La escalera regresa — con costos escondidos
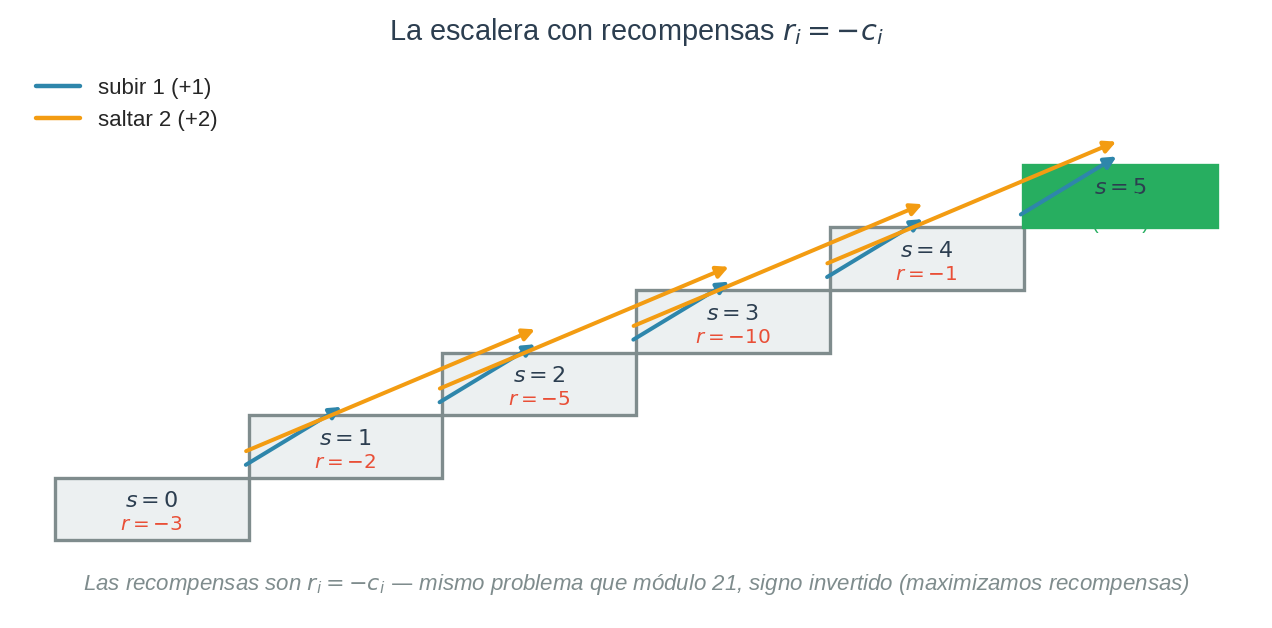
Recuerda la escalera del módulo 21. Seis estados ($s = 0, \ldots, 5$), dos acciones ($+1$ o $+2$), costos $c = [3, 2, 5, 10, 1, 0]$ y el objetivo de llegar a $s=5$ pagando lo menos posible.
Con programación dinámica calculamos $Q^∗$ exactamente porque teníamos la tabla de transición $T$ y los costos $R$ escritos explícitamente. Ahora imagina que eres el agente parado en $s=0$: no tienes el manual. Solo puedes dar un paso, observar a dónde llegaste y cuánto pagaste, y volver a intentarlo.
Eso es aprendizaje por refuerzo: aprender a actuar bien solo con la experiencia.
El convenio de signos
Antes de formalizar nada, un detalle crítico: en RL maximizamos recompensas, no minimizamos costos. La conversión es directa:
$$\boxed{r_i = -c_i}$$
Para la escalera:
| Estado | Costo $c_i$ | Recompensa $r_i$ |
|---|---|---|
| 0 | 3 | −3 |
| 1 | 2 | −2 |
| 2 | 5 | −5 |
| 3 | 10 | −10 |
| 4 | 1 | −1 |
| 5 | 0 | 0 (meta) |
Cuando el módulo 21 decía “minimiza el costo total”, este módulo dice “maximiza la recompensa total acumulada”. Son el mismo problema — solo invertido.
La interfaz RL
El mundo sigue siendo un MDP $(S, A, T, R, \gamma)$, pero ahora $T$ y $R$ están ocultas.
| Símbolo | Nombre | Significado en la escalera |
|---|---|---|
| $S$ | Espacio de estados | ${0, 1, 2, 3, 4, 5}$ |
| $A(s)$ | Acciones disponibles en $s$ | ${+1, +2}$ (solo ${+1}$ desde $s=4$) |
| $T(s’ \mid s, a)$ | Función de transición | Determinista: desde $s$ con $a$, siempre llegas a $s+a$ |
| $R(s, a, s’)$ | Función de recompensa | $r_{t+1} = -c_{s’}$ (costo del estado destino, negado) |
| $\gamma$ | Factor de descuento | $\gamma = 1$ en nuestros ejemplos (todas las recompensas pesan igual) |
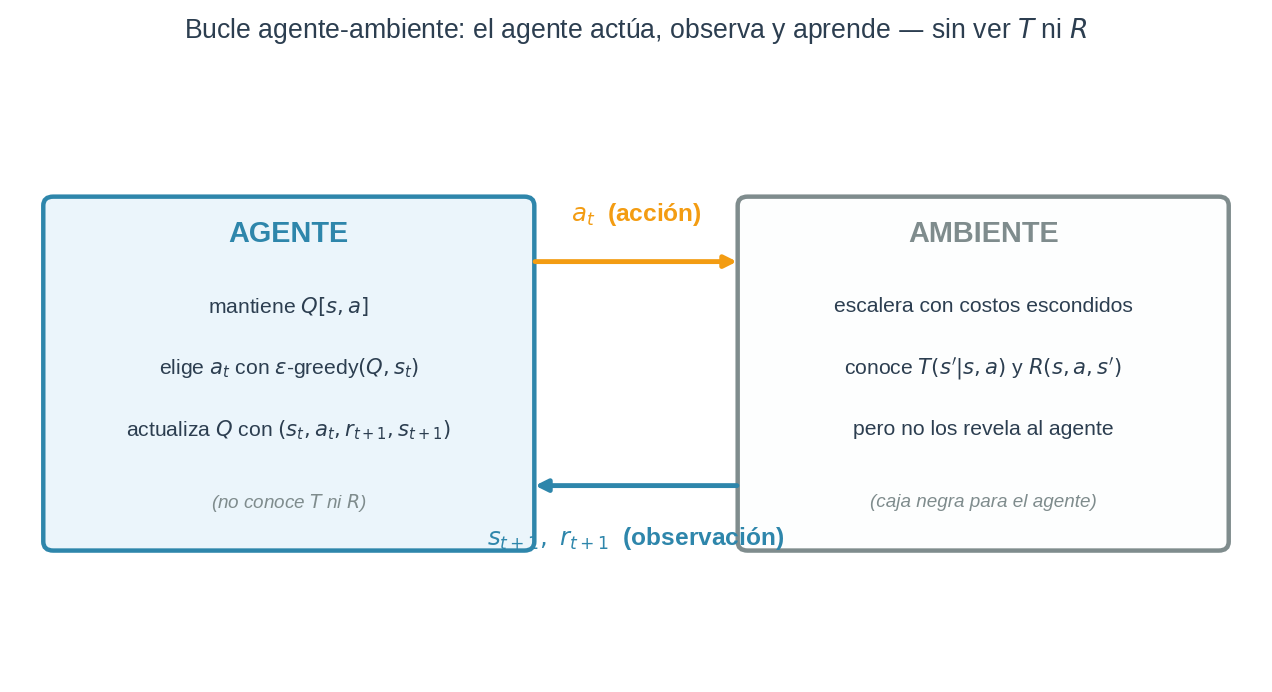
En RL, el agente no conoce $T$ ni $R$. Solo puede interactuar con el ambiente y observar lo que ocurre. El agente solo ve una secuencia de tuplas:
$$\underbrace{(s_0, a_0, r_1, s_1)}_{\text{paso 1}},\quad (s_1, a_1, r_2, s_2),\quad (s_2, a_2, r_3, s_3),\quad \ldots$$
En cada paso $t$:
- El agente observa el estado actual $s_t$.
- Elige una acción $a_t$ según su política.
- El ambiente — que sí conoce $T$ y $R$, pero no los revela — transiciona a $s_{t+1} \sim T(\cdot \mid s_t, a_t)$ y devuelve $r_{t+1} = R(s_t, a_t, s_{t+1})$.
- El agente observa $(r_{t+1}, s_{t+1})$ y actualiza su conocimiento.
Episodio, trayectoria y retorno $G_t$
Un episodio es una secuencia desde el estado inicial hasta un estado terminal:
$$\tau = (s_0, a_0, r_1, s_1,\ a_1, r_2, s_2,\ \ldots,\ s_T)$$
El retorno desde el paso $t$ es la suma de recompensas futuras descontadas:
$$\boxed{G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots = \sum_{k=0}^{\infty} \gamma^k r_{t+k+1}}$$
Cada símbolo nuevo:
| Símbolo | Significado |
|---|---|
| $G_t$ | Retorno — suma total de recompensas desde el paso $t$ en adelante, con descuento |
| $r_{t+1}$ | Recompensa recibida inmediatamente después del paso $t$ |
| $r_{t+k+1}$ | Recompensa recibida $k+1$ pasos en el futuro |
| $\gamma \in [0,1]$ | Factor de descuento: cuánto vale el futuro respecto al presente |
El factor $\gamma$ controla el horizonte temporal. $\gamma = 0$ significa miope (solo importa la próxima recompensa); $\gamma = 1$ significa que todas las recompensas valen igual (horizonte infinito).
Ejemplo concreto en la escalera ($\gamma = 1$, trayectoria $0 \to 2 \to 4 \to 5$):
| Paso | Estado | Acción | Siguiente | Recompensa |
|---|---|---|---|---|
| 0 | $s=0$ | $+2$ | $s=2$ | $r_1 = -5$ |
| 1 | $s=2$ | $+2$ | $s=4$ | $r_2 = -1$ |
| 2 | $s=4$ | $+1$ | $s=5$ | $r_3 = 0$ |
$$G_0 = r_1 + \gamma r_2 + \gamma^2 r_3 = -5 + (-1) + 0 = -6$$
Este es el retorno que encontramos en el módulo 21 como el coste óptimo (con signo invertido).
Las tres funciones de valor
Función de valor de estado bajo política $\pi$
$$V^\pi(s) = \mathbb{E}_\pi\left[G_t \mid s_t = s\right]$$
Lectura: “El retorno esperado si empiezo en $s$ y sigo la política $\pi$.”
Donde $\mathbb{E}_\pi[\cdot]$ es la esperanza matemática sobre las trayectorias generadas por $\pi$ (la misma herramienta de muestreo del módulo 12).
Función de valor acción-estado bajo política $\pi$
$$Q^\pi(s, a) = \mathbb{E}_\pi\left[G_t \mid s_t = s, a_t = a\right]$$
Lectura: “El retorno esperado si en $s$ tomo primero la acción $a$ y después sigo $\pi$.”
La diferencia con $V^\pi$: $Q^\pi$ especifica también la primera acción; $V^\pi$ deja que $\pi$ la elija.
Función de valor óptima
$$Q^∗(s, a) = \max_\pi Q^\pi(s, a)$$
Lectura: “El mayor retorno posible si en $s$ tomo $a$ y después actúo de la mejor manera posible.”
Es el máximo sobre todas las políticas posibles. Conocer $Q^∗$ es suficiente para actuar de manera óptima.
Ecuaciones de Bellman
$Q^\pi$ y $Q^∗$ satisfacen ecuaciones de Bellman (recursivas):
$$Q^\pi(s,a) = \mathbb{E}_{s’ \sim T, a’ \sim \pi}\left[r + \gamma Q^\pi(s’, a’)\right]$$
$$Q^∗(s,a) = \mathbb{E}_{s’ \sim T}\left[r + \gamma \max_b Q^∗(s’, b)\right]$$
($b$ variable muda de optimización — equivalente a $a’$ en la notación estándar)
La única diferencia es cómo se elige la siguiente acción: bajo $\pi$ para $Q^\pi$, como máximo para $Q^∗$.
¿Por qué $Q^∗$ y no $V^∗$?
A primera vista parece contradictorio: la ecuación de Bellman de $Q^∗$ incluye $\mathbb{E}_{s’ \sim T}$, que sí involucra $T$. ¿Cómo puede ser que no necesitemos $T$?
La respuesta está en cuándo se usa $T$:
| Momento | $V^∗$ | $Q^∗$ |
|---|---|---|
| Aprender (durante entrenamiento) | Usa $T$ implícitamente vía muestras del ambiente | Usa $T$ implícitamente vía muestras del ambiente |
| Actuar (con la tabla ya aprendida) | Sigue necesitando $T$ para elegir la acción | Ya no necesita $T$ — la tabla basta |
La diferencia es concreta. Supón que ya tienes la tabla completa:
Con $V^∗$ en mano — elegir la mejor acción en $s$ todavía exige calcular:
$$a^∗(s) = \arg\max_{a} \sum_{s’} T(s’ \mid s, a)\left[R(s,a,s’) + \gamma V^∗(s’)\right]$$
Esa suma requiere $T(s’ \mid s, a)$ para cada $s’$ y cada $a$ — exactamente lo que no tienes en RL.
Con $Q^∗$ en mano — elegir la mejor acción solo requiere:
$$\boxed{a^∗(s) = \arg\max_{a} Q^∗(s, a)}$$
Lees la fila $s$ de la tabla y tomas el máximo. $Q^∗(s,a)$ ya tiene el futuro incorporado: la suma sobre transiciones ocurrió durante el aprendizaje y quedó guardada como un número en la celda.
En una frase: $T$ aparece en la definición de $Q^∗$ porque fue necesaria para aprender el valor correcto. Una vez aprendida, la tabla $Q$ es autosuficiente — responde “¿cuánto vale cada acción?” sin ningún modelo del ambiente.
Exploración: $\varepsilon$-greedy
Recuerda del módulo 17 (Multi-Armed Bandits): para descubrir buenas acciones necesitas explorar, no solo explotarlas. La política $\varepsilon$-greedy hace exactamente eso:
$$\pi_\varepsilon(s) = \begin{cases} \text{acción aleatoria (uniforme sobre } A(s)) & \text{con probabilidad } \varepsilon \ \arg\max_a Q(s,a) & \text{con probabilidad } 1-\varepsilon \end{cases}$$
Con $\varepsilon = 0.4$ (como usaremos en los ejemplos), el 40% del tiempo el agente explora aleatoriamente y el 60% explota lo que ya aprendió. A medida que la tabla $Q$ converge, se suele decrecer $\varepsilon$ gradualmente.
Nota sobre notación: en el módulo 22, $\varepsilon$ se usó para el error de estimación. Aquí, como en el módulo 17, $\varepsilon$ es la tasa de exploración. Son contextos distintos; no se mezclan.
Monte Carlo vs Diferencia Temporal (TD)
Monte Carlo: esperar al final del episodio
Del módulo 12, la idea central es que $\mathbb{E}[X] \approx \frac{1}{N}\sum_{i=1}^N x_i$. Aplicado aquí: $Q^\pi(s,a) = \mathbb{E}[G_t \mid s_t=s, a_t=a]$ se puede estimar promediando los retornos reales $G_t$ de todos los episodios en que estuvimos en $(s,a)$.
La actualización incremental equivalente (misma idea, formulación online):
$$Q(s,a) \leftarrow Q(s,a) + \frac{1}{N}\bigl(G_t - Q(s,a)\bigr)$$
El problema: $G_t = r_{t+1} + \gamma r_{t+2} + \cdots + \gamma^{T-t} r_T$ es una suma de recompensas futuras. Para calcularla hay que esperar hasta el final del episodio y sumar hacia atrás.
Esto implica tres costos concretos:
- Demora: en un episodio de 1000 pasos, se acumulan 1000 experiencias pero la primera actualización de $Q$ ocurre recién al paso 1001.
- Alta varianza: $G_t$ depende de toda la trayectoria futura; pequeñas variaciones en la exploración producen retornos muy distintos, haciendo el aprendizaje ruidoso.
- Inaplicable en entornos continuos: si no hay estado terminal, nunca llega el “final del episodio” — Monte Carlo no puede arrancar.
Diferencia Temporal (TD): actualizar a cada paso
Diferencia Temporal es la idea de actualizar $Q(s,a)$ sin esperar al final del episodio, usando una estimación inmediata del retorno futuro.
En vez del retorno real $G_t = r + \gamma r’ + \gamma^2 r’’ + \cdots$, usamos solo un paso real y la propia tabla $Q$ para el resto:
$$\underbrace{r + \gamma Q(s’, ?)}_{\text{estimación TD del retorno}} \approx G_t$$
La actualización completa es:
$$Q(s,a) \leftarrow Q(s,a) + \alpha \cdot \delta_t$$
$$\delta_t = r + \gamma \cdot Q(s’, ?) - Q(s,a) \qquad \text{(error TD)}$$
| Símbolo | Significado |
|---|---|
| $\alpha \in (0,1]$ | Tasa de aprendizaje — qué fracción del error corregimos |
| $r$ | Recompensa observada en este paso |
| $Q(s’, ?)$ | Estimación del valor futuro desde $s’$ (bootstrap) |
| $Q(s,a)$ | Estimación actual — lo que ya creíamos |
| $\delta_t$ | Error TD — qué tan sorprendente fue la recompensa observada |
La clave del TD es el bootstrapping: usa la propia estimación $Q(s’, ?)$ para actualizar $Q(s,a)$, sin esperar el retorno real. Es una apuesta — $Q$ aún no es exacta — pero con suficiente experiencia converge.
La pregunta que queda abierta: ¿qué va en el ??
La respuesta divide el mundo del RL en dos familias de algoritmos, que exploraremos en la siguiente sección.