Una sola diferencia
Q-learning y SARSA son idénticos excepto por un símbolo en la regla de actualización.
| SARSA | Q-learning | |
|---|---|---|
| Actualización | $Q(s,a) \leftarrow Q(s,a) + \alpha\bigl[r + \gamma \mathbf{Q(s’, a’)} - Q(s,a)\bigr]$ | $Q(s,a) \leftarrow Q(s,a) + \alpha\bigl[r + \gamma \mathbf{\max_b Q(s’, b)} - Q(s,a)\bigr]$ |
| Siguiente valor | $Q(s’, a’)$ donde $a’ \sim \pi_\varepsilon$ | $\max_b Q(s’, b)$ |
| Datos necesarios | Quíntuple $(S, A, R, S’, A’)$ | Cuádruplo $(S, A, R, S’)$ |
La diferencia es que Q-learning no necesita observar $a’$ — toma el máximo directamente. Eso lo hace off-policy: no importa qué acción ejecute el agente en $s’$, siempre usa el valor óptimo posible.
Regla de actualización
$$\boxed{Q(s,a) \leftarrow Q(s,a) + \alpha\bigl[r + \gamma \max_b Q(s’, b) - Q(s,a)\bigr]}$$
Pseudocódigo
La idea en palabras: Al inicio de cada episodio, el agente simplemente observa el estado $s$ — no elige ninguna acción todavía. Dentro del bucle elige $a$ con $\varepsilon$-greedy, ejecuta, observa $(r, s’)$ y calcula el máximo sobre todas las acciones posibles en $s’$. Ese máximo — no la acción que realmente tomará — es el target. Después de actualizar $Q$, avanza a $s’$ y repite. No hay ninguna variable de acción que “cargar” de un paso al siguiente: cada paso es autónomo.
Q_LEARNING(α, γ, ε, num_episodios):
Inicializa Q[s, a] ← 0 para todo (s, a)
Para cada episodio:
s ← estado_inicial()
Mientras s no sea terminal:
a ← ε-greedy(Q, s) ← elegimos a para explorar
s', r ← ejecutar(a) ← observamos (s', r)
max_q ← max sobre b de Q[s', b] ← máximo, NO la acción que tomaremos
Q[s, a] ← Q[s, a] + α · (r + γ · max_q − Q[s, a])
s ← s' ← avanzamos con solo 4 elementos
Comparación directa con SARSA:
| SARSA | Q-learning | |
|---|---|---|
| ¿Elige acción antes del bucle? | Sí — a ← ε-greedy(Q, s) |
No — entra directo |
| ¿Qué usa como target en $s’$? | Q[s', a'] — la acción que realmente tomará |
max Q[s', b] — el mejor valor posible |
| ¿Pasa la acción al siguiente paso? | Sí — a ← a' |
No — cada paso es independiente |
| Elementos del quíntuple/cuádruplo | $(S, A, R, S’, A’)$ — cinco | $(S, A, R, S’)$ — cuatro |
| Aprende el valor de… | la política $\varepsilon$-greedy que ejecuta | la política greedy óptima |
La única diferencia de fondo está en el target: SARSA pregunta “¿cuánto vale lo que voy a hacer?”, Q-learning pregunta “¿cuánto vale lo mejor que podría hacer?”.
Los mismos dos episodios: ¿cuándo divergen?
Con los mismos parámetros ($\alpha=0.5$, $\gamma=1$, $\varepsilon=0.4$) y las mismas trayectorias:
Episodio 1: trayectoria $0 \to 1 \to 3 \to 5$
Todos los valores son cero; $\max_b Q(s’, b) = 0$ en todos los casos. Las actualizaciones son idénticas a SARSA:
| Paso | $s$ | $a$ | $r$ | $s’$ | $\max_b Q(s’, b)$ | $\delta$ | Actualización |
|---|---|---|---|---|---|---|---|
| 1 | 0 | $+1$ | $-2$ | 1 | $\max(0, 0) = 0$ | $-2$ | $Q(0,+1) = -1.0$ |
| 2 | 1 | $+2$ | $-10$ | 3 | $\max(0, 0) = 0$ | $-10$ | $Q(1,+2) = -5.0$ |
| 3 | 3 | $+2$ | $0$ | 5 | — | $0$ | sin cambio |
Episodio 2: trayectoria $0 \to 2 \to 4 \to 5$
De nuevo, los valores relevantes en $s’$ son cero o coinciden con el máximo. Las actualizaciones son idénticas a SARSA:
| Paso | $s$ | $a$ | $r$ | $s’$ | $\max_b Q(s’, b)$ | $\delta$ | Actualización |
|---|---|---|---|---|---|---|---|
| 1 | 0 | $+2$ | $-5$ | 2 | $\max(0, 0) = 0$ | $-5$ | $Q(0,+2) = -2.5$ |
| 2 | 2 | $+2$ | $-1$ | 4 | $\max(0, \text{—}) = 0$ | $-1$ | $Q(2,+2) = -0.5$ |
| 3 | 4 | $+1$ | $0$ | 5 | — | $0$ | sin cambio |
La tabla después del episodio 2 es idéntica en ambos algoritmos (ya la vimos en la sección 03).
Episodio 3, paso 1: aquí divergen
Desde $s=0$, $\varepsilon$-greedy elige $a=+2$ (exploración). El ambiente devuelve $s’=2$, $r=-5$.
Q-learning toma el máximo sobre $s’=2$: $$\max_b Q(2, b) = \max(Q(2,+1), Q(2,+2)) = \max(0, -0.5) = 0$$ $$\delta_{\text{QL}} = -5 + 0 - (-2.5) = -2.5$$ $$Q(0,+2) \leftarrow -2.5 + 0.5 \cdot (-2.5) = -3.75$$
SARSA (para comparar) usó $a’=+2$ muestreado de $\pi_\varepsilon$, obteniendo $Q(2,+2)=-0.5$: $$\delta_{\text{SARSA}} = -5 + (-0.5) - (-2.5) = -3.0$$ $$Q(0,+2) \leftarrow -2.5 + 0.5 \cdot (-3.0) = -4.00$$
A partir de aquí las tablas son distintas. Q-learning “ignora” la exploración de $s’=2$ y aprende un valor más optimista; SARSA la incorpora y es más conservador.
Convergencia
Q-learning converge a $Q^∗$ independientemente de la política de comportamiento, siempre que:
- Cada par $(s, a)$ sea visitado infinitas veces (garantizado por $\varepsilon$-greedy con $\varepsilon > 0$).
- La tasa de aprendizaje $\alpha$ decrezca apropiadamente (o sea constante y suficientemente pequeña).
No importa si el agente explora mucho o poco — el target siempre apunta a la ecuación de Bellman óptima.
La $Q^∗$ convergida y el círculo completo
Después de ~100 episodios, Q-learning converge a la siguiente tabla:
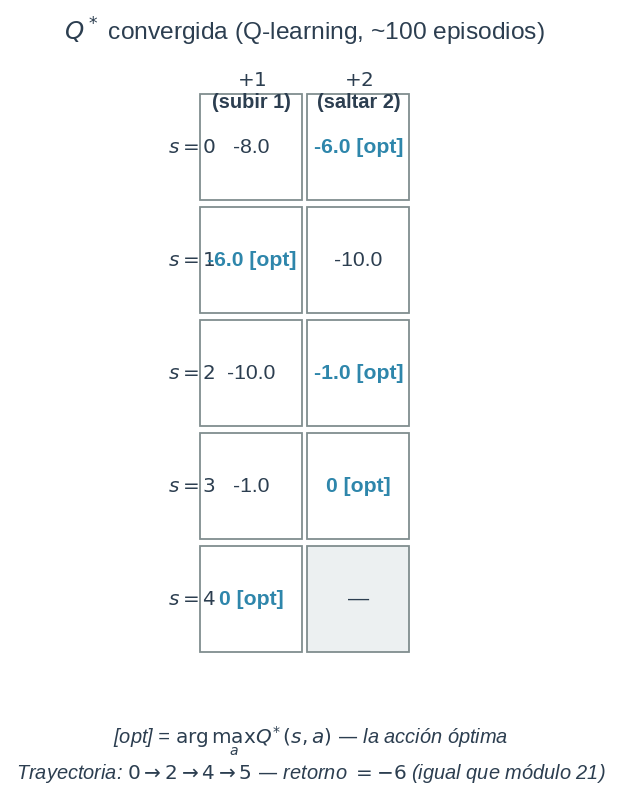
Los valores son:
| Estado | $+1$ | $+2$ | Acción óptima |
|---|---|---|---|
| $s=0$ | −8.0 | −6.0 | $+2$ |
| $s=1$ | −6.0 | −10.0 | $+1$ |
| $s=2$ | −10.0 | −1.0 | $+2$ |
| $s=3$ | −1.0 | 0.0 | $+2$ |
| $s=4$ | 0.0 | — | $+1$ |
La política óptima es: desde cada estado, toma la acción marcada. Siguiéndola:
$$0 \xrightarrow{+2} 2 \xrightarrow{+2} 4 \xrightarrow{+1} 5$$
Retorno: $r(s’=2) + r(s’=4) + r(s’=5) = -5 + (-1) + 0 = -6$.
Esto es exactamente la política y el coste que calculamos con programación dinámica en el módulo 21. El círculo se cierra:
Q-learning aprendió la misma política óptima que DP — pero sin conocer $T$ ni $R$, solo interactuando con el ambiente.
En términos formales: $\arg\max_a Q^∗(s,a)$ recupera la política del módulo 21, y el retorno óptimo $G_0 = -6$ coincide con el coste mínimo $= 6$ encontrado por iteración de valor.
Curvas de aprendizaje
Podemos ver cómo convergen ambos algoritmos a lo largo de los episodios:
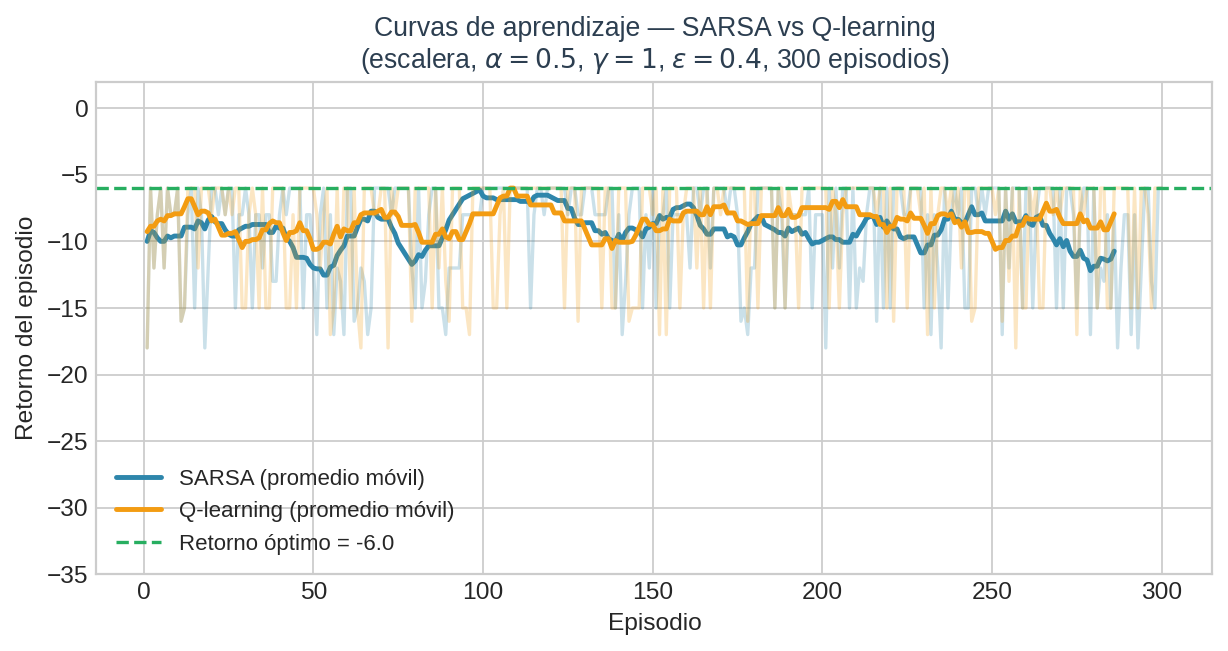
Ambos algoritmos convergen hacia el retorno óptimo $= -6$, aunque con diferentes trayectorias. Q-learning tiende a explorar de forma más “optimista” y puede mostrar mayor varianza inicial. SARSA aprende el valor de la política con exploración y puede ser más conservador.