás “olvidado” cómo hacerlo.
La solución: el replay buffer
En lugar de entrenar con cada transición en el momento en que ocurre, se almacenan todas en un buffer $\mathcal{D}$ y se muestrea aleatoriamente de él.
Estructura del buffer:
El buffer es una cola FIFO (primero en entrar, primero en salir) con capacidad fija $N$:
Buffer D [capacidad N = 10 000]
posición │ transición almacenada
──────────┼──────────────────────────────────────────
0 │ (s₀, a₀, r₁, s₁, done=False) ← más antigua
1 │ (s₁, a₁, r₂, s₂, done=False)
2 │ (s₂, a₂, r₃, s₃, done=True ) ← fin episodio 1
3 │ (s₀', a₀', r₁', s₁', done=False) ← inicio episodio 2
4 │ (s₁', a₁', r₂', s₂', done=False)
... │ ...
9 999 │ (sₙ, aₙ, rₙ, sₙ', done=?) ← más reciente
Cuando el buffer se llena, la transición más antigua se descarta para hacer lugar a la nueva. Así el buffer siempre contiene las últimas $N$ experiencias del agente, mezclando transiciones de muchos episodios distintos.
El ciclo de entrenamiento con replay:
En cada paso del entorno:
1. Actúa: ejecuta a_t con ε-greedy, observa (r_t, s_{t+1})
2. Almacena: agrega (s_t, a_t, r_t, s_{t+1}, done) al buffer D
3. Muestrea: si |D| ≥ 64, extrae un mini-lote de 64 transiciones al AZAR de D
4. Actualiza: calcula el error TD sobre ese mini-lote y hace un paso de gradiente
El paso 3 es la clave: las 64 transiciones del mini-lote vienen de momentos y episodios distintos — algunas pueden ser de hace 5 000 pasos, otras de hace 3 pasos. Sus gradientes ya no apuntan en la misma dirección, y la media vuelve a ser una estimación útil del gradiente verdadero.
¿Por qué esperar a que el buffer tenga al menos 64 entradas? Con pocas transiciones, todas son recientes y altamente correlacionadas — exactamente el problema que queremos evitar. Se entrena solo cuando el buffer tiene suficiente diversidad.
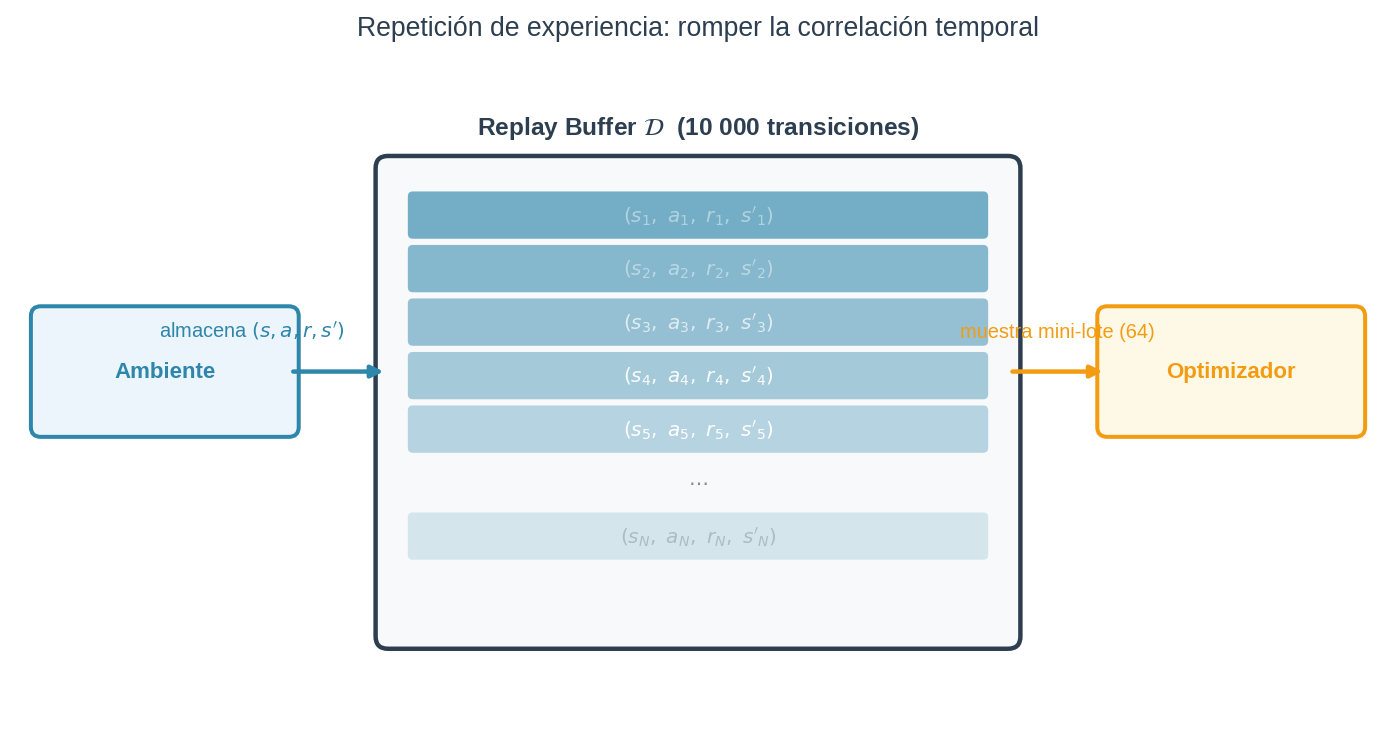
Dos beneficios en uno:
| Beneficio | Por qué ocurre |
|---|---|
| Rompe la correlación temporal | El muestreo aleatorio mezcla episodios y momentos distintos |
| Mayor eficiencia de datos | Cada transición puede ser muestreada y usada múltiples veces, no solo una |
Sin replay, cada transición se usa exactamente una vez y se descarta. Con replay, una transición útil (por ejemplo, la primera vez que el agente recuperó el equilibrio) puede influir en decenas de pasos de gradiente a lo largo del entrenamiento.
Problema 2: el blanco se mueve
La función de pérdida de Q-learning tiene la forma:
$$L(\theta) = \mathbb{E}\bigl[(y_i - Q_\theta(s_i, a_i))^2\bigr]$$
donde el objetivo es:
$$y_i = r + \gamma \max_b Q_\theta(s’, b)$$
Hay un problema oculto: $Q_\theta$ aparece en ambos lados. En el lado derecho genera el objetivo $y_i$; en el lado izquierdo es lo que intentamos ajustar. Cada vez que actualizamos $\theta$, el objetivo $y_i$ también cambia — es como intentar alcanzar un blanco que se mueve en cada paso. El resultado es entrenamiento inestable: los gradientes oscilan y la red puede no converger.
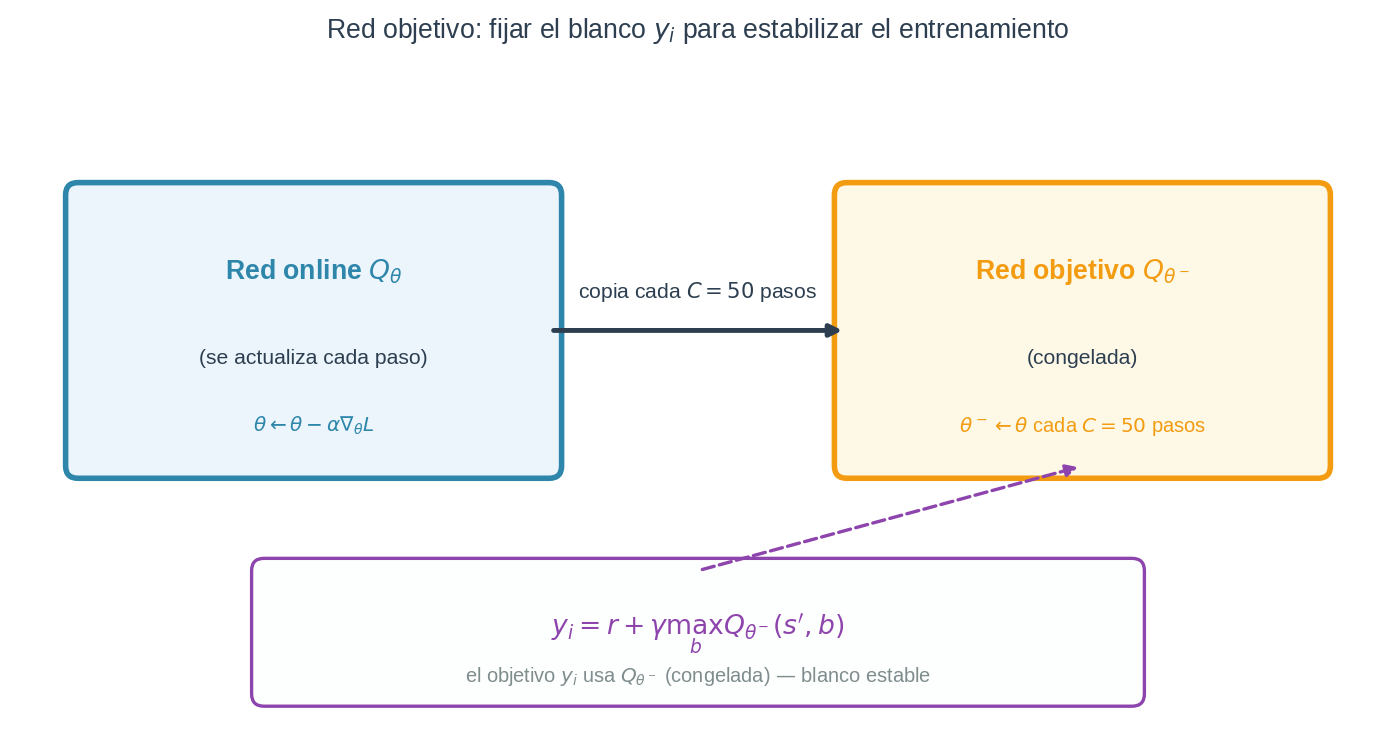
Solución: red objetivo (target network)
Se mantiene una segunda copia de la red, $Q_{\theta^-}$, con parámetros congelados. El objetivo se calcula con esta red congelada:
$$y_i = r + \gamma \max_b Q_{\theta^-}(s’, b)$$
Los pesos $\theta^-$ solo se actualizan cada $C = 50$ pasos, copiando los pesos de la red online: $\theta^- \leftarrow \theta$. Entre actualizaciones, el blanco se queda fijo — el entrenamiento es mucho más estable.
La función de pérdida
Reuniendo los dos elementos (experience replay + red objetivo):
$$\boxed{L(\theta) = \mathbb{E}\bigl[(y_i - Q_\theta(s_i, a_i))^2\bigr]}$$
| Símbolo | Significado |
|---|---|
| $y_i = r + \gamma \max_b Q_{\theta^-}(s’, b)$ | objetivo TD con red congelada |
| $Q_\theta(s_i, a_i)$ | predicción de la red online |
| $\theta$ | pesos de la red online (se actualizan en cada paso) |
| $\theta^-$ | pesos de la red objetivo (congelados, se copian cada $C$ pasos) |
Lectura: Es una regresión MSE estándar — la predicción es $Q_\theta$, la etiqueta es $y_i$. La única novedad es que $y_i$ viene de otra red ($\theta^-$), no del ambiente directamente. Eso es todo lo que añade DQN sobre Q-learning: dos trucos de estabilización, misma idea de fondo.
Pseudocódigo
Al inicio se crean dos redes con arquitectura idéntica e inicializadas con los mismos pesos. En cada paso: el agente actúa con $\varepsilon$-greedy, almacena la transición $(s,a,r,s’)$ en el buffer, muestrea un mini-lote aleatorio, calcula los objetivos con la red congelada, y hace un paso de gradiente sobre la red online. Cada 50 pasos, los pesos de la red online se copian a la red objetivo.
DQN(α, γ, ε, C, num_episodios):
Inicializa red online Q_θ y red objetivo Q_{θ^-} con pesos iguales
Inicializa buffer D (capacidad 10 000)
Para cada episodio:
s ← estado_inicial()
Mientras s no sea terminal:
a ← ε-greedy(Q_θ, s)
s', r, done ← ejecutar(a)
Almacena (s, a, r, s', done) en D
Si |D| ≥ 64:
Muestrea mini-lote {(s_i, a_i, r_i, s'_i, done_i)} de D
y_i ← r_i + γ · max_b Q_{θ^-}(s'_i, b) · (1 − done_i)
θ ← θ − α · ∇_θ L(θ) donde L = MSE(Q_θ(s_i, a_i), y_i)
Cada C pasos: θ^- ← θ
s ← s'
El factor (1 − done_i) en el cálculo del objetivo es un detalle importante: si el episodio terminó ($\text{done}=1$), no hay estado siguiente — el valor futuro es cero.
Hacia adelante
La página 07 explora una familia de algoritmos distinta: en lugar de aprender $Q_\theta$ y derivar la política con $\arg\max$, ¿por qué no aprender la política $\pi_\theta$ directamente? Esta idea — el gradiente de política — es la base de PPO y, en última instancia, del RLHF que entrena los modelos de lenguaje modernos.
La página 08 es el laboratorio aplicado: código ejecutable, demo en vivo y comparación de los cuatro métodos (Q-tabla, SARSA, Q-learning, DQN) sobre CartPole.