21.3 — Formular problemas como MDP
“Escribir el problema bien es resolver la mitad.”
En la página anterior, todo el desarrollo descansó en cinco cantidades: estados, acciones, transiciones, costos, y (a veces) descuento. Estos cinco elementos tienen un nombre colectivo: Proceso de Decisión de Markov o MDP (Markov Decision Process).
Un MDP es simplemente una tupla:
$$\text{MDP} = (S, A, T, R, \gamma)$$
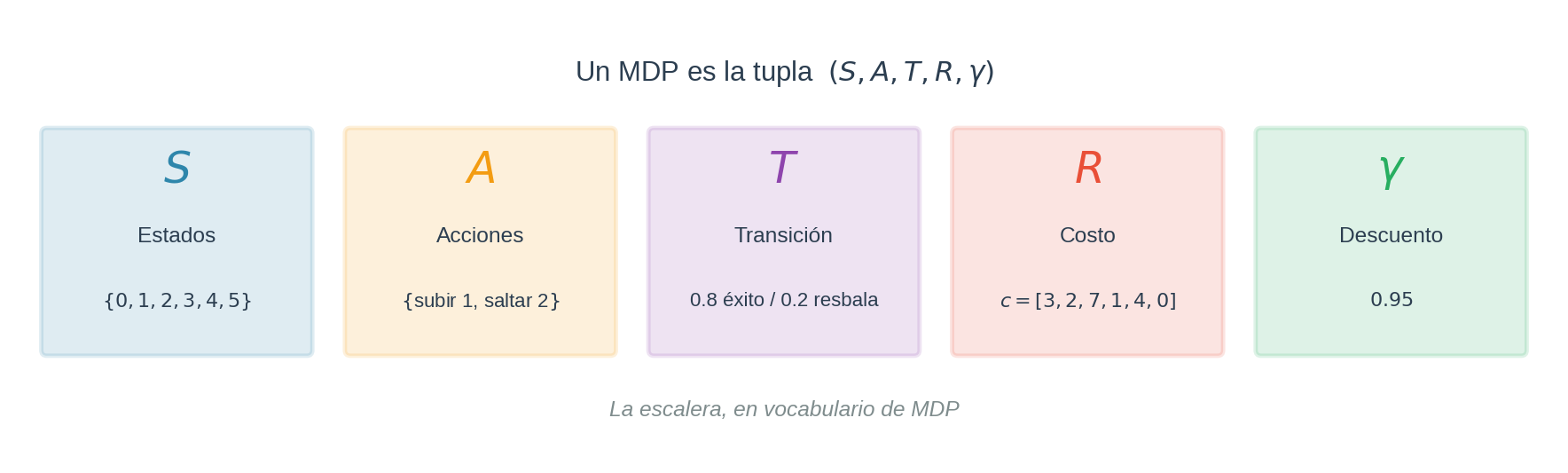
| Símbolo | Nombre | Significado | En la escalera |
|---|---|---|---|
| $S$ | Estados | Todas las configuraciones posibles del sistema | $\lbrace0, 1, 2, 3, 4, 5\rbrace$ — los escalones |
| $A$ | Acciones | Lo que el agente puede decidir hacer | $\lbrace\text{subir 1}, \text{saltar 2}\rbrace$ |
| $T$ | Transición | Cómo cambia el estado al tomar una acción, $T(s’ \mid s, a) = P(s’ \mid s, a)$ | Determinista o con prob. 0.8/0.2 al resbalar |
| $R$ | Recompensa o costo | Qué ganas (o pagas) por estar/actuar en cada estado, $R(s, a)$ o $c(s, a)$ | $c_i$ = costo del escalón $i$ |
| $\gamma$ | Descuento | Peso del futuro en el presente, $\gamma \in [0, 1]$ | $0.95$ (en la versión con descuento) |
La ecuación de Bellman usa exactamente estos cinco objetos. Nada más, nada menos:
$$V(s) = \min_a \sum_{s’} T(s’ \mid s, a)\bigl[ R(s, a, s’) + \gamma V(s’)\bigr].$$
Recuerda: $V(s)$ es el costo futuro desde $s$ — no incluye costo por estar en $s$. El costo se paga en la transición: pagas $R(s, a, s’)$ cuando tomas la acción $a$ desde $s$ y aterrizas en $s’$.
(O max en lugar de min, si el problema es de recompensas en vez de costos. La estructura es la misma.)
La receta para formular
Cuando te presenten un problema “en palabras”, tu trabajo es identificar los cinco componentes. Una receta que funciona:
- ¿Qué controlas? → Identifica las acciones $A$.
- ¿Qué describe la situación actual? → Identifica los estados $S$.
- ¿Cómo cambia el estado cuando actúas? → Escribe la función de transición $T$. Si es determinista, es una función $s \mapsto s’$. Si es estocástica, son probabilidades.
- ¿Qué ganas o pagas en cada paso? → Identifica la función de recompensa (o costo) $R$.
- ¿Te importa el futuro tanto como el presente? → Si no, fija $\gamma < 1$.
Escribe los cinco. Después, la ecuación de Bellman es automática: la escribes sustituyendo cada símbolo con lo que identificaste.
Ejercicio 1 — Robot con batería
[callback al Módulo 2 — Agentes y Ambientes]
Un robot en un edificio tiene que entregar un paquete en una celda específica. El edificio es una cuadrícula de $4 \times 4$ celdas. El robot tiene una batería que se mide en porcentaje (de 0 a 100, en pasos de 10). Cada movimiento horizontal o vertical le consume 10% de batería y le toma 1 minuto. Si llega a 0% de batería antes de entregar, se apaga y se le penaliza con 50 minutos de tiempo perdido (alguien tiene que ir por él). Hay una estación de carga en una celda fija: si pasa por ahí, su batería vuelve a 100% sin costo adicional de tiempo (pero tarda 1 minuto como cualquier movimiento).
Tu tarea: identifica los cinco componentes del MDP para este problema, y escribe la ecuación de Bellman especializada.
Ver solución
Estados $S$: el estado tiene que capturar todo lo que afecta decisiones futuras. Aquí necesitas la posición del robot y su nivel de batería:
$$S = \lbrace(c, b) : c \in \text{celdas}, b \in \lbrace0, 10, 20, \ldots, 100\rbrace\rbrace.$$
Más la posición del paquete si puede cambiar, pero aquí es fija, así que no hace falta incluirla.
Acciones $A$: lo que el agente controla desde cada estado:
$$A = \lbrace\text{norte}, \text{sur}, \text{este}, \text{oeste}\rbrace.$$
(Algunas acciones pueden estar bloqueadas si llevarían al robot fuera de la cuadrícula.)
Transición $T$: determinista. Si el robot está en celda $(x, y)$ con batería $b$ y toma “norte”:
$$T\bigl((x, y, b), \text{norte}\bigr) = \begin{cases} (x, y+1, 100) & \text{si } (x, y+1) = \text{estación de carga} \ (x, y+1, b - 10) & \text{si no y } b > 0 \ (x, y, 0) & \text{si } b = 0 \text{ (robot apagado)} \end{cases}$$
Recompensa (costo) $R$:
$$R(s, a) = \begin{cases} 50 \text{ minutos (penalización)} & \text{si la acción deja } b = 0 \text{ sin haber entregado} \ 1 \text{ minuto} & \text{en cualquier movimiento normal} \ 0 & \text{si el estado es la celda del paquete (meta)} \end{cases}$$
Descuento $\gamma$: como todas las acciones importan igual y la meta es alcanzable en tiempo finito, podemos usar $\gamma = 1$ (o $\gamma$ muy cercano a 1 por estabilidad numérica). En un problema donde el robot pudiera tardarse indefinidamente, $\gamma < 1$ ayudaría.
Ecuación de Bellman para este problema (determinista, $\gamma = 1$):
$$V(c, b) = \min_{a \in A} \bigl[ R\bigl((c, b), a\bigr) + V\bigl(T((c, b), a)\bigr)\bigr].$$
$V(c, b)$ es el tiempo esperado restante para entregar el paquete, empezando en celda $c$ con batería $b$. El “tiempo ya gastado” antes de estar en $(c, b)$ no cuenta — ya no lo puedes evitar.
Conexión con el Módulo 2. Los cinco componentes aquí son exactamente la descripción PEAS que hiciste hace semanas, solo reorganizada:
- Performance (desempeño) ↔ $R$ (queremos minimizar tiempo)
- Environment (ambiente) ↔ $S$ y $T$ (dónde vive y cómo cambia)
- Actuators (actuadores) ↔ $A$ (qué puede hacer)
- Sensors (sensores) ↔ no aparecen aquí porque suponemos observabilidad total (el agente conoce su estado)
El MDP es la formalización precisa de “agente basado en objetivos” del Módulo 2, cuando las decisiones son secuenciales.
Ejercicio 2 — Excursionista bajo lluvia
[callback al Módulo 19 — Cadenas de Markov]
Estás haciendo una excursión a la cima de un cerro. Hay 4 altitudes posibles: base, mitad, mirador, cumbre (donde quieres llegar). En cada turno puedes:
- Subir por la ruta A — rápida pero pesada (costo de esfuerzo = 3).
- Subir por la ruta B — más larga pero gentil (costo de esfuerzo = 1).
- Descansar — no avanzas, costo 0.
Pero el clima decide qué tan bien te va. El clima sigue una cadena de Markov con tres estados — {sol, lluvia, tormenta} — con esta matriz de transición (desde → a):
| sol | lluvia | tormenta | |
|---|---|---|---|
| sol | 0.6 | 0.3 | 0.1 |
| lluvia | 0.3 | 0.5 | 0.2 |
| tormenta | 0.2 | 0.4 | 0.4 |
Las acciones se comportan distinto según el clima:
- Ruta A bajo sol: subes una altitud con probabilidad 0.9, te quedas con 0.1.
- Ruta A bajo lluvia: subes con 0.6, te quedas con 0.4.
- Ruta A bajo tormenta: te resbalas — retrocedes una altitud con 0.7, te quedas con 0.3 (no puedes subir en tormenta por A).
- Ruta B siempre sube con probabilidad 1 (independiente del clima), pero al doble de pasos por altitud.
- Descansar no cambia la altitud.
El clima en el siguiente paso depende solo del clima actual (Markov) y es independiente de tu acción.
Finalmente: si estás en tormenta y te mojas, pagas un costo adicional de 5. La meta es llegar a cumbre. Usa $\gamma = 0.95$ (los pasos futuros pesan menos — es una excursión, no una obsesión).
Tu tarea: identifica los cinco componentes, escribe la ecuación de Bellman.
Ver solución
Estados $S$: la decisión de qué hacer depende tanto de dónde estás (altitud) como del clima actual. El estado es entonces un par:
$$S = \lbrace\text{altitud}\rbrace \times \lbrace\text{clima}\rbrace = \lbrace\text{base}, \text{mitad}, \text{mirador}, \text{cumbre}\rbrace \times \lbrace\text{sol}, \text{lluvia}, \text{tormenta}\rbrace.$$
Total: $4 \times 3 = 12$ estados.
Acciones $A$: $\lbrace\text{ruta A}, \text{ruta B}, \text{descansar}\rbrace$.
Transición $T$: se factoriza naturalmente en dos partes independientes:
$$T\bigl((\text{alt}, \text{clim}) \to (\text{alt}‘, \text{clim}’) \bigm| a\bigr) = P(\text{alt}’ \mid \text{alt}, \text{clim}, a) \cdot P(\text{clim}’ \mid \text{clim}).$$
- $P(\text{alt}’ \mid \text{alt}, \text{clim}, a)$ es la dinámica de la altitud (depende de la acción y del clima actual).
- $P(\text{clim}’ \mid \text{clim})$ es exactamente la cadena de Markov del clima (¡eso del Módulo 19!): no depende ni de la altitud ni de la acción.
Recompensa (costo) $R(s, a, s’)$: el costo se paga en la transición. Tiene dos partes:
$$R\bigl((\text{alt}, \text{clim}), a, (\text{alt}‘, \text{clim}’)\bigr) = \underbrace{\text{esfuerzo}(a)}{\text{ruta A: 3, ruta B: 1, descansar: 0}} + \underbrace{5 \cdot \mathbb{1}[\text{clim}’ = \text{tormenta}]}{\text{costo de mojarte (al aterrizar en tormenta)}}.$$
Descuento $\gamma = 0.95$.
Ecuación de Bellman para este problema:
$$V(\text{alt}, \text{clim}) = \min_{a \in A} \sum_{\text{alt}‘, \text{clim}’} P(\text{alt}’ \mid \text{alt}, \text{clim}, a) P(\text{clim}’ \mid \text{clim}) \bigl[ R\bigl((\text{alt},\text{clim}), a, (\text{alt}‘, \text{clim}’)\bigr) + \gamma V(\text{alt}‘,\text{clim}’)\bigr].$$
La doble suma viene de la factorización: una sobre el siguiente clima, otra sobre la siguiente altitud. Fíjate que el segundo factor — $P(\text{clim}’ \mid \text{clim})$ — es la matriz de transición del Módulo 19. La cadena de Markov vive dentro del MDP, como un componente del kernel.
Por qué incluir el clima en el estado. Podrías sentir la tentación de dejar solo la altitud en $S$ y “guardar” el clima aparte. Pero entonces $T$ no dependería solo del estado y la acción — dependería también de algo externo (el clima), y ya no sería un MDP bien definido. La propiedad de Markov del Módulo 19 exige que todo lo que importa para el futuro esté en el estado.
Esto es importante y general: el estado debe capturar toda la información relevante del pasado que afecta las decisiones futuras. Es exactamente el mismo criterio del Módulo 19, llevado al contexto de decisiones.
Lo que ganaste
Si hiciste los dos ejercicios, ahora puedes:
- Tomar cualquier problema que te describan en palabras y traducirlo a la tupla $(S, A, T, R, \gamma)$.
- Escribir la ecuación de Bellman específica para ese problema — no la versión genérica, sino la que tiene tus estados y tus acciones adentro.
- Reconocer cuándo una cadena de Markov vive dentro del kernel de transición de un MDP (spoiler: casi siempre).
Tener la ecuación escrita es el 90% de entender el problema. Lo que queda es resolverla — y para eso necesitamos la programación dinámica de manera explícita. Es lo que viene.
Siguiente: Programación dinámica en detalle →