Algoritmo Backward
Si Forward mira al pasado, Backward mira al futuro. Juntos, ven todo.
1. Motivación: ¿qué le falta al algoritmo Forward?
El algoritmo Forward calcula $\alpha_t(i) = P(O_1, \ldots, O_t, q_t = i \mid \lambda)$: la probabilidad de haber visto las observaciones hasta el instante $t$ y de estar en el estado $i$.
Pero hay preguntas que Forward no puede responder eficientemente por sí solo. Por ejemplo: dado el modelo y toda la secuencia observada, ¿cuál es la probabilidad de estar en el estado $i$ en el instante $t$? Esa pregunta requiere información de las observaciones futuras ($O_{t+1}, \ldots, O_T$), que Forward no tiene.
El algoritmo Backward calcula exactamente esa información futura. Por sí solo también puede verificar $P(O \mid \lambda)$, pero su uso principal es combinarse con Forward para obtener los posteriors $\gamma_t(i)$ que necesita Baum-Welch.
2. La variable backward $\beta_t(i)$
Definimos la variable backward como:
$$\beta_t(i) = P(O_{t+1}, O_{t+2}, \ldots, O_T \mid q_t = i, \lambda)$$
En palabras: $\beta_t(i)$ es la probabilidad de observar el resto de la secuencia (desde $O_{t+1}$ en adelante), dado que en el instante $t$ estamos en el estado $i$.
Intuición operacional: $\beta_t(i)$ es un acumulador hacia atrás. En vez de recordar todas las trayectorias futuras que parten de $(t, i)$, comprime esa información en un único número. Cuando calculamos $\beta_t$, solo necesitamos $\beta_{t+1}$.
Mientras $\alpha_t(i)$ acumula información desde el pasado hacia $t$, $\beta_t(i)$ acumula información desde el futuro hacia $t$. Se procesan en sentido contrario: de derecha a izquierda en el trellis.
Nota: $\beta_t(i)$ es una probabilidad condicional dado el estado $q_t = i$. Por eso $\sum_i \beta_t(i) \neq 1$ en general — no son una distribución sobre estados, sino probabilidades de la secuencia futura condicionadas a cada estado.
3. Construyendo $\beta$ — del caso simple a la recursión
Antes de dar la fórmula general, la descubrimos trabajando hacia atrás con el ejemplo de Lain: $N=2$ estados ${S, R}$, $O = (0, 1, 1)$, $T=3$.
3.1 Caso base $t = T$: el final de la secuencia
En $t = T = 3$ no hay observaciones futuras. La secuencia del futuro es la secuencia vacía. ¿Cuál es la probabilidad de observar nada, dado que estamos en cualquier estado?
$$\beta_T(i) = P(\text{secuencia vacía} \mid q_T = i, \lambda) = 1 \qquad \text{para todo } i$$
La probabilidad de un evento seguro (la secuencia vacía, que siempre se “observa”) es 1, independientemente del estado en que estemos. Esto es la definición del caso base.
Para el ejemplo: $\beta_3(S) = 1$, $\beta_3(\mathrm{R}) = 1$.
3.2 Un paso hacia atrás ($t = T-1$): descubriendo la recursión
Ahora calculamos $\beta_2(i) = P(O_3 \mid q_2 = i, \lambda)$: la probabilidad de ver la observación futura $O_3 = 1$ dado que en $t=2$ estamos en el estado $i$.
Hay 2 caminos para llegar a producir $O_3$ desde el estado $i$: transitar a $S$ en $t=3$, o transitar a $R$ en $t=3$. Aplicamos ley de probabilidad total sobre el estado siguiente $q_3$:
$$\beta_2(i) = P(O_3 \mid q_2=i, \lambda) = \sum_{j \in {S,R}} P(q_3=j, O_3 \mid q_2=i, \lambda)$$
Cada término se descompone por la regla del producto:
$$= \sum_j P(q_3=j \mid q_2=i) \cdot P(O_3 \mid q_3=j, q_2=i, \lambda)$$
Simplificamos con dos propiedades del HMM:
- Propiedad de Markov: $P(q_3=j \mid q_2=i) = A_{ij}$.
- Independencia de emisión: $P(O_3 \mid q_3=j, q_2=i) = P(O_3 \mid q_3=j) = B_{j,O_3}$ — la observación $O_3$ depende solo del estado $q_3=j$.
Entonces:
$$\beta_2(i) = \sum_j A_{ij} \cdot B_{j,O_3}$$
Escribimos $\beta_3(j) = 1$ explícitamente para ver el patrón:
$$\beta_2(i) = \sum_j A_{ij} \cdot B_{j,O_3} \cdot \beta_3(j)$$
Para el ejemplo con $O_3 = 1$ (columna 1 de $B$):
$$\beta_2(S) = A_{SS} \cdot B_{S,1} \cdot \beta_3(S) + A_{SR} \cdot B_{R,1} \cdot \beta_3(\mathrm{R})$$ $$= 0.7 \times 0.1 \times 1.0 + 0.3 \times 0.8 \times 1.0 = 0.07 + 0.24 = 0.310$$
$$\beta_2(\mathrm{R}) = A_{RS} \cdot B_{S,1} \cdot \beta_3(S) + A_{RR} \cdot B_{R,1} \cdot \beta_3(\mathrm{R})$$ $$= 0.4 \times 0.1 \times 1.0 + 0.6 \times 0.8 \times 1.0 = 0.04 + 0.48 = 0.520$$
Interpretación: si en $t=2$ estoy en $R$ (lluvioso), el futuro ($O_3=1$, paraguas) es más probable que si estoy en $S$ — de ahí que $\beta_2(\mathrm{R}) = 0.52 > \beta_2(S) = 0.31$.
3.3 Otro paso hacia atrás ($t = T-2$): el patrón se repite
Ahora $\beta_1(i) = P(O_2, O_3 \mid q_1=i, \lambda)$: probabilidad de ver dos observaciones futuras ($O_2=1$ y $O_3=1$) dado el estado en $t=1$.
Aplicamos la misma lógica: ley de probabilidad total sobre $q_2$:
$$\beta_1(i) = \sum_j P(q_2=j, O_2, O_3 \mid q_1=i, \lambda)$$
Regla del producto + Markov + independencia de emisión:
$$= \sum_j A_{ij} \cdot P(O_2 \mid q_2=j) \cdot P(O_3 \mid q_2=j, \lambda)$$
La clave: $P(O_3 \mid q_2=j, \lambda)$ es exactamente $\beta_2(j)$ — ya lo calculamos. Entonces:
$$\beta_1(i) = \sum_j A_{ij} \cdot B_{j,O_2} \cdot \beta_2(j)$$
Nota la diferencia con Forward: la observación usada aquí es $O_2$ (la observación siguiente, que ocurre al transitar al estado $j$), no $O_1$.
Para el ejemplo con $O_2 = 1$:
$$\beta_1(S) = A_{SS} \cdot B_{S,1} \cdot \beta_2(S) + A_{SR} \cdot B_{R,1} \cdot \beta_2(\mathrm{R})$$ $$= 0.7 \times 0.1 \times 0.310 + 0.3 \times 0.8 \times 0.520 = 0.0217 + 0.1248 = 0.1465$$
$$\beta_1(\mathrm{R}) = A_{RS} \cdot B_{S,1} \cdot \beta_2(S) + A_{RR} \cdot B_{R,1} \cdot \beta_2(\mathrm{R})$$ $$= 0.4 \times 0.1 \times 0.310 + 0.6 \times 0.8 \times 0.520 = 0.0124 + 0.2496 = 0.2620$$
3.4 La recursión general — y su fundamento probabilístico
El mismo patrón aparece a cada paso. Para el instante $t$ y el estado actual $i$, partimos de la definición:
$$\beta_t(i) = P(O_{t+1}, O_{t+2}, \ldots, O_T \mid q_t=i, \lambda)$$
Paso 1 — Ley de probabilidad total sobre $q_{t+1}$ (toda continuación del sistema pasa por algún estado $j$ en $t+1$):
$$= \sum_{j=1}^{N} P(q_{t+1}=j,, O_{t+1}, \ldots, O_T \mid q_t=i, \lambda)$$
Paso 2 — Regla del producto (separamos el factor de transitar a $j$ del factor de producir el futuro desde $j$):
$$= \sum_{j=1}^{N} P(q_{t+1}=j \mid q_t=i) \cdot P(O_{t+1}, \ldots, O_T \mid q_{t+1}=j,, q_t=i, \lambda)$$
donde usamos la propiedad de Markov: dado $q_t=i$, el siguiente estado $q_{t+1}$ no depende del historial anterior, así que $P(q_{t+1}=j \mid q_t=i) = A_{ij}$.
Paso 3 — Independencia de emisión del HMM: dado $q_{t+1}=j$, la observación $O_{t+1}$ no depende de $q_t$ ni del historial; y el resto del futuro ($O_{t+2},\ldots,O_T$) tampoco depende de $q_t$ dado $q_{t+1}=j$:
$$= \sum_{j=1}^{N} A_{ij} \cdot P(O_{t+1} \mid q_{t+1}=j) \cdot P(O_{t+2}, \ldots, O_T \mid q_{t+1}=j, \lambda)$$
Paso 4 — Reconocer los términos:
- $P(O_{t+1} \mid q_{t+1}=j) = B_{j,O_{t+1}}$ — emisión del valor $O_{t+1}$ desde el estado $j$.
- $P(O_{t+2}, \ldots, O_T \mid q_{t+1}=j, \lambda) = \beta_{t+1}(j)$ — por la definición de $\beta$.
Resultado: la recursión backward:
$$\beta_t(i) = \sum_{j=1}^{N} A_{ij} \cdot B_{j,O_{t+1}} \cdot \beta_{t+1}(j)$$
Cada factor tiene su papel:
- $A_{ij}$: transición de $i$ al estado siguiente $j$ (propiedad de Markov).
- $B_{j,O_{t+1}}$: emisión de la observación siguiente $O_{t+1}$ desde el estado destino $j$ (independencia de emisión del HMM). Nótese que es $O_{t+1}$, no $O_t$ — miramos hacia adelante.
- $\beta_{t+1}(j)$: información futura ya acumulada desde $j$ — todo lo que viene después de $O_{t+1}$.
- $\sum_j$: ley de probabilidad total — marginamos sobre todos los posibles estados siguientes.
Diferencia clave con Forward: en Forward la emisión es $B_{j,O_t}$ (el estado destino emite la observación actual). En Backward la emisión es $B_{j,O_{t+1}}$ (el estado destino $j$ en $t+1$ emite la observación siguiente). Backward mira un paso hacia adelante en cada iteración.
4. Inicialización, recursión y terminación
[P1] Inicialización ($t = T$):
$$\beta_T(i) = 1 \qquad \text{para todo } i = 1, \ldots, N$$
Interpretación: en el último instante no hay observaciones futuras. La probabilidad de “la secuencia vacía” es 1 para cualquier estado.
[P2] Recursión ($t = T-1, T-2, \ldots, 1$):
$$\beta_t(i) = \sum_{j=1}^{N} A_{ij} \cdot B_{j,O_{t+1}} \cdot \beta_{t+1}(j) \qquad \text{para todo } i = 1, \ldots, N$$
Desglose para el estado actual $i$ en el instante $t$:
- Para cada estado destino $j$ en $t+1$: la probabilidad de transitar de $i$ a $j$ es $A_{ij}$.
- El estado $j$ emite la observación siguiente $O_{t+1}$: cuesta $B_{j,O_{t+1}}$, donde $O_{t+1}$ es el valor de la observación — el índice de columna de $B$.
- El futuro restante desde $j$ en $t+1$ ya está resumido en $\beta_{t+1}(j)$.
- Sumamos sobre todos los estados $j$ posibles — todos contribuyen.
[P3] Terminación — verificación cruzada:
$$P(O \mid \lambda) = \sum_{i=1}^{N} \pi_i \cdot B_{i,O_1} \cdot \beta_1(i)$$
Aquí $O_1$ es el valor de la primera observación (=0 en el ejemplo de Lain), usado como índice de columna de $B$: si $O_1 = 0$, entonces $B_{i,O_1} = B_{i,0}$.
Esta fórmula debe dar el mismo resultado que el algoritmo Forward. Si coincide, ambos están correctos.
5. El trellis backward: cómo visualizar el cómputo
El trellis de Backward tiene la misma estructura que el de Forward — una rejilla de $N$ filas (estados) por $T$ columnas (instantes) — pero el cómputo va en sentido contrario: de derecha a izquierda.
Estructura del trellis:
t=1 t=2 t=3
┌──────┐ ┌──────┐ ┌──────┐
S ── │β₁(S) │ ←── │β₂(S) │ ←── │β₃(S)│ = 1
└──────┘ ↖ └──────┘ ↖ └──────┘
↙ ↙
┌──────┐ ↖ ┌──────┐ ↖ ┌──────┐
R ── │β₁(R) │ ←── │β₂(R) │ ←── │β₃(R)│ = 1
└──────┘ └──────┘ └──────┘
O₁=0 O₂=1 O₃=1
Qué significa cada elemento:
- Columna = un instante de tiempo $t$.
- Fila = un estado oculto (S o R en nuestro ejemplo).
- Nodo $(t, i)$ = almacena el valor $\beta_t(i)$.
- Inicialización: los nodos de la última columna ($t=T$) valen todos 1.
- Flecha de $(t+1, j)$ a $(t, i)$ = la contribución $A_{ij} \cdot B_{j,O_{t+1}} \cdot \beta_{t+1}(j)$ que el nodo futuro aporta al nodo actual. Hay $N \times N$ flechas entre cada par de columnas — todos los estados futuros contribuyen a todos los estados actuales.
Cómo se calcula cada nodo:
El nodo $\beta_t(i)$ recibe contribuciones de todos los nodos de la columna siguiente (eso es la suma $\sum_j A_{ij} \cdot B_{j,O_{t+1}} \cdot \beta_{t+1}(j)$). La emisión $B_{j,O_{t+1}}$ corresponde al nodo futuro $j$ en $t+1$ — porque propagamos hacia atrás lo que sucedería al transitar al estado $j$ y emitir la observación siguiente.
Dirección del cómputo: siempre de derecha a izquierda (futuro → pasado). Empezamos con $\beta_T(i)=1$ y propagamos hacia $t=1$.
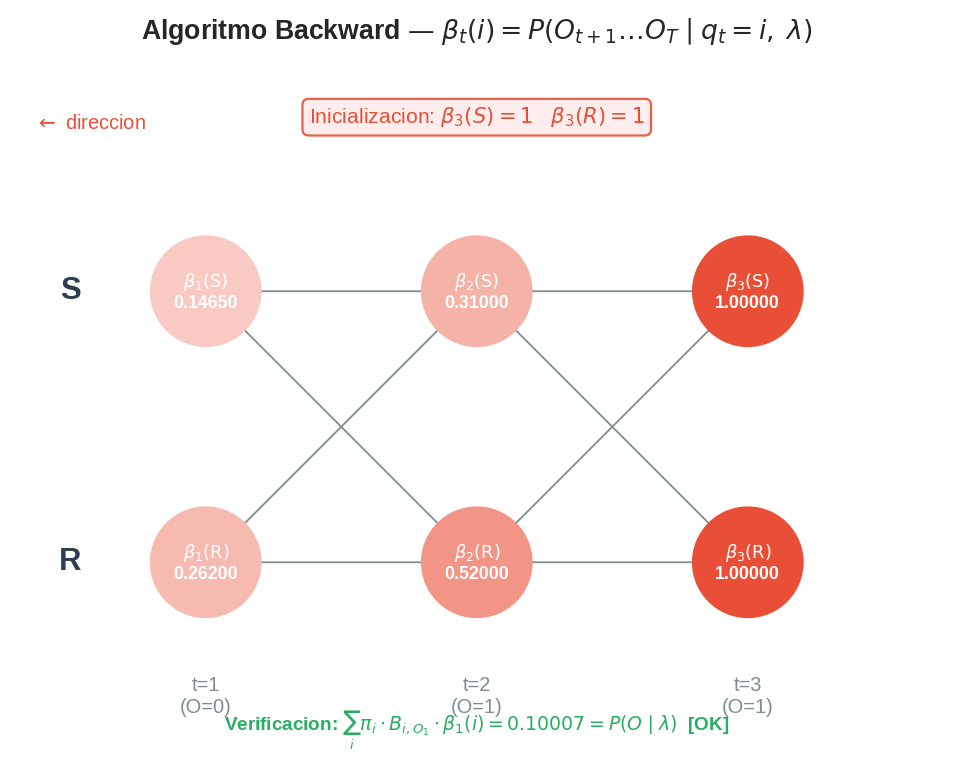
Con valores del ejemplo de Lain:
Estado │ t=1 t=2 t=3
───────┼────────────────────────────────────────────
S │ 0.14650 ←── 0.31000 ←── 1.00000
│ ↖ ↙↖ ↙
R │ 0.26200 ←── 0.52000 ←── 1.00000
O_t │ O₁=0 O₂=1 O₃=1
────────────────────────────────────────────→ tiempo
←────────────────────────────── sentido del cómputo
6. Traza completa: el ejemplo de Lain
Parámetros: $O = (0, 1, 1)$
Las matrices con sus entradas etiquetadas explícitamente:
$$A = \begin{pmatrix} A_{SS} & A_{SR} \\ A_{RS} & A_{RR} \end{pmatrix} = \begin{pmatrix} 0.7 & 0.3 \\ 0.4 & 0.6 \end{pmatrix}, \qquad B = \begin{pmatrix} B_{S,0} & B_{S,1} \\ B_{R,0} & B_{R,1} \end{pmatrix} = \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix}$$
Paso 1 — Inicialización ($t=3$):
$$\beta_3(S) = 1.0, \qquad \beta_3(\mathrm{R}) = 1.0$$
Interpretación: no hay observaciones después del instante 3. La probabilidad de “observar la secuencia vacía” es 1 para cualquier estado.
Paso 2 — Recursión ($t=2$, observación futura $O_3 = 1$, usamos la columna 1 de $B$):
Para el estado $S$ en $t=2$ — si estoy en $S$, ¿a qué estados puedo ir en $t=3$?
$$\beta_2(S) = A_{SS} \cdot B_{S,1} \cdot \beta_3(S) + A_{SR} \cdot B_{R,1} \cdot \beta_3(\mathrm{R})$$ $$= 0.7 \times 0.1 \times 1.0 + 0.3 \times 0.8 \times 1.0 = 0.07 + 0.24 = 0.310$$
Para el estado $R$ en $t=2$ — si estoy en $R$, ¿a qué estados puedo ir en $t=3$?
$$\beta_2(\mathrm{R}) = A_{RS} \cdot B_{S,1} \cdot \beta_3(S) + A_{RR} \cdot B_{R,1} \cdot \beta_3(\mathrm{R})$$ $$= 0.4 \times 0.1 \times 1.0 + 0.6 \times 0.8 \times 1.0 = 0.04 + 0.48 = 0.520$$
Paso 3 — Recursión ($t=1$, observación futura $O_2 = 1$, columna 1 de $B$ otra vez):
Para el estado $S$ en $t=1$:
$$\beta_1(S) = A_{SS} \cdot B_{S,1} \cdot \beta_2(S) + A_{SR} \cdot B_{R,1} \cdot \beta_2(\mathrm{R})$$ $$= 0.7 \times 0.1 \times 0.31 + 0.3 \times 0.8 \times 0.52 = 0.0217 + 0.1248 = 0.1465$$
Para el estado $R$ en $t=1$:
$$\beta_1(\mathrm{R}) = A_{RS} \cdot B_{S,1} \cdot \beta_2(S) + A_{RR} \cdot B_{R,1} \cdot \beta_2(\mathrm{R})$$ $$= 0.4 \times 0.1 \times 0.31 + 0.6 \times 0.8 \times 0.52 = 0.0124 + 0.2496 = 0.2620$$
Verificación cruzada (debe coincidir con Forward):
$$P(O \mid \lambda) = \pi_S \cdot B_{S,0} \cdot \beta_1(S) + \pi_R \cdot B_{R,0} \cdot \beta_1(\mathrm{R})$$ $$= 0.6 \times 0.9 \times 0.1465 + 0.4 \times 0.2 \times 0.2620$$ $$= 0.07911 + 0.02096 = \mathbf{0.10007} \checkmark$$
El resultado coincide exactamente con el Forward. Ambos algoritmos son correctos.
Nota: $B_{S,0}$ y $B_{R,0}$ aparecen aquí porque $O_1 = 0$ — el valor de la primera observación es 0, que es el índice de columna en $B$. Si la primera observación hubiera sido 1, usaríamos la columna 1.
Tabla resumen de $\beta$:
| $t$ | $O_t$ | $\beta_t(S)$ | $\beta_t(\mathrm{R})$ |
|---|---|---|---|
| 1 | 0 | 0.1465 | 0.2620 |
| 2 | 1 | 0.3100 | 0.5200 |
| 3 | 1 | 1.0000 | 1.0000 |
7. Pseudocódigo
función BACKWARD(O, π, A, B):
T ← longitud(O) # número de observaciones en la secuencia
N ← número de estados ocultos posibles
# ── [P1] Inicialización ────────────────────────────────────────────────────
# Caso base: en t=T no hay observaciones futuras.
# La probabilidad de "la secuencia vacía del futuro" es 1 para cualquier estado.
para i = 1 hasta N:
β[T][i] ← 1
# ── [P2] Recursión (de derecha a izquierda) ────────────────────────────────
# Avanzamos columna por columna, de t=T-1 hasta t=1.
# Para cada estado de origen i, acumulamos las contribuciones de TODOS
# los estados de destino j (columna siguiente), ponderadas por A[i][j].
# La emisión usada es B[j][O[t+1]] — la observación SIGUIENTE emitida por j.
para t = T-1 hasta 1:
para i = 1 hasta N: # i = estado actual en t
β[t][i] ← 0
para j = 1 hasta N: # j = estado siguiente en t+1
β[t][i] ← β[t][i] + A[i][j] × B[j][O[t+1]] × β[t+1][j]
# ↑ prob. ↑ emitir la obs. SIGUIENTE ↑ β futuro
# transición desde el estado destino j
# Nota: B[j][O[t+1]] usa el VALOR de la observación t+1 como índice de columna
# ── [P3] Terminación (verificación cruzada con Forward) ───────────────────
# Reconstruimos P(O|λ) desde β₁, combinando con π y la primera observación.
# Debe coincidir con el resultado del algoritmo Forward.
P_obs ← 0
para i = 1 hasta N:
P_obs ← P_obs + π[i] × B[i][O[1]] × β[1][i]
# ↑ inicio ↑ emitir O[1] desde i ↑ futuro completo desde i
# Nota: B[i][O[1]] usa el VALOR de la primera observación como índice de columna
retornar β, P_obs # β contiene todos los valores; P_obs = P(O | λ) (verificación)
8. Combinando Forward y Backward: la posterior $\gamma_t(i)$
La razón principal de calcular $\beta$ es poder combinarla con $\alpha$ para obtener la probabilidad posterior de cada estado:
$$\gamma_t(i) = P(q_t = i \mid O, \lambda) = \frac{\alpha_t(i) \cdot \beta_t(i)}{P(O \mid \lambda)}$$
En palabras: la probabilidad de estar en el estado $i$ en el instante $t$, dado que hemos observado toda la secuencia $O$, es proporcional al producto de la información pasada ($\alpha$) y la información futura ($\beta$). Dividimos por $P(O \mid \lambda)$ para normalizar.
¿Por qué el producto? Porque $\alpha_t(i)$ captura todo lo que sabemos mirando hacia la izquierda (pasado + estado actual), y $\beta_t(i)$ captura todo lo que sabemos mirando hacia la derecha (futuro desde el estado actual). Multiplicarlos y normalizar es aplicar el teorema de Bayes sobre toda la secuencia.
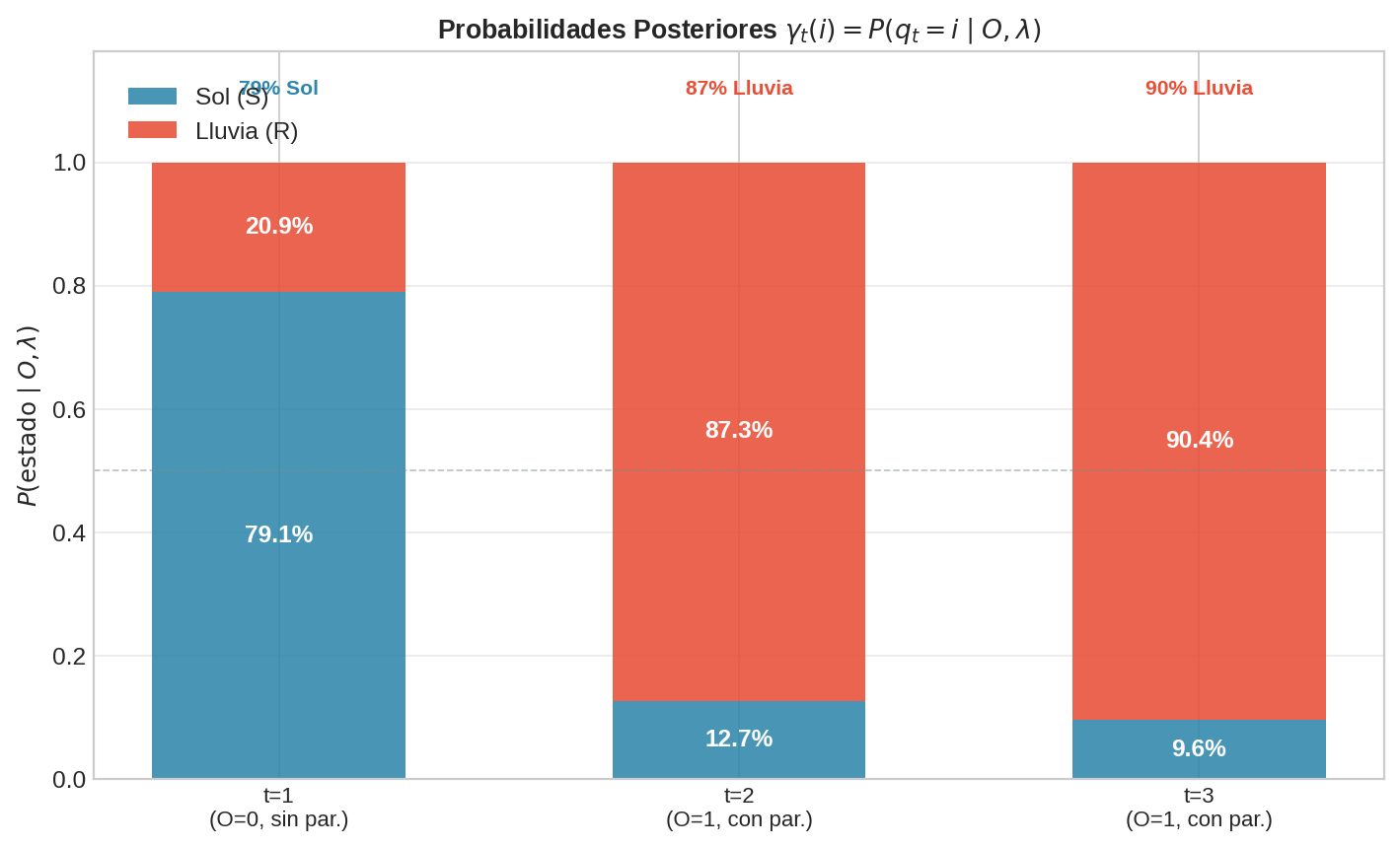
Para el ejemplo de Lain:
| $t$ | $\gamma_t(S)$ | $\gamma_t(\mathrm{R})$ | Interpretación |
|---|---|---|---|
| 1 | $\frac{0.540 \times 0.1465}{0.10007} = 0.791$ | 0.209 | Día 1: probablemente soleado ($O=0$ confirma) |
| 2 | $\frac{0.041 \times 0.310}{0.10007} = 0.127$ | 0.873 | Día 2: probablemente lluvioso ($O=1$ confirma) |
| 3 | $\frac{0.00959 \times 1.0}{0.10007} = 0.096$ | 0.904 | Día 3: muy probablemente lluvioso ($O=1$ confirma) |
Notar que $\gamma_t(S) + \gamma_t(\mathrm{R}) = 1$ para todo $t$ — son probabilidades condicionales correctamente normalizadas.
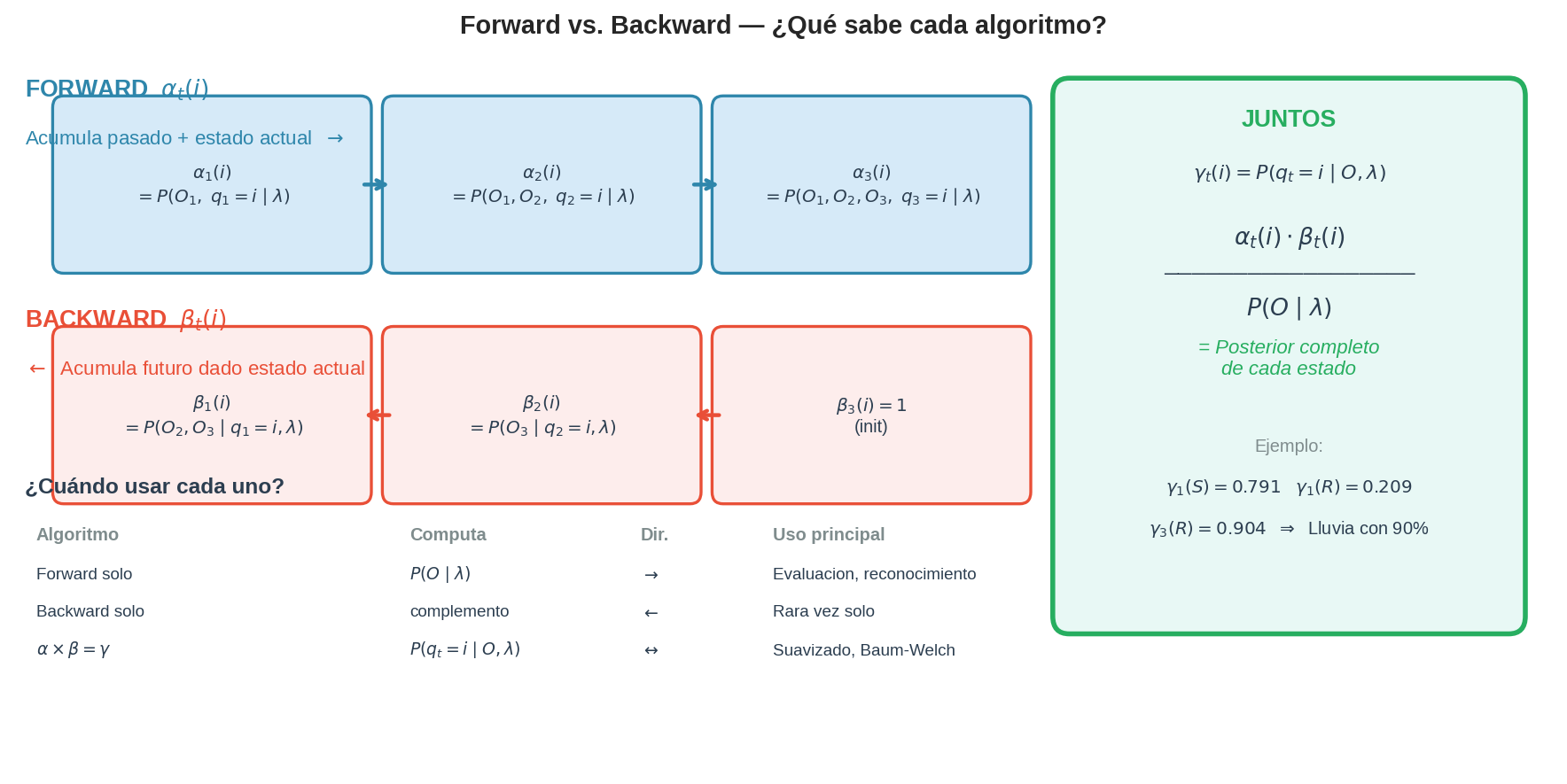
9. Forward vs Backward: comparación
| Aspecto | Forward $\alpha_t(i)$ | Backward $\beta_t(i)$ |
|---|---|---|
| Define | $P(O_1 \ldots O_t, q_t=i \mid \lambda)$ | $P(O_{t+1} \ldots O_T \mid q_t=i, \lambda)$ |
| Dirección | Izquierda → derecha | Derecha → izquierda |
| Inicialización | $\alpha_1(i) = \pi_i \cdot B_{i,O_1}$ | $\beta_T(i) = 1$ |
| Emisión en recursión | $B_{j,O_t}$ — obs. actual desde estado destino | $B_{j,O_{t+1}}$ — obs. siguiente desde estado destino |
| ¿Solo bastante? | Sí, para $P(O \mid \lambda)$ | No solo (necesita $\pi$ y $B$ para terminar) |
| Uso principal | Evaluación | Posteriors $\gamma$ (con Forward) |
| ¿Cuándo usar los dos? | Para Baum-Welch y para calcular $\gamma_t(i)$ | Siempre junto con Forward |
| Complejidad | $O(N^2 T)$ | $O(N^2 T)$ |
Regla práctica: Si solo necesitas $P(O \mid \lambda)$, usa Forward solo. Si necesitas los posteriors $\gamma_t(i)$ (para saber cuándo es más probable cada estado), necesitas ambos.